
Cum să utilizați raportul de acoperire a indexului Google Search Console
Publicat: 2021-12-28Acoperirea indexului este un raport din Google Search Console care arată starea accesării cu crawlere și a indexării tuturor adreselor URL pe care Google le-a descoperit pentru site-ul dvs.
Vă ajută să urmăriți starea de indexare a site-ului dvs. web și vă ține informat cu privire la problemele tehnice care împiedică accesarea cu crawlere și indexarea corectă a paginilor dvs.
Verificarea periodică a raportului de acoperire a indexului vă va ajuta să identificați și să înțelegeți problemele și să aflați cum să le rezolvați.
În acest articol, voi descrie:
- Ce este raportul de acoperire a indicelui,
- Când și cum ar trebui să îl utilizați,
- Stările afișate în raport, inclusiv tipurile de probleme, ce înseamnă acestea și cum să le remediați.
Când a fost introdus raportul Acoperirea indicelui?
Google a introdus raportul Acoperirea indexului în ianuarie 2018 , când a început să lanseze o versiune reînnoită a Search Console pentru toți utilizatorii .
Pe lângă acoperirea indexului, Search Console îmbunătățită conținea și alte rapoarte valoroase:
- Raportul de performanță a căutării,
- Rapoarte privind îmbunătățirile căutării: starea AMP și paginile de postare de locuri de muncă.
Google a spus că reproiectarea Google Search Console a fost motivată de feedback-ul utilizatorilor. Scopul a fost:
- Adăugați mai multe informații utile,
- Sprijină cooperarea diferitelor echipe care utilizează instrumentul,
- Oferiți bucle de feedback mai rapide între Google și site-urile utilizatorilor.
Actualizarea raportului privind acoperirea indicelui 2021
În ianuarie 2021, Google a îmbunătățit raportul Acoperirea indexului pentru a face problemele de indexare raportate mai precise și mai clare pentru utilizatori.
Modificările aduse raportului au constat în:
- Eliminarea tipului de problemă generic „anomalie de accesare cu crawlere”,
- Crearea paginilor care au fost trimise, dar blocate de robots.txt și au fost indexate raportate ca „indexate, dar blocate” (în avertismente) în loc de „trimise, dar blocate” (eroare),
- Adăugarea unei probleme numite „indexat fără conținut” (la avertismente),
- Faceți raportarea problemelor soft 404 mai precise.
Conducta de indexare Google
Înainte de a explora detaliile raportului, să discutăm despre pașii pe care trebuie să îi urmeze Google pentru a indexa și, în cele din urmă, a clasifica paginile web.
Pentru ca o pagină să fie clasată și afișată utilizatorilor, trebuie să fie descoperită, accesată cu crawlere și indexată.
Descoperire
Google trebuie să descopere mai întâi o pagină pentru a o putea accesa cu crawlere.
Descoperirea se poate întâmpla în câteva moduri.
Cele mai obișnuite sunt ca Googlebot să urmărească linkuri interne sau externe către o pagină sau să o găsească printr-un sitemap XML , care este un fișier care listează și organizează adresele URL de pe domeniul dvs.
Crawling
Crawlingul constă în motoarele de căutare care explorează paginile web și le analizează conținutul.
Un aspect esențial al accesării cu crawlere este bugetul de accesare cu crawlere , care reprezintă cantitatea de timp și resurse pe care motoarele de căutare le pot și doresc să o cheltuiască pentru accesarea cu crawlere a site-ului dvs. Motoarele de căutare au capacități limitate de accesare cu crawlere și pot accesa cu crawlere doar o parte din paginile unui site web. Citiți mai multe despre optimizarea bugetului de accesare cu crawlere.
Indexarea
În timpul indexării, Google evaluează paginile și le adaugă la index - o bază de date cu toate paginile web pe care Google le poate folosi pentru a genera rezultate de căutare. Această etapă constă și în randarea , care ajută Google să vadă aspectul și conținutul paginilor. Informațiile pe care Google le adună despre o pagină îl ajută să decidă cum să o afișeze în rezultatele căutării.
Dar, doar pentru că Google vă poate găsi și accesa cu crawlere pagina, nu înseamnă că va fi indexată.
Indexarea de către Google a devenit din ce în ce mai complicată. Acest lucru se datorează în principal faptului că web-ul este în creștere, iar site-urile web devin din ce în ce mai grele.
Dar aici este aspectul crucial al indexării de reținut: nu ar trebui să aveți toate paginile indexate.
În schimb, asigurați-vă că indexul conține numai paginile dvs. cu conținut de înaltă calitate, valoros pentru utilizatori. Unele pagini pot avea conținut de calitate scăzută sau duplicat și, dacă motoarele de căutare le văd, poate afecta negativ modul în care văd site-ul dvs. în ansamblu.
De aceea este vital să creați o strategie de indexare și să decideți ce pagini ar trebui și nu ar trebui să fie indexate. Prin pregătirea unei strategii de indexare, vă puteți optimiza bugetul de accesare cu crawlere, puteți urma un obiectiv clar de indexare și puteți remedia orice probleme în consecință.
Dacă doriți să aflați mai multe despre indexare, începeți prin a explora ghidul nostru de indexare SEO.
Clasament
Paginile care sunt indexate pot fi clasate și pot apărea în rezultatele căutării pentru interogările relevante.
Google decide cum să clasifice paginile în funcție de numeroși factori de clasare, cum ar fi cantitatea și calitatea linkurilor, viteza paginii, compatibilitatea cu dispozitivele mobile, relevanța conținutului și mulți alții.
Cum se utilizează raportul de acoperire a indexului?
Pentru a ajunge la raportul Acoperirea indexului, conectați-vă la contul dvs. Google Search Console. Apoi, în meniul din stânga, selectați „Acoperire” în secțiunea Index:
Veți vedea apoi raportul. Bifând fiecare sau toate stările, puteți alege ceea ce doriți să vizualizați pe diagramă:

Raportul va afișa adrese URL care răspund cu următoarele patru stări, legate de diferite probleme pe care Google le-a întâlnit în anumite pagini:
- Eroare – probleme critice la crawling sau indexare.
- Valabil cu avertismente – adrese URL care sunt indexate, dar care conțin unele erori necritice.
- Valid – adrese URL care au fost indexate corect.
- Excluse – pagini care nu au fost indexate din cauza unor probleme – aceasta este cea mai importantă secțiune pe care să vă concentrați.
„Toate paginile trimise” vs „Toate paginile cunoscute”
În colțul din stânga sus, puteți selecta dacă doriți să vizualizați „Toate paginile cunoscute”, care este opțiunea implicită, care afișează adresele URL pe care Google le-a descoperit prin orice mijloace, sau „Toate paginile trimise”, inclusiv numai adresele URL trimise într-un sitemap.
Ar trebui să găsiți o diferență puternică între starea „Toate paginile trimise” și „Toate paginile cunoscute” – „Toate paginile cunoscute” conțin în mod normal mai multe adrese URL și mai multe dintre ele sunt raportate ca Excluse. Acest lucru se datorează faptului că sitemapurile ar trebui să conțină numai adrese URL indexabile, în timp ce majoritatea site-urilor web conțin multe pagini care nu ar trebui să fie indexate. Un exemplu sunt adresele URL cu parametri de urmărire pe site-urile de comerț electronic. Boții motoarelor de căutare, cum ar fi Googlebot, pot găsi acele pagini prin diferite mijloace, dar nu ar trebui să le găsească în harta dvs. de site.
Prin urmare, fiți întotdeauna atenți când deschideți raportul Acoperirea indexului și asigurați-vă că vă uitați la datele care vă interesează.
Inspectarea stărilor URL
Pentru a vedea detaliile despre problemele găsite pentru fiecare dintre stări, priviți mai jos graficul:

Această secțiune afișează starea, tipul specific de problemă și numărul de pagini afectate.
Puteți vedea, de asemenea, starea de validare - după remedierea unei probleme, puteți informa Google că aceasta a fost rezolvată și cere să valideze remedierea.
Acest lucru este posibil în partea de sus a raportului după ce faceți clic pe problemă:
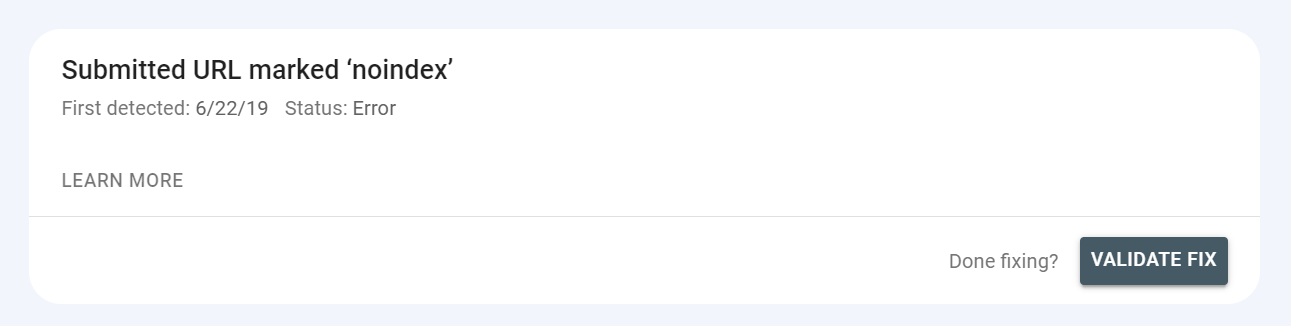
Starea de validare poate apărea ca „fixă”. Dar poate afișa și „eșuat” sau „nepornit” – ar trebui să acordați prioritate remedierii problemelor care răspund cu aceste stări.
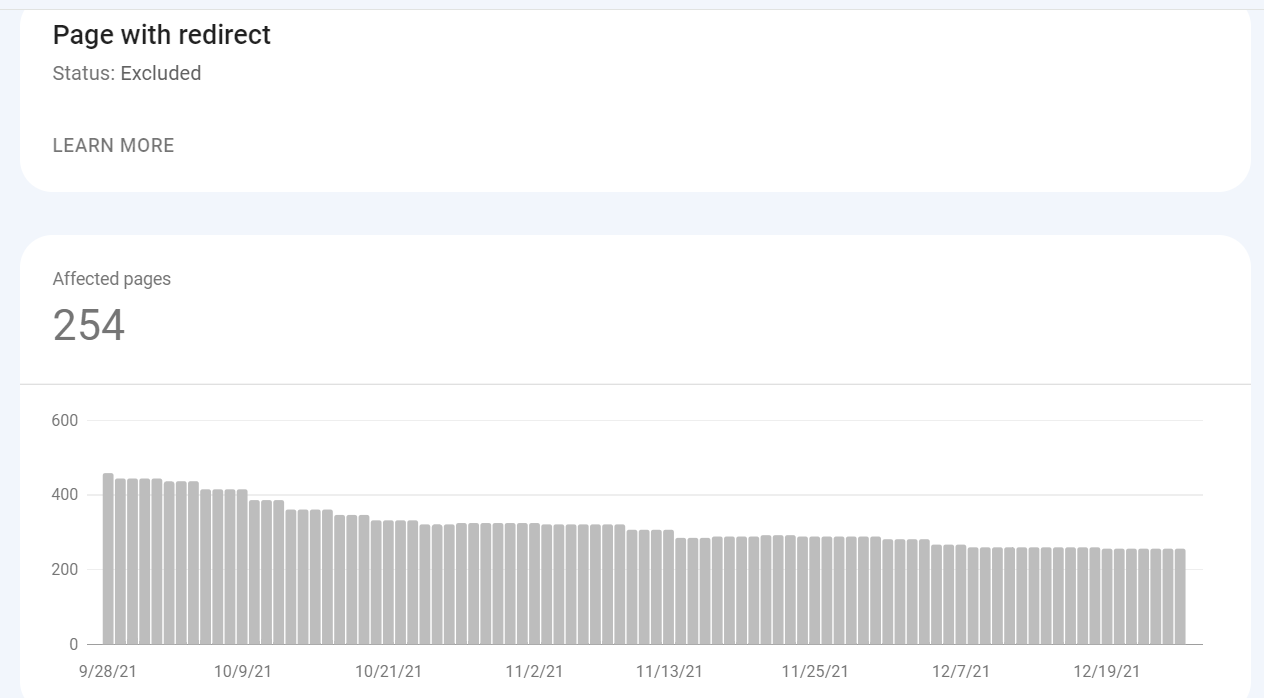
De asemenea, puteți vedea tendința pentru fiecare stare – dacă numărul de adrese URL a crescut, a scăzut sau a rămas la același nivel.
După ce faceți clic pe unul dintre tipuri, veți vedea ce adrese URL răspund la această problemă. În plus, puteți verifica când fiecare adresă URL a fost accesată ultima dată cu crawlere – cu toate acestea, aceste informații nu sunt întotdeauna actualizate din cauza posibilelor întârzieri în raportarea Google.
Există, de asemenea, un grafic care arată datele și modul în care problema s-a schimbat în timp.
Iată câteva considerente importante de care ar trebui să fii conștient atunci când folosești raportul:
- Verificați întotdeauna dacă vă uitați la toate paginile trimise sau la toate paginile cunoscute. Diferența dintre starea paginilor din harta site-ului dvs. față de toate paginile descoperite de Google poate fi foarte puternică.
- Raportul poate afișa modificări cu întârziere, așa că de fiecare dată când lansați conținut nou, acordați-i cel puțin câteva zile pentru a fi accesat cu crawlere și indexat.
- Google vă va trimite notificări prin e -mail despre orice probleme deosebit de presante întâlnite pe site-ul dvs.
- Scopul dvs. ar trebui să fie să indexați versiunile canonice ale paginilor pe care doriți să le găsească utilizatorii și roboții.
- Pe măsură ce site-ul dvs. web crește și creați mai mult conținut, așteptați-vă să crească numărul de pagini indexate din raport.
Cât de des ar trebui să verificați raportul?
Ar trebui să verificați periodic raportul Acoperirea indexului pentru a detecta eventualele greșeli la accesarea cu crawlere și la indexarea paginilor dvs. În general, încercați să verificați raportul cel puțin o dată pe lună.
Dar, dacă faceți modificări semnificative site-ului dvs., cum ar fi ajustarea aspectului, a structurii URL sau efectuarea unei migrări a site-ului, monitorizați rezultatele mai des pentru a identifica orice impact negativ. Apoi, recomand să vizitați raportul cel puțin o dată pe săptămână și să acordați o atenție deosebită statutului Exclus .
Instrument de inspecție URL
Înainte de a aborda detaliile fiecărei stări din raportul Acoperirea indexului, vreau să menționez un alt instrument din Search Console, care vă va oferi informații valoroase despre paginile dvs. accesate cu crawlere sau indexate.
Instrumentul de inspecție URL oferă detalii despre versiunea paginii indexate Google.
Îl puteți găsi în Google Search Console într-o bară de căutare din partea de sus a paginii.
Pur și simplu lipiți o adresă URL pe care doriți să o inspectați - apoi veți vedea următoarele date:
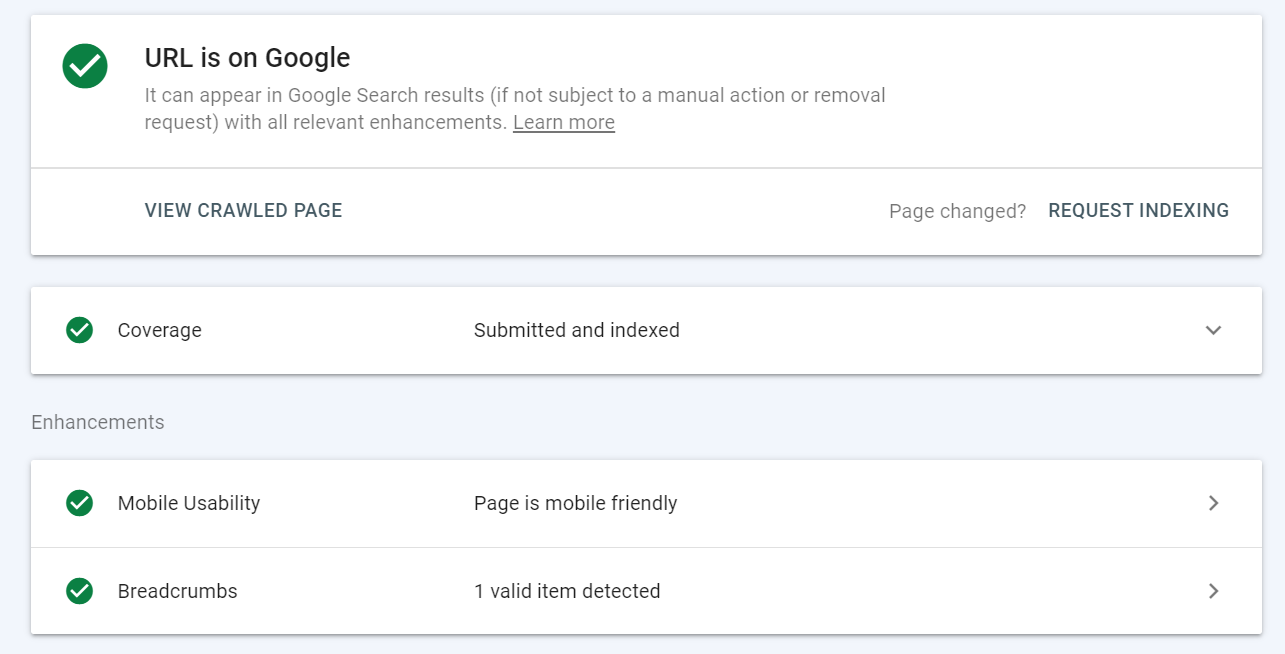
Puteți utiliza instrumentul de inspecție URL pentru:
- Verificați starea indexului unei adrese URL și, în caz de probleme, vedeți care sunt acestea și remediați-le,
- Aflați dacă o adresă URL poate fi indexată,
- Vizualizați versiunea redată a unei adrese URL,
- Solicitați indexarea unei adrese URL – de exemplu, dacă o pagină s-a schimbat,
- Vizualizați resursele încărcate, cum ar fi JavaScript,
- Vedeți pentru ce îmbunătățiri este eligibilă o adresă URL – de exemplu, pe baza implementării datelor structurate și dacă pagina este compatibilă cu dispozitivele mobile.
Dacă întâmpinați probleme în raportul Acoperirea indexului, utilizați instrumentul de inspecție a adreselor URL pentru a le verifica și a testa adresele URL pentru a înțelege mai bine ce ar trebui remediat.
Status în raportul de acoperire index și tipuri de probleme
Este timpul să analizăm fiecare dintre cele patru stări din raport și:
- Discutați tipurile de probleme specifice pe care le pot afișa,
- Ce cauzează aceste probleme și
- Cum ar trebui să le adresezi.
Eroare
Secțiunea de erori conține adrese URL care nu au fost indexate din cauza erorilor întâlnite de Google.
Ori de câte ori vedeți o problemă care conține „Trimisă”, aceasta se referă la adresele URL care au fost trimise pentru indexare, care se face în general printr-o hartă a site-ului și așa le-a descoperit Google. Asigurați-vă că harta dvs. de site conține numai adrese URL pe care doriți să le indexați.

Eroare de server (5xx)
După cum este indicat de nume, se referă la erori de server cu coduri de stare 5xx , cum ar fi 502 Bad Gateway sau 503 Service Unavailable.
Ar trebui să monitorizați această secțiune în mod regulat, deoarece Googlebot va avea probleme la indexarea paginilor cu erori de server. Poate fi necesar să contactați administratorul serverului pentru a remedia aceste erori sau pentru a verifica dacă sunt cauzate de vreo actualizare sau modificări recente pe site-ul dvs.
Consultați sugestiile Google despre cum să remediați erorile de server.
Eroare de redirecționare
Redirecționările transferă roboții și utilizatorii motoarelor de căutare de la o adresă URL veche la una nouă. Ele sunt de obicei implementate atunci când adresele URL vechi se modifică sau când conținutul lor nu mai există.
Erorile de redirecționare indică următoarele probleme:
- Lanțul de redirecționare (care apare atunci când există mai multe redirecționări între adrese URL) este prea lung,
- Bucla de redirecționare – URL-urile redirecționează unele către altele,
- Adresa URL de redirecționare care a depășit lungimea maximă a adresei URL,
- A fost găsită o adresă URL greșită sau goală în lanțul de redirecționare.
Verificați și remediați redirecționările pentru fiecare adresă URL afectată – dacă nu sunteți sigur de unde să începeți, urmați ghidul meu pentru redirecționări.
Adresa URL trimisă a fost blocată de robots.txt
Aceste adrese URL au fost trimise într-un sitemap, dar sunt blocate în robots.txt. Robots.txt este un fișier care conține instrucțiuni despre cum ar trebui roboții să acceseze cu crawlere site-ul dvs. Dacă această adresă URL ar trebui indexată, Google trebuie să o acceseze cu crawlere mai întâi, așa că accesați fișierul robots.txt și ajustați directivele.
Adresa URL trimisă marcată „noindex”
Similar cu eroarea anterioară, aceste pagini au fost trimise pentru indexare, dar sunt blocate de o etichetă sau antet noindex în răspunsul HTTP . „Noindex” împiedică indexarea unei pagini – dacă adresele URL afectate ar trebui indexate, eliminați directiva noindex.
Adresa URL trimisă pare să fie un Soft 404
O eroare soft 404 înseamnă că o pagină returnează o stare 200 OK, dar conținutul ei o face să arate ca o eroare , de exemplu, deoarece este goală sau conține conținut subțire. Examinați paginile cu această eroare și verificați dacă există o modalitate de a le modifica conținutul sau de a le redirecționa.
Adresa URL trimisă returnează o solicitare neautorizată (401)
Codul de stare 401 Neautorizat înseamnă că o solicitare nu poate fi finalizată deoarece este necesar să vă conectați cu un ID de utilizator și o parolă valide. Googlebot nu poate indexa paginile ascunse în spatele conectărilor – în acest caz, fie eliminați cerința de autorizare, fie verificați Googlebot pentru a putea accesa paginile.
Adresa URL trimisă nu a fost găsită (404)
Paginile de eroare 404 indică faptul că pagina solicitată nu a putut fi găsită deoarece s-a schimbat sau a fost ștearsă. Pagini de eroare există pe fiecare site web și, în general, câteva dintre ele nu vor dăuna site-ului dvs. Dar, ori de câte ori un utilizator întâlnește o pagină de eroare, aceasta poate duce la o experiență negativă.
Dacă vedeți această problemă în raport, parcurgeți adresele URL afectate și verificați dacă puteți remedia erorile. De exemplu, puteți configura redirecționări 301 către paginile de lucru. De asemenea, asigurați-vă că sitemap-ul dvs. nu conține adrese URL care returnează alt cod de stare HTTP decât 200 OK.
Adresa URL trimisă a returnat 403
Codul de stare 403 Forbidden înseamnă că serverul înțelege cererea, dar refuză să o autorizeze. Puteți fie să acordați acces vizitatorilor anonimi, astfel încât Googlebot să poată accesa adresa URL sau, dacă acest lucru nu este posibil, să eliminați adresa URL din hărțile site-ului.
Adresa URL trimisă a fost blocată din cauza unei alte probleme 4xx
Este posibil ca adresele URL dvs. să nu fie indexate din cauza problemelor 4xx nespecificate în alte tipuri de erori. Erorile 4xx se referă în general la probleme cauzate de client.
Puteți afla mai multe despre ce cauzează fiecare problemă utilizând instrumentul de inspecție URL . Dacă nu puteți rezolva eroarea, eliminați adresa URL de pe harta site-ului.
Valabil cu avertismente
Adresele URL care sunt valide cu avertismente au fost indexate, dar pot necesita atenția dvs.
Indexat, deși blocat de robots.txt
O pagină a fost indexată, dar directivele din fișierul robots.txt o blochează. În mod obișnuit, aceste pagini nu ar fi indexate, dar este probabil că Google a găsit link-uri care indică spre ele și le-a considerat importante.
Verificați paginile afectate – dacă ar trebui să fie indexate, actualizați fișierul robots.txt pentru a oferi Google acces la ele. Dacă aceste pagini nu ar trebui să fie indexate, căutați orice link-uri care să trimită către ele. Dacă doriți ca URL-urile să fie accesate cu crawlere, dar nu indexate, implementați directivele noindex.
Pagina indexată fără conținut
Aceste adrese URL sunt indexate, dar Google nu a putut să le citească conținutul.
Cauzele comune ale acestei probleme includ:
- Cloaking – afișarea de conținut diferit utilizatorilor și motoarelor de căutare,
- Pagina este goală,
- Google nu poate reda pagina,
- Pagina este într-un format pe care Google nu îl poate indexa.
Vizitați singur aceste pagini și verificați dacă conținutul este vizibil. De asemenea, accesați instrumentul de inspecție URL pentru a afla cum îl vede Googlebot. Apoi, după ce ați remediat problema sau nu vedeți nicio problemă, puteți solicita ca Google să o reindexeze.
Valabil
Această stare arată adresele URL care sunt indexate corect. Cu toate acestea, este totuși bine să monitorizați această secțiune de raport pentru a vedea dacă vreo adresă URL nu ar trebui indexată.
Trimis și indexat
Acestea sunt adrese URL care sunt corect indexate și trimise printr-un sitemap.
Indexat, nu a fost trimis în harta site-ului
În această situație, o adresă URL a fost indexată chiar dacă nu este inclusă în harta site-ului.
Ar trebui să verificați cum ajunge Google la această adresă URL. Puteți găsi aceste informații în instrumentul de inspecție URL.
Adresele URL din această secțiune includ adesea paginarea site-ului, ceea ce este corect deoarece paginarea nu ar trebui să fie trimisă în hărțile site-ului. Examinați adresele URL și verificați dacă acestea ar trebui adăugate pe harta site-ului.
Exclus
Acestea sunt pagini care nu au fost indexate. După cum puteți observa, multe probleme de aici sunt cauzate de aspecte similare cu cele din secțiunile anterioare. Principala diferență este că Google nu crede că excluderea următoarelor adrese URL este cauzată de o eroare.
Este posibil să descoperiți că multe adrese URL din această secțiune au fost excluse din motivele corecte. Dar este important să verificați în mod regulat ce adrese URL nu sunt indexate și de ce pentru a vă asigura că adresele URL esențiale nu sunt ținute în afara indexului.
Exclus de eticheta „noindex”.
O pagină nu a fost trimisă pentru indexare, dar Googlebot a găsit-o și nu a putut-o indexa din cauza unei etichete noindex. Parcurgeți aceste adrese URL pentru a vă asigura că cele potrivite sunt blocate din index. Dacă oricare dintre adresele URL ar trebui indexată, eliminați eticheta.
Blocat de instrumentul de eliminare a paginii
Aceste adrese URL au fost blocate de la Google folosind instrumentul Google Eliminare . Cu toate acestea, această metodă funcționează doar temporar și, de obicei, după 90 de zile, Google le poate afișa din nou în rezultatele căutării. Dacă doriți să blocați o pagină în mod permanent, puteți să o eliminați sau să o redirecționați sau să utilizați o etichetă noindex.
Blocat de robots.txt
Adresele URL au fost blocate în fișierul robots.txt, dar nu au fost trimise pentru indexare. Ar trebui să parcurgeți aceste adrese URL și să verificați dacă intenționați să le blocați.
Amintiți-vă că folosirea directivelor robots.txt nu este o modalitate sigură de a preveni indexarea paginilor. Google poate indexa în continuare o pagină fără a o vizita, de exemplu, dacă alte pagini se leagă la ea. Pentru a păstra o pagină în afara indexului Google, utilizați o altă metodă, cum ar fi protecția prin parolă sau eticheta noindex.
Blocat din cauza unei solicitări neautorizate (401)
În acest caz, Google a primit un cod de răspuns 401 și nu a fost autorizat să acceseze adresele URL.
Acest lucru tinde să apară în medii de pregătire sau alte pagini protejate prin parolă.
Dacă aceste adrese URL nu ar trebui indexate, această stare este bună. Cu toate acestea, pentru a nu lăsa aceste adrese URL la îndemâna Google, asigurați-vă că mediul dvs. de pregătire nu poate fi găsit de Google. De exemplu, eliminați orice link-uri interne sau externe existente care indică către acesta.
Accesat cu crawlere – momentan nu este indexat
Googlebot a accesat cu crawlere o adresă URL, dar așteaptă să decidă dacă ar trebui să fie indexată.
Ar putea fi multe motive pentru asta. De exemplu, este posibil să nu existe nicio problemă, iar Google va indexa această adresă URL în curând. Dar, frecvent, Google va aștepta să indexeze o pagină dacă conținutul acesteia nu este de calitate sau arată similar cu multe alte pagini de pe site. Google îl pune apoi în coadă cu o prioritate mai mică și se concentrează pe indexarea paginilor mai valoroase.
Dacă doriți să aflați despre ce ar putea cauza această stare și cum să rezolvați orice problemă, asigurați-vă că citiți articolul nostru despre cum să remediați „Crawled – momentan neindexat”.
Descoperit – momentan nu este indexat
Aceasta înseamnă că Google a găsit o adresă URL – de exemplu, într-un sitemap – dar nu a accesat-o încă cu crawlere.
Rețineți că, în unele cazuri, ar putea însemna pur și simplu că Google îl va accesa cu crawlere în curând. Această problemă poate fi asociată și cu probleme legate de bugetul de accesare cu crawlere – Google poate vedea site-ul dvs. web ca fiind de calitate scăzută, deoarece nu are performanță sau conține conținut slab.
Posibil, Google nu a găsit niciun link care să indice această adresă URL sau a întâlnit pagini cu semnale de link mai puternice că va fi accesat cu crawlere mai întâi. Dacă există o mulțime de pagini de calitate mai bună sau mai actuale, este posibil ca Google să nu acceseze cu crawlere această adresă URL timp de luni de zile sau chiar să nu o acceseze cu crawlere deloc.
Pagina alternativă cu eticheta canonică adecvată
Această adresă URL este o copie a unei pagini canonice marcată de eticheta corectă și indică pagina canonică. Etichetele canonice sunt folosite pentru a specifica o adresă URL care reprezintă versiunea principală a unei pagini. Este o modalitate de a preveni problemele de conținut duplicat atunci când există multe pagini identice sau similare.
În această situație, nu trebuie să faceți nicio modificare.
Duplicați fără canonice selectate de utilizator
Există duplicate pentru această pagină și nu este specificată nicio versiune canonică. Înseamnă că Google nu vede adresele URL specificate ca fiind canonice.
Puteți utiliza instrumentul de inspecție URL pentru a afla ce adresă URL a ales Google ca fiind canonică. Cel mai bine este să alegeți singur versiunea canonică și să o marcați corespunzător în adresele URL folosind eticheta rel="canonical".
Dublat, Google a ales diferit canonic decât utilizator
Ați ales o pagină canonică, dar Google a selectat o altă pagină drept canonică.
Pagina pe care doriți să o aveți drept canonică poate să nu fie la fel de puternic legată în interior ca o pagină necanonică, pe care Google o poate alege ca versiune canonică.
O modalitate de a rezolva această problemă este să vă consolidați adresele URL duplicat. Dacă doriți să aflați mai multe despre posibilele cauze și soluții pentru stare, citiți ghidul nostru despre cum să remediați Duplicat, Google a ales o altă problemă canonică decât cea a utilizatorului.
Negăsit (404)
Acestea sunt pagini de eroare 404 care nu au fost trimise într-un sitemap, dar Google le-a găsit în continuare.
Google le-ar fi putut descoperi prin link-uri sau pentru că au existat înainte și au fost șterse ulterior.
Dacă intenția dvs. a fost ca această pagină să nu fie găsită, nu este necesară nicio acțiune. O altă opțiune este să utilizați o redirecționare 301 pentru a muta 404 pe o pagină de lucru.
Pagina cu redirecționare
Aceste pagini sunt redirecționate, deci nu au fost indexate. Paginile de aici nu ar necesita, în general, atenția dvs.
Pentru a redirecționa permanent o pagină, asigurați-vă că ați implementat o redirecționare 301 către pagina alternativă cea mai apropiată. Redirecționarea paginilor 404 către pagina de pornire poate face ca Google să le trateze ca 404 soft.
Soft 404
După cum am menționat, aceste adrese URL seamănă cu paginile de eroare, dar nu returnează coduri de stare 404. De exemplu, pot fi pagini personalizate 404 care conțin conținut ușor de utilizat, care direcționează către alte pagini, dar care returnează un cod HTTP 200 OK.
Pentru a remedia erorile soft 404, puteți:
- Adăugați sau îmbunătățiți conținutul acestor adrese URL,
- 301 redirecționează-le către cele mai apropiate alternative sau
- Configurați-vă serverul pentru a returna codurile 404 sau 410 adecvate.
Duplicat, adresa URL trimisă nu a fost selectată ca canonică
Aceasta include adresele URL trimise într-un hartă site, dar fără versiuni canonice specificate.
Google consideră aceste adrese URL duble ale altor adrese URL și a decis să canonizeze aceste adrese URL cu adrese URL canonice selectate de Google. Ar trebui să adăugați adrese URL canonice care să indice versiunile URL preferate.
Blocat din cauza accesului interzis (403)
Google nu a putut accesa aceste adrese URL și a primit un cod de eroare 403 Forbidden. Dacă Google nu ar trebui să acceseze aceste adrese URL, este mai bine să utilizați o etichetă noindex.
Blocat din cauza unei alte probleme 4xx
Aceste adrese URL răspund cu alte coduri de stare 4xx - verificați aceste pagini pentru a afla care este eroarea. Apoi, fie remediați-l conform codului specific care apare, fie lăsați paginile așa cum sunt.
Concluzie
Raportul Acoperirea indexului arată o imagine de ansamblu detaliată a problemelor dvs. de crawling și indexare și indică modul în care acestea ar trebui abordate, făcându-l o sursă vitală de date SEO.
Starea de accesare cu crawlere și de indexare a site-ului dvs. web nu este simplă – nu toate paginile dvs. trebuie accesate cu crawlere sau indexate. Asigurarea faptului că astfel de pagini nu sunt accesibile pentru roboții motoarelor de căutare este la fel de esențială ca și paginile tale cele mai valoroase indexate corect.
Raportul reflectă faptul că starea dvs. de indexare nu este nici neagră, nici albă. Evidențiază gama de stări în care se pot afla adresele URL, afișând atât erori grave, cât și probleme minore care nu necesită întotdeauna acțiune.
În cele din urmă, ar trebui să răsfoiți în mod regulat raportul Google Index Coverage și să interveniți atunci când acesta nu se aliniază cu strategia dvs. de indexare.