
Google uită de adresele URL din coada de indexare
Publicat: 2021-12-21Bug-urile de indexare nu sunt nemaiauzite. Google are probleme cu indexarea de ceva timp. Se pot întâmpla oricui fără vina proprietarului site-ului, indiferent de dimensiunea site-ului. Chiar anul trecut, a existat un caz de erori de indexare care implică indexarea și canonizarea dispozitivelor mobile.
Cu câteva luni în urmă, m-am confruntat personal cu o eroare de indexare când s-a dovedit că Ghidul meu definitiv pentru indexarea SEO nu era indexat.
După o cercetare amănunțită, am aflat că Google a indexat versiunea greșită a adresei URL fără un motiv aparent. Puteți afla mai multe despre această eroare în articolul meu Ghidul meu definitiv pentru indexarea SEO nu este indexat.
La începutul acestui an, am găsit o altă eroare de indexare, care indică faptul că Google ar putea pierde urma URL-urilor din coada de indexare.
Să o descompunem pas cu pas.
Adresa URL uitată în coada de indexare Google
Pe 6 octombrie, am publicat un articol: Rendering SEO: How Google Digest Your Content. Articolul a fost o transcriere a unei conversații dintre Bartosz Goralewicz de la Onely, Martin Splitt de la Google și Jason Barnard de la Kalicube.
Din păcate, în cele trei săptămâni de la data publicării, articolul nu a adus trafic de la Google.
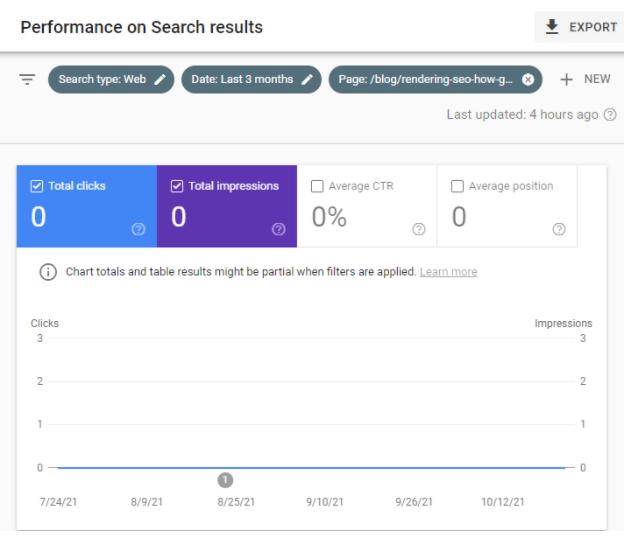
Mi s-a părut ciudat - un alt articol interesant neindexat de Google? Google suferă de altă eroare de indexare?
Deoarece mă străduiesc să înțeleg dezavantajele procesului de indexare Google, am decis să fac o mică investigație.
Am verificat ce a avut de spus Google Search Console despre această adresă URL.
GSC a declarat că această adresă URL a fost „Descoperită – momentan nu este indexată”.
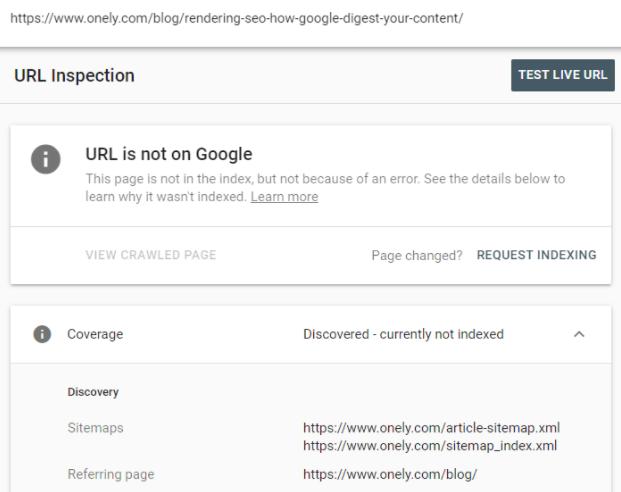
Când te uiți în documentația Google, vei găsi următoarea explicație a stării:
Descoperit – momentan neindexat: pagina a fost găsită de Google, dar încă nu a fost accesată cu crawlere.sursa: Google
Starea URL-ului părea foarte improbabilă. Nu-mi venea să cred că Google nu a accesat cu crawlere această pagină în decurs de trei săptămâni de la publicare pe un site relativ mic.
Deci, am verificat jurnalele serverului nostru.
Jurnalele de server vă permit să examinați traficul care vine pe site-ul dvs. web. Acestea conțin informații despre fiecare solicitare, inclusiv ora și data acesteia, șirul user-agent, adresa IP etc. Datorită acestor informații, am putut vedea dacă (și când) Googlebot se afla pe această pagină.
În mod surprinzător, am descoperit că Googlebot a vizitat pagina în ziua în care am publicat articolul!
În acest moment, aveam două informații esențiale:
- Datele din Google Search Console conform cărora Googlebot nu vizitase încă pagina nu erau adevărate. Jurnalele de server au dovedit că Googlebot a vizitat adresa URL în ziua publicării articolului.
- Nu a fost doar o eroare de raportare din Google Search Console. Pagina nu a primit trafic organic, așa că au existat în mod clar probleme mai semnificative decât doar greșeli în raport.
Mai multe site-uri web suferă de eroarea de indexare a Google
Am vrut să aflu mai multe despre acest bug și amploarea lui, așa că am cercetat un eșantion mai mare de site-uri web pentru a trage concluzii utile.

Am colectat jurnalele de server de pe alte patru site-uri web și am săpat în date.
S-a dovedit că 100% dintre site-urile web pe care le- am examinat sufereau chiar de această problemă. Au fost mai multe adrese URL vizitate de Googlebot, dar clasificate greșit de Google Search Console fie ca:
- Descoperit – momentan nu este indexat sau
- Necunoscut.
În cazul stării Necunoscute, se pare că Google afirmă că nu a vizitat niciodată pagina și nu are nicio amintire că a descoperit adresa URL.

Am descoperit că problema era prezentă pe una dintre paginile testate chiar și la 6 luni după ce Google a vizitat-o inițial. Conform jurnalelor de server, ultima vizită a fost pe 7 martie, dar pe 27 octombrie, starea era încă Necunoscută.
Se pare că Google uită ocazional de adrese URL la un moment dat în conducta de indexare. Nu este clar dacă motorul de căutare doar pierde urma unor adrese URL sau le omite în mod deliberat.
În orice caz, consecințele sunt grave. Paginile uitate nu primesc trafic organic.
O posibilă soluție la bug
Dan Shure a împărtășit un caz interesant legat de eroarea URL uitată.
„Descoperit – dar neindexat în prezent” ar putea pune o adresă URL într-un fel de „listă neagră”?
M-am gândit să împărtășesc ceva ciudat și interesant care s-a întâmplat cu câteva postări pe blog ale unui client...
(1/5) (Urăsc să fac fire, dar asta necesită puține detalii)
— Dan Shure (@dan_shure) 8 noiembrie 2021
Se pare că schimbarea adresei URL a fost suficientă pentru a rezolva problema.
Dan Shure nu a fost singurul care a testat această soluție. Frank Olivo a primit aproape ⅓ din articolele sale indexate prin schimbarea adreselor URL!
Acest lucru a funcționat pentru aproximativ 12 din cele 38 de articole pe care le-am încercat. Toate indexate în aceeași zi în care am republicat. Articolele rămase sunt încă „descoperite” aproape o lună mai târziu.
— Frank Olivo (@FrancoOlivo) 7 decembrie 2021
Este posibil ca aceste adrese URL să se încadreze în tipare de adrese URL de calitate scăzută, așa că Google nu le-a accesat cu crawlere și, astfel, le-a clasificat ca „Descoperite – momentan neindexate” în Google Search Console.
Puteți convinge Google să trateze pagina ca pe una nouă și să o acceseze cu crawlere din nou schimbând adresa URL. Această soluție ar putea ajuta la indexarea paginii, dar este doar o soluție. Nu împiedică problema să se repete. Google ar trebui să rezolve problema, iar eroarea ar trebui remediată definitiv.
Încheierea
După cum este descris în articol, există o problemă gravă cu indexarea. Nu este la fel de aparent și spectaculos ca erorile anterioare de indexare (de exemplu, legate de canonizare), dar poate avea totuși un impact negativ asupra oricărui site web.
Dacă sunteți angajat Google și doriți să investigați problema, vă pot trimite câteva exemple de adrese URL care au suferit de această problemă.
Ați observat această eroare sau o eroare similară de indexare pe site-ul dvs.? Să-mi dai de veste!