
Cara Memperbaiki "Merayap - Saat Ini Tidak Terindeks" di Google Search Console
Diterbitkan: 2021-12-28Dokumentasi Google mendefinisikan Crawling – saat ini tidak mengindeks status sebagai:
Halaman telah dirayapi oleh Google, tetapi tidak diindeks. Ini mungkin atau mungkin tidak diindeks di masa depan; tidak perlu mengirim ulang URL ini untuk dirayapi.sumber: Google
Membaca penjelasan ini mungkin akan membuat Anda frustasi, terutama jika status tersebut memengaruhi halaman yang penting bagi bisnis Anda. Definisi Google tidak menjelaskan apa yang terjadi dan apa yang mungkin Anda lakukan selanjutnya. Yang dikatakan hanyalah bahwa Googlebot merayapi halaman Anda tetapi, untuk beberapa alasan, memutuskan untuk tidak mengindeksnya.
Menurut penelitian kami, status Crawling – saat ini tidak diindeks adalah masalah paling umum yang dilaporkan dalam laporan Cakupan Indeks. Ini berarti Anda mungkin pernah mengalaminya, atau kemungkinan besar Anda akan mengalaminya di masa depan.
Sangat penting untuk memperbaiki masalah secepat mungkin. Lagi pula, jika halaman Anda tidak diindeks, halaman itu tidak akan muncul di hasil pencarian, dan tidak akan mendapatkan lalu lintas organik dari Google.
Artikel ini menyajikan kemungkinan penyebab Perayapan – saat ini bukan status indeks dan cara memperbaikinya .
Di mana Anda dapat menemukan status Perayapan – saat ini tidak diindeks?
Anda dapat menemukan statusnya di laporan Cakupan Indeks dan Alat Inspeksi URL di Google Search Console.
Laporan Cakupan Indeks
Dirayapi – saat ini tidak diindeks termasuk dalam kategori “Dikecualikan”, yang menunjukkan bahwa Google tidak menganggap bahwa halaman tersebut tidak diindeks adalah suatu kesalahan.
Halaman-halaman ini biasanya tidak diindeks, dan kami pikir itu tepat. Halaman-halaman ini adalah duplikat halaman yang diindeks, atau diblokir dari pengindeksan oleh beberapa mekanisme di situs Anda, atau tidak diindeks karena alasan yang menurut kami bukan kesalahan.sumber: Google
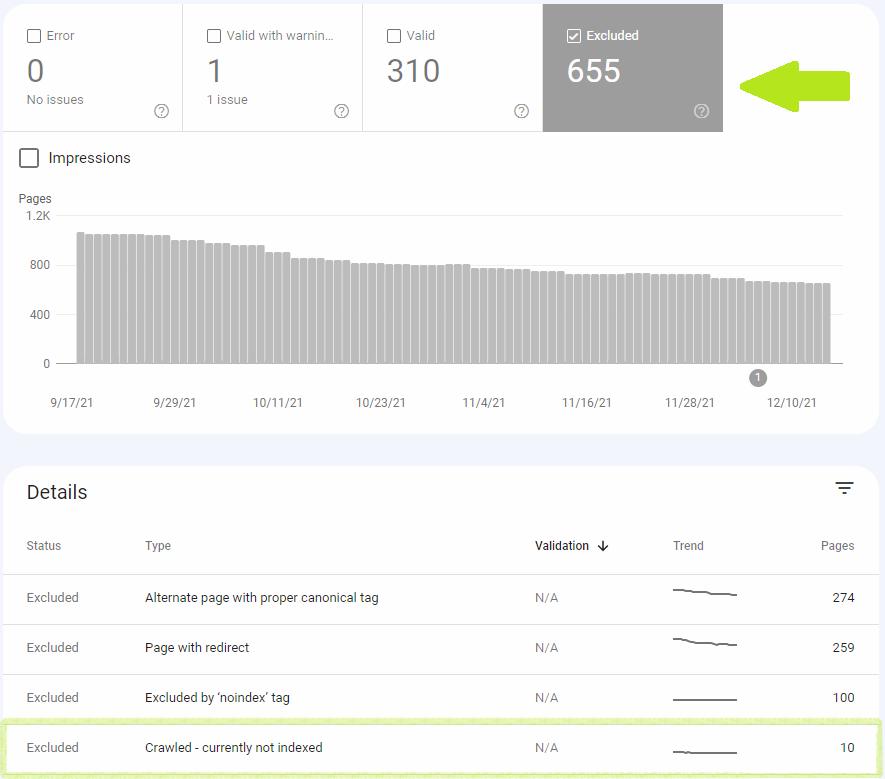
Setelah mengklik status Dirayapi – saat ini tidak diindeks, Anda akan melihat daftar URL yang terpengaruh. Anda harus memeriksanya dan memprioritaskan perbaikan masalah untuk halaman yang paling berharga bagi Anda.
Laporan ini juga tersedia untuk ekspor. Namun, Anda hanya dapat mengekspor hingga 1000 URL. Jika lebih banyak halaman terpengaruh, Anda dapat meningkatkan jumlah URL yang diekspor dengan memfilter halaman khusus untuk peta situs. Misalnya, jika Anda memiliki dua peta situs, masing-masing dengan 1000 URL, Anda dapat mengekspor keduanya secara terpisah.
Alat Inspeksi URL
Alat Inspeksi URL di Google Search Console juga dapat memberi tahu Anda tentang URL yang Dirayapi – saat ini tidak diindeks.
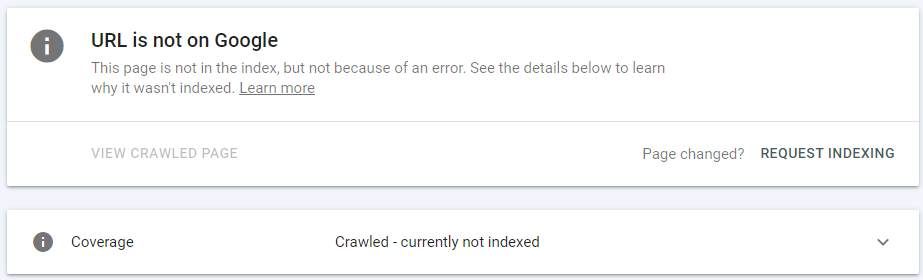
Bagian atas alat ini memberi tahu Anda apakah URL dapat ditemukan di Google atau tidak. Jika URL yang diperiksa termasuk dalam kategori Dikecualikan dalam laporan Cakupan Indeks, Alat Inspeksi URL akan melaporkan hal berikut: “Halaman tidak ada dalam indeks, tetapi bukan karena kesalahan.”
Di bawah, Anda dapat menemukan informasi yang lebih spesifik tentang status Cakupan saat ini dari URL yang diinspeksi – jika URL dirayapi di atas – saat ini tidak diindeks.
Melaporkan bug: halaman Anda mungkin benar-benar diindeks
Setelah memperhatikan status Crawled – saat ini tidak diindeks, hal pertama yang harus Anda lakukan adalah menyelidiki apakah halaman Anda benar-benar tidak diindeks.
Bukan hal yang aneh untuk melihat halaman yang ditandai sebagai Dirayapi – saat ini tidak diindeks dalam laporan Cakupan Indeks, sedangkan alat Inspeksi URL menunjukkan bahwa halaman tersebut benar-benar diindeks.
Alat Inspeksi URL memungkinkan Anda memeriksa detail tentang URL tertentu, termasuk:
- Masalah pengindeksan,
- Kesalahan data terstruktur,
- Kegunaan Seluler,
- Lihat sumber daya yang dimuat (misalnya, JavaScript).
Anda juga dapat meminta pengindeksan untuk URL atau melihat versi halaman yang dirender.
John Muller dari Google mengatasi masalah dengan perbedaan antara laporan Cakupan Indeks dan alat Inspeksi URL selama Jam Kantor SEO Google:
Saya baru-baru ini melihat beberapa utas seperti ini di Twitter di mana orang melihat URL yang ditandai sebagai tidak diindeks di Search Console. Dan kemudian, ketika Anda memeriksanya satu per satu, mereka sebenarnya diindeks. Saya belum tahu persis apa yang terjadi di sana. […] Kecurigaan saya adalah ini lebih pada masalah waktu – kami menampilkannya di laporan Search Console, dan kemudian mereka diindeks seiring waktu. Kemudian di beberapa titik, mereka akan keluar dari laporan lagi. Dan untuk alasan apa pun, putus sekolah membutuhkan waktu sedikit lebih lama dari yang seharusnya.sumber: John Mueller
Seperti yang dikatakan John, ini mungkin hanya masalah penundaan dan sinkronisasi data antara kedua alat ini, dan statusnya mungkin diperbarui dalam laporan Cakupan Indeks dari waktu ke waktu.
Namun, itu tidak selalu hanya penundaan. Terkadang ini adalah bug pelaporan.
Pada bulan September, kami melihat beberapa artikel kami yang diindeks melaporkan Dirayapi – saat ini tidak diindeks.
Dengan GSC, Anda dapat memeriksa halaman mana yang dirayapi tetapi masih belum diindeks oleh Google.
GSC mencantumkan beberapa artikel kami sebagai yang dirayapi – saat ini tidak diindeks.
Namun, alat Inspeksi URL menunjukkan ini sebagai diindeks.
Dan mereka benar-benar diindeks.
Ada wawasan, #SEOTwitter? pic.twitter.com/xKv0IYpGLa
— Onely (@OnelyCom) 16 September 2021
Itu jelas bukan masalah penundaan karena artikel lama juga terpengaruh.
Tak lama setelah itu, SEO lainnya, termasuk Lily Ray, mulai memperhatikan masalah ini.
Orang lain telah menge-tweet tentang ini, tetapi saya melihat banyak contoh URL dalam laporan "Dirayapi, Tidak Diindeks" GSC (dengan tanggal perayapan terbaru) yang sebenarnya adalah URL yang diindeks.
Memeriksa URL individual sering kali menghasilkan pesan di bawah ini.
Pikiran @danielwaisberg @googlesearchc? pic.twitter.com/i1XfcvldEq
— Lily Ray (@lilyraynyc) 28 September 2021
Apa yang harus dilakukan dalam situasi ini? Laporan mana yang harus dipercaya?
Umumnya , alat Inspeksi URL menampilkan lebih banyak data terkini daripada laporan Cakupan Indeks. Itulah mengapa Anda harus selalu lebih memercayai alat Inspeksi URL saat dipaksa untuk memilih di antara laporan-laporan ini.
Penyebab dan solusi untuk Crawling – status saat ini tidak diindeks
Sekarang, mari kita ke dasar masalahnya – apa yang menyebabkan status tersebut muncul dan apa yang dapat Anda lakukan untuk memperbaikinya.
Google tidak memberikan jawaban yang jelas mengapa halaman Anda dirayapi tetapi tidak diindeks, tetapi ada beberapa kemungkinan alasan mengapa status tersebut muncul, termasuk:
- Penundaan pengindeksan,
- Halaman tidak memenuhi standar kualitas,
- Halaman dideindeks,
- Masalah arsitektur situs web,
- Masalah konten duplikat.
Penundaan pengindeksan
Bukan hal yang aneh bahwa Google mengunjungi suatu halaman, tetapi perlu beberapa saat untuk mengindeksnya. Internet sangat besar, dan Google perlu memprioritaskan halaman mana yang diindeks terlebih dahulu.
Dalam menunjukkan berapa lama waktu yang dibutuhkan halaman di situs web populer untuk diindeks. Berikut beberapa hasil investigasi saya:
- Google mengindeks hanya 56% URL yang dapat diindeks setelah 1 hari sejak dipublikasikan.
- Setelah 2 minggu, hanya 87% URL yang diindeks.
sumber: Tomek Rudzki
Jika Anda baru saja memublikasikan halaman Anda, mungkin normal bahwa halaman tersebut belum diindeks, dan Anda perlu menunggu sedikit lebih lama agar Google mengindeks konten Anda.
Larutan
Anda tidak dapat memengaruhi perayapan dan pengindeksan halaman Anda dalam jangka pendek, tetapi ada beberapa hal yang dapat Anda lakukan untuk membantu situs web Anda dalam jangka panjang:
- Buat strategi pengindeksan untuk membantu Google memprioritaskan halaman yang tepat di situs Anda. Untuk melakukannya, Anda perlu memutuskan halaman mana yang harus diindeks dan metode terbaik untuk mengomunikasikannya ke Google.
- Pastikan ada tautan internal ke halaman yang Anda minati. Ini akan membantu Google menemukan halaman dan mempelajari lebih lanjut tentang konteksnya.
- Buat peta situs yang dioptimalkan dengan baik. Ini adalah file teks sederhana yang mencantumkan URL berharga Anda. Google akan menggunakannya sebagai peta jalan untuk menemukan halaman lebih cepat.
Halaman tidak memenuhi standar kualitas
Google tidak dapat mengindeks semua halaman di Internet. Ruang penyimpanannya terbatas, dan itulah mengapa perlu menyaring konten berkualitas rendah.

Tujuan Google adalah menyediakan halaman dengan kualitas terbaik yang menjawab maksud pengguna dengan paling baik. Ini berarti bahwa jika halaman memiliki kualitas yang lebih rendah, Google kemungkinan besar akan mengabaikannya untuk meninggalkan ruang penyimpanan yang tersedia untuk konten berkualitas lebih tinggi. Dan kita dapat mengharapkan standar kualitas menjadi lebih ketat di masa depan.
Larutan
Sebagai pemilik situs web, Anda harus memastikan halaman Anda menyediakan konten berkualitas tinggi. Periksa apakah itu mungkin memuaskan niat pengguna Anda dan tambahkan konten berkualitas baik jika diperlukan. Google menawarkan daftar pertanyaan untuk membantu Anda menentukan nilai konten Anda. Berikut adalah beberapa di antaranya:
- Apakah konten memberikan informasi, pelaporan, penelitian, atau analisis asli?
- Apakah konten memberikan analisis mendalam atau informasi menarik yang tidak terlihat?
- Apakah ini jenis halaman yang ingin Anda tandai, bagikan dengan teman, atau rekomendasikan?
- Jika konten mengacu pada sumber lain, apakah konten tersebut menghindari penyalinan atau penulisan ulang sumber tersebut dan malah memberikan nilai tambah dan orisinalitas yang substansial?
sumber: Google
Selain itu, Anda dapat menggunakan kiat tentang konten berkualitas dari Pedoman Penilai Kualitas Google. Meskipun dokumen ini dimaksudkan terutama untuk Penilai Kualitas Penelusuran untuk menilai kualitas situs web, webmaster dapat menggunakannya untuk mendapatkan beberapa wawasan tentang cara meningkatkan situs mereka sendiri. Jika Anda ingin mempelajari lebih lanjut, lihat panduan kami tentang Pedoman Penilai Kualitas.
Konten buatan pengguna
Konten yang dibuat pengguna mungkin menjadi masalah dari sudut pandang kualitas.
Misalnya, anggap Anda memiliki forum, dan seseorang mengajukan pertanyaan. Meskipun mungkin ada banyak balasan berharga di masa mendatang, pada saat perayapan, tidak ada balasan, sehingga Google dapat mengklasifikasikan halaman tersebut sebagai konten berkualitas rendah.
Apa yang harus dilakukan untuk melindungi diri dari situasi ini?
Quora datang dengan strategi yang sangat baik untuk masalah ini. Setiap pertanyaan yang belum terjawab memiliki awalan “/ belum terjawab/” di URL.
Berikut ini contohnya: https://www.quora.com/unanswered/Are-you-really-happy-with-your-results
File robots.txt memblokir semua halaman dengan /unanswered/ di URL-nya. Itu berarti Googlebot tidak dapat merayapinya.
Setelah ada balasan untuk pertanyaan, URL berubah dan tersedia untuk dirayapi. Dengan cara ini, Quora memblokir akses ke konten berkualitas rendah yang dihasilkan oleh pengguna.
Halaman dideindeks
URL dapat mengalami Perayapan – status saat ini tidak diindeks karena diindeks di masa lalu, tetapi Google memutuskan untuk menghapus indeks dari waktu ke waktu.
Jika Anda bertanya-tanya mengapa beberapa hal mungkin hilang dari indeks, kemungkinan besar mereka hanya digantikan oleh konten berkualitas lebih tinggi.
Pemilihan indeks, meskipun sebagian besar tentang ruang (RAM/flash/disk), ini terkait erat dengan kualitas konten. Jika kami memiliki banyak ruang kosong yang tersedia, kami cenderung mengindeks konten yang lebih jelek. Jika tidak, kami mungkin mendeindeks barang-barang untuk memberi ruang bagi dokumen berkualitas lebih tinggi. pic.twitter.com/jRMkEqdft0
— Gary Illyes (@methode) 15 Mei 2020
Selain itu, Anda harus memperhatikan pembaruan algoritme. Ada kemungkinan algoritme baru diluncurkan, dan laman Anda terpengaruh olehnya.
Sayangnya, deindexing mungkin juga disebabkan oleh bug di pihak Google. Misalnya, Search Engine Land pernah di-deindex karena Google salah berasumsi bahwa situs tersebut diretas.
Larutan
Solusi untuk halaman yang di-deindex terkait erat dengan kualitasnya. Anda harus selalu memastikan halaman Anda menyajikan konten berkualitas terbaik dan terbaru. Jangan berasumsi bahwa setelah halaman diindeks, Anda tidak perlu melakukan apa pun dengannya lagi. Terus pantau dan terapkan perubahan dan peningkatan jika perlu.
[…]Halaman yang jatuh setelah pembaruan inti tidak memiliki kesalahan untuk diperbaiki. Dengan demikian, kami memahami bahwa mereka yang kurang baik setelah perubahan pembaruan inti mungkin masih merasa perlu melakukan sesuatu. Kami menyarankan untuk berfokus pada memastikan Anda menawarkan konten terbaik yang Anda bisa. Itulah yang dicari oleh algoritme kami untuk dihargai.sumber: Google
Setelah memperbaiki masalah, Anda dapat mengirimkan URL tersebut ke Google Search Console untuk membantu Google melihat perubahan lebih cepat.
Masalah arsitektur situs web
Ketika John Mueller ditanya tentang kemungkinan alasan halaman ditandai dengan Crawling – status saat ini tidak diindeks, ia menyebutkan kemungkinan penyebab lain – struktur situs web yang buruk.
Anda tidak dapat memaksa halaman untuk diindeks — itu normal bahwa kami tidak mengindeks semua halaman di semua situs web. Ini bukan masalah dengan "halaman itu", ini lebih ke seluruh situs. Membuat struktur situs yang baik dan memastikan situs memiliki kualitas setinggi mungkin pada dasarnya adalah arahnya.
— johnmu.xml (pribadi) (@JohnMu) 28 Juni 2021
Mari kita bayangkan situasi di mana Anda memiliki halaman berkualitas baik, tetapi satu-satunya cara Google menemukannya adalah karena Anda memasukkannya ke dalam peta situs Anda.
Google mungkin melihat halaman dan merayapinya, tetapi karena tidak ada tautan internal, itu akan menganggap halaman tersebut memiliki nilai yang lebih rendah daripada halaman lain. Tidak ada informasi semantik atau struktural untuk membantu mengevaluasi halaman. Itu mungkin salah satu alasan mengapa Google memutuskan untuk fokus pada halaman lain dan meninggalkan yang ini dari indeks setelah merayapinya.
Larutan
Arsitektur situs web yang baik adalah kunci untuk membantu Anda memaksimalkan peluang untuk diindeks. Ini memungkinkan bot mesin pencari untuk menemukan konten Anda dan lebih memahami hubungan antar halaman.
Itulah mengapa sangat penting untuk menyediakan arsitektur situs web yang baik dan memastikan ada tautan internal ke halaman yang ingin Anda indeks.
Jika Anda ingin mempelajari lebih lanjut tentang struktur situs web, lihat artikel kami tentang Cara Membuat Situs Web yang Berperingkat dan Berkonversi.
Konten duplikat
Adam Gent, seorang freelancer SEO, berbagi kasus menarik dengan komunitas SEO. Halamannya melaporkan Crawling – saat ini tidak diindeks karena Google mengira itu adalah halaman duplikat.
Google ingin menyajikan konten yang unik dan berharga kepada pengguna. Itu sebabnya ketika menyadari selama perayapan bahwa beberapa halaman identik atau hampir identik, mungkin hanya mengindeks salah satunya.
Biasanya, yang lain diberi label sebagai "Duplikat" dalam laporan Cakupan Indeks. Namun, tidak selalu demikian, dan terkadang Google menetapkan Crawling – saat ini bukan status terindeks.
Tidak sepenuhnya jelas mengapa Google memilih Crawled – saat ini tidak diindeks di atas status khusus untuk konten duplikat. Salah satu penjelasan yang mungkin adalah bahwa statusnya akan berubah nanti setelah Google memutuskan apakah ada yang lebih cocok untuk halaman tersebut.
Pilihan lain mungkin bug pelaporan . Google mungkin membuat kesalahan saat menetapkan status. Sayangnya, situasinya lebih menantang karena Merangkak – saat ini tidak diindeks tidak memberi Anda informasi sebanyak status khusus untuk konten duplikat.
Bagaimana cara memeriksa apakah halaman duplikat muncul di hasil pencarian?
- Buka halaman yang tidak diindeks dan salin fragmen teks acak.
- Tempel teks di Google Penelusuran dalam tanda kutip.
- Analisis hasilnya. Jika URL yang berbeda dengan teks yang Anda salin muncul, itu mungkin berarti bahwa halaman Anda tidak diindeks karena Google memilih URL yang berbeda untuk diindeks.
Larutan
Pertama dan terpenting, Anda harus memastikan Anda membuat halaman asli. Jika perlu – tambahkan konten unik.
Sayangnya, duplikat konten mungkin tidak dapat dihindari (misalnya, Anda memiliki versi seluler dan desktop). Anda tidak memiliki banyak kendali atas apa yang muncul di hasil pencarian, tetapi Anda dapat memberikan beberapa petunjuk kepada Google tentang versi aslinya.
Jika Anda melihat banyak duplikat konten yang diindeks, evaluasi elemen berikut:
- Tag kanonik – tag HTML ini memberi tahu mesin telusur versi mana yang asli.
- Tautan internal – pastikan tautan internal mengarah ke konten asli Anda. Google mungkin menggunakannya sebagai indikator halaman mana yang lebih penting.
- Peta Situs XML – pastikan hanya versi kanonik yang ada di peta situs Anda.
Ingatlah bahwa ini hanya petunjuk, dan Google tidak berkewajiban untuk mengikutinya. Dalam kasus yang dijelaskan oleh Adam Gent, Google memilih versi umpan RSS untuk diindeks, meskipun banyak sinyal kanonikalisasi menunjuk ke URL asli yang berbeda. Adam memecahkan masalah dengan menyiapkan 404 untuk memastikan hanya versi asli yang tetap ada. Dia juga menyarankan untuk menyiapkan header HTTP X-robots di semua URL feed agar tidak diindeks.
Dirayapi – saat ini tidak diindeks vs. Ditemukan – saat ini tidak diindeks
Status Perayapan – saat ini tidak diindeks biasanya dikacaukan dengan masalah pengindeksan lain dalam laporan Cakupan Indeks: Ditemukan – saat ini tidak diindeks.
Kedua status menunjukkan bahwa halaman tidak diindeks. Namun, dalam kasus Crawling – saat ini tidak diindeks, Google telah mengunjungi halaman tersebut. Sementara itu, di Ditemukan – saat ini tidak diindeks, URL-nya diketahui oleh Google, tetapi, karena alasan tertentu, belum dirayapi.
| Dirayapi – saat ini tidak diindeks | Ditemukan – saat ini tidak diindeks | |
| Halaman ditemukan oleh Google | Ya | Ya |
| Halaman yang dikunjungi oleh Google | Ya | Tidak |
| Halaman diindeks | Tidak | Tidak |
Beberapa alasan untuk status ini mungkin serupa, termasuk halaman berkualitas buruk dan masalah tautan internal. Namun, ketika Anda melihat status Ditemukan – saat ini tidak diindeks, Anda perlu menyelidiki lebih lanjut mengapa Google tidak dapat atau tidak ingin mengakses halaman tersebut. Misalnya, ini mungkin menunjukkan masalah dengan kualitas keseluruhan situs web, masalah anggaran perayapan, atau kelebihan server.
Membungkus
Dirayapi – saat ini tidak diindeks terutama terkait dengan kualitas halaman, tetapi pada kenyataannya, ini dapat menunjukkan lebih banyak masalah, seperti arsitektur situs web atau konten duplikat.
Berikut adalah takeaways utama dari artikel yang dapat membantu Anda menangani Crawling – status saat ini tidak diindeks:
- Tambahkan konten unik dan berharga ke halaman Anda. Setelah Anda melakukannya, kirimkan URL tersebut ke Google Search Console. Dengan cara ini, Google dapat melihat perubahan lebih cepat.
- Tinjau arsitektur situs web Anda dan pastikan ada tautan internal ke halaman berharga Anda.
- Putuskan halaman mana yang harus dan tidak boleh diindeks untuk membantu Google memprioritaskan URL yang paling berharga.
Jika Anda memerlukan bantuan untuk mengatasi Status Perayapan — saat ini tidak diindeks di situs web Anda, layanan SEO teknis kami adalah yang Anda cari.