
Co to jest PageRank?
Opublikowany: 2022-07-01PageRank to algorytm opracowany przez założycieli Google, Larry'ego Page'a i Sergeya Brina. Mierzy znaczenie strony w większym zestawie stron, obliczając liczbę i jakość linków prowadzących do badanej strony. PageRank jest jednym z wielu czynników, które Google wykorzystuje do pozycjonowania stron internetowych w wynikach wyszukiwania Google, co czyni go wskaźnikiem sukcesu w SEO.
Pierwotnym celem PageRank była pomoc Google w generowaniu wysoce trafnych wyników wyszukiwania w porównaniu z alternatywnymi wyszukiwarkami w tamtych czasach poprzez zastosowanie dodatkowego, innowacyjnego czynnika. Algorytm jest nadal używany do rankingu wyszukiwania, chociaż jego pierwotna formuła zmieniła się znacznie na przestrzeni lat i nie jest już publicznie dostępna.
Dlaczego PageRank jest kluczowy dla SEO?
Pierwotnym pomysłem Larry'ego Page'a i Sergeya Brina było stworzenie algorytmu, który postrzegałby linki jako głosy oddawane przez strony, wyrażające zaufanie i poparcie. Zgodnie z tą logiką, im więcej linków dana strona otrzymuje z innych stron internetowych, tym bardziej jest ona uważana za ważniejszą — strony z wyższym wynikiem PageRank są uważane za bardziej przydatne dla internautów i powinny pojawiać się wyżej na stronie wyników wyszukiwania Google.
Chociaż nie jest to jedyny czynnik rankingowy, z którego korzysta Google, jest to zdecydowanie ważny.
PageRank to algorytm rekurencyjny — wartość przypisana linkom z danej strony zależy od liczby i jakości linków, które sama strona otrzymała. Dlatego linki z renomowanych witryn przekazują większą wartość PageRank.
Jeśli jednak dana strona zawiera linki do wielu innych stron, strony te otrzymają tylko ułamek autorytetu danej strony ze względu na osłabienie PageRank . Linki na stronie dzielą między sobą wartość PageRank tej strony. Im więcej linków znajduje się na stronie, tym mniejszą wartość może przekazać każdy z nich.
Te cechy algorytmu mają dwie konsekwencje, jeśli chodzi o SEO.
- Opłaca się, aby Twoje treści były linkowane przez inne renomowane witryny.
- Liczba linków na Twoich stronach może być strategicznym wyborem.
W dzisiejszych czasach pracownicy Google rzadko rozmawiają o PageRank, ale trudno wyobrazić sobie Google bez niego. PageRank pomógł Google podbić sieć i wywarł ogromny wpływ na branżę SEO.
Historia PageRank
Przez ostatnie dwie dekady Google czerpał korzyści z używania PageRank, jednocześnie walcząc z różnymi metodami nadużywania go przez właścicieli witryn.
Poznanie historii PageRank jest nie tylko absorbujące, ale także stanowi pomocny kontekst do planowania spójnej kampanii SEO.
Larry Page i Sergey Brin wprowadzili PageRank w 1998 roku w swoim patencie zatytułowanym „Anatomia hipertekstowej wyszukiwarki internetowej na dużą skalę”. Patent opisał ich pomysł na innowacyjną wyszukiwarkę o nazwie Google i wyjaśnił, w jaki sposób przyniosłaby ona trafniejsze wyniki niż konkurencyjne systemy. Autorzy twierdzili, że wyjątkowa dokładność wyszukiwarki Google wynikałaby z wykorzystania PageRank — możliwości pozycjonowania stron na podstawie wymienianych między nimi linków.
Kolejne lata pokazały, że PageRank rzeczywiście był przełomem i to nie tylko dla Wyszukiwarki.
John Mueller, rzecznik wyszukiwarki Google, powiedział na Twitterze, że PageRank jest obecnie używany w biologii, neuronauce, chemii i fizyce.
Dylematy wyszukiwarek przed PageRank
Cofnijmy się w czasie do czasów, kiedy po raz pierwszy utworzono PageRank.
Sieć tamtych czasów była mniejsza niż dzisiaj, ale z każdym mijającym dniem stawała się coraz bardziej chaotyczna. Pierwsza strona internetowa pojawiła się w 1991 roku; trzy lata później działało już prawie 2800 stron internetowych. W 1998 roku, kiedy narodził się PageRank, Internet rozrósł się do ponad 2 410 000 stron.
Jeśli w 1998 roku zgłodniałeś i chciałeś znaleźć przepis na szybki sos do spaghetti wśród tych 2,4 miliona stron, możesz skorzystać z pomocy raczkujących wyszukiwarek, takich jak AltaVista.
W tamtych czasach wyszukiwarki próbujące znaleźć najszybszy i najsmaczniejszy przepis na sos do spaghetti kierowały się przede wszystkim słowami kluczowymi. Im częściej dana strona wspominała o sosie do spaghetti, tym bardziej uważali, że powinien on mieć wysoką pozycję. To spowodowało, że właściciele witryn upchali swoje strony słowami kluczowymi, aby uzyskać wyższą pozycję w rankingu i przyciągnąć większy ruch z wyszukiwania. Więc zamiast najbardziej satysfakcjonującego wyniku, prawdopodobnie uzyskasz najbardziej wypełniony słowami kluczowymi.
Alternatywnym rozwiązaniem było wyszukanie przepisu w stworzonym przez człowieka katalogu internetowym, takim jak Yahoo Directory. Te indeksy były wyselekcjonowane, co oznaczało, że ludzie ręcznie ustawiali swoje wyniki wyszukiwania. Głodny poszukiwacz mógł liczyć na dokładniejsze, zweryfikowane wyniki za pomocą wyselekcjonowanego przez człowieka indeksu. Ale wraz z rozwojem sieci stało się jasne, że ludzie nie nadążą za tempem. Było po prostu zbyt wiele witryn, aby ktokolwiek mógł je ręcznie śledzić.
Rozwiązanie
Stało się jasne, że tylko w pełni zautomatyzowane systemy wyszukiwania informacji mogą wystarczająco szybko przejść przez stale rozwijającą się sieć. Problem polegał na tym, że komputery nie były w stanie zrozumieć i ocenić treści internetowych tak dobrze, jak ludzie. Algorytmy potrzebowały nowych wskaźników poza słowami kluczowymi.
Ludzie uznali, że linki nadają się do tego typu wskaźników i zaczęli eksperymentować z hipertekstową naturą Internetu. Słusznie założyli, że strony odsyłające do danej strony dostarczają dodatkowych informacji o zawartości tej strony. Niektóre wskazówki potrzebne algorytmom zostały zawarte w tekście zakotwiczenia. Poza tym strony o podobnej tematyce zawierałyby między sobą bardziej obszerne linki.
Autorzy PageRank wykorzystali ten pomysł i poszli o krok dalej. Postanowili użyć linków do pomiaru ważności stron. Uważali, że autorytatywne witryny mogą przekazywać swój autorytet stronom, do których prowadzą linki, a wtedy wyszukiwarka będzie w stanie nie tylko zidentyfikować najbardziej odpowiednie wyniki, ale także uszeregować je pod względem użyteczności.
Oryginalna formuła PageRank
Jak więc można by mierzyć wagę danej strony internetowej? W tym miejscu do gry wkracza PageRank.
Poznaj Joe, przypadkowego surfera
Najprostszym sposobem na zrozumienie, jak działa PageRank, jest wyobrażenie sobie internauty losowo podążającego za linkami między stronami. Nazwijmy go Joe i załóżmy, że ma ogromny apetyt na spaghetti.
Głód sprowadził Joe na bloga o kuchni włoskiej, który zawiera odnośniki do przepisu na sos boloński i przepis na sos carbonara.
Strona carbonara odnosi się do zupełnie innej witryny z pizzą.

Strona z pizzą zawiera linki do bloga, od którego Joe zaczął, i do znanego już przepisu na karbonarę.

Zaczynając od strony bolońskiej, Joe może przeskoczyć do strony pizzy lub strony carbonara.
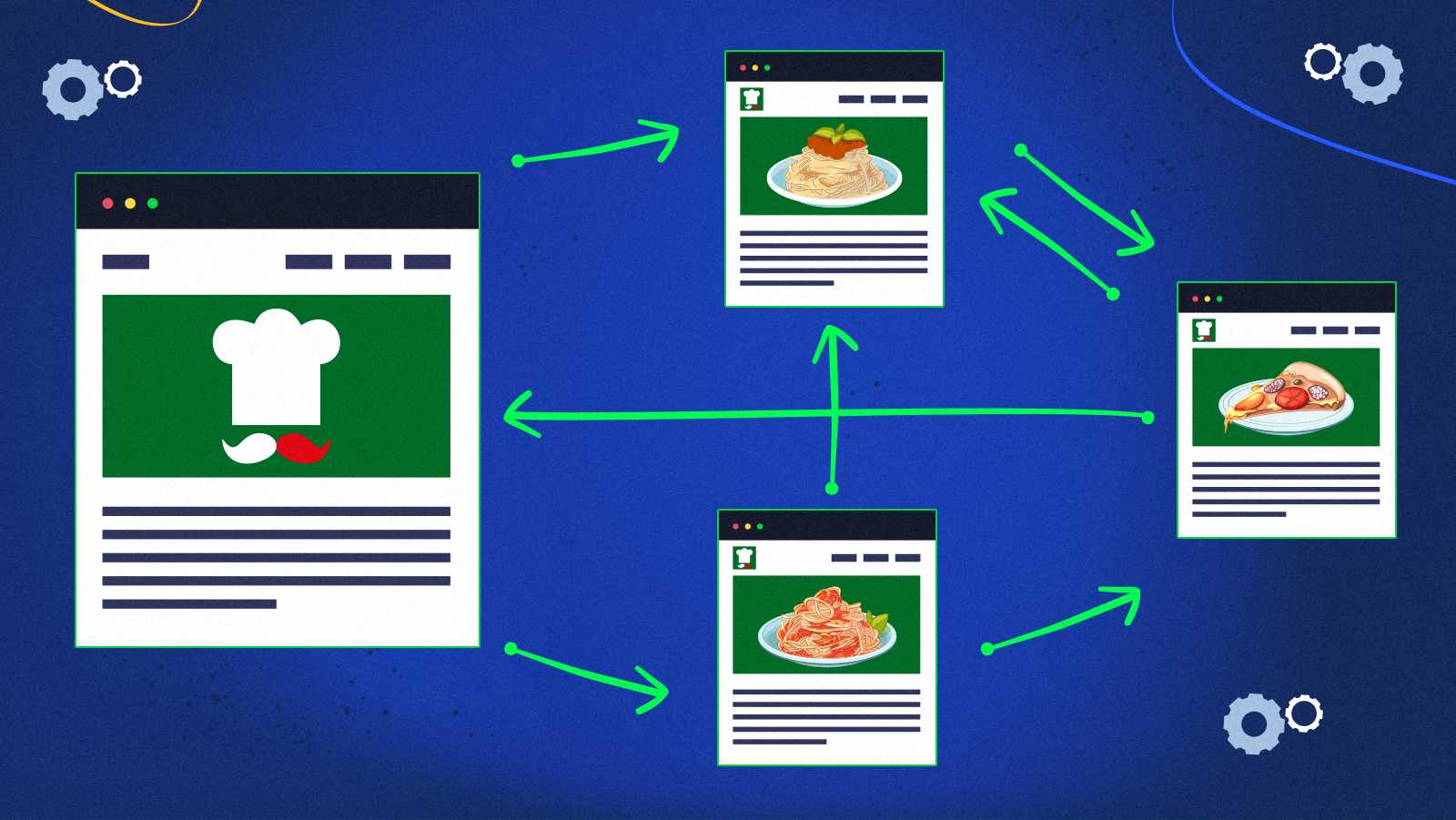
Joe jest bardzo niezdecydowaną osobą. Klika bez końca między tymi czterema stronami.
Co ciekawe, powoduje to zmianę prawdopodobieństwa odwiedzenia każdej z tych stron.
Kiedy Joe czyta bloga (załóżmy, że jest to blog jednostronicowy), istnieje 50% szansa, że otworzy przepis na bolończyka i 50% szansa, że otworzy przepis na carbonara. Jednak kiedy jest na miejscu spaghetti carbonara, nie ma innego wyjścia, jak przenieść się do witryny z pizzą. Następnie może wrócić do przepisu carbonara lub bloga i powtórzyć cykl. Prawdopodobieństwo obu tych opcji wynosi 50%.
Aby Joe mógł dostać się na stronę spaghetti bolognese za pomocą pierwszego kliknięcia, dwie rzeczy muszą być prawdziwe. Najpierw jest 25% szansy, że zacznie przeglądać bloga, a potem 50% szansa, że kliknie w odpowiedni link.
Gdy pomnożymy te prawdopodobieństwa, okaże się, że istnieje 12,5% szansa, że Joe po pierwszym kliknięciu przeczyta przepis na sos boloński. Dla porównania prawdopodobieństwo, że Joe trafi na stronę o sosie carbonara po pierwszym kliknięciu wynosi 37,5%.
Rekursywność PageRank
Możemy z grubsza przewidzieć, ile czasu Joe spędzi na każdej z czterech stron. W drugiej rundzie kliknięć szanse Joe na uruchomienie w różnych witrynach nie wynoszą już 25%, ale są różne. Wielokrotnie mnożąc liczby, zauważamy, że linki z często polecanych stron zwiększają prawdopodobieństwo przejścia do strony, do której prowadzą.
Nazywa się to rekursywnością PageRank i dlatego witryny z wysokim wynikiem PageRank przekazują więcej wyniku PageRank do innych witryn, więc linki z nich są cenione w SEO.
Rozcieńczenie PageRank
Model Random Surfer jest również świetną ilustracją osłabienia PageRank. W powyższym przykładzie strona z przepisem carbonara miała największy autorytet. Link łączył się tylko ze stroną z przepisami na pizzę, dzięki czemu strona z przepisami na pizzę uzyskała całą wartość PageRank, ponieważ przypadkowy internauta nie miał innego wyboru, jak tylko się tam przenieść.
Gdyby jednak strona carbonara zawierała dwa dodatkowe linki, strona pizzy otrzymałaby jedną trzecią początkowej wartości PageRank. Wtedy byłaby jedna do trzech szans, że przypadkowy internauta użyje linku do strony z pizzą .
Współczynnik tłumienia
Oczywiście przypadkowy internauta opisany w patencie Google nie może utknąć na czterech linkujących do siebie stronach, ponieważ jego zadaniem jest mierzenie znaczenia witryn w całym Internecie.
Wyobraźmy sobie więc, że niezdecydowany Joe waha się, czy woli zjeść chińskie danie. Jeśli zdecyduje się odłożyć jedzenie makaronu na jutro, całkowicie zrezygnuje z przeglądania sieci. Podążanie za tym scenariuszem pomaga nam zrozumieć czynnik tłumienia: szansę, że Joe będzie nadal podążał za strukturą linków zamiast porzucać podane cztery strony i przeglądać inny kącik sieciowy.
W pierwotnym patencie Larry Page i Sergey Brin zasugerowali użycie współczynnika tłumienia 0,85, co oznacza, że przy każdej odwiedzonej stronie istnieje prawdopodobieństwo 85%, że przypadkowy internauta będzie nadal klikał linki na stronie i nie porzuci całkowicie tego procesu.
Wzór matematyczny PageRank
Wszystko opisane powyżej możemy przedstawić jako jedną formułę matematyczną do obliczania PageRank. W najprostszej formie, gdyby sieć zawierała tylko cztery strony, wyglądałoby to tak:
PR(A) = [PR(B)]/L(B) + [PR(C)]/L(C) + [PR(D)]/L(D),
gdzie PR(B) oznacza wynik PageRank strony B , a L(B) oznacza całkowitą liczbę linków na stronie B .
Z równania wynika, że PageRank strony A jest równy sumie wyników PageRank stron B , C i D , z których każda jest podzielona przez liczbę linków pochodzących z tych stron.
Aby jednak uzyskać pełny obraz działania algorytmu, musimy również wziąć pod uwagę współczynnik tłumienia d .
PR(A) = [(1-d)/N] + d{ ([PR(B)]/L(B) + [PR(C)]/L(C) + [PR(D)]/L (D) }
Litera N oznacza liczbę dokumentów w danej kolekcji. W tym scenariuszu N równa się cztery.
Jeśli interesują Cię bardziej zaawansowane przekształcenia formuły PageRank, zapoznaj się z artykułem Wikipedii o PageRank.
Czym był pasek narzędzi PageRank i dlaczego został usunięty?
PageRank stał się obsesją wszystkich w 2000 roku, kiedy Google wprowadził pasek narzędzi do zainstalowania w przeglądarce. Jedną z funkcji paska narzędzi Google Toolbar było wyświetlanie PageRank. Jego twórcy opisali to następująco: „Zastanawiasz się, czy nowa strona internetowa jest warta twojego czasu? Użyj PageRank paska narzędzi Toolbar, aby dowiedzieć się, jak Google ocenia ważność przeglądanej strony”.
Najwyższy PageRank, jaki strona mogła uzyskać na pasku narzędzi, wynosił 10. Zero oznaczało, że strona nie zasługuje na zaufanie i uwagę.
Trzeba przyznać, że liczba ta była łatwa do zrozumienia i śledzenia, a wielu SEO koncentrowało się na jej poprawie jako kluczowej metryce sukcesu dla wszystkich witryn.
Okazało się to fatalne dla jakości treści w sieci. Zamiast tworzyć lepsze, bardziej przydatne strony internetowe, ludzie skupili się na budowaniu jak największej liczby linków, aby poprawić swoje wyniki PageRank. Nie trzeba dodawać, że większość tych linków nie została stworzona, aby pomóc użytkownikom — ich celem było oszukanie Google.
Sami Googlersi próbowali przekonać administratorów sieci do skupienia się na innych wskaźnikach , ale z niewielkim sukcesem. Chociaż PageRank był stale przeliczany, Google rzadko aktualizował wartości wyświetlane przez pasek narzędzi. Googlersi przyznali, że chcą uniknąć jeszcze większej obsesji na punkcie wyników PageRank.
Kiedy próby zmiany manier adminów nie powiodły się, Google w końcu zauważył, że wyświetlanie PageRank wyrządza więcej szkody i pożytku. Wyświetlanie PageRank paska narzędzi zostało ostatnio zaktualizowane w grudniu 2013 r., a trzy lata później funkcja całkowicie zniknęła.
Ważne aktualizacje PageRank
PageRank nie był idealny w swojej pierwotnej formie. Z czasem okazało się, że wymaga poprawy i zabezpieczenia przed tymi, którzy próbują nim manipulować.
Google coraz bardziej dyskretnie podchodziło do roli PageRank w rankingu wyników wyszukiwania. W końcu były pracownik Google ujawnił, że firma nie korzysta już z oryginalnego patentu PageRank od 2006 roku . Te kroki mogły być motywowane tym, jak bardzo cała branża SEO była skoncentrowana na manipulowaniu PageRank. Jednak były pracownik wskazał również, że nowy algorytm jest znacznie szybszy w obliczeniach, a jedynym powodem tej zmiany mogła być potrzeba większej wydajności.
Możemy nigdy nie wiedzieć, jak ewoluowała oryginalna formuła PageRank i jak jest teraz wykorzystywana w rankingu wyszukiwania. Jednak z dwóch patentów zgłoszonych w 2004 i 2006 roku możemy wywnioskować dwie krytyczne zmiany.
Poznaj Joelle, rozsądnego surfera
W patencie zgłoszonym w czerwcu 2004 r. „Ranking dokumentów na podstawie zachowania użytkownika i/lub danych o funkcjach” Google opisał model Reasonable Surfer.
Dlaczego przypadkowy surfer musiał stać się rozsądny? Jednym z elementów początkowego modelu było założenie, że internauta ma takie samo prawdopodobieństwo kliknięcia w każdy link na danej stronie. Oznaczało to, że każdy link miał taką samą wartość PageRank.
Oczywiście to założenie nie do końca odzwierciedlało rzeczywistość.
Wyobraź sobie kobietę o imieniu Joelle, która chce zaimponować znajomym, robiąc domową pizzę. Przegląda sieć i przegląda wiele przepisów. Gdy strona zawiera linki do innych sugerowanych przepisów, ona również je losowo przegląda.
Jednak w tej chwili raczej nie zainteresuje się polityką prywatności portalu kulinarnego. Nie musi też kupować doniczek do uprawy bazylii. Szansa, że kliknie którykolwiek z tych linków, jest niewielka.
Patent stwierdza:
Systemy i metody zgodne z zasadami wynalazku mogą zapewnić rozsądny model internauty, który wskazuje, że gdy internauta uzyskuje dostęp do dokumentu z zestawem łączy, surfer będzie podążał za niektórymi łączami z większym prawdopodobieństwem niż za innymi. Ten rozsądny model surfera odzwierciedla fakt, że nie wszystkie linki skojarzone z dokumentem mają takie samo prawdopodobieństwo wykorzystania. Przykładami mało prawdopodobnych linków mogą być linki „Warunki korzystania z usługi”, banery reklamowe i linki niezwiązane z dokumentem.źródło: Ranking dokumentów na podstawie zachowania użytkownika i/lub danych funkcji
Joelle jest niezdecydowana i chaotyczna, ale jest rozsądna. Jak algorytm może z powodzeniem naśladować jej zachowanie? Musi uwzględniać na przykład pozycję linku na stronie . Rozmiar i kolor tekstu kotwicy może również wskazywać, czy Joelle byłby zainteresowany kliknięciem. Jeśli tekst zakotwiczenia brzmi zbyt komercyjnie, poczuje się zniechęcona do odwiedzania witryny. Jeśli ktoś wymienił link między innymi, Joelle chętniej kliknie linki o wyższych pozycjach na tej liście.
Celem było zróżnicowanie wagi przekazywanej przez linki według ich cech. Te ważne atrybuty są wymienione w patencie:
Przykłady funkcji powiązanych z linkiem mogą obejmować rozmiar czcionki tekstu kotwicy (…); pozycja linku (…), strona dokumentu; jeśli link znajduje się na liście, pozycja linku w Lista; kolor czcionki lub atrybuty linku (np. kursywa, szary, kolor tła itp.); (…); komercyjność tekstu kotwicy powiązanego z linkiem; (…). Ta lista nie jest wyczerpująca i może zawierać więcej, mniej lub różne funkcje powiązane z linkiem.źródło: Ranking dokumentów na podstawie zachowania użytkownika i/lub danych funkcji
Witryny nasienne – czym są i jak wpływają na PageRank?
Inną ważną ideą, która prawdopodobnie wpłynęła na formułę PageRank, było uświadomienie sobie, że można wybrać zestaw stron, które z definicji są godne zaufania.

Na przykład jest mało prawdopodobne, aby strony rządowe zawierały linki do blogów wyjaśniających, jak oszukać system podatkowy. Możliwe jest również zidentyfikowanie kilku renomowanych gazet, których dziennikarze przeprowadzają badania jakościowe i nie odnoszą się do niezweryfikowanych informacji.
Według patentu z 2006 r. zatytułowanego „Tworzenie rankingu stron wykorzystujących odległości na wykresie linków internetowych”, tego typu strony internetowe są „witrynami źródłowymi”. Dwa przykłady wymienione w dokumencie to The Google Directory i The New York Times. Strony te są wstępnie wybrane i możemy założyć, że strony, do których prowadzą bezpośrednio, powinny mieć wyższy PageRank.
Ale co ze stronami, do których prowadzą linki z witryn, do których prowadzą bezpośrednie linki z witryn z nasionami? Wybrane witryny źródłowe ich nie rozpoznają, ale nadal możemy być pewni, że witryna, która zdobyła zaufanie New York Times, nie będzie zawierała w swoich artykułach odsyłaczy-śmieci. Rozsądnie jest, aby algorytm rankingowy obliczał odległość między daną stroną a jedną z wybranych witryn źródłowych.
Wyobraź sobie stronę internetową wymyślonego Stowarzyszenia Miłośników Kuchni Włoskiej. Ze względu na swoją reputację, zatrudnianie profesjonalnych autorów i wysokiej jakości treści, Google może uznać ją za witrynę zarodkową.
Dla uproszczenia załóżmy, że w całym Internecie są tylko dwie strony z przepisem na spaghetti bolognese. Kiedy jesteś głodny i szukasz przepisu na to danie, Google może mieć dylemat, który z nich wyświetlić jako pierwszy. Sprawdzę więc, jak blisko są do słynnej strony Stowarzyszenia Miłośników Kuchni Włoskiej. Linki do strony drugiej z dala od witryny z nasionami powinny mieć wyższą pozycję niż linki do drugiej strony z zaufanego źródła.
Przestarzałe praktyki SEO zwiększające PageRank
Jak wspomnieliśmy wcześniej, właściciele stron internetowych i SEO rozwinęli ogromną ambicję, aby uzyskać najwyższy wynik PageRank. Algorytm wpłynął na ich pozycję w wynikach wyszukiwania i świadczył o prestiżu serwisu. Niektórzy SEO zwykli odnosić się do wartości PageRank, którą strony przekazały sobie nawzajem, jako „sok linków”. I wszyscy chcieli go wycisnąć do ostatniej kropli.

Ku zadowoleniu wielu, oryginalny algorytm był łatwy do manipulowania . Osoby, które szły na skróty i nie stroniły od nieuczciwych praktyk, z powodzeniem generowały duży ruch na swoich witrynach o niskiej jakości. Posiadanie większej liczby linków wystarczyło, aby zwiększyć widoczność dowolnej witryny. Skąd pochodzą te linki, w końcu nie miało znaczenia.
Google musiał wyciągnąć wnioski ze swoich błędów, aby zapobiec przekształceniu się Internetu w ogromną farmę linków. Przełom nastąpił, gdy firma opracowała automatyczne sposoby wyłapywania i karania stron internetowych, które łamały zasady .
Czym są schematy linków?
Wyobraź sobie prowadzenie bloga o chińskiej kuchni. Gdy tworzysz posty i dzielisz się swoją wiedzą, pomocne może być polecanie czytelnikom innych źródeł. Czasem linkujesz do innego bloga na ten temat lub promujesz angażujące warsztaty kulinarne, na które pójdziesz do siebie.
Tego rodzaju linki nazywane są „naturalnymi”. Umieszczenie ich w poście sprawi, że informacje będą kompletne i bardziej wartościowe. Decydujesz się zrobić je z chęci stworzenia dobrego bloga, a nie z podniesienia czyjegoś PageRank.
Jednak nie wszyscy w sieci mają tak dobre intencje jak Ty. Ludzie regularnie publikują linki poza kontekstem bez żadnych korzyści dla użytkowników. Ich celem jest zwiększenie liczby linków zwrotnych kierujących do witryny, którą chcą uzyskać wyższą pozycję w wynikach wyszukiwania. Te bezużyteczne linki zwrotne są zwykle kupowane, automatycznie generowane lub wymuszane na kontrahentach.
Takie działania polegające na umieszczaniu nienaturalnych linków i próbach manipulowania PageRank nazywane są schematami linków . Omówmy je bardziej szczegółowo.
Kupowanie i sprzedawanie linków
W przeszłości dominowała sprzedaż linków przez domeny o wysokim rankingu. Tego typu praktyka nadużywała zasady, że linki ze stron o wysokim wyniku PageRank znacznie zwiększają wynik PageRank witryny, do której prowadzą linki. Google złapało sprzedaż linków przez Washington Post w 2007 r. i BBC w 2013 r. W ramach kary wyniki PageRank ich witryn zostały ręcznie obniżone, a w kolejnych miesiącach stracili wielu odwiedzających.
Google kiedyś musiał nawet ukarać własny produkt. W 2012 roku oficjalna strona Google Chrome wykorzystywała do promocji zakupione posty na blogu. Kara spowodowała spadek PageRank domeny, a pierwsza strona wyników wyszukiwania nie wyświetlała już stron Chrome dla zapytania „przeglądarka”.
Google nie ujawnia, czy ręczna kara za strony sprzedające linki jest zawsze obniżeniem ich PageRank, ale doniesienia prasowe na temat ręcznych działań Google z początku 2010 roku sugerują, że na tym się to składało.
Kiedyś, gdy na pasku narzędzi widzieliśmy wynik PageRank, nie był to tylko wynik obliczeń algorytmicznych, ale także wyrażenie opinii Google na temat danego portalu. A Google nie mógł tak bardzo ufać witrynie przyłapanej na sprzedawaniu nienaturalnych linków, jak wcześniej.
Były szef zespołu Google ds. spamu w sieci, Matt Cutts , wspomina w filmie na YouTube kwestię ręcznego obniżania rankingu PageRank.
Sprzedawanie i kupowanie linków nie zawsze wiązało się z pieniędzmi. Zdarzało się, że dwie niepowiązane ze sobą strony zgodziły się na łączenie się ze sobą podczas wymiany. Co więcej, niektórzy przedsiębiorcy postanowili wysyłać innym „darmowe” produkty w zamian za dołączenie linku do strony ich sklepu. Niektórzy przedsiębiorcy podali link do swojej strony jako warunek skorzystania z usług ich firmy. Zazwyczaj nie pozwalali wykonawcom na rezygnację z tej części umowy.
Spam w komentarzach
Kolejnym smutnym wydarzeniem było umieszczanie komentarzy spamowych w sieci. Załóżmy, że ktoś zauważył, że Twój blog o kuchni chińskiej ma wysoki PageRank, a następnie umieścił komentarz pod jednym z Twoich postów z linkiem do przepisu na karbonarę, mimo że nie jest to interesujące dla Twoich czytelników. Takie działanie z pewnością nie pobudza do owocnej dyskusji na Twoim blogu, a jedynie służy nienaturalnemu podniesieniu rankingu innej strony.
Farmy linków
Internauci sprzed kilku lat mogli również zaobserwować wyrastające jak grzyby po deszczu farmy linków. Farmy linków to grupy stron internetowych, które łączą się ze sobą, aby zwiększyć swoje rankingi. Wcześniej rozmawialiśmy o tym, jak PageRank symuluje zachowanie przypadkowego internauty i jak działa na czterech stronach kulinarnych, które łączą się ze sobą. Co by było, gdyby ten sam autor stworzył wszystkie te strony, a ich jedynym zamiarem było zwiększenie PageRank jednej z nich?
Wyobraź sobie, że wspomniany autor nie uczynił z tych dodatkowych stron źródła niezależnych informacji, a jedynie po to, by dać przypadkowemu internautowi większą szansę na odwiedzenie strony z przepisem carbonara. Ich postawa nie sprzyja budowaniu wiarygodnych i satysfakcjonujących treści w sieci i nie odpowiada celom Google.
Większość farm linków nie została stworzona ludzkimi rękami, ale raczej przez zautomatyzowane programy, które każdego dnia mogą zapełniać serwery setkami nowych stron-śmieci. Farmy linków należy postrzegać jako bardzo negatywne zjawisko, ponieważ wypełniają one sieć spamem.
Czym jest aktualizacja Penguin i jak zwalcza nieuczciwe SEO?
W kwietniu 2012 roku ogłoszono nową aktualizację Google. Pomimo przyjaznego kryptonimu – „Penguin” – miał na celu zaciekłą walkę z administratorami sieci, którzy manipulowali PageRank. Google zaprogramował algorytm Penguin tak, aby szukał nienaturalnych linków i nakładał kary na strony , które z nich korzystały.
Po wydaniu Penguin wielu administratorów stron internetowych było zaskoczonych nagłym załamaniem się rankingu ich witryn. Musieli przejść przez żmudne czyszczenie linków zwrotnych, aby odzyskać utracony wynik PageRank. Często musieli wysyłać e-maile z prośbami o usunięcie nienaturalnych linków do ich witryn, a Google doceniało skrupulatne dokumentowanie tych działań.
Gdy nie można było skontaktować się ze stroną internetową za pomocą niechcianego linku, sposobem postępowania było zrzeczenie się go poprzez przesłanie odpowiedniego żądania do Google.
Algorytm Penguin był aktualizowany siedmiokrotnie i stał się częścią podstawowej infrastruktury Google. Od momentu jego wprowadzenia farmy linków lub kupowanie linków może tylko zaszkodzić widoczności witryny — przynajmniej na dłuższą metę. Chociaż spam linkowy trwa do dziś, jego skuteczność znacznie spadła dzięki temu środkowi. Każdy z nas może pomóc Penguinowi w pilnowaniu jakości wyników wyszukiwania. Jeśli zauważysz nienaturalne łączenie, możesz użyć tego formularza Google, aby zgłosić schematy linków.
PageRank we współczesnym SEO
PageRank przebył długą drogę, odkąd został wprowadzony. Algorytm musiał przechytrzyć schematy linków i nauczyć się rozróżniać różne typy linków. Jego dokładna rola w rankingu wyników wyszukiwania pozostaje tajemnicą.
Więc co powinieneś wiedzieć o PageRank, aby budować lepsze strategie SEO?
Czy Google nadal korzysta z PageRank?
PageRank powstał jako algorytm mierzący, ile czasu przypadkowy internauta spędziłby w Twojej witrynie. Z biegiem czasu prawdopodobnie nauczył się brać pod uwagę lokalizację i tekst kotwicy linków oraz różnicować prawdopodobieństwo, że internauta za nimi podąża. Algorytm musiał też stać się odporny na manipulacje i zacząć rozpoznawać strony z nasionami, które z definicji były godne zaufania.
Wszystkie te znaczące zmiany w rankingu PageRank oraz fakt, że jego pierwotny patent został porzucony najpóźniej w 2006 roku, może prowadzić do wniosku, że Google może nie używać już tego algorytmu. Ale Google nie zapomniał o rozwiązaniu, które sprawiło, że odniósł taki sukces.
Ten tweet Johna Muellera o PageRank może być dowodem na to, że Google nadal używa swojego słynnego algorytmu. Analityk Google Webmaster Trends , Gary Illyes, również potwierdził na Twitterze, że PageRank wciąż ma duże znaczenie w rankingu.
Zasady zdrowego budowania linków
Obecnie nie można już używać paska PageRank i sprawdzać wyniku PageRank swojej witryny. Jednak jego ukryta wartość jest nadal fundamentalna dla widoczności wyszukiwania i może zostać zwiększona.
Z pewnością nie powinieneś płacić za linki w celu poprawy PageRank. Ściśle narusza wytyczne Google i na dłuższą metę z pewnością zaszkodzi Twoim rankingom.
Zamiast tego powinieneś skupić się na dwóch rzeczach:
- Tworzenie wysokiej jakości treści, które w naturalny sposób uzyskują jakościowe linki zwrotne, aby poprawić zewnętrzny przepływ PageRank do Twojej domeny.
- Upewnij się, że Twoje treści są wewnętrznie połączone i nadają się do prawidłowego rozpowszechniania wewnętrznego PageRank w Twojej witrynie.
Jakościowe linki zwrotne
Wyobraź sobie, że założyłeś bloga o kuchni chińskiej. Jak możesz poprawić ranking tej strony, skoro linki sponsorowane nie mogą przekazać Ci żadnego PageRank bez złamania wytycznych Google? Właśnie tam pojawia się cyfrowy PR. Podczas gdy tradycyjny PR koncentruje się na zwiększeniu rozpoznawalności marki za pomocą tradycyjnych mediów, takich jak prasa, PR cyfrowy koncentruje się na metodach internetowych.
Możesz skontaktować się z blogerami lub dziennikarzami i zaproponować im napisanie o projekcie, który prowadzisz na swoim blogu, w ramach którego rozsyłasz ankiety do dietetyków i publikujesz swoje odkrycia na temat korzyści zdrowotnych płynących z jedzenia chińskich potraw. Twórcy treści raczej nie będą zainteresowani samym istnieniem Twojej witryny, ponieważ jest to jeden z tysięcy blogów o chińskiej kuchni, ale możesz ich zaintrygować swoimi badaniami.
Jeśli jesteś wytrwały, możesz zostać wyróżniony w niektórych wiadomościach i artykułach, a dzięki nim zyskasz naturalne, wartościowe linki zwrotne.
Łączenie wewnętrzne
Nie możemy ignorować wewnętrznych linków w dyskusji PageRank. Linki wewnętrzne służą dwóm zasadniczym celom:
- Wpływają na poszczególne rankingi.
- Pomagają przeglądarkom poruszać się po witrynie.
Sposób, w jaki poszczególne strony w Twojej witrynie łączą się ze sobą, ma kluczowe znaczenie, ponieważ bez prawidłowych połączeń mogą nigdy nie zostać odkryte przez Google. Na przykład tworzenie tak zwanych stron osieroconych bez wewnętrznych linków prowadzących do nich jest ogromnym błędem. Nasz artykuł na temat tych problemów pomoże Ci dowiedzieć się, jak rozwiązać problemy z wewnętrznymi linkami.
PageRank a subdomeny i podfoldery
Co ciekawe, jednym z głównych pytań, które możesz zadać sobie podczas optymalizacji swojego PageRank, jest dylemat między tworzeniem subdomen lub podfolderów dla swojej witryny. Wyobraź sobie na przykład, że Twój blog o kuchni chińskiej ma wersję dla początkujących szefów kuchni oraz wersję ekspercką.
Powszechnie akceptowana teoria mówi, że Google może postrzegać subdomenę wersji eksperckiej jako oddzielną witrynę od Twojego bloga (a wszelkie linki między nimi jako linki zewnętrzne), interpretując linki między blogiem a jego podfolderem wersji eksperckiej jako linki wewnętrzne.
Wielu wybitnych ekspertów SEO, takich jak Barry Adams, twierdzi, że wyższy współczynnik tłumienia obciąży linki do subdomeny. Twój blog będzie więc przekazywał im mniej PageRank, a więcej PageRank do swoich podfolderów. Warto jednak zauważyć, że ludzie opierają to przypuszczenie na nieco przestarzałym zrozumieniu algorytmu, który nie zawsze może zachowywać się w tak przewidywalny sposób.
Jak uniknąć łamania wskazówek Google dla webmasterów?
PageRank ma na celu pomóc użytkownikom wyszukiwarek w znajdowaniu wysokiej jakości treści z zaufanych witryn. Linki zwrotne mogą mierzyć to zaufanie tylko wtedy, gdy są naturalne; czyli odsyłają do stron przydatnych w kontekście wyszukiwania użytkowników.
Sprzedaż linków jako próba manipulacji PageRank naraża stronę na karę nałożoną przez Google, co obniży jej pozycję w rankingu i widoczność. Po aktualizacji Penguin z 2012 r. algorytmy Google automatycznie wykrywają i karzą takie praktyki.
Teraz możesz się zastanawiać, jak tak wiele witryn wyświetla reklamy w swoich treściach bez szkody dla ich widoczności. Sekret polega na tym, że Google nie uzna Twoich linków komercyjnych za nienaturalne lub fałszywe, jeśli zostaną odpowiednio oznaczone.
Google docenia to, gdy otwarcie wyjaśniasz związek między Twoją witryną a linkiem. Aby uniknąć przypadkowego naruszenia wytycznych, możesz użyć atrybutów linków, które są ukrytymi fragmentami tekstu opisującymi każdy link w kodzie HTML.
Tag Nofollow
Tag nofollow to najstarszy sposób na poinformowanie Google, aby nie przekazywał żadnego PageRank do powiązanej strony. SEO porównują wartość PageRank do soku linków, który można „przelać” z jednej witryny na drugą. Mogliby powiedzieć, że gdyby Twoja witryna była szklanką soku z linków, która przelewa się przez otwory linków, tag nofollow byłby kawałkiem taśmy utrzymującej płyn wewnątrz szklanki.
Ta metafora jest oczywiście niedoskonała, ponieważ linkowanie do innej strony nie spowoduje utraty żadnego PageRank. Ale nadal możesz użyć tagu nofollow, aby zapobiec przekazywaniu uprawnień stronom, których nie chcesz promować.
Tag nofollow powinien być używany wewnątrz elementu HTML <a> jako taki:
<a href=”http://www.example.com”rel=”nofollow”>Some Anchor Text</a>
Sponsored and UGC tags
In September 2019, Google announced two new rel attributes designed to stop the PageRank flow. You can put them into HTML the same way as nofollow tags. Here's what they look like and what they do in comparison to the nofollow attribute:
| Nofollow tag | Sponsored tag | UGC tag |
| rel=” nofollow” | rel=” sponsored” | rel=” ugc” |
| Marks links to sites you don't want to pass any PageRank to for whatever reason. | Marks links resulting from a paid advertisement or endorsement. | Marks links posted by your website's users that might be spam, and you don't want to take responsibility for them. |
Google indicated that it isn't necessary to change the existing nofollow tags to more specific UGC or sponsored tags but recommended using them in the future. It's also possible to use more than one rel attribute to mark a single link.
At the same time, as stated in the announcement, from now on, the described tags will no longer serve as an absolute PageRank blocker but rather as hints for Googlebot. However, their use is still required if you don't want your site to be penalized for unnatural linking.
PageRank and redirects
Sometimes, you may need to move your website or page to a different address. Surely you'd like its PageRank to be retained. Fortunately, using a 301 redirect will help you achieve precisely this effect.
People have many doubts about how Google treats 302 redirects regarding PageRank. Due to the fear of losing PageRank, web admins often give up using those redirects. In one of the SEO Office Hours meetings, John Mueller confirmed that concerns around 302 redirects are unfounded. The 302 redirect allows the original address to retain the whole PageRank value.
PageRank and links shared on social media
A participant of a different SEO Office Hours meeting asked another interesting question whether the number of followers or likes increases the PageRank passed by the social media profile. We found out then that Google doesn't consider social media activity with regard to PageRank. Even if the search engine treats a social media profile as a regular webpage, the number of likes it has will not affect the PageRank passed.
Measuring PageRank
Since Google Toolbar isn't available anymore and Google no longer uses the original PageRank formula, there aren't any methods you can use to measure PageRank for your web pages or even to see its approximation.
However, it's still helpful to analyze your website's link profile, and for that, you need an alternative metric. There are several metrics that are popular in the SEO industry that attempt to simulate PageRank. Although Google doesn't use any of those metrics for ranking web pages, using them can be useful when auditing your website.
Page Authority and Domain Authority
Page Authority and Domain Authority are metrics developed by Moz to illustrate a page's or a domain's ranking potential. PA and DA range from 0 to 100 on a logarithmic scale, making it easier to improve them from 20 to 30 points than from 60 to 70 points. To calculate Page and Domain Authority, Moz uses data from the Mozscape web index and machine learning algorithms.
Trust Flow and Citation Flow
Trust Flow and Citation Flow by Majestic assess a website's authority based on its backlink profile. Citation Flow shows how many links point to your website, while Trust Flow focuses on the quality of those links.
Trust Flow grows when popular and reputable websites link to your page and will always score lower than Citation Flow, which considers all links no matter their status.
Domain Rating
Domain Rating is a metric developed by Ahrefs. It's calculated on a logarithmic scale of 0 to 100. Domain Rating is based on backlinks Ahrefs found pointing to your site without nofollow tags.
Ahrefs designed it to measure the authority of entire websites, not individual pages.
Key takeaways
- PageRank is an algorithm that helps Google evaluate the popularity and credibility of websites. It allows Google to surface more relevant content in search results. By assessing the number of links on pages and their quality, PageRank estimates how much time a random surfer would spend on them.
- By getting your website linked to other reputable domains, you increase your PageRank score and your chances of ranking high.
- For every page within your domain to rank high, you should also take care of proper internal linking to improve your internal PageRank flow.
- Google penalizes attempts to manipulate PageRank with unnatural links. Remember to correctly mark your links with nofollow, sponsored, and UGC tags to avoid traffic loss.