
Comment réparer "Découvert - Actuellement non indexé" dans Google Search Console
Publié: 2022-01-11La documentation de Google définit le statut Découvert - actuellement non indexé dans le rapport de couverture de l'index de Google comme :
La page a été trouvée par Google, mais pas encore explorée. En règle générale, Google souhaitait explorer l'URL, mais cela devait surcharger le site ; Google a donc reprogrammé l'exploration. C'est pourquoi la date du dernier crawl est vide sur le rapport.source : rapport de couverture de l'index de Google
Tomek Rudzki a recherché les problèmes d'indexation les plus courants affichés dans Google Search Console et a découvert que Discovered - actuellement non indexé est l'un d'entre eux, juste à côté de :
- contenu dupliqué,
- Crawlé - actuellement non indexé,
- 404 souples, et
- Problèmes d'exploration.
Traiter le problème découvert - actuellement non indexé devrait être une priorité car il peut affecter de nombreuses pages et indique que certaines de vos pages n'ont pas été explorées et indexées par la suite.
Ce problème peut être causé par de nombreux facteurs qui, s'ils ne sont pas résolus, peuvent empêcher certaines pages de se retrouver dans l'index de Google. Et si tel est le cas, ils ne vous apporteront pas de trafic organique et ne généreront aucune conversion.
Cet article est une plongée en profondeur dans la section Découvert - actuellement non indexée du rapport de couverture de l'index de la Search Console, en se concentrant sur l'analyse de la raison pour laquelle vos pages y arrivent et sur la façon de résoudre les problèmes qui pourraient en être la cause.
Où trouver le statut Découvert - actuellement non indexé
Découvert - actuellement non indexé est l'un des types de problèmes dans le rapport de couverture de l'index dans Google Search Console. Le rapport affiche les statuts d'exploration et d'indexation des pages de votre site Web.
Découverte – actuellement non indexée apparaît dans la catégorie Exclus , qui inclut les URL que Google n'a pas indexées mais, du point de vue de Google, cette situation n'est pas le résultat d'une erreur.
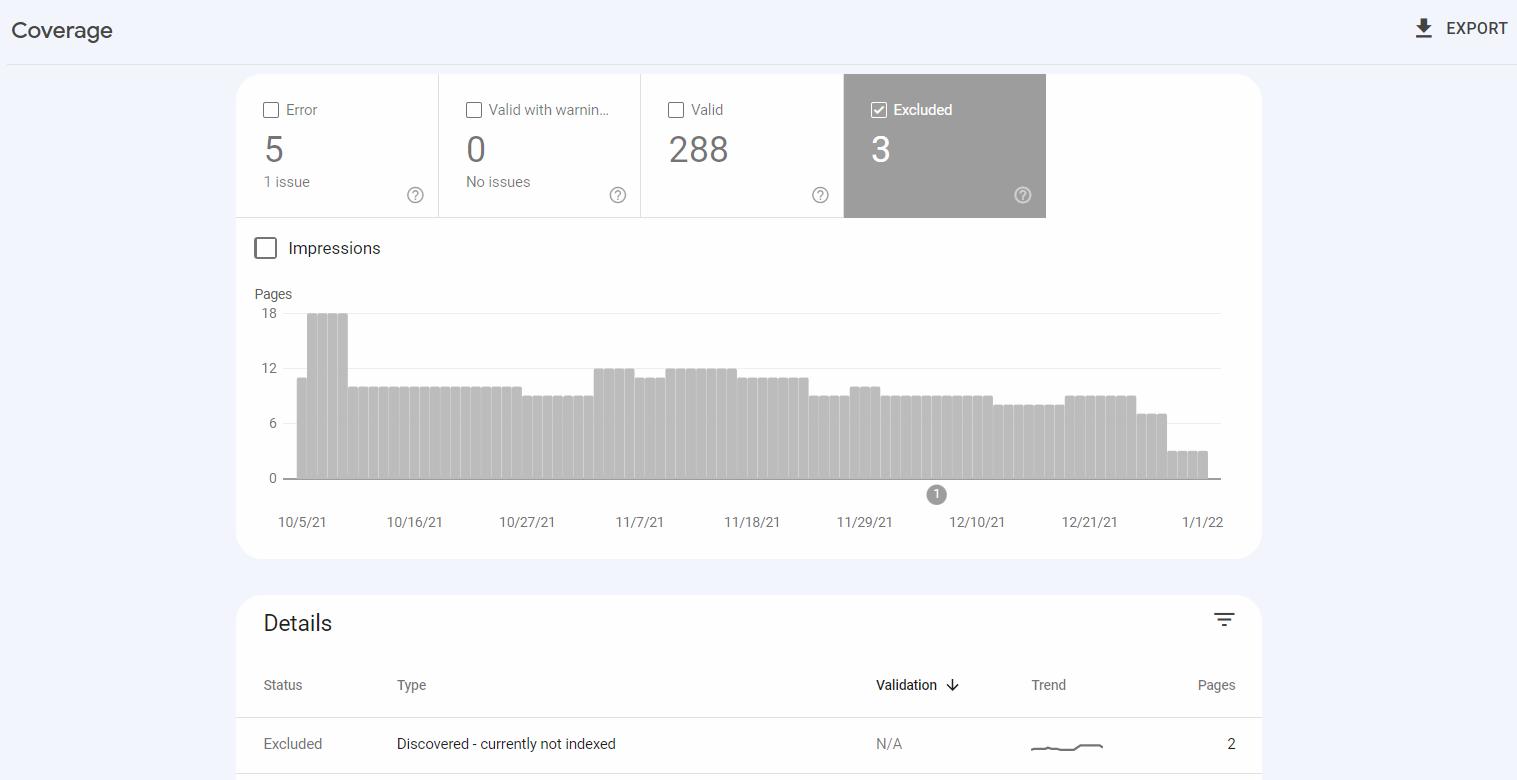
Lorsque vous utilisez Google Search Console, vous pouvez cliquer sur le type de problème pour afficher une liste des URL concernées.
Vous pouvez constater que vous aviez l'intention de garder certaines des URL signalées hors de l'index - et c'est très bien. Mais vous devez surveiller vos pages précieuses - si l'une d'entre elles n'a pas été indexée, vérifiez les problèmes que Google a trouvés.
Découverte, exploration et indexation
Avant de passer aux caractéristiques de Discovered - actuellement non indexé et d'aborder ce problème, clarifions ce qu'il faut pour qu'une URL soit classée sur Google :
- Google doit trouver une URL avant de pouvoir l'explorer. Les URL sont le plus souvent découvertes en suivant des liens internes ou externes, ou des sitemaps XML, qui doivent contenir toutes les pages qui doivent être indexées.
- En explorant les pages, Google les visite et vérifie leur contenu. Google n'a pas les ressources nécessaires pour explorer toutes les pages qu'il trouve - et ce fait est à l'origine de nombreux problèmes d'exploration rencontrés par les sites.
- Lors de l'indexation , Google extrait le contenu des pages et évalue leur qualité. L'indexation est nécessaire pour apparaître dans les résultats de recherche et obtenir du trafic organique de Google. Les pages indexées sont évaluées en fonction de nombreux facteurs de classement , déterminant comment elles sont classées en réponse aux requêtes de recherche saisies par les utilisateurs dans Google.
Se faire indexer par Google est difficile en raison de la capacité limitée de ses ressources, du Web en croissance constante et parce que Google attend un certain niveau de qualité des pages qu'il indexe.
De nombreux facteurs techniques et liés au contenu peuvent jouer un rôle dans le fait que vos pages ne sont pas explorées ou indexées.
Il existe des solutions pour augmenter les chances d'être indexé. Ceux-ci inclus:
- Avoir une stratégie de crawl qui donne la priorité au crawl des parties précieuses de votre site Web,
- Mise en place du maillage interne,
- Créer un sitemap précis contenant toutes les URL qui doivent être indexables, et
- Rédaction de contenu précieux et de qualité.
Assurez-vous de parcourir la documentation de Google - il y a une section sur les directives à suivre pour faciliter l'exploration et l'indexation de vos pages par Google.
Comment utiliser la section de rapport Découvert – actuellement non indexé
Le statut Découvert - actuellement non indexé est l'endroit où aller pour se tenir au courant de tout problème d'exploration potentiel.
Après avoir trouvé les URL dans cette section, vérifiez si elles doivent être explorées en premier lieu.
Si c'est le cas, essayez de trouver un modèle dans les URL qui apparaissent dans le rapport . Cela vous aidera à identifier les aspects de ces URL qui pourraient être à l'origine du problème.
Par exemple, le problème peut concerner des URL dans une catégorie spécifique de produits, des pages avec des paramètres ou celles avec une structure spécifique, les faisant toutes être considérées comme du contenu léger.
Lorsque la section Découvert - actuellement non indexé nécessite une action
Les URL dans Découverte - actuellement non indexées ne vous obligent pas toujours à apporter des modifications à votre site Web.
À savoir, vous n'avez rien à faire si :
- Le nombre d'URL concernées est faible et reste stable dans le temps, ou
- Le rapport contient des URL qui ne doivent pas être explorées ou indexées, par exemple, celles avec des balises canoniques ou "noindex", ou celles dont l'exploration est bloquée dans votre fichier robots.txt.
Mais il est toujours crucial de maîtriser la section de ce rapport.
Les URL nécessitent votre attention si leur nombre augmente, ou s'il s'agit d'URL précieuses que vous vous attendez à classer et à vous apporter un trafic organique important.
L'impact de Discovered - actuellement non indexé sur les petits sites Web par rapport aux grands sites Web
L'impact de la section Découvert - actuellement non indexée peut varier en fonction de la taille d'un site Web.
Si vous avez un site Web plus petit – qui ne dépasse généralement pas 10 000 URL – et que vos pages ont un contenu unique et de bonne qualité, le statut Découvert – actuellement non indexé se résoudra souvent de lui-même. Google ne rencontre peut-être aucun problème, mais n'a tout simplement pas encore exploré les URL répertoriées.
Les petits sites ne sont généralement pas confrontés aux problèmes de budget d'exploration , et une augmentation du nombre de pages signalées peut survenir en raison de problèmes de qualité du contenu ou d'une mauvaise structure de liens internes.
Le statut Découvert – actuellement non indexé peut être particulièrement sévère pour les grands sites (plus de 10 000 URL) et s'appliquer à des milliers, voire des millions d'URL.
Chez Onely, nous avons constaté que les sites Web contenant plus de 100 000 URL souffrent généralement de problèmes d'exploration , souvent dus à un budget d'exploration gaspillé.
Ces problèmes surviennent généralement sur les sites Web de commerce électronique . Ils ont souvent un contenu en double ou léger ou contiennent des produits en rupture de stock ou périmés. Ces pages n'auront généralement pas la qualité nécessaire pour entrer dans la file d'attente d'indexation de Google, sans parler d'être explorées.
Lors du lancement d'un grand site
Si vous venez de lancer un grand site Web, vous pouvez faciliter le travail de Googlebot dès le début.
Si vous souhaitez lancer un gros site, il ne faut pas lancer toute sa structure immédiatement s'il contient de nombreuses pages vides ou inachevées qui ne seront mises à jour que plus tard. Googlebot tombera sur ces pages et les jugera de mauvaise qualité, ce qui présente un risque d'avoir un budget de crawl faible dès le départ. Et cette situation peut même prendre des années à se corriger.
Il est préférable d' ajouter du contenu au fur et à mesure que vous le publiez régulièrement. De cette façon, Googlebot obtient une impression positive de votre qualité dès le début.
Avant de vous lancer, vous devez toujours avoir une stratégie d'indexation et d'exploration en place et savoir quelles pages doivent être visitées par Google.
Causes de la découverte - statut actuellement non indexé et comment les corriger
En règle générale, les URL seront classées comme découvertes - actuellement non indexées en raison de la qualité du contenu, des liens internes ou des problèmes de budget d'exploration.
Voyons pourquoi vous voyez peut-être vos pages avec ce statut et comment y remédier.
Problèmes de qualité du contenu
Google a des seuils de qualité qu'il souhaite que les pages respectent , car il ne peut pas explorer et indexer tout sur le Web.
Google peut considérer certaines pages de votre domaine comme ne méritant pas d'être explorées et les ignorer, en donnant la priorité à d'autres contenus plus précieux. Par conséquent, ces URL peuvent être marquées comme découvertes - actuellement non indexées.
Il convient de noter que le fait d'avoir des URL comme découvertes - actuellement non indexées n'est souvent pas limité aux pages marquées, mais pourrait plutôt être un problème de qualité du contenu à l'échelle du site, comme l'a dit John Mueller . Si Google considère votre site comme étant de mauvaise qualité par rapport à d'autres contenus sur le Web, il peut ignorer l'exploration et l'indexation de vos pages.
Pour commencer à résoudre ce problème, parcourez la liste des URL concernées et assurez-vous que chaque page contient un contenu unique. Le contenu doit satisfaire l'intention de recherche de l'utilisateur et résoudre un problème spécifique.
Je vous recommande de suivre les directives d'évaluation de la qualité que Google suit lors de l'évaluation des sites Web - cela vous aidera à comprendre ce que Google recherche dans le contenu trouvé sur le Web.
En même temps, n'oubliez pas que toutes vos pages ne doivent pas être indexées.
Certaines pages de mauvaise qualité ne doivent pas être indexables , telles que :
- Contenu obsolète (comme les anciens articles de presse),
- Pages générées par un champ de recherche au sein d'un site Web,
- Pages générées en appliquant des filtres,
- contenu dupliqué,
- Contenu généré automatiquement,
- Contenu généré par l'utilisateur.
Il est préférable d'empêcher l'exploration et l'indexation de ces sections dans votre fichier robots.txt.
Pendant les heures de bureau du SEO le 31 décembre 2021, John Mueller a discuté d'apporter des modifications à la qualité d'un site Web comme moyen d'aborder la découverte - actuellement non indexée :
[…] Faire des changements de qualité plus importants sur un site Web prend un peu de temps pour que les systèmes Google détectent cela. […] C'est plutôt quelque chose de l'ordre de plusieurs mois et non de plusieurs jours. […] Parce qu'il faut tellement de temps pour obtenir des changements de qualité, ma recommandation serait de ne pas faire de petits changements et d'attendre et de voir si c'est assez bon, mais plutôt de s'assurer que, si vous faites des changements de qualité importants, […] c'est vraiment des changements de bonne qualité […]. Vous n'avez pas envie d'attendre quelques mois avant de décider : « Oh, oui, j'ai aussi besoin de changer d'autres pages.source : John Muller
Problèmes de liens internes
Googlebot suit les liens internes de votre site pour découvrir d'autres pages et comprendre les liens entre elles. Par conséquent, assurez-vous que vos pages les plus importantes sont fréquemment liées en interne.

Martin Splitt a expliqué pourquoi des structures de liens incorrectes pouvaient être problématiques dans le webinaire Rendering SEO :
[…] Si nous avons environ un millier d'URL de votre part, qui ne sont toutes que dans le plan du site et que nous ne les avons vues dans aucune des autres pages que nous avons explorées, nous pourrions nous dire : « Nous ne savons pas à quel point c'est vraiment' […]. Au lieu de simplement l'avoir dans le plan du site, créez un lien vers celui-ci à partir d'autres endroits de votre site Web afin que lorsque nous explorons ces pages, nous voyons "Aha ! Donc cette page, et cette page, et cette page pointent toutes vers cette page produit, alors peut-être est-elle un peu plus importante que cet autre produit qui ne vit que dans le sitemap' […].source : Martin Splitt
Une bonne liaison interne consiste à connecter vos pages pour créer une structure logique qui aide les moteurs de recherche et les utilisateurs à suivre la hiérarchie de votre site. Les liens internes sont également associés à l'agencement de l'architecture de votre site.
Aider les moteurs de recherche à trouver et à attribuer une importance appropriée à vos pages comprend :
- Décidez quel est votre contenu fondamental et assurez-vous qu'il est lié à d'autres pages,
- Ajouter des liens contextuels dans votre contenu,
- Relier les pages en fonction de leur hiérarchie, par exemple en reliant les pages parents aux pages enfants et vice versa, ou en incluant des liens dans la navigation du site,
- Éviter de placer des liens de manière spam et de trop optimiser le texte d'ancrage,
- Incorporer des liens vers des produits ou des publications connexes.
Vous pouvez également lire cet article sur l'amélioration de la structure des liens internes.
Budget d'exploration
Le budget de crawl est le nombre de pages que Googlebot peut et veut explorer sur un site Web.
Le budget de crawl d'un site est déterminé par :
- Limite de vitesse d'exploration - combien d'URL Google peut explorer, qui est ajustée aux capacités de votre site Web,
- Demande d'exploration - combien d'URL Google souhaite explorer, en fonction de l'importance qu'il accorde aux URL, en examinant leur popularité et la fréquence à laquelle elles sont mises à jour.
Le gaspillage du budget d'exploration peut entraîner une exploration inefficace de votre site Web par les moteurs de recherche. Par conséquent, certaines parties fondamentales de votre site Web peuvent être ignorées.
De nombreux facteurs peuvent être à l'origine de problèmes de budget de crawl, notamment :
- Contenu de mauvaise qualité,
- Mauvaise structure de liaison interne,
- Erreurs dans la mise en œuvre des redirections,
- Serveurs surchargés,
- Sites Web lourds.
Avant d'optimiser votre budget d'exploration, vous devez examiner exactement comment Googlebot explore votre site.
Vous pouvez le faire en naviguant vers un autre outil utile dans la console de recherche - le rapport de statistiques Crawl. Consultez également les journaux de votre serveur pour obtenir des informations détaillées sur les ressources que Googlebot a explorées et sur celles qu'il a ignorées.
Vous trouverez ci-dessous 5 aspects que vous devriez examiner pour optimiser votre budget de crawl et amener Google à explorer certaines des pages découvertes – actuellement non indexées sur votre site :
Contenu de mauvaise qualité
Si Googlebot peut explorer librement des pages de mauvaise qualité, il n'a peut-être pas les ressources nécessaires pour accéder aux éléments précieux de votre site Web.
Pour empêcher les robots d'exploration des moteurs de recherche d'explorer certaines pages, appliquez les directives appropriées dans le fichier robots.txt.
Vous devez également vous assurer que votre site Web dispose d'un sitemap correctement optimisé qui aide Googlebot à découvrir des pages uniques et indexables sur votre site et à remarquer les modifications qui y sont apportées.
Le plan du site doit contenir :
- URL répondant avec 200 codes de statut,
- URL sans balises meta robots les empêchant d'être indexées, et
- Uniquement les versions canoniques de vos pages.
Mauvaise structure de liaison interne
Si Google ne trouve pas suffisamment de liens vers une URL, il peut ignorer son exploration en raison de signaux insuffisants indiquant son importance.
Suivez mes directives décrites dans le sous-chapitre "Problèmes de liens internes".
Erreurs dans la mise en œuvre des redirections
La mise en œuvre de redirections peut être bénéfique pour votre site, mais uniquement si elle est effectuée correctement. Chaque fois que Googlebot rencontre une URL redirigée, il doit envoyer une requête supplémentaire pour accéder à l'URL de destination, ce qui nécessite plus de ressources.
Assurez-vous de respecter les meilleures pratiques pour la mise en œuvre des redirections. Vous pouvez rediriger à la fois les utilisateurs et les robots à partir de pages d'erreur 404 qui ont été liées à partir de sources externes vers des pages de travail, ce qui vous aidera à préserver les signaux de classement.
Assurez-vous cependant de ne pas créer de liens vers des pages redirigées , mettez-les plutôt à jour afin qu'elles pointent vers les pages correctes. Vous devez également éviter les boucles et les chaînes de redirection.
Problèmes de serveur
Google peut rencontrer des problèmes d'exploration car votre site semble être surchargé. Cela se produit parce que le taux d'exploration, qui a un impact sur le budget d'exploration, est ajusté aux capacités de votre serveur.
Dans un webinaire sur le rendu SEO , Martin Splitt a discuté des problèmes de serveur concernant l'exploration des pages par Google :
[…] Une chose que je vois arriver assez souvent, c'est que les serveurs donnent des erreurs intermittentes - en particulier, 500 quelque chose - et tout ce à quoi votre serveur répond avec un 500, 501, 502, 504, peu importe, signifie que votre serveur dit 'Hold on , j'ai un problème ici' […], et il pourrait tomber à tout moment, alors nous reculons. Chaque fois que nous reculons et que votre serveur répond positivement, nous reprenons généralement lentement. Imaginez avoir une réponse de 500 quelque chose chaque jour.On le voit, on recule un peu, on accélère – on le revoit […]. Vous devriez vérifier si votre serveur répond négativement.
source : Martin Splitt
Vérifiez auprès de votre fournisseur d'hébergement s'il y a des problèmes de serveur sur votre site.
Les problèmes de serveur peuvent également être causés par de mauvaises performances Web. Pour en savoir plus, lisez notre article sur les performances Web et le budget de crawl.
Sites Web lourds
Les problèmes d'exploration peuvent être causés par certaines pages trop lourdes. Google peut simplement ne pas disposer de ressources suffisantes pour les explorer et les afficher.
Chaque ressource que Googlebot doit récupérer pour afficher votre page compte dans votre budget d'exploration. Dans ce cas, Google voit une page mais la pousse plus loin dans la file d'attente prioritaire.
Vous devez optimiser les fichiers JavaScript et CSS de votre site pour réduire l'impact négatif de votre code.
Avoir un nouveau site web
Tomek Rudzki a créé un sondage Twitter dans lequel il a interrogé la communauté SEO sur les problèmes d'indexation sur les nouveaux sites. Et, selon les résultats du sondage, près de 40 % des personnes rencontraient de tels problèmes :
Avez-vous rencontré des problèmes avec l'indexation des nouveaux sites Web RÉCEMMENT ?
– Tomek Rudzki (@TomekRudzki) 7 décembre 2021
Au cours de l'une des sessions SEO Office Hours, un participant a présenté son nouveau site Web qui a été lancé il y a 2 mois, où de nombreuses pages étaient marquées comme découvertes - actuellement non indexées. Il a ensuite demandé combien de temps les pages devraient apparaître avec ce statut, ce à quoi John a répondu :
Cela peut être pour toujours […]. Et surtout avec un site Web plus récent, si vous avez beaucoup de contenu, je suppose que l'on s'attend à ce qu'une grande partie du nouveau contenu soit découvert pendant un certain temps et non indexé. Et puis avec le temps, généralement, ça change. Et c'est comme, eh bien, c'est en fait exploré ou en fait indexé quand nous voyons qu'il est en fait utile de se concentrer davantage sur le site Web lui-même.source : John Muller
En règle générale, il n'y a pas de solutions rapides pour indexer les pages, mais l'examen des aspects SEO que j'ai décrits précédemment peut vous aider à avoir une meilleure chance de les faire indexer.
Il est clair que Google veut être sûr qu'il n'indexe que du contenu de haute qualité et ces seuils de qualité semblent augmenter. Mais cela est particulièrement difficile pour les nouveaux sites Web qui doivent prouver à Google, à maintes reprises, que leur contenu mérite d'être dans l'index.
Informations supplémentaires sur l'adressage Découvert - actuellement non indexé
Pendant les heures de bureau SEO, John Mueller a été interrogé sur la résolution du problème d'environ 99 % des URL d'un site Web bloquées dans la section de rapport Découvert - actuellement non indexé.
Les recommandations de John tournaient autour de trois étapes principales :
[…] Je voudrais peut-être tout d'abord regarder […] que vous ne générez pas accidentellement des URL avec des modèles d'URL différents, […] des choses comme les paramètres que vous avez dans votre URL, majuscules minuscules, toutes ces choses peuvent conduire essentiellement dupliquer le contenu . Et si nous avons découvert un grand nombre de ces URL en double, nous pourrions penser que nous n'avons pas vraiment besoin d'explorer tous ces doublons car nous avons déjà une variante de cette page […]. Assurez-vous que depuis le maillage interne, tout est ok. Que nous puissions parcourir toutes ces pages de votre site Web et aller jusqu'au bout. Vous pouvez tester cela à peu près en utilisant un outil d'exploration ou quelque chose comme Screaming Frog ou Deep Crawl . […] Ils vous diront essentiellement s'ils sont capables d'explorer votre site Web et vous montreront les URL qui ont été trouvées lors de cette exploration. Si cette exploration fonctionne, je me concentrerais fortement sur la qualité de ces pages . Si vous parlez d'environ 20 millions de pages et que 99 % d'entre elles ne sont pas indexées, nous n'indexons qu'une très petite partie de votre site Web. […] Peut-être que cela a du sens de dire : 'Eh bien, et si je réduisais le nombre de pages de moitié ou peut-être même […] à 10 % du nombre actuel'. […] Vous pouvez généralement améliorer un peu la qualité du contenu en ayant un contenu plus complet sur ces pages. Et pour nos systèmes, c'est un peu plus facile de regarder ces pages et de dire : « Eh bien, ces pages […] ont l'air plutôt bien. Nous devrions partir, explorer et indexer beaucoup plus ».source : John Muller
Lors d'une autre session des heures de bureau le 18 février 2022, John a de nouveau été interrogé sur un grand nombre d'URL apparemment bloquées comme "découvertes - actuellement non indexées".
Et John a dit qu'il est souvent normal d'avoir beaucoup de pages avec ce statut :
[…] Dans une certaine mesure, j'accepterais simplement que Google ne puisse pas tout explorer et tout indexer. […] Si vous reconnaissez, par exemple, que […] des produits individuels ne sont pas explorés et indexés, assurez-vous qu'au moins la page de catégorie de ces produits est explorée et indexée. Parce que de cette façon, les gens peuvent toujours trouver du contenu pour ces produits individuels sur votre site Web […].source : John Muller
Les membres de la communauté SEO ont signalé une augmentation du nombre de pages marquées comme découvertes - actuellement non indexées depuis des mois. Certains testent des solutions alternatives pour résoudre ce problème.
Dan Shure a décidé de le tester en déplaçant le contenu bloqué vers différentes URL, ce qui a entraîné leur indexation.
Il semble donc possible que beaucoup de ces pages restent simplement bloquées après avoir été initialement laissées avec ce statut.
Découvert - actuellement non indexé vs. Crawlé - actuellement non indexé
Ces deux statuts se confondent souvent et, bien qu'ils soient liés, ils signifient des choses différentes.
Dans les deux cas, les URL n'ont pas été indexées mais, avec Crawled – actuellement non indexé, Google a déjà visité la page . Avec Découverte - actuellement non indexée, la page a été trouvée par Google mais n'a pas été explorée.
Exploré - actuellement indexé est souvent causé par un retard d'indexation, des problèmes de qualité du contenu, des problèmes d'architecture du site ou une page pourrait avoir été désindexée.
Nous avons également un article détaillé qui explique comment réparer Crawled - actuellement non indexé.
Emballer
Découvert - actuellement non indexé a tendance à être causé par des problèmes de qualité de page et de budget d'exploration.
Pour résoudre ces problèmes et aider Google à explorer vos pages de manière efficace et précise à l'avenir, vous devrez peut-être passer en revue de nombreux aspects de vos pages et les optimiser.
Voici quelques éléments principaux qui peuvent aider à éviter les problèmes avec les pages découvertes - actuellement non indexées :
- Utilisez robots.txt pour empêcher Googlebot d'explorer les pages de mauvaise qualité, en se concentrant sur le contenu en double, par exemple, les pages générées par des filtres ou des champs de recherche sur votre site.
- Prenez le temps de créer un sitemap approprié que Google pourra utiliser pour découvrir vos pages.
- Gardez l'architecture de votre site intacte et assurez-vous que vos pages cruciales sont liées en interne.
- Ayez une stratégie d'indexation en place pour prioriser les pages qui sont les plus précieuses pour vous.
- Optimisez en tenant compte du budget de crawl.