
Google検索コンソールで「クロール済み–現在インデックスに登録されていない」を修正する方法
公開: 2021-12-28Googleのドキュメントでは、クロール済み–現在のインデックスステータスは次のように定義されていません。
ページはGoogleによってクロールされましたが、インデックスに登録されていません。 将来、インデックスが作成される場合とされない場合があります。 クロールのためにこのURLを再送信する必要はありません。出典: Google
この説明を読むと、特にステータスがビジネスにとって重要なページに影響を与える場合は、イライラするかもしれません。 Googleの定義では、何が起こったのか、次に何をするのかは明確にされていません。 Googlebotがページをクロールしたが、何らかの理由でインデックスに登録しないことにしたということだけです。
私たちの調査によると、クロール済み–現在インデックス付けされていないステータスは、インデックスカバレッジレポートで報告される最も一般的な問題です。 それはおそらくあなたがすでにそれを経験したか、またはあなたが将来それを経験する可能性が高いことを意味します。
できるだけ早く問題を解決することが重要です。 結局のところ、ページがインデックスに登録されていない場合、検索結果には表示されず、Googleからのオーガニックトラフィックも取得されません。
この記事では、クロールの考えられる原因について説明します。現在、インデックスのステータスとその修正方法は示していません。
クロール済み–現在インデックス付けされていないステータスはどこにありますか?
ステータスは、インデックスカバレッジレポートとGoogle検索コンソールのURL検査ツールで確認できます。
インデックスカバレッジレポート
クロール–現在インデックスに登録されていないのは「除外」カテゴリに属します。これは、ページがインデックスに登録されていないのは間違いではないとGoogleが考えていることを示しています。
これらのページは通常、インデックスに登録されていないため、適切であると考えています。 これらのページは、インデックスが作成されたページと重複しているか、サイトの何らかのメカニズムによってインデックスが作成されていないか、エラーではないと思われる理由でインデックスが作成されていません。出典: Google
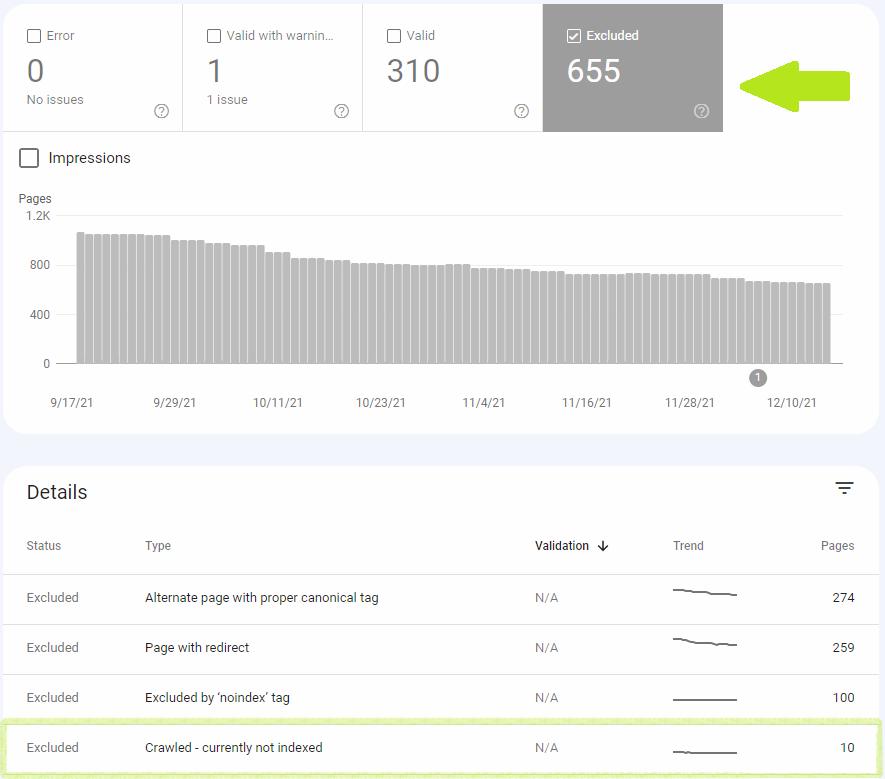
[クロール済み–現在インデックスに登録されていないステータス]をクリックすると、影響を受けるURLのリストが表示されます。 あなたはそれを調べて、あなたにとって最も価値のあるページの問題を修正することを優先するべきです。
レポートはエクスポートすることもできます。 ただし、エクスポートできるURLは最大1000個までです。 より多くのページが影響を受ける場合は、サイトマップに固有のページをフィルタリングすることで、エクスポートされるURLの数を増やすことができます。 たとえば、それぞれが1000のURLを持つ2つのサイトマップがある場合、両方を別々にエクスポートできます。
URL検査ツール
Google検索コンソールのURL検査ツールは、クロールされている(現在はインデックスに登録されていない)URLについても通知できます。
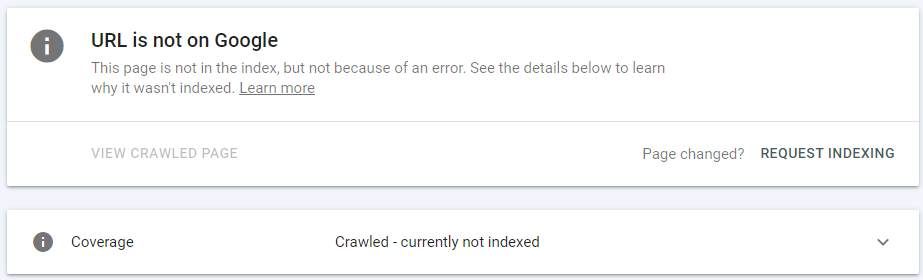
ツールの上部セクションには、URLがGoogleで見つかるかどうかが表示されます。 検査されたURLがインデックスカバレッジレポートの除外カテゴリに属している場合、URL検査ツールは次のように報告します。「ページはインデックスに含まれていませんが、エラーが原因ではありません。」
以下に、検査されたURLの現在のカバレッジステータスに関するより具体的な情報を示します。上記の場合、URLはクロールされていましたが、現在はインデックスに登録されていません。
バグの報告:ページが実際にインデックスに登録されている可能性があります
クロール済み–現在インデックスが作成されていないステータスに気付いた後、最初に行うべきことは、ページが実際にインデックスに登録されていないかどうかを調査することです。
クロール済みとしてマークされたページが表示されることは珍しくありません。現在、インデックスカバレッジレポートでインデックスが作成されていませんが、URL検査ツールはページが実際にインデックスに登録されていることを示します。
URL検査ツールを使用すると、次のような特定のURLに関する詳細を確認できます。
- インデックス作成の問題、
- 構造化データエラー、
- モバイルユーザビリティ、
- ロードされたリソース(JavaScriptなど)を表示します。
URLのインデックス作成をリクエストしたり、レンダリングされたバージョンのページを表示したりすることもできます。
GoogleのJohnMullerは、GoogleのSEO営業時間中のインデックスカバレッジレポートとURL検査ツールの違いに関する問題に対処しました。
最近、Twitterでこのようなスレッドをいくつか見ました。そこでは、検索コンソールでインデックスに登録されていないというフラグが付けられたURLが表示されました。 そして、それらを個別にチェックすると、実際にインデックスが作成されます。 私はまだそこで何が起こっているのか正確にはわかりません。 […]私の疑いは、それはタイミングの問題であるということです。検索コンソールレポートに表示され、その後、時間の経過とともにインデックスが作成されます。 その後、ある時点で、彼らは再びレポートから脱落するでしょう。 そして、何らかの理由で、中退は本来よりも少し時間がかかります。出典:ジョン・ミューラー
ジョンが言ったように、それは単にこれら2つのツール間の遅延とデータ同期の問題である可能性があり、ステータスは時間の経過とともにインデックスカバレッジレポートで更新される可能性があります。
ただし、それは必ずしも単なる遅延ではありません。 時々それは報告のバグです。
9月に、インデックスに登録された記事の一部がクロールされたと報告していることに気付きました。現在はインデックスに登録されていません。
GSCを使用すると、どのページがクロールされているが、Googleによってインデックスに登録されていないかを確認できます。
GSCは、いくつかの記事をクロール済みとしてリストしましたが、現在はインデックスに登録されていません。
ただし、URL検査ツールはこれらをインデックス付きとして表示します。
そして、それらは実際に索引付けされています。
洞察、#SEOTwitter? pic.twitter.com/xKv0IYpGLa
— Onely(@OnelyCom)2021年9月16日
古い記事も影響を受けたので、それは間違いなく遅延の問題ではありませんでした。
その後まもなく、リリーレイを含む他のSEOがこの問題に気づき始めました。
他の人はすでにこれについてツイートしていますが、GSCの「クロールされたインデックスなし」レポート(最近のクロール日を含む)には、実際にはインデックス付きのURLであるURLの例がたくさんあります。
個々のURLを調べると、多くの場合、以下のメッセージが表示されます。
考え@danielwaisberg@googlesearchc? pic.twitter.com/i1XfcvldEq
—リリーレイ(@lilyraynyc)2021年9月28日
この状況で何をしますか? どのレポートを信頼しますか?
通常、 URL検査ツールは、インデックスカバレッジレポートよりも最新のデータを表示します。 そのため、これらのレポートから選択する必要がある場合は、URL検査ツールを常に信頼する必要があります。
クロールされた状態の原因と解決策–現在インデックスに登録されていないステータス
それでは、問題の根底にある問題に取り掛かりましょう。ステータスが表示される原因と、それを修正するためにできることです。
Googleは、ページがクロールされたがインデックスに登録されなかった理由を明確に示していませんが、ステータスが表示される理由はいくつか考えられます。
- インデックス作成の遅延、
- ページが品質基準を満たしていない、
- ページのインデックスが解除され、
- ウェブサイトのアーキテクチャの問題、
- 重複するコンテンツの問題。
インデックス作成の遅延
Googleがページにアクセスすることは珍しくありませんが、インデックスを作成するには時間がかかります。 インターネットは無限に大きく、Googleはどのページが最初にインデックスに登録されるかを優先する必要があります。
私の示しました。 これが私の調査結果の一部です。
- Googleは、公開されてから1日後にインデックス可能なURLのわずか56%をインデックスに登録します。
- 2週間後、URLの87%だけがインデックスに登録されます。
出典: Tomek Rudzki

ページを公開したばかりの場合、まだインデックスに登録されていないのはまったく正常なことであり、Googleがコンテンツのインデックスを作成するまでもう少し待つ必要があります。
解決
短期的にはページのクロールとインデックス作成に影響を与えることはできませんが、長期的にはWebサイトを支援するためにできることがいくつかあります。
- Googleがサイトの適切なページに優先順位を付けるのに役立つインデックス戦略を作成します。 そのためには、インデックスを作成するページと、それをGoogleに伝達するための最良の方法を決定する必要があります。
- 気になるページへの内部リンクがあることを確認してください。 これは、Googleがページを見つけて、そのコンテキストについて詳しく知るのに役立ちます。
- 十分に最適化されたサイトマップを作成します。 これは、貴重なURLをリストした単純なテキストファイルです。 Googleは、ページをより速く見つけるためのロードマップとしてそれを使用します。
ページが品質基準を満たしていない
Googleは、インターネット上のすべてのページをインデックスに登録することはできません。 そのストレージスペースは限られているため、低品質のコンテンツを除外する必要があります。
Googleの目標は、ユーザーの意図に最もよく答える最高品質のページを提供することです。 これは、ページの品質が低い場合、Googleはそのページを無視して、高品質のコンテンツに使用できるストレージスペースを残す可能性が高いことを意味します。 そして、将来的には品質基準が厳しくなることが予想されます。
解決
Webサイトの所有者は、ページが高品質のコンテンツを提供していることを確認する必要があります。 ユーザーの意図を満足させる可能性があるかどうかを確認し、必要に応じて高品質のコンテンツを追加します。 Googleは、コンテンツの価値を判断するのに役立つ質問のリストを提供しています。 それらのいくつかを次に示します。
- コンテンツは、独自の情報、報告、調査、または分析を提供していますか?
- コンテンツは、明白ではない洞察に満ちた分析や興味深い情報を提供していますか?
- これは、ブックマークしたり、友達と共有したり、おすすめしたりしたい種類のページですか?
- コンテンツが他のソースを利用している場合、それらのソースを単にコピーまたは書き換えることを避け、代わりに実質的な付加価値と独創性を提供しますか?
出典: Google
さらに、GoogleのQualityRatersGuidelinesの高品質コンテンツに関するヒントを使用できます。 このドキュメントは主に検索品質評価者がWebサイトの品質を評価することを目的としていますが、Webマスターはこのドキュメントを使用して、自分のサイトを改善する方法についての洞察を得ることができます。 詳細については、品質評価者ガイドラインに関するガイドをご覧ください。
ユーザー作成コンテンツ
ユーザー生成コンテンツは、品質の観点から問題になる可能性があります。
たとえば、フォーラムがあり、誰かが質問をしたとします。 将来的には貴重な返信がたくさんあるかもしれませんが、クロールの時点では何もなかったので、Googleはそのページを低品質のコンテンツとして分類する可能性があります。
この状況から身を守るために何をすべきか?
Quoraは、この問題に対する優れた戦略を考え出しました。 すべての未回答の質問には、URLに「/unanswered/」プレフィックスが付いています。
次に例を示します: https ://www.quora.com/unanswered/Are-you-really-happy-with-your-results
robots.txtファイルは、URLに/unanswered/が含まれるすべてのページをブロックします。 これは、Googlebotがそれらをクロールできないことを意味します。
質問への回答があると、URLが変更され、クロールできるようになります。 このようにして、Quoraはユーザーによって生成された低品質のコンテンツへのアクセスをブロックします。
ページのインデックスが解除されました
URLはクロールされた状態になる可能性があります。過去にインデックスが作成されていたため、現在はインデックスに登録されていませんが、Googleは時間の経過とともにインデックスを解除することを決定しました。
一部のものがインデックスから消える理由がわからない場合は、それらが高品質のコンテンツに置き換えられている可能性があります。
インデックスの選択は、主に(RAM /フラッシュ/ディスク)スペースに関するものですが、コンテンツの品質と密接に関係しています。 利用可能な空き容量がたくさんある場合は、より粗雑なコンテンツのインデックスを作成する可能性が高くなります。 そうしないと、インデックスを解除して、より高品質のドキュメント用のスペースを作ることができます。 pic.twitter.com/jRMkEqdft0
—ゲイリー簿理/경리イリーズ(@methode)2020年5月15日
さらに、アルゴリズムの更新に注意を払う必要があります。 新しいアルゴリズムが公開され、ページがその影響を受けた可能性があります。
残念ながら、インデックス解除は、Google側のバグによっても引き起こされる可能性があります。 たとえば、 Googleがサイトがハッキングされたと誤って想定したため、検索エンジンランドのインデックスが解除されたことがあります。
解決
インデックス解除されたページの解決策は、その品質と密接に関連しています。 ページが最高品質のコンテンツを提供し、最新であることを常に確認する必要があります。 ページがインデックスに登録されると、それを二度と何もする必要がないと思い込まないでください。 それを監視し続け、必要に応じて変更と改善を実装します。
[…]コアアップデート後にドロップするページには、修正するのに問題はありません。 とはいえ、コアアップデートの変更後にうまくいかない人は、まだ何かをする必要があると感じるかもしれないことを私たちは理解しています。 可能な限り最高のコンテンツを提供できるようにすることに重点を置くことをお勧めします。 それが私たちのアルゴリズムが報いようとしていることです。出典: Google
問題を修正したら、それらのURLをGoogle検索コンソールに送信して、Googleが変更にすばやく気付くようにすることができます。
ウェブサイトのアーキテクチャの問題
John Muellerは、ページがクロールされた(現在はインデックスに登録されていない)とマークされた考えられる理由について尋ねられたとき、別の考えられる原因であるWebサイトの構造の悪さについて言及しました。
ページを強制的にインデックスに登録することはできません。通常、すべてのWebサイトのすべてのページにインデックスを作成するわけではありません。 これは「そのページ」の問題ではなく、サイト全体の問題です。 優れたサイト構造を作成し、サイトが可能な限り最高の品質であることを確認することが、本質的に方向性です。
— johnmu.xml(個人)(@ JohnMu)2021年6月28日
あなたが良質のページを持っている状況を想像してみましょう、しかしグーグルがそれを見つけた唯一の方法はあなたがそれをあなたのサイトマップに置いたからです。
Googleはそのページを見てクロールするかもしれませんが、内部リンクがないため、そのページの価値は他のページよりも低いと見なされます。 ページの評価に役立つセマンティック情報や構造情報はありません。 これが、Googleが他のページに焦点を合わせ、クロール後にこのページをインデックスから除外することを決定した理由の1つである可能性があります。
解決
優れたWebサイトのアーキテクチャは、インデックスに登録される可能性を最大化するための鍵です。 これにより、検索エンジンボットはコンテンツを発見し、ページ間の関係をよりよく理解できます。
そのため、優れたWebサイトアーキテクチャを提供し、インデックスを作成するページへの内部リンクがあることを確認することが重要です。
ウェブサイトの構造について詳しく知りたい場合は、ランク付けして変換するウェブサイトを構築する方法に関する記事をご覧ください。
重複するコンテンツ
SEOフリーランサーのAdamGentは、SEOコミュニティと興味深い事例を共有しました。 彼のページはクロールされたと報告していました– Googleが重複ページであると考えたため、現在インデックスに登録されていません。
Googleは、ユニークで価値のあるコンテンツをユーザーに提供したいと考えています。 そのため、クロール中に一部のページが同一またはほぼ同一であることに気付いた場合、そのうちの1つだけがインデックスに登録される可能性があります。
通常、もう1つは、インデックスカバレッジレポートで「重複」とラベル付けされます。 ただし、常にそうであるとは限らず、Googleがクロール済み(現在はインデックスに登録されていないステータス)を割り当てる場合があります。
GoogleがCrawledを選択する理由は完全には明らかではありません。現在、重複コンテンツの専用ステータスでインデックスが作成されていません。 考えられる理由の1つは、Googleがそのページにより適したものがあるかどうかを決定した後、ステータスが後で変更されるというものです。
別のオプションは、バグの報告である可能性があります。 Googleは、ステータスの割り当て中に単に間違いを犯す可能性があります。 残念ながら、クロール済み–現在インデックスが作成されていないため、重複コンテンツの専用ステータスほど多くの情報が得られないため、状況はさらに困難になります。
重複するページが検索結果に表示されているかどうかを確認するにはどうすればよいですか?
- インデックスが作成されていないページに移動し、ランダムなテキストフラグメントをコピーします。
- Google検索のテキストを引用符で囲んで貼り付けます。
- 結果を分析します。 コピーしたテキストとは別のURLが表示される場合は、Googleがインデックスに別のURLを選択したため、ページがインデックスに登録されていない可能性があります。
解決
何よりもまず、オリジナルのページを作成する必要があります。 必要に応じて–独自のコンテンツを追加します。
残念ながら、コンテンツの重複は避けられない場合があります(たとえば、モバイルバージョンとデスクトップバージョンがあります)。 検索結果に表示される内容をあまり制御することはできませんが、元のバージョンに関するヒントをGoogleに提供することはできます。
インデックスに登録された重複コンテンツが多数ある場合は、次の要素を評価してください。
- 標準タグ–これらのHTMLタグは、どのバージョンが元のバージョンであるかを検索エンジンに通知します。
- 内部リンク–内部リンクが元のコンテンツを指していることを確認します。 グーグルはどのページがより重要であるかの指標としてそれを使うかもしれません。
- XMLサイトマップ–正規バージョンのみがサイトマップに含まれていることを確認します。
これらは単なるヒントであり、Googleはそれらに従う義務を負わないことを忘れないでください。 Adam Gentが説明したケースでは、多くの正規化シグナルが別の元のURLを指していても、Googleはインデックスを作成するためにRSSフィードバージョンを選択しました。 Adamは、元のバージョンのみが残るように404を設定することで、この問題を解決しました。 彼はまた、すべてのフィードURLにX-robots HTTPヘッダーを設定すると、それらのインデックスが作成されなくなることを提案しました。
クロール–現在インデックス付けされていないvs.検出済み–現在インデックス付けされていない
クロール済み–現在インデックス付けされていないステータスは、通常、インデックスカバレッジレポートの別のインデックス作成の問題と混同されます:検出済み–現在インデックス付けされていません。
両方のステータスは、ページがインデックスに登録されていないことを示しています。 ただし、クロールされた場合–現在インデックスに登録されていないため、Googleはすでにページにアクセスしています。 一方、Discovered –現在インデックスに登録されていないURLは、Googleに認識されていますが、何らかの理由で、まだクロールされていません。
| クロール–現在インデックス付けされていません | 発見済み–現在インデックスに登録されていません | |
| Googleによって発見されたページ | はい | はい |
| Googleがアクセスしたページ | はい | いいえ |
| インデックスに登録されたページ | いいえ | いいえ |
これらのステータスの理由のいくつかは、低品質のページや内部リンクの問題など、類似している可能性があります。 ただし、Discovered –現在インデックスに登録されていないステータスが表示された場合は、Googleがページにアクセスできなかった理由またはアクセスしたくない理由をさらに調査する必要があります。 たとえば、Webサイト全体の全体的な品質の問題、クロールの予算の問題、またはサーバーの過負荷を示している可能性があります。
まとめ
クロール–現在インデックスに登録されていないのは主にページの品質に関連していますが、実際には、Webサイトのアーキテクチャや重複コンテンツなど、さらに多くの問題を示している可能性があります。
クロール済み–現在インデックス付けされていないステータスに対処するのに役立つ記事からの重要なポイントは次のとおりです。
- ユニークで価値のあるコンテンツをページに追加します。 完了したら、それらのURLをGoogle検索コンソールに送信します。 このように、Googleは変更にすばやく気付く可能性があります。
- Webサイトのアーキテクチャを確認し、貴重なページへの内部リンクがあることを確認してください。
- Googleが最も価値のあるURLに優先順位を付けるのに役立つように、インデックスを作成するページとインデックスを作成しないページを決定します。
クロールされた(現在Webサイトでインデックスに登録されていないステータス)に対処するためのサポートが必要な場合は、当社の技術的なSEOサービスがお探しです。