
Google検索コンソールで「検出済み–現在インデックスに登録されていない」を修正する方法
公開: 2022-01-11Googleのドキュメントでは、Discovered –現在Googleのインデックスカバレッジレポートでインデックスに登録されていないステータスを次のように定義しています。
このページはGoogleによって検出されましたが、まだクロールされていません。 通常、GoogleはURLをクロールしたいと考えていましたが、これによりサイトが過負荷になると予想されていました。 そのため、Googleはクロールのスケジュールを変更しました。 これが、レポートの最終クロール日が空である理由です。出典: Googleのインデックスカバレッジレポート
Tomek Rudzkiは、Google Search Consoleに表示される最も一般的なインデックス作成の問題を調査し、Discovered –現在インデックス作成されていない問題の1つであることがわかりました。
- 重複コンテンツ、
- クロール–現在インデックス付けされていません。
- ソフト404、および
- クロールの問題。
発見された問題への対処–現在インデックスに登録されていない問題は、多くのページに影響を与える可能性があり、一部のページがクロールされてからインデックスに登録されていないことを示しているため、優先する必要があります。
この問題は多くの要因によって引き起こされる可能性があり、対処しないと、一部のページがGoogleのインデックスに登録されない可能性があります。 その場合、オーガニックトラフィックをもたらしたり、コンバージョンを促進したりすることはありません。
この記事では、検索コンソールのインデックスカバレッジレポートの現在インデックスに登録されていないセクションを詳しく説明し、ページがそこに到達する理由と、それを引き起こす可能性のある問題を修正する方法に焦点を当てます。
発見された場所–現在インデックスに登録されていないステータス
発見–現在インデックスに登録されていないのは、Google検索コンソールのインデックスカバレッジレポートの問題タイプの1つです。 レポートには、Webサイトのページのクロールとインデックス作成のステータスが表示されます。
検出済み–現在インデックスに登録されていないカテゴリは除外カテゴリに表示されます。これには、Googleがインデックスに登録していないURLが含まれますが、Googleの観点からは、この状況はエラーの結果ではありません。
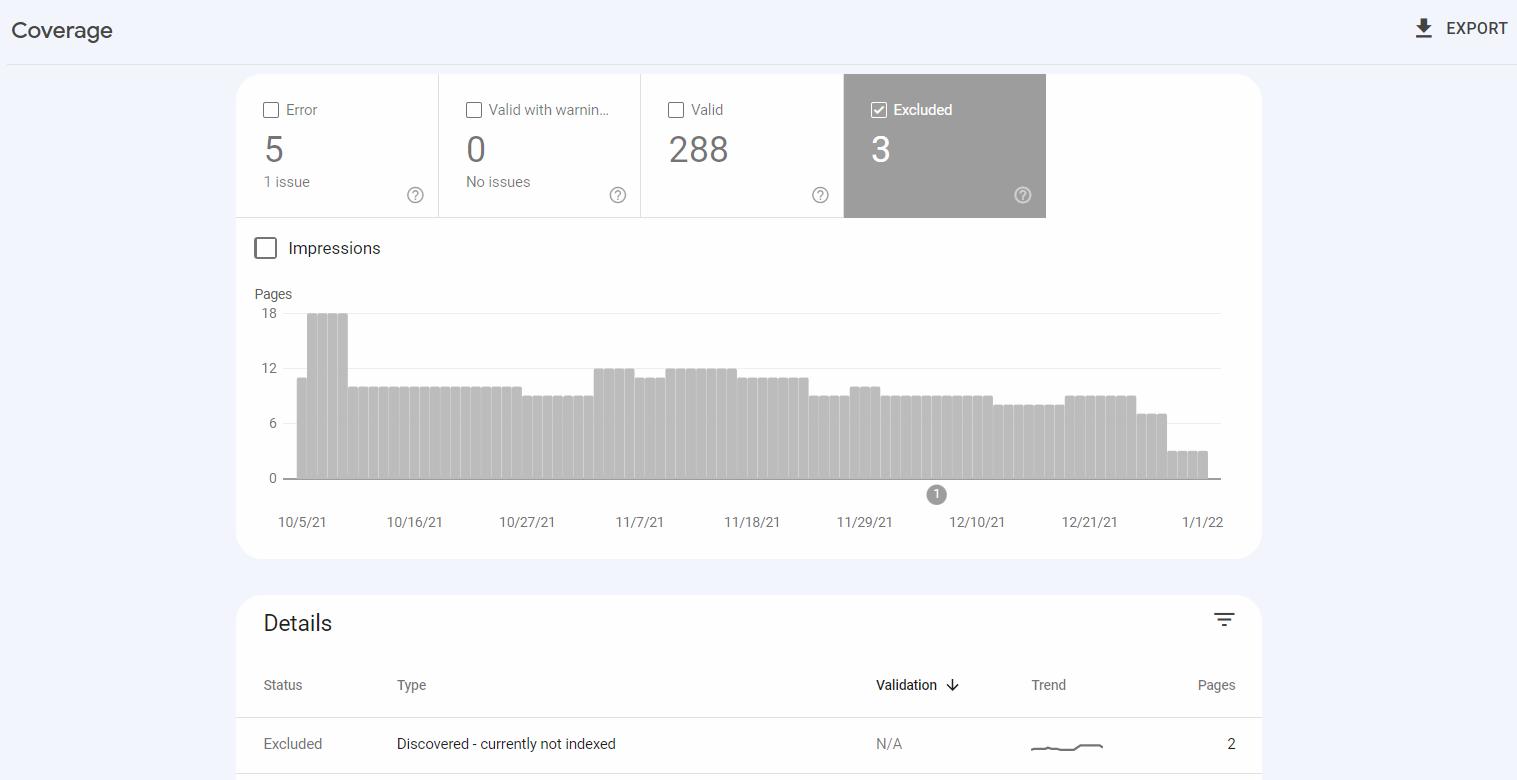
Google Search Consoleを使用している場合は、問題の種類をクリックして、影響を受けるURLのリストを表示できます。
報告されたURLの一部をインデックスから除外することを意図していることに気付くかもしれませんが、それは問題ありません。 ただし、貴重なページを監視する必要があります。インデックスに登録されていないページがある場合は、Googleが検出した問題を確認してください。
検出、クロール、およびインデックス作成
Discoveredの特徴に移る前に、現在インデックスに登録されておらず、この問題に対処する前に、URLがGoogleでランク付けされるために必要なことを明確にしましょう。
- Googleは、クロールする前にURLを見つける必要があります。 URLは、最も一般的には、内部リンクまたは外部リンク、あるいはXMLサイトマップをたどることによって発見されます。XMLサイトマップには、インデックスを作成する必要のあるすべてのページが含まれている必要があります。
- ページをクロールすることで、Googleはページにアクセスし、コンテンツをチェックします。 Googleには、検出したすべてのページをクロールするためのリソースがありません。この事実は、サイトで発生する多くのクロールの問題の背後にあります。
- インデックス作成中に、 Googleはページのコンテンツを抽出し、その品質を評価します。 検索結果に表示され、Googleからオーガニックトラフィックを取得するには、インデックスを作成する必要があります。 インデックスに登録されたページは、ユーザーがGoogleに入力した検索クエリに応じてどのようにランク付けされるかを決定する、多数のランキング要素に基づいて評価されます。
Googleによるインデックスの作成は、リソースの容量が限られていること、Webが成長し続けていること、およびGoogleがインデックスを作成するページに一定レベルの品質を期待していることから、困難です。
多くの技術的およびコンテンツ関連の要因が、ページがクロールまたはインデックスに登録されない場合に影響を与える可能性があります。
インデックスに登録される可能性を高めるための解決策があります。 これらには以下が含まれます:
- あなたのウェブサイトの貴重な部分のクロールを優先するクロール戦略を持っている、
- 内部リンクの実装、
- インデックス付け可能である必要があるすべてのURLを含む正確なサイトマップを作成し、
- 高品質で価値のあるコンテンツを書く。
Googleのドキュメントを必ず確認してください。Googleがページをクロールしてインデックスに登録しやすくするために従うべきガイドラインに関するセクションがあります。
Discovered –現在インデックス付けされていないレポートセクションの使用方法
Discovered –現在インデックスに登録されていないステータスは、潜在的なクロールの問題について最新情報を入手するための場所です。
このセクションでURLを見つけたら、そもそもそれらをクロールする必要があるかどうかを確認します。
必要に応じて、レポートに表示されるURLのパターンを見つけてください。 これは、これらのURLのどの側面が問題を引き起こしている可能性があるかを特定するのに役立ちます。
たとえば、この問題は、特定のカテゴリの製品のURL、パラメータのあるページ、または特定の構造のページに関係している可能性があり、それらはすべてシンコンテンツと見なされます。
検出された場合–現在インデックス付けされていないセクションにアクションが必要な場合
DiscoveredのURL–現在インデックスに登録されていないため、必ずしもWebサイトに変更を加える必要はありません。
つまり、次の場合は何もする必要はありません。
- 影響を受けるURLの数が少なく、時間の経過とともに安定している、または
- レポートには、クロールまたはインデックス作成しないURLが含まれています。たとえば、canonicalタグまたは'noindex'タグが付いているURLや、robots.txtファイルでクロールがブロックされているURLなどです。
ただし、このレポートのセクションを管理することは依然として重要です。
URLの数が増える場合、またはURLがランク付けされ、大量のオーガニックトラフィックをもたらすと予想される貴重なURLで構成されている場合は、注意が必要です。
Discoveredの影響–現在、小規模なWebサイトと大規模なWebサイトではインデックスに登録されていません
Discoveredの影響–現在インデックスに登録されていないセクションは、Webサイトのサイズによって異なる場合があります。
小規模なWebサイト(通常は1万のURLを超えない)があり、ページに高品質で一意のコンテンツがある場合、現在インデックスに登録されていないステータスは自動的に解決されることがよくあります。 Googleで問題が発生していない可能性がありますが、リストされているURLをまだクロールしていません。
小規模なサイトは通常、クロール予算の問題に対処していません。また、コンテンツの品質の問題や不十分な内部リンク構造が原因で、報告されたページが急増する可能性があります。
Discovered –現在インデックスに登録されていないステータスは、大規模なサイト(10,000以上のURL)で特に深刻であり、数千または数百万のURLに適用される可能性があります。
Onelyでは、10万を超えるURLを含むWebサイトは、通常、クロールの予算の浪費に起因するクロールの問題に悩まされていることがわかりました。
これらの問題は通常、 eコマースのWebサイトで発生します。 多くの場合、コンテンツが重複または薄いか、在庫切れまたは期限切れの製品が含まれています。 このようなページは通常、クロールされるどころか、Googleのインデックスキューに入るのに必要な品質を欠いています。
大規模なサイトを立ち上げるとき
大規模なウェブサイトを立ち上げるだけの場合は、最初からGooglebotの仕事を簡単にすることができます。
大規模なサイトを立ち上げたい場合、後で更新されるだけの空のページや未完成のページが多数含まれている場合は、構造全体をすぐに立ち上げないでください。 Googlebotはこれらのページに出くわし、品質が低いと見なします。これにより、最初からクロールの予算が低くなるリスクがあります。 そして、この状況は修正するのに何年もかかるかもしれません。
定期的にリリースするコンテンツを追加することをお勧めします。 このようにして、Googlebotは最初からあなたの品質について肯定的な印象を与えます。
起動する前に、常にインデックス作成とクロールの戦略を立て、Googleがどのページにアクセスする必要があるかを知っておく必要があります。
検出された原因–現在インデックスに登録されていないステータスとその修正方法
通常、URLは検出済みとして分類されます。現在、コンテンツの品質、内部リンク、またはクロール予算の問題のためにインデックスに登録されていません。
このステータスのページが表示される理由とその修正方法を考えてみましょう。
コンテンツ品質の問題
Googleには、ウェブ上のすべてをクロールしてインデックスに登録することができないため、ページが満たす必要のある品質のしきい値があります。
Googleは、ドメイン上の一部のページをクロールする価値がないと見なしてスキップし、他のより価値のあるコンテンツを優先する場合があります。 その結果、これらのURLはDiscoveredとしてマークされる可能性があります–現在インデックス付けされていません。
John Muellerが言ったように、URLをDiscoveredとして持つことは注目に値します。現在インデックスに登録されていないのは、マークされたページに限定されるのではなく、サイト全体のコンテンツ品質の問題である可能性があります。 Googleがサイトをウェブ上の他のコンテンツと比較して低品質と見なしている場合、ページのクロールとインデックス作成をスキップする可能性があります。
この問題への対処を開始するには、影響を受けるURLのリストを調べて、各ページに一意のコンテンツが含まれていることを確認してください。 コンテンツは、ユーザーの検索意図を満たし、特定の問題を解決する必要があります。
Googleがウェブサイトを評価する際に従う品質評価ガイドラインを確認することをお勧めします。これは、ウェブ上で見つかったコンテンツでGoogleが何を探しているかを理解するのに役立ちます。
同時に、すべてのページをインデックスに登録するべきではないことを忘れないでください。
次のように、一部の低品質のページはインデックスに登録できないようにする必要があります。
- 古いコンテンツ(古いニュース記事など)、
- ウェブサイト内の検索ボックスによって生成されたページ、
- フィルタを適用して生成されたページ、
- 重複コンテンツ、
- 自動生成されたコンテンツ、
- ユーザー作成コンテンツ。
このようなセクションがrobots.txtファイルでクロールおよびインデックス作成されないようにブロックすることをお勧めします。

2021年12月31日のSEO営業時間中に、 John Muellerは、Discoveredに対処する方法としてWebサイトの品質を変更することについて話し合いました。現在はインデックスに登録されていません。
[…]ウェブサイトでより大きな品質変更を行うには、Googleシステムがそれを検出するのにかなりの時間がかかります。 […]これは、数日ではなく、数か月の流れに沿ったものです。 […]品質の変更が反映されるまでには時間がかかるため、小さな変更を加えて、それで十分かどうかを確認するのではなく、品質を大幅に変更する場合は、 […]それは本当に良い品質の変化です[…]。 数か月待ってから、「ああ、そうだね、他のページも変更する必要がある」と決めたくないでしょう。出典:ジョン・ミューラー
内部リンクの問題
Googlebotは、サイトの内部リンクをたどって他のページを見つけ、それらの間の接続を理解します。 したがって、最も重要なページが頻繁に内部でリンクされていることを確認してください。
Martin Splittは、レンダリングSEOウェビナーで誤ったリンク構造が問題になる可能性がある理由について話しました。
[…]1,000個のURLがあり、それらはすべてサイトマップにあり、クロールした他のどのページにも表示されていない場合は、次のようになります。これは本当に'[…]です。 サイトマップに表示するだけでなく、Webサイトの他の場所からリンクして、これらのページをクロールしたときに「Aha!」と表示されるようにします。 したがって、このページ、このページ、およびこのページはすべてこの製品ページを指しているので、サイトマップにのみ存在するこの他の製品よりも少し重要かもしれません'[…]。出典: Martin Splitt
適切な内部リンクは、ページを接続して、検索エンジンとユーザーがサイトの階層をたどるのに役立つ論理構造を作成することを中心に展開されます。 内部リンクは、サイトアーキテクチャのレイアウトにも関連しています。
検索エンジンがあなたのページを見つけて適切な重要性を割り当てるのを助けることは以下を含みます:
- 基礎となるコンテンツを決定し、他のページからリンクされていることを確認します。
- コンテンツにコンテキストリンクを追加し、
- 階層に基づいてページをリンクします。たとえば、親ページを子ページにリンクしたり、その逆を行ったり、サイトのナビゲーションにリンクを含めたりします。
- スパム的な方法でリンクを配置したり、アンカーテキストを過度に最適化したりすることを避け、
- 関連商品や投稿へのリンクを組み込む。
内部リンク構造の改善に関するこの記事も読むことができます。
クロール予算
クロール予算は、 Googlebotがウェブサイトでクロールできるページ数です。
サイトのクロール予算は、次の要素によって決定されます。
- クロール速度の制限– GoogleがクロールできるURLの数。これは、Webサイトの機能に合わせて調整されます。
- クロールの需要– URLの人気と更新頻度を確認することにより、URLを考慮する重要性に基づいて、GoogleがクロールするURLの数。
クロール予算を浪費すると、検索エンジンがWebサイトを非効率的にクロールする可能性があります。 その結果、あなたのウェブサイトのいくつかの基本的な部分がスキップされるかもしれません。
クロール予算の問題を引き起こす可能性のある多くの要因–次のようなものがあります。
- 低品質のコンテンツ、
- 内部リンク構造が不十分、
- リダイレクトの実装における間違い、
- 過負荷のサーバー、
- 重いウェブサイト。
クロール予算を最適化する前に、 Googlebotがサイトをどのようにクロールしているかを正確に調べる必要があります。
これを行うには、検索コンソールの別の便利なツールであるクロール統計レポートに移動します。 また、Googlebotがクロールしたリソースとスキップしたリソースの詳細については、サーバーログを確認してください。
以下は、クロール予算を最適化し、GoogleにDiscoveredの一部をクロールさせるために検討する必要がある5つの側面です。現在、サイトのインデックスに登録されていないページです。
低品質のコンテンツ
Googlebotが低品質のページを自由にクロールできる場合、ウェブサイト上の貴重なものにアクセスするためのリソースがない可能性があります。
検索エンジンのクローラーが特定のページをクロールしないようにするには、robots.txtファイルで正しいディレクティブを適用します。
また、Googlebotがサイト上の一意のインデックス可能なページを検出し、それらの変更に気付くのに役立つ、正しく最適化されたサイトマップがWebサイトにあることを確認する必要があります。
サイトマップには次のものが含まれている必要があります。
- 200のステータスコードで応答するURL、
- メタロボットタグのないURLは、インデックス作成をブロックし、
- ページの正規バージョンのみ。
内部リンク構造が不十分
GoogleがURLに到達する十分なリンクを見つけられない場合、その重要性を示す信号が不十分なため、URLのクロールをスキップする可能性があります。
「内部リンクの問題」のサブチャプターで概説されている私のガイドラインに従ってください。
リダイレクトの実装における間違い
リダイレクトを実装することは、サイトにとって有益な場合がありますが、正しく実行された場合に限ります。 GooglebotがリダイレクトされたURLに遭遇するたびに、リンク先URLに到達するために追加のリクエストを送信する必要があり、これにはより多くのリソースが必要です。
リダイレクトを実装するためのベストプラクティスに固執するようにしてください。 外部ソースから作業ページにリンクされている404エラーページからユーザーとボットの両方をリダイレクトできます。これにより、ランキングシグナルを維持できます。
ただし、リダイレクトされたページにリンクしないように注意してください。代わりに、正しいページを指すように更新してください。 また、リダイレクトループとチェーンを回避する必要があります。
サーバーの問題
サイトが過負荷になっているように見えるため、Googleでクロールの問題が発生する可能性があります。 これは、クロールバジェットに影響を与えるクロールレートがサーバーの機能に合わせて調整されるために発生します。
Rendering SEOに関するウェビナーで、Martin Splittは、Googleによるページのクロールに関するサーバーの問題について説明しました。
[…]私がよく目にすることの1つは、サーバーが断続的なエラー(具体的には、500の何か)を出し、サーバーが500、501、502、504などで応答するものはすべて、サーバーが「保留」と言うことを意味します。 、ここで問題が発生しました'[…]、そしてそれはすぐに倒れる可能性があるので、私たちは後退しています。 私たちが後退し、サーバーが積極的に反応するときはいつでも、私たちは通常、再びゆっくりと立ち上がっています。 毎日500件の応答があると想像してみてください。私たちはこれを見ています、私たちは少し後退しています、私たちは立ち直っています–私たちは再びそれを見ています[…]。 サーバーが否定的に応答するかどうかを調べる必要があります。
出典: Martin Splitt
サイトにサーバーの問題があるかどうかをホスティングプロバイダーに確認してください。
サーバーの問題は、Webパフォーマンスの低下によっても発生する可能性があります。詳細については、 Webパフォーマンスとクロールバジェットに関する記事を参照してください。
重いウェブサイト
クロールの問題は、一部のページが重すぎることが原因で発生する可能性があります。 Googleには、クロールしてレンダリングするためのリソースが不足している可能性があります。
ページをレンダリングするためにGooglebotが取得する必要のあるすべてのリソースは、クロール予算にカウントされます。 この場合、Googleはページを認識しますが、優先キューにさらにプッシュします。
コードの悪影響を減らすために、サイトのJavaScriptファイルとCSSファイルを最適化する必要があります。
新しいウェブサイトを持つ
Tomek RudzkiはTwitterの世論調査を作成し、SEOコミュニティに新しいサイトのインデックス作成の問題について尋ねました。 そして、世論調査の結果によると、ほぼ40%の人々がそのような問題を経験していました。
最近、新しいWebサイトのインデックス作成に問題がありますか?
— Tomek Rudzki(@TomekRudzki)2021年12月7日
SEO Office Hoursセッションの1つで、参加者が2か月前に立ち上げた新しいWebサイトを立ち上げました。このウェブサイトでは、多くのページがDiscoveredとしてマークされており、現在はインデックスに登録されていません。 次に、このステータスでページが表示されると予想される期間を尋ねたところ、ジョンは次のように回答しました。
それは永遠に続く可能性があります[…]。 特に新しいWebサイトでは、コンテンツが多い場合は、しばらくの間、新しいコンテンツの多くが検出され、インデックスに登録されないことが予想されます。 そして、時間の経過とともに、通常、それは一種のシフトオーバーをします。 そして、それは、実際にクロールされているか、実際にWebサイト自体に焦点を当てることに実際に価値があることがわかったときに、実際にインデックスが作成されるようなものです。出典:ジョン・ミューラー
通常、ページのインデックスを作成するための迅速な修正はありませんが、前述のSEOの側面を確認すると、ページのインデックスを作成する可能性が高くなる可能性があります。
Googleが高品質のコンテンツのみをインデックスに登録することを望んでいることは明らかであり、これらの品質のしきい値は増加しているようです。 しかし、これは、コンテンツがインデックスに含まれるに値することを何度もGoogleに証明する必要がある新しいWebサイトにとって特に困難です。
Discoveredのアドレス指定に関する追加情報–現在インデックスに登録されていません
SEOのオフィスアワー中に、John Muellerは、Discovered –現在インデックス付けされていないレポートセクションでスタックしているWebサイトのURLの約99%の問題を解決することについて質問されました。
ジョンの推奨事項は、次の3つの主要なステップを中心に展開されました。
[…]まず最初に、おそらく[…]異なるURLパターンのURLを誤って生成していないように見えます[…] URLにあるパラメータのような大文字、小文字、これらすべてがつながる可能性があります基本的にコンテンツを複製します。 また、これらの重複URLを多数発見した場合、このページのバリエーションがすでに存在するため、実際にはこれらの重複すべてをクロールする必要はないと思われるかもしれません[…]。 内部リンクから、すべてが正常であることを確認してください。 あなたのウェブサイト上のこれらすべてのページをクロールして、最後までやり遂げることができます。 これは、クローラーツール、またはScreamingFrogやDeepCrawlなどを使用して大まかにテストできます。 […]基本的に、Webサイトにクロールできるかどうかを通知し、そのクロール中に見つかったURLを表示します。 そのクロールが機能する場合は、これらのページの品質に重点を置きます。 あなたが約2000万ページを話していて、それらの99%がインデックスに登録されていない場合、私たちはあなたのウェブサイトの非常に小さな部分だけをインデックスに登録しています。 […]おそらく、「ページ数を半分に、あるいは[…]現在の数の10%に減らしたらどうなるか」と言うのは理にかなっています。 […]これらのページにさらに包括的なコンテンツを含めることで、通常、コンテンツの品質を少し向上させることができます。 そして、私たちのシステムでは、これらのページを見て、「まあ、これらのページ[…]は実際にはかなりよく見える」と言う方が少し簡単です。 立ち去って、もっとたくさんクロールしてインデックスを作成する必要があります。出典:ジョン・ミューラー
2022年2月18日の別のOfficeHoursセッションで、Johnは、「検出された–現在はインデックスに登録されていない」と思われる多数のURLについてもう一度尋ねられました。
そしてジョンは、このステータスのページがたくさんあるのは普通だと言っていました。
[…]ある程度、Googleがすべてをクロールしてインデックスに登録することはできないことを認めます。 […]たとえば、[…]個々の製品がクロールされてインデックスに登録されていないことに気付いた場合は、少なくともそれらの製品のカテゴリページがクロールされてインデックスに登録されていることを確認してください。 そうすれば、人々はまだあなたのウェブサイトでそれらの個々の製品のいくつかのコンテンツを見つけることができます[…]。出典:ジョン・ミューラー
SEOコミュニティのメンバーは、Discoveredとマークされたページの数が増えていると報告しています。現在、何ヶ月もインデックスに登録されていません。 この問題に対処するための代替ソリューションをテストしているところもあります。
Dan Shureは、スタックしたコンテンツを別のURLに移動してテストすることにしました。その結果、実際にインデックスが作成されました。
したがって、これらのページの多くは、最初にこのステータスのままにされた後、単にスタックする可能性があります。
検出済み–現在インデックス付けされていないvs.クロール済み–現在インデックス付けされていない
これらの2つのステータスは一般的に混同され、接続されていても、意味が異なります。
どちらの場合も、URLはインデックスに登録されていませんが、クロールされた状態で–現在インデックスに登録されていないため、Googleはすでにページにアクセスしています。 Discovered –現在インデックスに登録されていないため、ページはGoogleによって検出されましたが、クロールされていません。
クロール–現在インデックスが作成されているのは、インデックス作成の遅延、コンテンツ品質の問題、サイトアーキテクチャの問題、またはページのインデックスが解除されている可能性があることが原因であることがよくあります。
また、クロールを修正する方法を説明する詳細な記事があります–現在インデックスは作成されていません。
まとめ
発見–現在インデックスに登録されていないのは、ページの品質とクロールの予算の問題が原因である傾向があります。
これらの問題を修正し、将来的にGoogleがページを効率的かつ正確にクロールできるようにするには、ページのさまざまな側面を調べて最適化する必要があります。
Discoveredの問題を回避するのに役立つ主なものをいくつか紹介します–現在インデックスに登録されていないページ:
- robots.txtを使用して、Googlebotが低品質のページをクロールしないようにします。たとえば、サイトのフィルターや検索ボックスによって生成されたページなど、重複するコンテンツに焦点を当てます。
- Googleがページを見つけるために使用できる適切なサイトマップを作成するために時間をかけてください。
- サイトのアーキテクチャをそのまま維持し、重要なページが内部でリンクされていることを確認します。
- 自分にとって最も価値のあるページに優先順位を付けるために、インデックス作成戦略を立ててください。
- クロール予算を念頭に置いて最適化します。