
Comment réparer "Exploré - Actuellement non indexé" dans Google Search Console
Publié: 2021-12-28La documentation de Google définit le statut Crawled - actuellement non indexé comme :
La page a été explorée par Google, mais pas indexée. Il peut ou non être indexé à l'avenir; pas besoin de resoumettre cette URL pour exploration.source : Google
La lecture de cette explication peut sembler frustrante, surtout si le statut affecte une page importante pour votre entreprise. La définition de Google ne clarifie pas ce qui s'est passé et ce que vous pourriez faire ensuite. Tout ce qu'il dit, c'est que Googlebot a exploré votre page mais, pour une raison quelconque, a décidé de ne pas l'indexer.
Selon nos recherches, le statut Crawled – actuellement non indexé est le problème le plus fréquemment signalé dans le rapport Index Coverage. Cela signifie que vous en avez probablement déjà fait l'expérience ou que vous en ferez probablement l'expérience à l'avenir.
Il est crucial de résoudre le problème dès que possible. Après tout, si votre page n'est pas indexée, elle n'apparaîtra pas dans les résultats de recherche et n'obtiendra aucun trafic organique de Google.
Cet article présente les causes possibles de l'état Crawled – actuellement non indexé et les moyens de les corriger .
Où pouvez-vous trouver le statut Crawled – actuellement non indexé ?
Vous pouvez trouver l'état dans le rapport de couverture de l'index et l' outil d'inspection d'URL dans Google Search Console.
Rapport de couverture d'index
Crawled - actuellement non indexé appartient à la catégorie "Exclu", ce qui indique que Google ne pense pas que ce soit une erreur si la page n'est pas indexée.
Ces pages ne sont généralement pas indexées, et nous pensons que c'est approprié. Ces pages sont soit des doublons de pages indexées, soit bloquées de l'indexation par un mécanisme sur votre site, ou autrement non indexées pour une raison qui, selon nous, n'est pas une erreur.source : Google
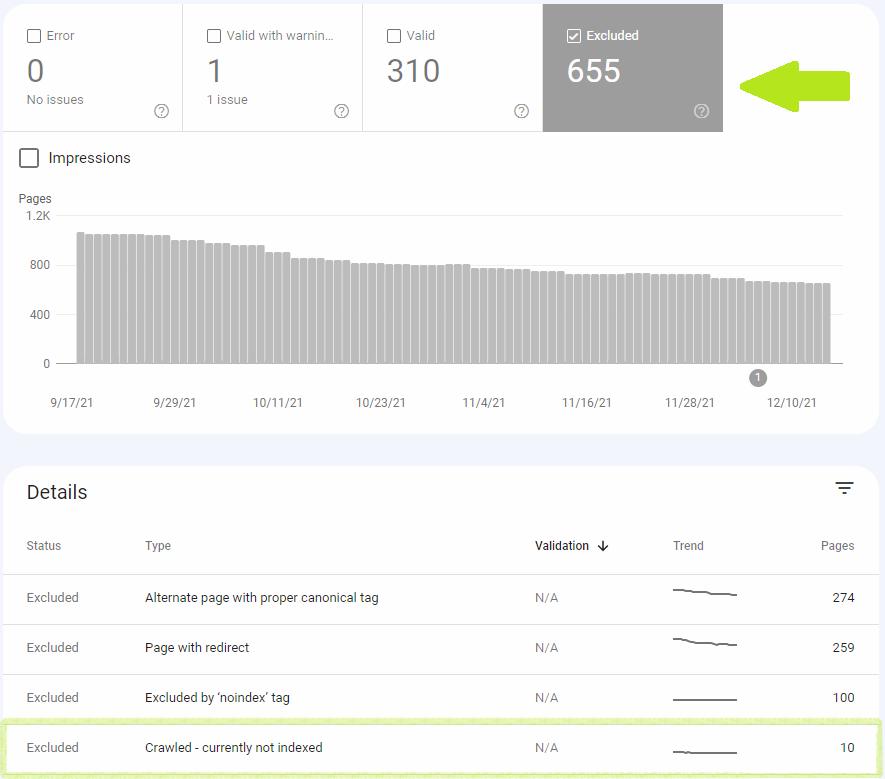
Après avoir cliqué sur le statut Crawled – Actuellement non indexé, vous verrez une liste des URL concernées. Vous devriez l'examiner et prioriser la résolution du problème pour les pages les plus précieuses pour vous.
Le rapport est également disponible pour l'exportation. Cependant, vous ne pouvez exporter que jusqu'à 1 000 URL. Si plusieurs pages sont concernées, vous pouvez augmenter le nombre d'URL exportées en filtrant les pages spécifiques aux sitemaps. Par exemple, si vous avez deux sitemaps, chacun avec 1000 URL, vous pouvez les exporter séparément.
Outil d'inspection d'URL
L'outil d'inspection d'URL de Google Search Console peut également vous informer sur les URL qui sont explorées - actuellement non indexées.
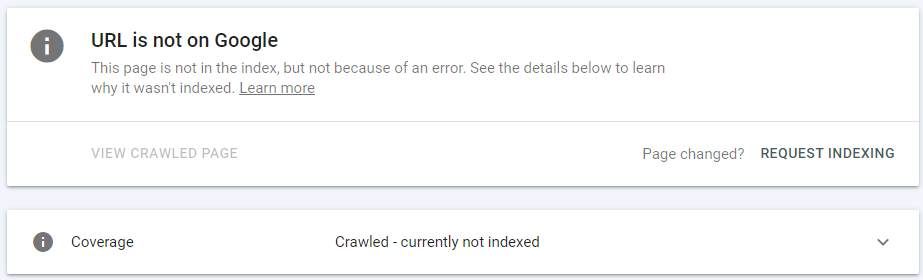
La section supérieure de l'outil vous informe si l'URL peut être trouvée sur Google ou non. Si l'URL inspectée appartient à la catégorie Exclue du rapport Couverture de l'index, l'outil d'inspection d'URL signale ce qui suit : "La page n'est pas dans l'index, mais pas à cause d'une erreur."
Ci-dessous, vous trouverez des informations plus spécifiques sur l'état actuel de la couverture de l'URL inspectée - dans le cas ci-dessus, l'URL a été explorée - actuellement non indexée.
Signaler un bogue : votre page est peut-être en fait indexée
Après avoir remarqué le statut Crawled - actuellement non indexé, la première chose à faire est de vérifier si votre page n'est vraiment pas indexée.
Il n'est pas rare de voir une page marquée comme explorée - actuellement non indexée dans le rapport de couverture de l'index, tandis que l'outil d'inspection d'URL indique que la page est réellement indexée.
L'outil d'inspection d'URL vous permet de vérifier les détails d'une URL spécifique, notamment :
- Problèmes d'indexation,
- Erreurs de données structurées,
- Convivialité mobile,
- Afficher les ressources chargées (par exemple, JavaScript).
Vous pouvez également demander l'indexation d'une URL ou afficher une version rendue d'une page.
John Muller de Google a abordé le problème des différences entre le rapport de couverture de l'index et l'outil d'inspection d'URL pendant les heures de bureau SEO de Google :
J'ai récemment vu des fils comme celui-ci sur Twitter où les gens ont vu des URL signalées comme n'étant pas indexées dans la Search Console. Et puis, lorsque vous les vérifiez individuellement, ils sont en fait indexés. Je ne sais pas encore exactement ce qui se passe là-bas. […] Je soupçonne que c'est plus une question de timing - nous les montrons dans le rapport de la Search Console, puis ils sont indexés au fil du temps. Puis, à un moment donné, ils abandonnaient à nouveau le rapport. Et pour une raison quelconque, le décrochage prend un peu plus de temps qu'il ne le devrait.source : John Muller
Comme l'a dit John, il peut s'agir simplement d'un problème de retard et de synchronisation des données entre ces deux outils, et l'état peut être mis à jour dans le rapport Index Coverage au fil du temps.
Cependant, ce n'est pas toujours juste un retard. Parfois, c'est un bogue de rapport.
En septembre, nous avons remarqué que certains de nos articles indexés signalaient Crawled - actuellement non indexé.
Avec GSC, vous pouvez vérifier lesquelles de vos pages sont explorées mais toujours pas indexées par Google.
GSC a répertorié quelques-uns de nos articles comme explorés - actuellement non indexés.
Cependant, l'outil d'inspection d'URL les affiche comme indexées.
Et ils sont en fait indexés.
Des idées, #SEOTwitter ? pic.twitter.com/xKv0IYpGLa
– Onely (@OnelyCom) 16 septembre 2021
Ce n'était certainement pas un problème de retard car les anciens articles étaient également affectés.
Peu de temps après, d'autres référenceurs, dont Lily Ray, ont commencé à remarquer ce problème.
D'autres ont déjà tweeté à ce sujet, mais je vois de nombreux exemples d'URL dans le rapport "Crawled, Not Indexed" de GSC (avec des dates d'exploration récentes) qui sont, en fait, des URL indexées.
L'inspection d'URL individuelles entraîne souvent le message ci-dessous.
Pensées @danielwaisberg @googlesearchc ? pic.twitter.com/i1XfcvldEq
– Lily Ray (@lilyraynyc) 28 septembre 2021
que-faire dans cette situation? A quel rapport se fier ?
En règle générale, l' outil d'inspection d'URL affiche des données plus à jour que le rapport sur la couverture de l'index. C'est pourquoi vous devriez toujours faire davantage confiance à l'outil d'inspection d'URL lorsque vous êtes obligé de choisir entre ces rapports.
Causes et solutions pour le statut Crawled - actuellement non indexé
Maintenant, allons au fond du problème - qu'est-ce qui fait apparaître l'état et ce que vous pouvez faire pour le résoudre.
Google ne vous donne pas de réponse claire sur la raison pour laquelle votre page a été explorée mais pas indexée, mais il existe plusieurs raisons possibles pour lesquelles l'état peut apparaître, notamment :
- Délai d'indexation,
- La page ne répond pas aux normes de qualité,
- La page a été désindexée,
- Problème d'architecture de site Web,
- Problèmes de contenu dupliqué.
Délai d'indexation
Il n'est pas rare que Google visite une page, mais il faut un certain temps pour l'indexer. Internet est infiniment grand et Google doit hiérarchiser les pages indexées en premier.
Dans mon montré combien de temps il faut pour que les pages de sites Web populaires soient indexées. Voici quelques résultats de mon enquête :
- Google n'indexe que 56 % des URL indexables 1 jour après leur publication.
- Après 2 semaines, seulement 87% des URL sont indexées.
source : Tomek Rudzki
Si vous venez de publier votre page, il est tout à fait normal qu'elle ne soit pas encore indexée et que vous deviez attendre un peu plus longtemps que Google indexe votre contenu.
Solution
Vous ne pouvez pas influencer l'exploration et l'indexation de votre page à court terme, mais il y a quelques choses que vous pouvez faire pour aider votre site Web à long terme :
- Créez une stratégie d'indexation pour aider Google à prioriser les bonnes pages sur votre site. Pour ce faire, vous devez décider quelles pages doivent être indexées et la meilleure méthode pour le communiquer à Google.
- Assurez-vous qu'il existe des liens internes vers les pages qui vous intéressent. Cela aidera Google à trouver les pages et à en savoir plus sur leur contexte.
- Créez un sitemap bien optimisé. Il s'agit d'un simple fichier texte qui répertorie vos précieuses URL. Google l'utilisera comme feuille de route pour trouver les pages plus rapidement.
La page ne répond pas aux normes de qualité
Google ne peut pas indexer toutes les pages sur Internet. Son espace de stockage est limité, et c'est pourquoi il doit filtrer le contenu de mauvaise qualité.

L'objectif de Google est de fournir des pages de la plus haute qualité qui répondent le mieux aux intentions des utilisateurs. Cela signifie que si une page est de qualité inférieure, Google l'ignorera très probablement pour laisser l'espace de stockage disponible pour un contenu de meilleure qualité. Et nous pouvons nous attendre à ce que les normes de qualité deviennent de plus en plus strictes à l'avenir.
Solution
En tant que propriétaire de site Web, vous devez vous assurer que votre page fournit un contenu de haute qualité. Vérifiez s'il est susceptible de satisfaire l'intention de vos utilisateurs et ajoutez du contenu de bonne qualité si nécessaire. Google propose une liste de questions pour vous aider à déterminer la valeur de votre contenu. En voici quelques uns:
- Le contenu fournit-il des informations, des rapports, des recherches ou des analyses originaux ?
- Le contenu fournit-il une analyse perspicace ou des informations intéressantes qui vont au-delà de l'évidence ?
- Est-ce le genre de page que vous voudriez ajouter à vos favoris, partager avec un ami ou recommander ?
- Si le contenu s'appuie sur d'autres sources, évite-t-il simplement de copier ou de réécrire ces sources et apporte-t-il à la place une valeur et une originalité supplémentaires substantielles ?
source : Google
De plus, vous pouvez utiliser les conseils sur la qualité du contenu des directives de qualité des évaluateurs de Google. Même si le document est principalement destiné aux évaluateurs de la qualité de la recherche pour évaluer la qualité d'un site Web, les webmasters peuvent l'utiliser pour obtenir des informations sur la manière d'améliorer leurs propres sites. Si vous souhaitez en savoir plus, consultez notre guide sur les lignes directrices des évaluateurs de qualité.
Contenu généré par l'utilisateur
Le contenu généré par l'utilisateur peut être un problème du point de vue de la qualité.
Par exemple, supposons que vous ayez un forum et que quelqu'un pose une question. Même s'il pourrait y avoir de nombreuses réponses utiles à l'avenir, au moment de l'exploration, il n'y en avait pas, donc Google peut classer la page comme un contenu de mauvaise qualité.
Que faire pour se protéger de cette situation ?
Quora a proposé une excellente stratégie pour résoudre le problème. Chaque question sans réponse a le préfixe "/sans réponse/" dans l'URL.
Voici un exemple : https://www.quora.com/unanswered/Are-you-really-happy-with-your-results
Le fichier robots.txt bloque toutes les pages avec /unanswered/ dans leurs URL. Cela signifie que Googlebot ne peut pas les explorer.
Une fois qu'il y a une réponse à la question, l'URL change et devient disponible pour l'exploration. De cette façon, Quora bloque l'accès au contenu de mauvaise qualité généré par les utilisateurs.
La page a été désindexée
Une URL peut souffrir du statut Crawled - actuellement non indexé car elle a été indexée dans le passé, mais Google a décidé de la désindexer au fil du temps.
Si vous vous demandez pourquoi certaines choses peuvent disparaître de l'index, il est probable qu'elles soient simplement remplacées par du contenu de meilleure qualité.
La sélection d'index, bien qu'il s'agisse en grande partie d'espace (RAM/flash/disque), est étroitement liée à la qualité du contenu. Si nous avons des tonnes d'espace libre disponible, nous sommes plus susceptibles d'indexer un contenu plus merdique. Si nous ne le faisons pas, nous pourrions désindexer des éléments pour faire de la place à des documents de meilleure qualité. pic.twitter.com/jRMkEqdft0
– Gary 鯨理/경리 Illyes (@methode) 15 mai 2020
De plus, vous devez faire attention aux mises à jour des algorithmes. Il est possible qu'un nouvel algorithme ait été déployé et que votre page en ait été affectée.
Malheureusement, la désindexation peut également être causée par un bogue du côté de Google. Par exemple, Search Engine Land a été désindexé parce que Google a supposé à tort que le site avait été piraté.
Solution
La solution aux pages désindexées est étroitement liée à sa qualité. Vous devez toujours vous assurer que votre page propose un contenu de la meilleure qualité et qu'elle est à jour. Ne présumez pas qu'une fois qu'une page est indexée, vous n'avez plus jamais besoin de faire quoi que ce soit avec elle. Continuez à le surveiller et mettez en œuvre des changements et des améliorations si nécessaire.
[…]les pages qui tombent après une mise à jour principale n'ont rien de mal à corriger. Cela dit, nous comprenons que ceux qui réussissent moins bien après un changement de mise à jour de base peuvent toujours ressentir le besoin de faire quelque chose. Nous vous suggérons de vous assurer que vous offrez le meilleur contenu possible. C'est ce que nos algorithmes cherchent à récompenser.source : Google
Après avoir résolu les problèmes, vous pouvez soumettre ces URL à Google Search Console pour aider Google à remarquer les changements plus rapidement.
Problème d'architecture du site
Lorsque John Mueller a été interrogé sur les raisons possibles pour lesquelles une page était marquée avec le statut Crawled - actuellement non indexé, il a mentionné une autre cause possible - une mauvaise structure du site Web.
Vous ne pouvez pas forcer l'indexation des pages. Il est normal que nous n'indexions pas toutes les pages de tous les sites Web. Ce n'est pas un problème avec "cette page", c'est plus à l'échelle du site. Créer une bonne structure de site et s'assurer que le site est de la meilleure qualité possible est essentiellement la direction.
– johnmu.xml (personnel) (@JohnMu) 28 juin 2021
Imaginons une situation où vous avez une page de bonne qualité, mais la seule façon dont Google l'a trouvée est parce que vous l'avez mise dans votre sitemap.
Google pourrait regarder la page et l'explorer, mais comme il n'y a pas de liens internes, il supposerait que la page a moins de valeur que les autres pages. Il n'y a aucune information sémantique ou structurelle pour l'aider à évaluer la page. C'est peut-être l'une des raisons pour lesquelles Google a décidé de se concentrer sur d'autres pages et de laisser celle-ci hors de l'index après l'avoir explorée.
Solution
Une bonne architecture de site Web est essentielle pour vous aider à maximiser les chances d'être indexé. Il permet aux robots des moteurs de recherche de découvrir votre contenu et de mieux comprendre la relation entre les pages.
C'est pourquoi il est crucial de fournir une bonne architecture de site Web et de s'assurer qu'il existe des liens internes vers la page que vous souhaitez indexer.
Si vous souhaitez en savoir plus sur la structure du site Web, consultez notre article sur Comment créer un site Web qui se classe et se convertit.
Contenu dupliqué
Adam Gent, un freelance SEO, a partagé un cas intéressant avec la communauté SEO. Sa page signalait Crawled - actuellement non indexée car Google pensait qu'il s'agissait d'une page en double.
Google veut présenter un contenu unique et précieux aux utilisateurs. C'est pourquoi lorsqu'il se rend compte lors du crawling que certaines pages sont identiques ou quasi identiques, il peut n'en indexer qu'une seule.
Habituellement, l'autre est étiqueté comme "Dupliquer" dans le rapport de couverture de l'index. Cependant, ce n'est pas toujours le cas, et parfois Google attribue le statut Crawled - actuellement non indexé à la place.
Il n'est pas tout à fait clair pourquoi Google pourrait choisir Crawled - actuellement non indexé sur un statut dédié pour le contenu dupliqué. L'une des explications possibles est que le statut changera plus tard après que Google ait décidé s'il en existe un plus approprié pour la page.
Une autre option pourrait être un rapport de bogue . Google pourrait simplement faire une erreur lors de l'attribution des statuts. Malheureusement, la situation est plus difficile car Crawled - actuellement non indexé ne vous donne pas autant d'informations qu'un statut dédié pour le contenu dupliqué.
Comment vérifier si une page en double s'affiche dans les résultats de recherche ?
- Accédez à la page qui n'est pas indexée et copiez un fragment de texte aléatoire.
- Collez le texte dans la recherche Google entre guillemets.
- Analysez les résultats. Si une URL différente avec votre texte copié s'affiche, cela peut signifier que votre page n'est pas indexée car Google a choisi une autre URL à indexer.
Solution
Avant tout, vous devez vous assurer de créer des pages originales. Si nécessaire, ajoutez un contenu unique.
Malheureusement, le contenu en double peut être inévitable (par exemple, vous avez une version mobile et une version de bureau). Vous n'avez pas beaucoup de contrôle sur ce qui apparaît dans les résultats de recherche, mais vous pouvez donner à Google quelques indices sur la version originale.
Si vous remarquez beaucoup de contenu dupliqué indexé, évaluez les éléments suivants :
- Balises canoniques - ces balises HTML indiquent aux moteurs de recherche quelles versions sont les versions originales.
- Liens internes – assurez-vous que les liens internes pointent vers votre contenu original. Google pourrait l'utiliser comme indicateur de la page la plus importante.
- Plans de site XML – assurez-vous que seule la version canonique se trouve dans votre plan de site.
N'oubliez pas qu'il ne s'agit que d'indices et que Google n'est pas obligé de les suivre. Dans le cas décrit par Adam Gent, Google a choisi la version du flux RSS à indexer, même si de nombreux signaux de canonisation pointaient vers une URL d'origine différente. Adam a résolu le problème en configurant un 404 pour s'assurer que seule la version originale est conservée. Il a également suggéré de configurer un en -tête HTTP X-robots sur toutes les URL de flux pour empêcher leur indexation.
Crawlé – actuellement non indexé vs. Découvert – actuellement non indexé
Le statut Crawled – actuellement non indexé est souvent confondu avec un autre problème d'indexation dans le rapport Index Coverage : Discovered – actuellement non indexé.
Les deux statuts indiquent que la page n'est pas indexée. Cependant, dans le cas de Crawled – actuellement non indexé, Google a déjà visité la page. Pendant ce temps, dans Découverte - actuellement non indexée, l'URL est connue de Google, mais, pour une raison quelconque, elle n'a pas encore été explorée.
| Exploré - actuellement non indexé | Découvert - actuellement non indexé | |
| Page découverte par Google | Oui | Oui |
| Page visitée par Google | Oui | Non |
| Page indexée | Non | Non |
Certaines des raisons de ces statuts peuvent être similaires, notamment des pages de mauvaise qualité et des problèmes de liens internes. Cependant, lorsque vous voyez un état Découvert - actuellement non indexé, vous devez également rechercher pourquoi Google n'a pas pu ou n'a pas voulu accéder à la page. Par exemple, cela peut indiquer des problèmes de qualité globale de l'ensemble du site Web, des problèmes de budget d'exploration ou une surcharge du serveur.
Emballer
Crawled - actuellement non indexé est principalement associé à la qualité de la page, mais en réalité, il peut indiquer de nombreux autres problèmes, comme l'architecture du site Web ou le contenu dupliqué.
Voici les principaux points à retenir de l'article qui peuvent vous aider à gérer le statut Crawled - actuellement non indexé :
- Ajoutez un contenu unique et précieux à vos pages. Une fois que vous l'avez fait, soumettez ces URL à la Google Search Console. De cette façon, Google peut remarquer les changements plus rapidement.
- Passez en revue l'architecture de votre site Web et assurez-vous qu'il existe des liens internes vers vos pages utiles.
- Décidez quelles pages doivent et ne doivent pas être indexées pour aider Google à hiérarchiser les URL les plus précieuses.
Si vous avez besoin d'aide pour traiter le statut Crawled - actuellement non indexé sur votre site Web, nos services techniques de référencement sont ce que vous recherchez.