
Cum să remediați „Crawled – Momentan neindexat” în Google Search Console
Publicat: 2021-12-28Documentația Google definește statutul Crawled – momentan nu este indexat ca:
Pagina a fost accesată cu crawlere de Google, dar nu a fost indexată. Poate fi sau nu indexat în viitor; nu este nevoie să retrimiteți această adresă URL pentru accesare cu crawlere.sursa: Google
Citirea acestei explicații poate fi frustrantă, mai ales dacă starea afectează o pagină importantă pentru afacerea dvs. Definiția Google nu clarifică ce s-a întâmplat și ce ați putea face în continuare. Tot ce spune este că Googlebot a accesat cu crawlere pagina dvs., dar, din anumite motive, a decis să nu o indexeze.
Conform cercetării noastre, starea Crawled – moment neindexat este cea mai frecventă problemă raportată în raportul Index Coverage. Înseamnă că probabil ați experimentat-o deja sau probabil că o veți experimenta în viitor.
Este esențial să remediați problema cât mai curând posibil. La urma urmei, dacă pagina ta nu este indexată, nu va apărea în rezultatele căutării și nu va primi trafic organic de la Google.
Acest articol prezintă cauzele posibile pentru starea Crawled – în prezent nu este indexată și modalități de remediere a acestora .
Unde puteți găsi starea Crawled – moment neindexat?
Puteți găsi starea în raportul Acoperirea indexului și Instrumentul de inspecție URL din Google Search Console.
Raport de acoperire a indexului
Accesat cu crawlere – momentan neindexat aparține categoriei „Exclus”, ceea ce indică faptul că Google nu crede că este o greșeală faptul că pagina nu este indexată.
Aceste pagini nu sunt de obicei indexate și considerăm că este potrivit. Aceste pagini fie sunt duplicate ale paginilor indexate, fie sunt blocate de la indexare de către un mecanism de pe site-ul dvs. sau nu sunt indexate în alt mod dintr-un motiv pe care îl considerăm că nu este o eroare.sursa: Google
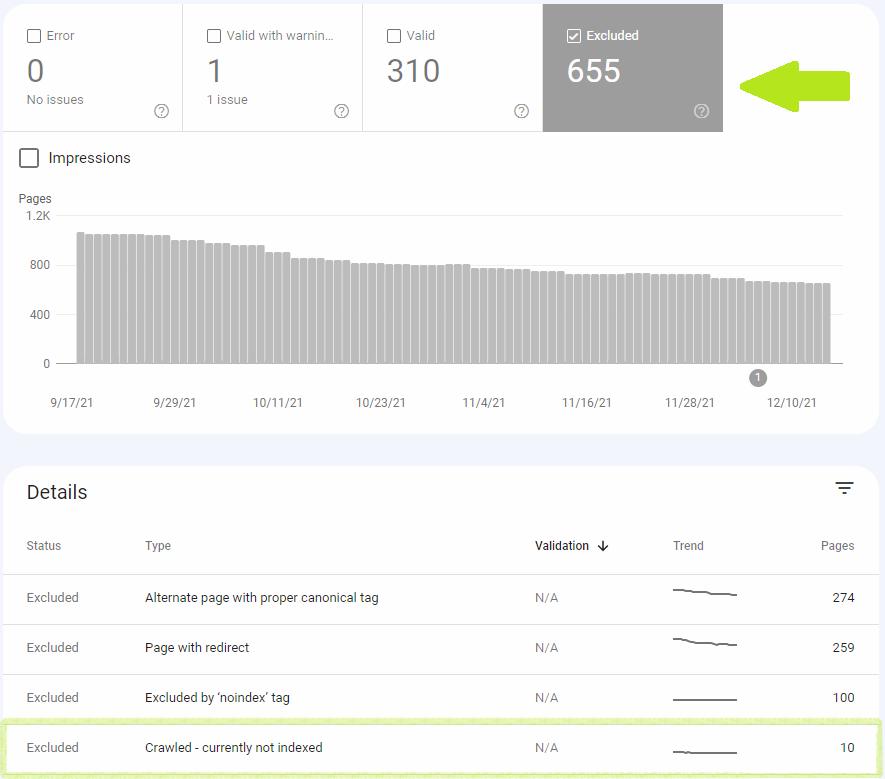
După ce faceți clic pe starea Accesat cu crawlere – momentan neindexat, veți vedea o listă de adrese URL afectate. Ar trebui să îl examinați și să acordați prioritate remedierii problemei pentru paginile cele mai valoroase pentru dvs.
Raportul este disponibil și pentru export. Cu toate acestea, puteți exporta numai până la 1000 de adrese URL. Dacă sunt afectate mai multe pagini, puteți crește numărul de adrese URL exportate prin filtrarea paginilor specifice sitemap-urilor. De exemplu, dacă aveți două sitemap-uri, fiecare cu 1000 de adrese URL, le puteți exporta pe amândouă separat.
Instrument de inspecție URL
Instrumentul de inspecție a adreselor URL din Google Search Console vă poate informa și despre adresele URL care sunt accesate cu crawlere – momentan neindexate.
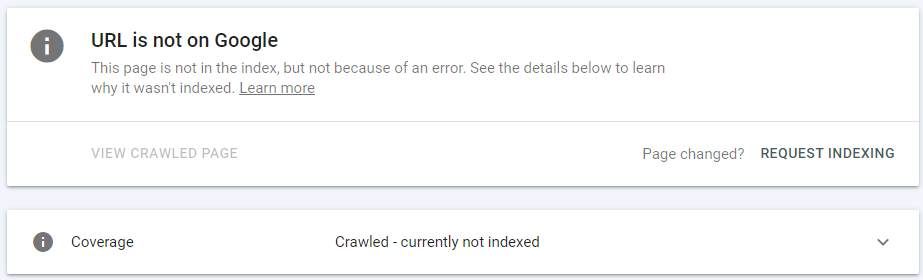
Secțiunea de sus a instrumentului vă informează dacă adresa URL poate fi găsită pe Google sau nu. Dacă adresa URL inspectată aparține categoriei Excluse din raportul Acoperirea indexului, Instrumentul de inspecție URL va raporta următoarele: „Pagina nu este în index, dar nu din cauza unei erori”.
Mai jos, puteți găsi informații mai specifice despre starea actuală de acoperire a adresei URL inspectate – în cazul de mai sus, adresa URL a fost accesată cu crawlere – momentan neindexată.
Raportarea erorilor: pagina dvs. ar putea fi de fapt indexată
După ce ați observat starea Crawled – moment neindexată, primul lucru pe care ar trebui să-l faceți este să investigați dacă pagina dvs. nu este într-adevăr indexată.
Nu este neobișnuit să vezi o pagină marcată ca accesată cu crawlere – momentan neindexată în raportul Acoperirea indexului, în timp ce instrumentul de inspecție URL indică faptul că pagina este de fapt indexată.
Instrumentul de inspecție URL vă permite să verificați detalii despre o anumită adresă URL, inclusiv:
- Probleme de indexare,
- erori de date structurate,
- Utilizabilitate pe mobil,
- Vizualizați resursele încărcate (de exemplu, JavaScript).
De asemenea, puteți solicita indexarea unei adrese URL sau puteți vedea o versiune redată a unei pagini.
John Muller de la Google a abordat problema cu diferențele dintre raportul de acoperire a indexului și instrumentul de inspecție URL în timpul programului de lucru SEO al Google:
Am văzut recent câteva fire ca acesta pe Twitter în care oamenii au văzut adrese URL care au fost semnalate ca neindexate în Search Console. Și apoi, când le verificați individual, sunt de fapt indexate. Nu știu încă exact ce se întâmplă acolo. […] Bănuiala mea este că este mai degrabă o chestiune de timp – le arătăm în raportul Search Console, iar apoi sunt indexate în timp. Apoi, la un moment dat, vor renunța din nou la raport. Și din orice motiv, abandonul școlar durează puțin mai mult decât ar trebui.sursa: John Mueller
După cum a spus John, ar putea fi pur și simplu o problemă de întârziere și sincronizare a datelor între aceste două instrumente, iar starea ar putea fi actualizată în raportul de acoperire a indexului în timp.
Cu toate acestea, nu este întotdeauna doar o întârziere. Uneori este o eroare de raportare.
În septembrie, am observat că unele dintre articolele noastre indexate raportau Crawled – momentan neindexate.
Cu GSC, puteți verifica care dintre paginile dvs. sunt accesate cu crawlere, dar încă nu sunt indexate de Google.
GSC a enumerat câteva dintre articolele noastre ca fiind accesate cu crawlere – momentan neindexate.
Cu toate acestea, instrumentul de inspecție URL le arată ca fiind indexate.
Și sunt de fapt indexați.
Ceva informații, #SEOTwitter? pic.twitter.com/xKv0IYpGLa
— Onely (@OnelyCom) 16 septembrie 2021
Cu siguranță nu a fost o problemă de întârziere, deoarece articolele vechi au fost și ele afectate.
La scurt timp după, alți SEO, inclusiv Lily Ray, au început să observe această problemă.
Alții au scris deja pe Twitter despre asta, dar văd multe exemple de adrese URL în raportul GSC „Crawled, Not Indexed” (cu date recente de accesare cu crawlere) care sunt, de fapt, adrese URL indexate.
Inspectarea adreselor URL individuale duce adesea la mesajul de mai jos.
Gânduri @danielwaisberg @googlesearchc? pic.twitter.com/i1XfcvldEq
— Lily Ray (@lilyraynyc) 28 septembrie 2021
Ce să faci în această situație? În ce raport de încredere?
În general , instrumentul de inspecție URL arată mai multe date actualizate decât raportul Acoperire index. De aceea, ar trebui să aveți întotdeauna mai multă încredere în instrumentul de inspecție URL atunci când sunteți forțat să alegeți între aceste rapoarte.
Cauze și soluții pentru starea Crawled – moment neindexată
Acum, să ajungem la fundul problemei – ce cauzează apariția stării și ce puteți face pentru a o remedia.
Google nu vă oferă un răspuns clar de ce pagina dvs. a fost accesată cu crawlere, dar nu a fost indexată, dar există câteva motive posibile pentru care starea poate apărea, inclusiv:
- Întârziere de indexare,
- Pagina nu respectă standardele de calitate,
- Pagina a fost deindexată,
- Problemă de arhitectură a site-ului web,
- Probleme de conținut duplicat.
Întârziere de indexare
Nu este neobișnuit ca Google să viziteze o pagină, dar durează ceva timp pentru ao indexa. Internetul este infinit de mare, iar Google trebuie să prioritizeze paginile care sunt indexate mai întâi.
În arătat cât timp este nevoie pentru ca paginile de pe site-uri web populare să fie indexate. Iată câteva dintre rezultatele investigației mele:
- Google indexează doar 56% dintre adresele URL indexabile după 1 zi de la publicare.
- După 2 săptămâni, doar 87% dintre adresele URL sunt indexate.
sursa: Tomek Rudzki
Dacă tocmai ți-ai publicat pagina, ar putea fi perfect normal ca aceasta să nu fie indexată încă și trebuie să aștepți puțin mai mult ca Google să indexeze conținutul tău.
Soluţie
Nu puteți influența accesarea cu crawlere și indexarea paginii dvs. pe termen scurt, dar există câteva lucruri pe care le puteți face pentru a vă ajuta site-ul pe termen lung:
- Creați o strategie de indexare pentru a ajuta Google să prioritizeze paginile potrivite de pe site-ul dvs. Pentru a face acest lucru, trebuie să decideți ce pagini trebuie indexate și cea mai bună metodă de a le comunica la Google.
- Asigurați-vă că există legături interne către paginile care vă interesează. Acesta va ajuta Google să găsească paginile și să învețe mai multe despre contextul acestora.
- Creați un sitemap bine optimizat. Este un simplu fișier text care listează adresele URL valoroase. Google îl va folosi ca foaie de parcurs pentru a găsi paginile mai rapid.
Pagina nu respectă standardele de calitate
Google nu poate indexa toate paginile de pe Internet. Spațiul său de stocare este limitat și de aceea trebuie să filtreze conținutul de calitate scăzută.

Scopul Google este de a oferi pagini de cea mai înaltă calitate care să răspundă cel mai bine intenției utilizatorilor. Înseamnă că, dacă o pagină este de calitate inferioară, cel mai probabil Google o va ignora pentru a lăsa spațiul de stocare disponibil pentru conținut de calitate superioară. Și ne putem aștepta ca standardele de calitate să devină doar mai stricte în viitor.
Soluţie
În calitate de proprietar de site, ar trebui să vă asigurați că pagina dvs. oferă conținut de înaltă calitate. Verificați dacă este probabil să satisfacă intenția utilizatorilor dvs. și adăugați conținut de bună calitate dacă este necesar. Google oferă o listă de întrebări pentru a vă ajuta să determinați valoarea conținutului dvs. Aici sunt câțiva dintre ei:
- Conținutul oferă informații originale, raportări, cercetări sau analize?
- Conținutul oferă o analiză perspicace sau informații interesante care sunt dincolo de evidente?
- Este acesta genul de pagină pe care ați dori să o marcați, să o distribuiți unui prieten sau să o recomandați?
- Dacă conținutul se bazează pe alte surse, evită pur și simplu copierea sau rescrierea acelor surse și, în schimb, oferă o valoare suplimentară substanțială și originalitate?
sursa: Google
În plus, puteți folosi sfaturi privind conținutul de calitate din Ghidul Google pentru evaluatorii de calitate. Chiar dacă documentul este destinat în principal evaluatorilor de calitate a căutării pentru a evalua calitatea unui site web, webmasterii îl pot folosi pentru a obține câteva informații despre cum să-și îmbunătățească propriile site-uri. Dacă doriți să aflați mai multe, consultați ghidul nostru privind Ghidul evaluatorilor de calitate.
Conținut generat de utilizatori
Conținutul generat de utilizatori ar putea fi o problemă din punct de vedere al calității.
De exemplu, să presupunem că aveți un forum și cineva pune o întrebare. Chiar dacă ar putea exista multe răspunsuri valoroase în viitor, în momentul accesării cu crawlere, nu a existat niciunul, așa că Google poate clasifica pagina drept conținut de calitate scăzută.
Ce să faci pentru a te proteja de această situație?
Quora a venit cu o strategie excelentă pentru problema. Fiecare întrebare fără răspuns are prefixul „/fără răspuns/” în adresa URL.
Iată un exemplu: https://www.quora.com/unanswered/Are-you-really-happy-with-your-results
Fișierul robots.txt blochează toate paginile cu /unanswered/ în adresele URL. Înseamnă că Googlebot nu le poate accesa cu crawlere.
Odată ce există un răspuns la întrebare, adresa URL se modifică și devine disponibilă pentru accesare cu crawlere. În acest fel, Quora blochează accesul la conținutul de calitate scăzută generat de utilizatori.
Pagina a fost deindexată
O adresă URL poate suferi de starea Crawled – în prezent nu este indexată, deoarece a fost indexată în trecut, dar Google a decis să o deindexeze în timp.
Dacă vă întrebați de ce unele lucruri ar putea dispărea din index, este posibil ca acestea să fie doar înlocuite cu conținut de calitate superioară.
Selectarea indexului, deși este în mare parte despre spațiu (RAM/flash/disc), este strâns legată de calitatea conținutului. Dacă avem tone de spațiu liber disponibil, este mai probabil să indexăm conținut mai prost. Dacă nu o facem, s-ar putea să deindexăm lucrurile pentru a face spațiu pentru documente de calitate superioară. pic.twitter.com/jRMkEqdft0
– Gary 鯨理/경리 Illyes (@methode) 15 mai 2020
În plus, ar trebui să acordați atenție actualizărilor algoritmilor. Este posibil să fie lansat un nou algoritm, iar pagina dvs. să fi fost afectată de acesta.
Din păcate, deindexarea ar putea fi cauzată și de o eroare din partea Google. De exemplu, Search Engine Land a fost deindexat odată, deoarece Google a presupus în mod greșit că site-ul a fost piratat.
Soluţie
Soluția pentru paginile deindexate este strâns legată de calitatea acesteia. Ar trebui să vă asigurați întotdeauna că pagina dvs. oferă conținut de cea mai bună calitate și este actualizată. Nu presupuneți că, odată ce o pagină este indexată, nu mai trebuie să faceți nimic cu ea. Monitorizați-l în continuare și implementați modificări și îmbunătățiri dacă este necesar.
[…]paginile care cad după o actualizare de bază nu au nimic greșit de remediat. Acestea fiind spuse, înțelegem că cei care se descurcă mai puțin bine după o modificare a actualizării de bază pot simți în continuare că trebuie să facă ceva. Vă sugerăm să vă concentrați pe a vă asigura că oferiți cel mai bun conținut posibil. Asta caută să recompenseze algoritmii noștri.sursa: Google
După remedierea problemelor, puteți trimite acele adrese URL la Google Search Console pentru a ajuta Google să observe modificările mai repede.
Problemă de arhitectură a site-ului web
Când John Mueller a fost întrebat despre posibilele motive pentru care o pagină a fost marcată cu starea Crawled – în prezent neindexată, el a menționat o altă cauză posibilă – structura defectuoasă a site-ului.
Nu puteți forța paginile să fie indexate — este normal ca noi să nu indexăm toate paginile de pe toate site-urile web. Nu este o problemă cu „acea pagină”, ci mai mult la nivelul întregului site. Crearea unei structuri bune de site și asigurarea faptului că site-ul este de cea mai înaltă calitate posibilă este în esență direcția.
— johnmu.xml (personal) (@JohnMu) 28 iunie 2021
Să ne imaginăm o situație în care aveți o pagină de bună calitate, dar singurul mod în care Google a găsit-o este pentru că ați pus-o în sitemap-ul dvs.
Google ar putea să se uite la pagina și să o acceseze cu crawlere, dar, deoarece nu există legături interne, ar presupune că pagina are o valoare mai mică decât alte pagini. Nu există informații semantice sau structurale care să o ajute să evalueze pagina. Acesta ar putea fi unul dintre motivele pentru care Google a decis să se concentreze pe alte pagini și să o lase pe aceasta în afara indexului după ce a accesat-o cu crawlere.
Soluţie
Arhitectura bună a site-ului este cheia pentru a vă ajuta să maximizați șansele de a fi indexat. Le permite roboților motoarelor de căutare să vă descopere conținutul și să înțeleagă mai bine relația dintre pagini.
De aceea, este esențial să oferiți o arhitectură bună a site-ului web și să vă asigurați că există legături interne către pagina pe care doriți să fie indexată.
Dacă doriți să aflați mai multe despre structura site-ului web, consultați articolul nostru despre Cum să construiți un site web care se clasează și face conversie.
Conținut duplicat
Adam Gent, un freelancer SEO, a împărtășit un caz interesant comunității SEO. Pagina sa raporta accesat cu crawlere – momentan nu este indexată, deoarece Google credea că este o pagină duplicată.
Google dorește să prezinte utilizatorilor conținut unic și valoros. De aceea, atunci când își dă seama în timpul accesării cu crawlere că unele pagini sunt identice sau aproape identice, s-ar putea să indexeze doar una dintre ele.
De obicei, celălalt este etichetat ca „Duplicat” în raportul Acoperirea indexului. Cu toate acestea, nu este întotdeauna cazul și, uneori, Google atribuie statutul Crawled - momentan neindexat.
Nu este complet clar de ce Google ar putea alege Crawled – momentan nu este indexat față de un statut dedicat pentru conținut duplicat. Una dintre explicațiile posibile este că starea se va schimba mai târziu după ce Google decide dacă există una mai potrivită pentru pagină.
O altă opțiune ar putea fi o eroare de raportare . Google ar putea pur și simplu să facă o greșeală în timp ce atribuie stările. Din păcate, situația este mai dificilă, deoarece Crawled – în prezent neindexat nu vă oferă atât de multe informații ca o stare dedicată pentru conținut duplicat.
Cum să verificați dacă o pagină duplicată apare în rezultatele căutării?
- Accesați pagina care nu este indexată și copiați un fragment de text aleatoriu.
- Lipiți textul în Căutarea Google între ghilimele.
- Analizați rezultatele. Dacă apare o adresă URL diferită cu textul dvs. copiat, poate însemna că pagina dvs. nu este indexată, deoarece Google a ales o adresă URL diferită pentru indexare.
Soluţie
În primul rând, trebuie să vă asigurați că creați pagini originale. Dacă este necesar – adăugați conținut unic.
Din păcate, conținutul duplicat ar putea fi inevitabil (de exemplu, aveți o versiune pentru mobil și desktop). Nu aveți prea mult control asupra a ceea ce apare în rezultatele căutării, dar puteți oferi Google câteva indicii despre versiunea originală.
Dacă observați mult conținut duplicat indexat, evaluați următoarele elemente:
- Etichete canonice – aceste etichete HTML le spun motoarelor de căutare care versiuni sunt cele originale.
- Link-uri interne – asigurați-vă că linkurile interne indică către conținutul dumneavoastră original. Google ar putea să-l folosească ca un indicator al paginii care este mai importantă.
- Sitemaps XML – asigurați-vă că numai versiunea canonică este în harta dvs. site.
Rețineți că acestea sunt doar indicii, iar Google nu este obligat să le urmeze. În cazul descris de Adam Gent, Google a ales versiunea de feed RSS pentru a indexa, chiar dacă multe semnale de canonizare au indicat o adresă URL originală diferită. Adam a rezolvat problema instalând un 404 pentru a se asigura că rămâne doar versiunea originală. De asemenea, el a sugerat că configurarea unui antet HTTP X-roboți pe toate adresele URL de feed ar împiedica indexarea acestora.
Accesat cu crawlere – momentan neindexat vs. Descoperit – momentan neindexat
Statutul Crawled – moment neindexat este de obicei confundat cu o altă problemă de indexare din raportul Index Coverage: Descoperit – momentan neindexat.
Ambele stări indică faptul că pagina nu este indexată. Cu toate acestea, în cazul Crawled – momentan neindexat, Google a vizitat deja pagina. Între timp, în Discovered – momentan neindexat, adresa URL este cunoscută de Google, dar, din anumite motive, nu a fost încă accesată cu crawlere.
| Accesat cu crawlere – momentan nu este indexat | Descoperit – momentan nu este indexat | |
| Pagina descoperită de Google | da | da |
| Pagina vizitată de Google | da | Nu |
| Pagina indexată | Nu | Nu |
Unele dintre motivele pentru aceste stări pot fi similare, inclusiv paginile de proastă calitate și problemele de legături interne. Cu toate acestea, când vedeți o stare Descoperit - momentan neindexat, trebuie să investigați suplimentar de ce Google nu a putut sau nu a dorit să acceseze pagina. De exemplu, ar putea indica probleme cu calitatea generală a întregului site web, probleme legate de bugetul de accesare cu crawlere sau supraîncărcarea serverului.
Încheierea
Accesat cu crawlere – momentan neindexat este asociat în principal cu calitatea paginii, dar, în realitate, poate indica mult mai multe probleme, cum ar fi arhitectura site-ului sau conținut duplicat.
Iată principalele concluzii din articol care vă pot ajuta să vă ocupați de starea Crawled – momentan neindexată:
- Adăugați conținut unic și valoros paginilor dvs. După ce ați făcut-o, trimiteți acele adrese URL la Google Search Console. În acest fel, Google poate observa modificări mai repede.
- Examinați arhitectura site-ului dvs. și asigurați-vă că există legături interne către paginile dvs. valoroase.
- Decideți ce pagini ar trebui și nu ar trebui să fie indexate pentru a ajuta Google să prioritizeze cele mai valoroase adrese URL.
Dacă aveți nevoie de ajutor pentru a aborda starea Crawled — momentan neindexată pe site-ul dvs., serviciile noastre tehnice SEO sunt ceea ce căutați.