
PageRankとは何ですか?
公開: 2022-07-01PageRankは、Googleの創設者であるラリーペイジとセルゲイブリンによって開発されたアルゴリズムです。 調査対象のページにつながるリンクの数と品質を計算することにより、より多くのページセット内でのWebページの重要性を測定します。 PageRankは、GoogleがGoogleの検索結果でウェブページをランク付けするために使用する多くの要素の1つであり、SEOの成功指標になります。
PageRankの当初の目的は、追加の革新的な要素を採用することにより、Googleが当時の代替検索エンジンと比較して関連性の高い検索結果を生成できるようにすることでした。 このアルゴリズムは現在でも検索ランキングに使用されていますが、元の式は何年にもわたって大幅に変更されており、一般には公開されていません。
PageRankがSEOにとって重要なのはなぜですか?
ラリーペイジとセルゲイブリンの当初のアイデアは、リンクをページが互いに投票する投票と見なし、信頼と支持を表すアルゴリズムを作成することでした。 このロジックによれば、特定のWebページが他のWebページから取得するリンクが多いほど、それが重要であると見なされます。PageRankスコアが高いページは、Webユーザーにとってより有用であると見なされ、Googleの検索結果ページでより高く表示されるはずです。
Googleが使用する唯一のランキング要素からはほど遠いですが、それは間違いなく重要な要素です。
PageRankは再帰的なアルゴリズムです。特定のページからのリンクに割り当てられる値は、特定のページ自体が受信したリンクの数と品質によって異なります。 したがって、評判の良いサイトからのリンクは、より多くのPageRank値を渡します。
ただし、特定のページが他の多くのページにリンクしている場合、 PageRankの希薄化により、それらのページは特定のページの権限の一部しか受け取りません。 ページ上のリンクは、それらの間でそのページのPageRankの値を共有します。 ページ上にあるリンクが多いほど、それぞれが渡すことができる値は少なくなります。
アルゴリズムのこれらの機能は、SEOに関して2つの結果をもたらします。
- あなたのコンテンツを他の評判の良いウェブサイトにリンクさせることはお金がかかります。
- ページ上のリンクの数は戦略的な選択かもしれません。
今日、Google社員がPageRankについて議論することはめったにありませんが、それなしでGoogleを想像するのは難しいです。 PageRankは、Googleがウェブを征服するのを助け、SEO業界に多大な影響を与えました。
PageRankの歴史
過去20年間、GoogleはPageRankを使用することのメリットを享受しながら、Webサイトの所有者が同時にPageRankを悪用するさまざまな方法と戦わなければなりませんでした。
PageRankの歴史を学ぶことは、吸収するだけでなく、首尾一貫したSEOキャンペーンを計画するための有用なコンテキストを提供します。
LarryPageとSergeyBrinは、1998年に「大規模なハイパーテキストWeb検索エンジンの構造」というタイトルの特許でPageRankを紹介しました。 この特許は、グーグルと呼ばれる革新的な検索エンジンのアイデアを説明し、競合するシステムよりも関連性の高い結果を生み出す方法を説明しました。 著者は、Google検索の並外れた精度は、PageRankを使用すること、つまり、ページ間で交換されるリンクに基づいてページをランク付けできることに起因すると主張しました。
次の年は、PageRankが確かに画期的であり、 サーチエンジン。
Googleの検索提唱者であるジョン・ミューラー氏はツイッターで、 PageRankは現在、生物学、神経科学、化学、物理学で使用されていると述べた。
PageRankの前の検索エンジンのジレンマ
PageRankが最初に作成されたときの時間をさかのぼってみましょう。
当時の網は今日よりも小さかったが、日を追うごとに混沌としたものになった。 最初のウェブサイトは1991年に登場しました。 3年後、約2,800のWebサイトが稼働しました。 PageRankが誕生した1998年、インターネットは241万ページを超えるまでに成長しました。
1998年に空腹になり、240万ページの中から簡単なスパゲッティソースのレシピを見つけたい場合は、AltaVistaなどの新しい検索エンジンを利用できます。
当時、スパゲッティソースの最も速くておいしいレシピを見つけようとする検索エンジンは、主にキーワードによって導かれていました。 与えられたページがスパゲッティソースに言及すればするほど、彼らはそれが上位にランクされるべきだと考えました。 これにより、ウェブサイトの所有者は、ランクを上げてより多くの検索トラフィックを引き付けるために、ページにキーワードを詰め込むようになりました。 したがって、最も満足のいく結果の代わりに、最もキーワードが詰め込まれた結果が得られる可能性があります。
別の解決策は、YahooDirectoryなどの人工のWebディレクトリでレシピを検索することでした。 これらのインデックスは厳選されたもので、検索結果を手動でランク付けしました。 空腹の検索者は、人間が作成したインデックスを使用して、より正確で検証済みの結果を期待できます。 しかし、ウェブが成長するにつれて、人間がペースに追いついていないことが明らかになりました。 誰もが手動で追跡するにはウェブサイトが多すぎただけです。
ソリューション
完全に自動化された情報検索システムだけが、拡大し続けるWebを十分に速く通過できることが明らかになりました。 問題は、コンピューターが人間だけでなくWebコンテンツも理解および評価できないことでした。 アルゴリズムには、キーワード以外の新しいメトリックが必要でした。
人々は、リンクがそのような測定基準に適していると判断し、インターネットのハイパーテキストの性質を実験し始めました。 彼らは、特定のページにリンクしているページがそのページのコンテンツに関する追加情報を提供すると正しく想定していました。 アルゴリズムに必要ないくつかのヒントは、アンカーテキストに含まれていました。 その上、同様のトピックに関するページは、より広範囲に相互にリンクします。
PageRankの作者はこのアイデアを利用して、さらに一歩進んだ。 彼らは、ページの重要性を測定するためにリンクを使用することにしました。 彼らは、権威あるサイトがリンク先のページに権限を渡すことができ、検索エンジンが最も適切な結果を特定するだけでなく、使いやすさの観点からそれらをランク付けできると考えました。
PageRankの元の式
では、特定のWebページの重要性をどのように測定するのでしょうか。 そこでPageRankが登場します。
ランダムサーファーのジョーに会いましょう
PageRankがどのように機能するかを理解する最も簡単な方法は、ページ間のリンクをランダムにたどるサーファーを想像することです。 彼をジョーと呼び、彼がスパゲッティに大きな食欲を持っていると仮定しましょう。
飢えはジョーをイタリア料理についてのブログに連れて行きました。それはボロネーゼソースのレシピとカルボナーラソースのレシピにリンクしています。
カルボナーラのページは、まったく別のピザサイトを参照しています。

ピザのページは、ジョーが始めたブログと、すでにおなじみのカルボナーラレシピにリンクしています。

ボロネーゼのページから始めて、ジョーはピザのページまたはカルボナーラのページにジャンプできます。
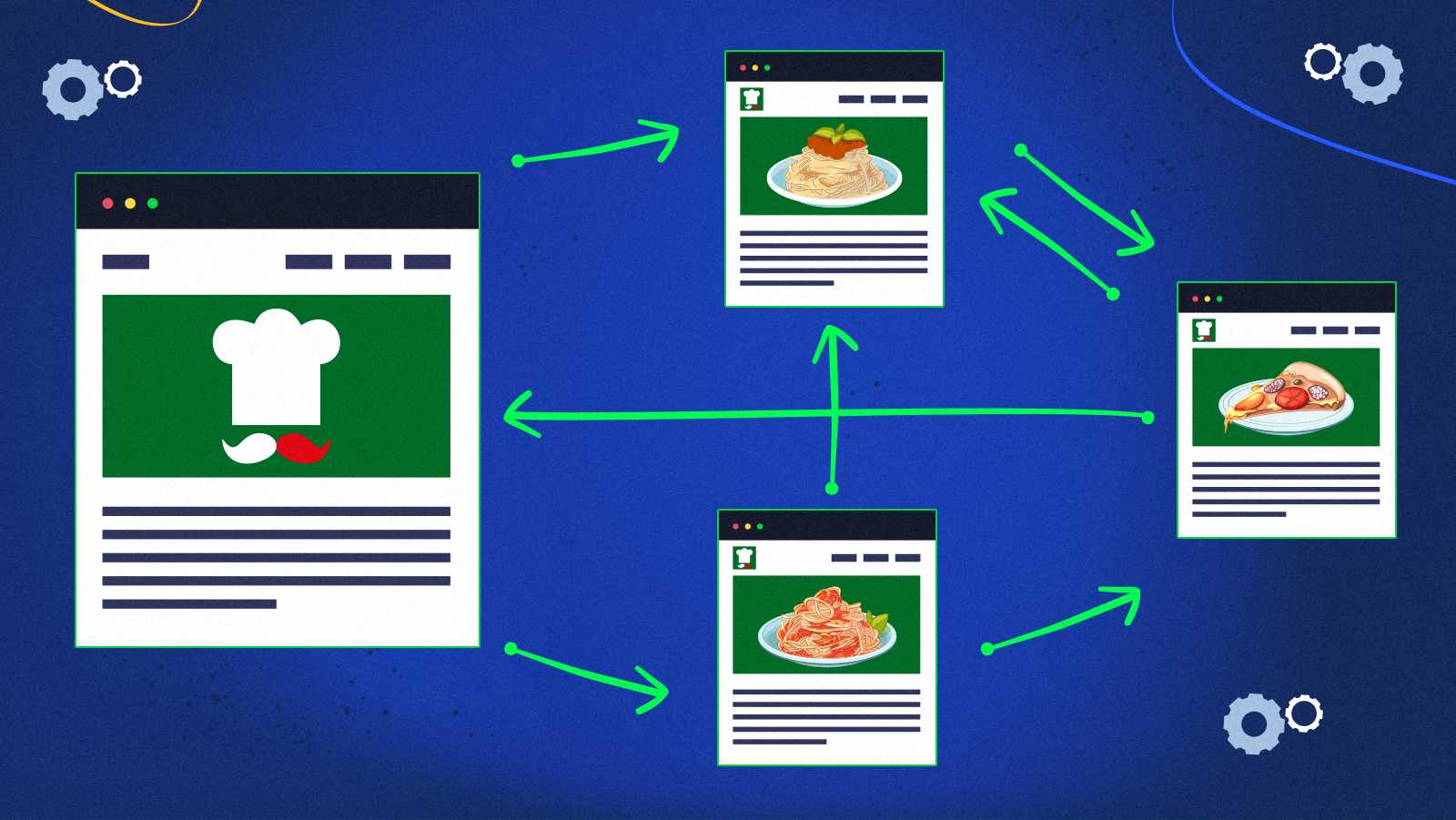
ジョーはとても躊躇している人です。 彼はこれらの4つのページの間を際限なくクリックします。
興味深いことに、これにより、これらの各ページにアクセスする確率が変わります。
ジョーがブログを読んだとき(1ページのブログだとしましょう)、ボロネーゼのレシピを開く可能性は50%で、カルボナーラのレシピを開く可能性は50%です。 しかし、彼がスパゲッティカルボナーラサイトにいるとき、彼はピザサイトに移動するしかない。 その後、彼はカルボナーラレシピに戻るか、ブログに戻ってサイクルを繰り返すことができます。 これらのオプションの両方の確率は50%です。
ジョーが最初のクリックでスパゲッティボロネーゼのウェブサイトにアクセスするには、2つのことが当てはまる必要があります。 まず、彼がブログから閲覧を開始する可能性が25%あり、次に適切なリンクをクリックする可能性が50%あります。
これらの確率を掛けると、ジョーが最初のクリック後にボロネーゼソースのレシピを読む可能性が12.5%あることがわかります。 ちなみに、ジョーが最初のクリック後にカルボナーラソースに関するウェブサイトにたどり着く可能性は37.5%です。
PageRankの再帰性
ジョーが4つのページのそれぞれに費やす時間を大まかに予測できます。 2回目のクリックでは、ジョーがさまざまなサイトで起動する確率は25%ではなくなりましたが、変動します。 数を何度も掛けることで、頻繁に推奨されるページからのリンクが、それらによってリンクされたページに移動する可能性を高めることがわかります。
これはPageRank再帰性と呼ばれ、PageRankスコアが高いサイトがPageRankスコアの多くを他のサイトに渡すのはそのためです。そのため、それらのサイトからのリンクはSEOで評価されます。
PageRank希釈
Random Surferモデルは、PageRankの希釈の優れた例でもあります。 カルボナーラレシピのページは、上記の例で最も権限がありました。 ピザレシピページにのみリンクし、ランダムサーファーはそこに移動する以外に選択肢がなかったため、ピザレシピページがPageRank値全体を取得できるようにしました。
ただし、カルボナーラページに2つの追加リンクが含まれている場合、ピザページは最初のPageRank値の3分の1を受け取ります。 その場合、ランダムなサーファーがピザページへのリンクを使用する可能性が1〜3回あります。
減衰係数
もちろん、Google特許に記載されているランダムサーファーは、インターネット全体でWebサイトの重要性を測定することが仕事であるため、相互にリンクしている4ページにとどまることができません。
それで、優柔不断なジョーが中華料理を食べることを好むかどうか躊躇していると想像してみましょう。 明日のためにパスタを食べるのをやめようと決心したなら、彼はブラウジングの旅を完全に断念するでしょう。 このシナリオに従うと、ダンピングファクターを理解するのに役立ちます。つまり、ジョーが特定の4ページを放棄して別のウェブコーナーを閲覧する代わりに、リンク構造をたどり続ける可能性です。
元の特許では、ラリーペイジとセルゲイブリンは0.85の減衰係数を使用することを提案しました。これは、訪問したすべてのページで、ランダムサーファーがページ上のリンクをクリックし続け、プロセスを完全に放棄しない確率が85%であることを意味します。
PageRankの数式
上記のすべてを、PageRankを計算するための単一の数式として表すことができます。 最も単純な形式では、Webに4ページしか含まれていない場合、次のようになります。
PR(A)= [PR(B)] / L(B)+ [PR(C)] / L(C)+ [PR(D)] / L(D)、
ここで、 PR(B)はページBのPageRankスコアを表し、 L(B)はページBのリンクの総数を表します。
この式は、ページAのPageRankが、ページB 、 C 、およびDのPageRankスコアの合計に等しく、それぞれがこれらのページから発信されたリンクの数で割られていることを示しています。
ただし、アルゴリズムがどのように機能するかを完全に把握するには、減衰係数dも考慮する必要があります。
PR(A)= [(1-d)/ N] + d {([PR(B)] / L(B)+ [PR(C)] / L(C)+ [PR(D)] / L (D)}
文字Nは、特定のコレクション内のドキュメントの数を表します。 このシナリオでは、 Nは4に等しくなります。
PageRank式のより高度な変換に興味がある場合は、PageRankに関するウィキペディアの記事を確認してください。
PageRankツールバーとは何ですか?なぜ削除されたのですか?
PageRankは、Googleがブラウザにインストール可能なツールバーを導入した2000年に誰もが夢中になりました。 Googleツールバーの機能の1つは、PageRankを表示することでした。 その開発者はそれを次のように説明しました。 ツールバーのPageRankを使用して、表示しているページの重要性をGoogleがどのように評価しているかを確認してください。」
ページがツールバーで取得できる最高のPageRankは10でした。ゼロは、ページが信頼と注目に値しないことを意味しました。
確かに、この数値は理解と追跡が容易であり、多くのSEOは、すべてのWebサイトの主要な成功指標としてこの数値を改善することに重点を置いていました。
これは、Web上のコンテンツの品質にとってひどいものであることが判明しました。 より良く、より有用なウェブサイトを作る代わりに、人々は彼らのPageRankスコアを改善するためにできるだけ多くのリンクを構築することに焦点を合わせました。 言うまでもなく、これらのリンクのほとんどはユーザーを支援するために作成されたものではなく、その目的はGoogleをだますことでした。
Google社員自身が、ウェブ管理者に他の指標に集中するよう説得しようとしましたが、ほとんど成功しませんでした。 PageRankは常に再計算されましたが、Googleがツールバーに表示される値を更新することはめったにありませんでした。 Google社員は、人々がPageRankスコアにさらに夢中にならないようにしたいと認めました。
ウェブ管理者のマナーを変更する試みが失敗したことが判明したとき、グーグルはついにPageRankディスプレイがより害と善を行っていることに気づきました。 ツールバーのPageRank表示は、2013年12月に最後に更新され、3年後、この機能は完全になくなりました。
重要なPageRankの更新
PageRankは、元の形式では理想的ではありませんでした。 時間の経過とともに、それを操作しようとする人々に対する改善と保護が必要であることが明らかになりました。
グーグルはまた、検索結果のランク付けにおけるPageRankの役割についてますます慎重になりつつあった。 最終的に、 Googleの元従業員は、同社が2006年以降元のPageRank特許を使用しなくなったことを明らかにしました。 これらのステップは、SEO業界全体がPageRankの操作にどれだけ集中していたかによって動機付けられた可能性があります。 ただし、元従業員は、新しいアルゴリズムの計算が大幅に高速であり、この変更の唯一の理由は、より効率的なものが必要だった可能性があることも指摘しました。
元のPageRank式がどのように進化し、現在検索ランキングでどのように使用されているかを知ることはできないかもしれません。 ただし、2004年と2006年に出願された2つの特許から2つの重要な変更を推測することができます。
リーズナブルなサーファー、ジョエルに会いましょう
2004年6月に出願された特許で、「ユーザーの行動や機能データに基づいてドキュメントをランク付けする」と、 GoogleはReasonableSurferModelについて説明しました。
なぜランダムサーファーは合理的になる必要があったのですか? 初期モデルの要素の1つは、サーファーが特定のページの各リンクをクリックする確率が同じであるという仮定でした。 これは、各リンクが同じ量のPageRank値を持っていることを意味しました。
もちろん、この前提は現実を完全には反映していませんでした。
自家製ピザを作って友達に感動を与えたいジョエルという女性を想像してみてください。 彼女はウェブを閲覧し、多くのレシピを見ています。 ページが他の提案されたレシピにリンクしているとき、彼女はそれらもランダムに表示しています。
それでも、現時点では、彼女は料理ポータルのプライバシーポリシーに関心を持っている可能性は低いです。 彼女はまた、バジルを育てるのに鉢を買う必要はありません。 彼女がこれらのリンクのいずれかをクリックする可能性はごくわずかです。
特許は次のように述べています。
本発明の原理と一致するシステムおよび方法は、サーファーが一連のリンクを有する文書にアクセスするとき、サーファーが他よりも高い確率でいくつかのリンクをたどることを示す合理的なサーファーモデルを提供し得る。 この合理的なサーファーモデルは、ドキュメントに関連付けられているすべてのリンクが同じようにたどられるとは限らないという事実を反映しています。 たまらないリンクの例としては、「利用規約」リンク、バナー広告、ドキュメントに関係のないリンクなどがあります。出典:ユーザーの行動や機能データに基づくドキュメントのランキング
ジョエルは優柔不断で混沌としているが、彼女は理にかなっている。 アルゴリズムはどのようにして彼女の行動をうまく模倣できますか? たとえば、 Webサイトでのリンクの位置を考慮する必要があります。 アンカーテキストのサイズと色も、ジョエルがクリックに興味があるかどうかを示唆している可能性があります。 アンカーテキストが商業的すぎるように聞こえる場合、彼女はサイトにアクセスすることを思いとどまるでしょう。 誰かが他の人の中でリンクをリストした場合、ジョエルはそのリストの上位にあるリンクをクリックする可能性が高くなります。
目標は、リンクによって渡される重みをその機能に従って区別することでした。 これらの重要な属性は、特許に記載されています。
リンクに関連付けられている機能の例には、アンカーテキストのフォントサイズ(…)が含まれる場合があります。 リンクの位置(…)、ドキュメントの側面。 リンクがリストにある場合、リンクの位置は リスト; リンクのフォントの色または属性(たとえば、斜体、灰色、背景と同じ色など)。 (…); リンクに関連付けられたアンカーテキストの商業性。 (…)。 このリストは網羅的なものではなく、リンクに関連付けられている機能の数が多い、少ない、または異なる場合があります。出典:ユーザーの行動や機能データに基づくドキュメントのランキング
シードサイト–それらは何であり、PageRankにどのように影響しますか?
PageRankの公式に影響を与えた可能性のある別の重要なアイデアは、定義上信頼できるページのセットを選択できることを理解することでした。
たとえば、政府所有のサイトが税制をだます方法を説明するブログにリンクすることはありそうにありません。 ジャーナリストが定性的調査を行い、未確認の情報を参照していない評判の良い新聞をいくつか特定することも可能です。
「Webリンクグラフの距離を使用してページのランキングを作成する」というタイトルの2006年の特許によると、これらのタイプのWebサイトは「シードサイト」です。 ドキュメントに記載されている2つの例は、GoogleDirectoryとTheNewYorkTimesです。 これらのページは事前に選択されているため、直接リンクしているページのPageRankが高くなると想定できます。

しかし、シードサイトによって直接リンクされているサイトによってリンクされているページはどうでしょうか。 選択されたシードサイトはそれらを認識しませんが、ニューヨークタイムズの信頼を勝ち取ったサイトの記事にジャンクリンクが含まれないことは確かです。 ランキングアルゴリズムでは、特定のページと選択したシードサイトの1つとの間の距離を計算するのが賢明です。
架空のイタリア料理愛好家協会のウェブサイトを想像してみてください。 その評判、プロの作家の採用、高品質のコンテンツにより、Googleはそれをシードサイトと見なすことができます。
簡単にするために、インターネット全体でスパゲッティボロネーゼレシピを含むページが2つしかない場合を想定します。 お腹が空いていてこの料理のレシピを探しているとき、Googleはどちらを最初に表示するかについてジレンマを抱えている可能性があります。 それで、彼らがイタリア料理愛好家協会の有名なウェブサイトにどれだけ近いかをチェックします。 シードサイトから2ページ離れたページは、信頼できるソースから7ページ離れたページよりもランクが高くなるはずです。
PageRankを増やすための時代遅れのSEO慣行
前に述べたように、ウェブサイトの所有者とSEOは、最高のPageRankスコアを取得するという巨大な野心を開発しました。 アルゴリズムは検索結果での位置に影響を与え、ウェブサイトの名声を証明しました。 一部のSEOは、ページが相互に受け渡ししたPageRankの値を「リンクジュース」と呼んでいました。 そして、誰もがそれを最後の一滴まで絞りたかったのです。

多くの人が満足するように、元のアルゴリズムは操作が簡単でした。 近道を取り、不公正な慣行を避けなかった人々は、質の低いサイトへの大量のトラフィックをうまく生成しました。 より多くのリンクを持つことは、ウェブサイトの可視性を高めるのに十分でした。 結局、それらのリンクがどこから来たのかは問題ではありませんでした。
グーグルは、インターネットが大規模なリンクファームに変わるのを防ぐために、その過ちからいくつかの教訓を学ばなければなりませんでした。 ブレークスルーは、ルールに違反したWebサイトを自動的にキャッチして罰する方法を開発したときに実現しました。
リンクスキームとは何ですか?
中華料理についてのブログを運営していると想像してみてください。 投稿を作成して知識を共有するときは、他の情報源を読者に勧めると役立つ場合があります。 時々、あなたはその主題に関する別のブログにリンクしたり、あなたが自分自身に行くであろう魅力的な料理のワークショップを促進したりします。
このようなリンクは「ナチュラル」と呼ばれます。 それらを投稿に含めると、情報が完全になり、より価値のあるものになります。 あなたは、誰かのPageRankを上げるのではなく、良いブログを作りたいという願望からそれらを作ることにしました。
ただし、Web上のすべての人があなたほど善意を持っているわけではありません。 人々は定期的にコンテキスト外のリンクを投稿しますが、ユーザーには何のメリットもありません。 彼らの目標は、検索結果で上位にランク付けしたいサイトを指すバックリンクの数を増やすことです。 これらの役に立たない被リンクは、購入されるか、自動的に生成されるか、請負業者に強制される傾向があります。
不自然なリンクを投稿し、PageRankを操作しようとするこのようなアクションは、リンクスキームと呼ばれます。 それらについてさらに詳しく説明しましょう。
リンクの売買
過去には、上位ドメインによるリンクの販売が一般的でした。 このタイプの慣行は、PageRankスコアが高いページからのリンクがリンクされたサイトのPageRankスコアを大幅に増加させるという原則を乱用しました。 グーグルは2007年にワシントンポストの販売リンクをキャッチし、2013年にBBCをキャッチしました。ペナルティとして、彼らのウェブサイトのPageRankスコアは手動で下げられ、その後数か月で多くの訪問者を失いました。
グーグルはかつて自社製品を罰しなければならなかった。 2012年、 Google Chromeの公式ウェブサイトは、購入したブログ投稿を宣伝に使用していました。 ペナルティによりドメインのPageRankが削除され、最初の検索結果ページに「ブラウザ」クエリのChromeのページが表示されなくなりました。
Googleは、リンクを販売するサイトに対する手動のペナルティが常にPageRankの削減であるかどうかを明らかにしていませんが、 2010年代初頭からのGoogleの手動アクションに関する報道によると、それがその構成要素であることが示唆されています。
ツールバーにPageRankスコアが表示されたとき、それはアルゴリズムによる計算結果だけでなく、特定のポータルに関するGoogleの意見の表現でもありました。 そしてグーグルは以前ほど不自然なリンクを売っているウェブサイトを信用できなかった。
Googleの元Webスパムチームの責任者であるMattCuttsは、 YouTubeのビデオでPageRankの手動降格の問題について言及しています。
リンクの売買には必ずしもお金がかかるとは限りませんでした。 以前は、2つの無関係なページが交換で相互にリンクすることに同意していました。 さらに、一部の起業家は、店舗のWebサイトへのリンクを添付する見返りに、他の人に「無料」の製品を送ることにしました。 一部のビジネスマンは、自分のサイトへのリンクを会社のサービスを使用する条件にしました。 彼らは通常、請負業者が取引のこの部分をオプトアウトすることを許可しませんでした。
スパムコメント
もう1つの悲しい出来事は、Webにスパムコメントを投稿することでした。 誰かがあなたの中華料理に関するブログのPageRankが高いことに気づき、読者には興味がないのに、投稿の1つの下にカルボナーラレシピへのリンクを含むコメントを投稿したとします。 そのような行動は確かにあなたのブログでの生産的な議論を刺激せず、不自然に別のページのランキングを上げるのに役立つだけです。
リンクファーム
数年前のインターネットユーザーも、きのこのように湧き出るリンクファームを観察することができました。 リンクファームは、ランキングを上げるためにすべてが相互にリンクしているWebサイトのグループです。 以前、PageRankがランダムなサーファーの動作をシミュレートする方法と、相互にリンクする4つの料理ページでどのように機能するかについて説明しました。 同じ作成者がこれらすべてのページを作成し、その唯一の目的がそのうちの1つのPageRankを増やすことだった場合はどうなりますか?
著者がこれらの追加のページを独立した情報のソースにしたのではなく、ランダムなサーファーにカルボナーラのレシピでサイトにアクセスする可能性を高めるためだけに作成したと想像してみてください。 彼らの態度は、ウェブ上での信頼できる満足のいくコンテンツの構築をサポートしておらず、Googleの目標に対応していません。
ほとんどのリンクファームは人間の手によって作成されたのではなく、毎日何百もの新しいジャンクページでサーバーを埋めることができる自動プログラムによって作成されました。 リンクファームは、Webをスパムで埋め尽くすため、非常にネガティブな現象と見なす必要があります。
ペンギンのアップデートとは何ですか、そしてそれはどのように不正なSEOと戦うのですか?
2012年4月に、新しいGoogleアップデートが発表されました。 フレンドリーなコードネーム「ペンギン」にもかかわらず、PageRankを操作したWeb管理者と激しく戦うことを目的としていました。 Googleは、ペンギンアルゴリズムをプログラムして、不自然なリンクを探し、それらの恩恵を受けたサイトにペナルティを課しました。
ペンギンのリリース後、多くのWeb管理者は、Webサイトのランキングが突然低下したことに驚いていました。 失われたPageRankスコアを取り戻すには、バックリンクの面倒なクリーンアップを行う必要がありました。 彼らはしばしば彼らのサイトへの不自然なリンクを削除するために電子メール要求を送信しなければならなかった、そしてグーグルはそれらの行動を細心の注意を払って文書化することに感謝した。
不要なリンクでウェブサイトに連絡することが不可能な場合、続行する方法は、Googleに適切なリクエストを送信してウェブサイトを否認することでした。
ペンギンアルゴリズムは7回更新され、Googleのコアインフラストラクチャの一部になりました。 それが導入されて以来、リンクファームや購入リンクは、少なくとも長期的には、Webサイトの可視性を損なうだけです。 リンクスパムは今日も続いていますが、この対策のおかげでその効果は大幅に低下しています。 私たち一人一人が、ペンギンが検索結果の品質を守るのを手伝うことができます。 不自然なリンクを観察した場合は、このGoogleフォームを使用してリンクスキームを報告できます。
現代のSEOにおけるPageRank
PageRankは、最初に導入されて以来、長い道のりを歩んできました。 アルゴリズムは、リンクスキームを凌駕し、さまざまなタイプのリンクを区別することを学ぶ必要がありました。 検索結果のランク付けにおけるその正確な役割は秘密のままです。
では、より良いSEO戦略を構築するために、PageRankについて何を理解する必要がありますか?
GoogleはまだPageRankを使用していますか?
PageRankは、ランダムなサーファーがサイトで費やす時間を測定するアルゴリズムとして始まりました。 時間の経過とともに、リンクの場所とアンカーテキストを考慮に入れ、サーファーがリンクをたどる確率を区別することを学んだ可能性があります。 アルゴリズムはまた、操作に耐性を持ち、定義上信頼できるシードサイトの認識を開始する必要がありました。
これらすべての重要なPageRankの変更と、遅くとも2006年に元の特許が放棄されたという事実から、Googleがこのアルゴリズムを使用しなくなった可能性があると思われる可能性があります。 しかし、グーグルはそもそもそれをとても成功させた解決策を忘れなかった。
PageRankに関するJohnMuellerからのこのツイートは、Googleがまだ有名なアルゴリズムを使用していることの証拠として役立つ可能性があります。 グーグルウェブマスタートレンドアナリストのゲイリーイリーズもツイッターで、PageRankがランキングにおいて依然として重要であることを確認した。
健全なリンク構築の原則
現在、PageRankバーを使用して、WebサイトのPageRankスコアを表示することはできなくなりました。 ただし、その隠れた価値は依然として検索の可視性の基本であり、増やすことができます。
あなたは確かにPageRankを改善するためにリンクにお金を払うべきではありません。 これはGoogleのガイドラインに厳密に違反しており、長期的にはランキングを損なうことになります。
代わりに、次の2つのことに焦点を当てる必要があります。
- ドメインへの外部PageRankフローを改善するために、定性的なバックリンクを自然に取得する高品質のコンテンツを作成します。
- コンテンツが内部で接続されており、サイトで内部PageRankを適切に配布できるようになっていることを確認してください。
定性的被リンク
あなたが中華料理についてのブログを始めたと想像してください。 スポンサーリンクがGoogleのガイドラインに違反せずにPageRankを渡すことができない場合、どうすればこのページのランキングを向上させることができますか? そこで、デジタルPRが活躍します。 従来のPRは、報道機関などの従来のメディアを使用してブランド認知度を高めることに重点を置いていますが、デジタルPRはオンライン手法に重点を置いています。
ブロガーやジャーナリストに連絡して、ブログで実行しているプロジェクトについて書くよう提案することができます。その中で、栄養士に調査を送信し、中華料理を食べることの健康上の利点に関する調査結果を公開します。 コンテンツクリエーターは、中華料理に関する数千のブログの1つであるため、Webサイトの存在だけに興味を持つ可能性は低いですが、研究に興味を持ってもらうことができます。
あなたがしつこいなら、あなたはいくつかのニュースや記事で取り上げられることができます、そしてそれらであなたは自然で価値のあるバックリンクを得るでしょう。
内部リンク
PageRankディスカッションの内部リンクを無視することはできません。 内部リンクには、次の2つの重要な目的があります。
- それらは個々のランキングに影響します。
- ブラウザがサイトをナビゲートするのに役立ちます。
正しい接続がないと、Googleによって検出されない可能性があるため、Webサイトの個々のページが互いにどのようにリンクするかが重要です。 たとえば、内部リンクがそれらを指していることのない、いわゆる孤立したページを作成することは大きな間違いです。 これらの問題に関する記事は、内部リンクの問題を修正する方法を学ぶのに役立ちます。
PageRankとサブドメインおよびサブフォルダー
興味深いことに、PageRankを最適化する際に自問したい主な質問の1つは、Webサイトのサブドメインまたはサブフォルダーを作成することの間のジレンマです。 たとえば、中華料理に関するブログに、初心者向けのバージョンと専門家向けのバージョンがあるとします。
広く受け入れられている理論によると、Googleは、ブログとそのエキスパートバージョンサブフォルダ間のリンクを内部リンクとして解釈しながら、エキスパートバージョンサブドメインをブログとは別のウェブサイト(およびそれらの間のリンクを外部リンク)と見なす場合があります。
バリーアダムスのような多くの著名なSEO専門家は、より高い減衰係数がサブドメインへのリンクに負担をかけると主張しています。 したがって、ブログはそれらに渡すPageRankを減らし、サブフォルダーに渡すPageRankを増やします。 ただし、人々がこの推測をアルゴリズムのやや時代遅れの理解に基づいていることは注目に値します。これは、常にそのような予測可能な方法で動作するとは限りません。
Googleウェブマスターガイドラインに違反しないようにするにはどうすればよいですか?
PageRankは、検索エンジンのユーザーが信頼できるサイトから高品質のコンテンツを見つけられるようにすることを目的としています。 バックリンクは、自然な場合にのみこの信頼を測定できます。 つまり、ユーザーの検索のコンテキストで役立つページを参照します。
PageRankを操作する試みとしてリンクを販売すると、WebサイトがGoogleによって課せられるペナルティにさらされ、ランキングと可視性が低下します。 2012年のペンギンの更新に続いて、 Googleのアルゴリズムはそのような慣行を自動的に検出してペナルティを科します。
今、あなたはどれほど多くのウェブサイトが彼らの可視性を損なうことなく彼らのコンテンツの中で広告を維持しているのか疑問に思うかもしれません。 秘密は、適切にタグ付けされている場合、Googleはあなたの商用リンクを不自然または不正とは見なさないということです。
あなたがあなたのウェブサイトとリンクの間の関係を公然と説明するとき、グーグルはそれを感謝します。 ガイドラインの偶発的な違反を回避するために、リンク属性を使用できます。リンク属性は、HTMLコード内の各リンクを説明する非表示のテキストです。
Nofollowタグ
nofollowタグは、リンクされたページにPageRankを渡さないようにGoogleに指示する最も古い方法です。 SEOは、PageRankの値を比較して、あるサイトから別のサイトに「注ぐ」ことができるジュースをリンクします。 彼らは、あなたのウェブサイトがリンクの穴から注がれているリンクジュースのグラスである場合、nofollowタグはグラスの中に液体を保持するテープのスライスであると言うことができます。
別のページにリンクしてもPageRankが失われることはないため、このメタファーは明らかに不完全です。 ただし、nofollowタグを使用して、承認したくないページに権限が渡されるのを防ぐことができます。
nofollowタグは、<a>HTML要素内で次のように使用する必要があります。
<a href=”http://www.example.com”rel=”nofollow”>いくつかのアンカーテキスト</a>
スポンサータグとUGCタグ
In September 2019, Google announced two new rel attributes designed to stop the PageRank flow. You can put them into HTML the same way as nofollow tags. Here's what they look like and what they do in comparison to the nofollow attribute:
| Nofollow tag | Sponsored tag | UGC tag |
| rel=” nofollow” | rel=” sponsored” | rel=” ugc” |
| Marks links to sites you don't want to pass any PageRank to for whatever reason. | Marks links resulting from a paid advertisement or endorsement. | Marks links posted by your website's users that might be spam, and you don't want to take responsibility for them. |
Google indicated that it isn't necessary to change the existing nofollow tags to more specific UGC or sponsored tags but recommended using them in the future. It's also possible to use more than one rel attribute to mark a single link.
At the same time, as stated in the announcement, from now on, the described tags will no longer serve as an absolute PageRank blocker but rather as hints for Googlebot. However, their use is still required if you don't want your site to be penalized for unnatural linking.
PageRank and redirects
Sometimes, you may need to move your website or page to a different address. Surely you'd like its PageRank to be retained. Fortunately, using a 301 redirect will help you achieve precisely this effect.
People have many doubts about how Google treats 302 redirects regarding PageRank. Due to the fear of losing PageRank, web admins often give up using those redirects. In one of the SEO Office Hours meetings, John Mueller confirmed that concerns around 302 redirects are unfounded. The 302 redirect allows the original address to retain the whole PageRank value.
PageRank and links shared on social media
A participant of a different SEO Office Hours meeting asked another interesting question whether the number of followers or likes increases the PageRank passed by the social media profile. We found out then that Google doesn't consider social media activity with regard to PageRank. Even if the search engine treats a social media profile as a regular webpage, the number of likes it has will not affect the PageRank passed.
Measuring PageRank
Since Google Toolbar isn't available anymore and Google no longer uses the original PageRank formula, there aren't any methods you can use to measure PageRank for your web pages or even to see its approximation.
However, it's still helpful to analyze your website's link profile, and for that, you need an alternative metric. There are several metrics that are popular in the SEO industry that attempt to simulate PageRank. Although Google doesn't use any of those metrics for ranking web pages, using them can be useful when auditing your website.
Page Authority and Domain Authority
Page Authority and Domain Authority are metrics developed by Moz to illustrate a page's or a domain's ranking potential. PA and DA range from 0 to 100 on a logarithmic scale, making it easier to improve them from 20 to 30 points than from 60 to 70 points. To calculate Page and Domain Authority, Moz uses data from the Mozscape web index and machine learning algorithms.
Trust Flow and Citation Flow
Trust Flow and Citation Flow by Majestic assess a website's authority based on its backlink profile. Citation Flow shows how many links point to your website, while Trust Flow focuses on the quality of those links.
Trust Flow grows when popular and reputable websites link to your page and will always score lower than Citation Flow, which considers all links no matter their status.
Domain Rating
Domain Rating is a metric developed by Ahrefs. It's calculated on a logarithmic scale of 0 to 100. Domain Rating is based on backlinks Ahrefs found pointing to your site without nofollow tags.
Ahrefs designed it to measure the authority of entire websites, not individual pages.
Key takeaways
- PageRank is an algorithm that helps Google evaluate the popularity and credibility of websites. It allows Google to surface more relevant content in search results. By assessing the number of links on pages and their quality, PageRank estimates how much time a random surfer would spend on them.
- By getting your website linked to other reputable domains, you increase your PageRank score and your chances of ranking high.
- For every page within your domain to rank high, you should also take care of proper internal linking to improve your internal PageRank flow.
- Google penalizes attempts to manipulate PageRank with unnatural links. Remember to correctly mark your links with nofollow, sponsored, and UGC tags to avoid traffic loss.