
最新のデータスタックを作成する方法
公開: 2022-05-06今日のテクノロジー主導の経済では、データストレージはかつてないほど複雑になっています。 IDC(International Data Corporation)によると、2025年には175ゼタバイトのデータが生成されます。これは2021年に生成された量(61ゼタバイト)のほぼ3倍に相当します。
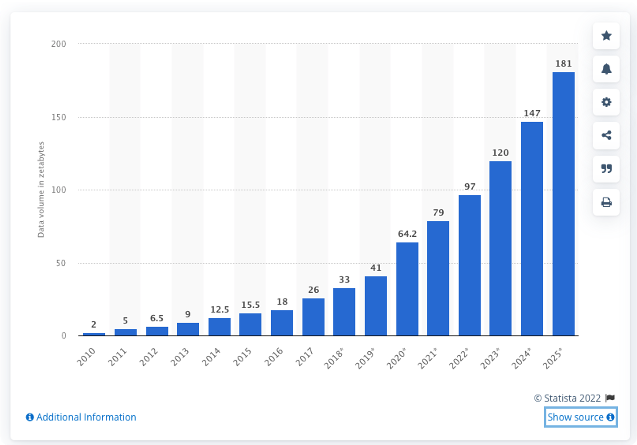
Statistaから2010年から2025年にかけて世界中で作成、キャプチャ、コピー、消費されたデータの量
会社の情報を正しく保存および管理する場合は、利用可能な多くのオプションと、それらを統合する方法を理解する必要があります。
幸い、このガイドは、データを収集、保存、分析し、最終的に可能な限り最も効果的な方法で利用できる最新のデータスタックを構築するのに役立ちます。 この青写真は、企業の規模や業種に関係なく、開発のあらゆる段階で企業が使用できるほど柔軟です。
なぜ最新のデータスタックが必要なのですか?
最新のデータスタックは、データのエンドツーエンドのライフサイクルを処理するための統合されたツールセットです。 リアルタイムで情報を収集、処理、およびアクティブ化するように設計されています。 傾向を詳細なレベルで理解し(たとえば、クライアントの組織内で)、永続的に定着する前にそれに基づいて行動したい組織にとっては不可欠です。
最新のデータスタックを作成することは難しくありませんが、ある程度の時間とコミットメント、およびデータから何が必要かを正確に理解する必要があります。 運用の改善と顧客への洞察の獲得に真剣に取り組んでいる場合は、1分ごとに努力する価値があります。 秘訣は、どこから始めて、どのように前進するかを知ることです。
このガイドの残りの部分では、最新のデータスタックを作成するために必要なすべての情報を提供します。 さまざまなコンポーネントがどのように連携するか、および最新のデータスタックの各部分にソフトウェアを選択する方法を学習します。 読み終えたら、今日の組織で最新のデータスタックの構築を開始するために必要なすべてのものが揃っています。
「データの観点からは、データウェアハウスアプライアンスは真の金鉱です。 垂直統合ソリューションで利用できるようにすることは、業界クラウドのアイデアの中核です。」
AshishThusoo
データレイクとデータウェアハウス:最新のクラウドデータプラットフォームの両面
最新のデータスタックの利点
なぜ最新のデータスタックに投資するのですか? ここにいくつかの利点があります:
- データを数分で簡単に抽出して、任意の宛先にロードできます。
- カスタムスクリプトを記述したり、アドホッククエリを作成したりすることなく、大量の非構造化データ(ドキュメント、検索結果、さまざまなメトリックなど)を分析します。
- すべてのビジネスチームが、独自のツールで運用、信頼、および最新のデータを使用してセルフサービスを利用できるようにします。
- ビジネスチーム向けのノーコードツールを統合することにより、組織にイノベーションをより迅速に展開します
- 最新のデータスタックは、データパイプラインを構築および維持する必要をなくすことにより、データエンジニアリングのオーバーヘッドを削減します。
現在の環境を理解する
ソリューションを設計するための最初のステップは、修正しようとしていることを理解することです。 一歩下がって、組織が現在使用している現在のツール、プロセス、および手順を確認してください。 次に、自問してみてください。効率的ですか。 改善の余地はありますか?
最新のデータスタックは効率がすべてであるため、現在のプロセスに非効率がある場合(そして私を信じてください)、それは合理化できる領域です。
チーム間のコラボレーションを増やしたり、プロセスを更新したりするのと同じくらい簡単な場合もありますが、古いソフトウェアを置き換えたり、環境に新しいテクノロジーを導入したりすることを意味する場合もあります。
それが何であれ、設計作業を進める前に、解決しようとしている問題を正確に定義することから始めます。 これにより、将来の実装がはるかに簡単になります。
ビジネスニーズと目標を特定する
ビジネス用のデータベースを選択する前に、そのデータモデル、必要なクエリとレポートの種類、およびデータベースを使用するユーザーを理解する必要があります。 これらの質問への回答を得ることは、ビジネスが(将来的に変更を加えるのではなく)事前の計画を開始するのにも役立ちます。
ここでの重要な質問の1つは、データストアの大きさがどれだけ必要かということです。 たとえば、OLAP(オンライン分析処理)シナリオでは、行はたくさんありますが、各行にはデータがほとんどありませんが、オンライントランザクション処理(OLTP)シナリオでは、大量のデータを含む行がたくさんあります。各行には、より多くのストレージスペースが必要です。 そして、さらに多くのスペースを必要とするビジネスインテリジェンス(BI)レポートのニーズがあります。 このような場合、BigQueryは、3つのシナリオすべてを非常にうまく処理できる完璧なストレージです。
もう1つ考えるべきことは、クラウドとオンプレミスのどちらのストレージを使用するかということです。 したがって、オンプレミスインフラストラクチャにすでに投資している場合は、GoogleCloudPlatformが適切でない可能性があります。
スケーラビリティとパフォーマンスを計算する
クラウドプロバイダーを選択するときは、アプリケーションが時間の経過とともに期待どおりに拡張および実行されるかどうかを検討することが重要です。
もう1つの重要なことは、各環境でデータがどのように保護されるかを理解することです(たとえば、データセンターでは、自然災害、停電、または機器の障害が発生する可能性があります)。
これらのすべてのステップと同様に、調査を行い、質問をすることが不可欠です。 New Relicなどの企業は、アプリケーションのパフォーマンスとトラフィックを監視するのに役立つツールを提供しています。
さらに、Netflixのような組織は、パブリッククラウドで実行される最新のアプリケーション用に特別に設計されたオープンソーステクノロジーを作成しました。 たとえば、Netflixは、大規模なAWSベースの環境の監視と保護に役立つソフトウェアであるSecurityMonkeyを開発しました。
クラウドプロバイダーを評価するときは、これらのテクノロジーを掘り下げる価値があります。この種の知識は、さまざまな企業のエンジニアと話し合い、彼らの経験を理解することから得られます。
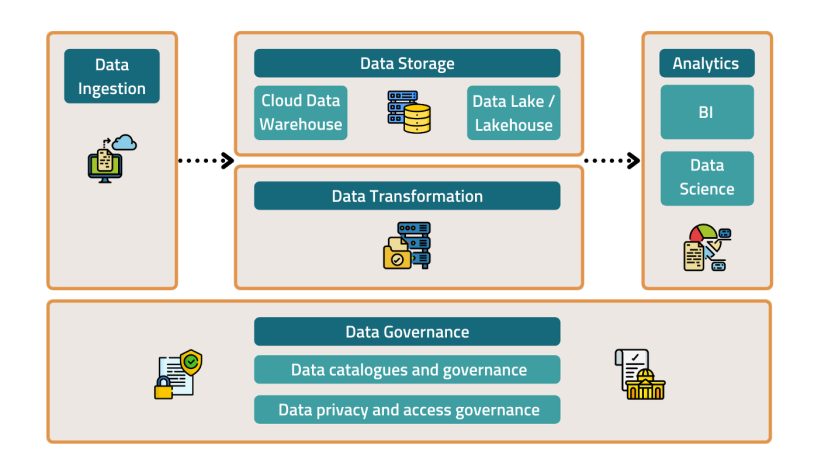
最新のデータスタックのコンポーネント
データは戦略的資産です。 それを最大限に活用するには、データスタックを構成するさまざまなコンポーネントとそれらがどのように連携するかを理解する必要があります。
製品の独自のデータインフラストラクチャを設計するときに含めるデータスタックの主要コンポーネントは次のとおりです。
- データの取り込み
- データストレージ
- データ変換
- データ分析
- データガバナンス
1.データの取り込み
データの取り込みとは、ある場所からデータウェアハウスやデータレイクなどの新しい宛先にデータをインポートして、さらに保存および分析することです。
最新のデータスタックを作成するための最初のステップは、データソースを特定することです。 データ取り込みツールのおかげで、すべてのデータを数分でインポートできるようになります。
あなたがeコマースビジネスを運営しているとしましょう。問い合わせはあなたが販売する製品とそのバリエーションに限定されなければなりません。 誰かが購入すらしていないアイテムをクエリしたため、1日に何百ものクエリがデータベースにヒットすることは望ましくありません。 顧客グループ、SKU、またはその他のフィルターで製品をランク付けしてフィルター処理し、[ストアにアクセス]ボタンを使用してユーザーフレンドリーなアクセスを提供します。これにより、顧客はサイトを通じて行われた販売の注文履歴を簡単に取得できます。
ツールの例:Improvado、Fivetran、Stitch、Airflow
️上位16のデータ取り込みツールのリストは、データスタックに最適なツールを選択するのに役立ちます️
2.データストレージ
クラウドネイティブアプリケーションとマイクロサービスの台頭により、ほとんどの企業は、保存と管理が必要な大量のデータを生成しています。 これは、構造化データ用に設計された従来のリレーショナルデータベースにとっては困難な作業です。
NoSQLデータベースは非構造化データに最適ですが、特にハイブリッド環境では、大規模に展開するのが難しい場合があります。
クラウドプロバイダーは、このステップを支援する独自のマネージドソリューションを提供します。 たとえば、AWSは、オブジェクトストレージ用のAmazon Simple Storage Service(S3)と呼ばれるソリューションを提供しています。 GoogleはCloudPlatformの一部としてBigQueryを提供しています。 どちらのサービスも、大量のデータを大規模に保存するための低レイテンシのプラットフォームを提供します。
ツールの例:Snowflake、Databricks、AWS、GCP
トップ15のデータウェアハウジングツールのリストを読んで、ビジネスニーズに合ったツールを見つけてください
3.データ変換
データ変換は、データをある形式または構造から別の形式または構造に変換するプロセスです。 通常、データ変換は、抽出、変換、および読み込み(ETL)技術を使用して実行されます。
ETLプロセスが手動のデータ操作をどのように加速するかを学ぶ
データ変換は、さらなる分析、レポート、および視覚化のためにデータを準備および正規化するため、データ統合プロセスにおいて非常に重要です。 データ変換は、元の形式や指定に関係なく、任意のタイプのデータセットで実行できます。
ツールの例:Improvado DataPrep、Dbt、MCDM、Matillon、Alteryx、RestApp

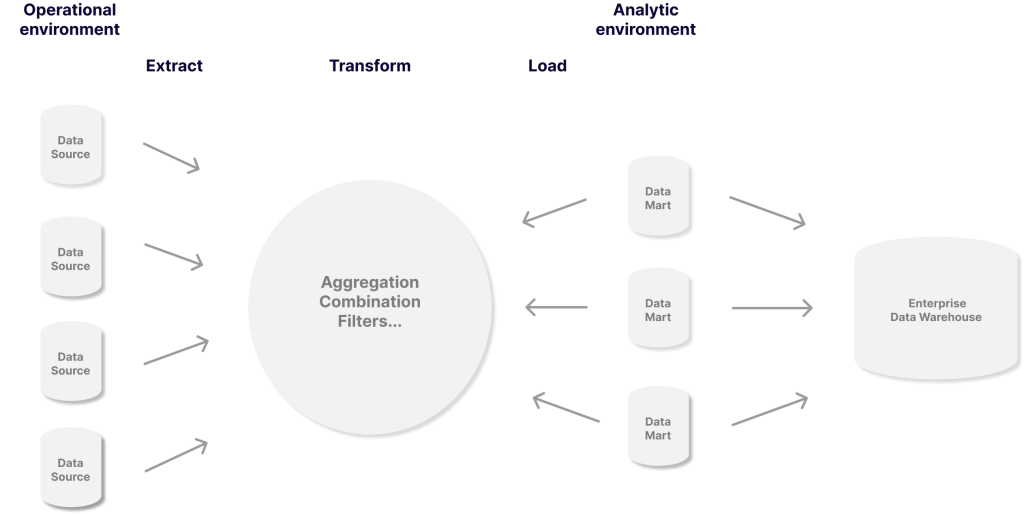
4.データ分析
分析レイヤーは、データを集約、分析、およびユーザーに提示する役割を果たします。 分析レイヤーは、次のような質問に答える必要があります。
- 私のビジネスの主要な指標は何ですか?
- これらの指標は時間の経過とともにどのように変化しますか?
- あるメトリックが別のメトリックにどのように影響しますか?
ほとんどの場合、これは、データがグラフ、チャート、表、およびすぐに理解できるその他の視覚的表現に変換されることを意味します。
最近の一部のデータ分析プラットフォームには、技術者以外の人がSQLを知らなくてもデータを調査できる機能があります。
ツールの例:Looker、Tableau、Power BI
「ビッグデータ分析がなければ、企業は盲目で耳が聞こえず、高速道路で鹿のようにウェブ上をさまよっています。」
ジェフリー・ムーア、作家、コンサルタント。
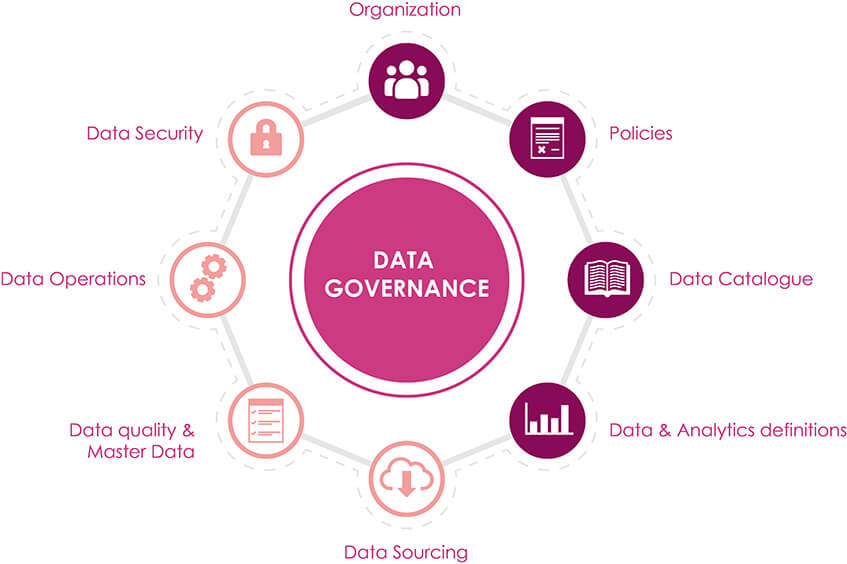
5.データガバナンス
データパイプラインのすべてのステップについて、明確な所有権とプロセスを確保することが不可欠です。 これには、収集されるデータの種類とそれらの保存およびアクセス方法の基準の設定、およびこれらの基準に準拠して実施されることを保証するプロセスが含まれます。
データを使用して運用効率を向上させることが目標であるとします。 異なるコードやシステムを手動で調整しなくてもサプライチェーンの全体像を把握できるように、すべての在庫システムで同じバーコードシステムを使用することを決定する場合があります。
ツールの例:Atlan、Microsoft Azureデータカタログ、Informatica
リバースETLの代替
多くの企業は、ETLテクノロジーを使用してデータスタックを構築しています。 これらのテクノロジーは、複数のソースからの大量のデータを処理し、それを一元化されたデータウェアハウスに移動するのに役立ちます。 ただし、このアプローチではインフラストラクチャが複雑になり、配信時間が遅くなります。
今日の世界では、財務、サプライチェーン管理、顧客関係など、リアルタイムのデータに基づいてビジネス上の意思決定が行われることが増えています。 最新のデータスタックを使用すると、データを最新の状態に保ち、アクセス可能で安全な状態に保つことで、組織全体にリアルタイムの洞察を提供できます。
ここで、Reverse ETLは、ビジネスにリアルタイムの価値を提供し、古い情報による障害のリスクを排除する最新のデータスタックを構築するのに役立ちます。
リバースETLは、データウェアハウスからCRM、CMS、製品、または任意のビジネスツール(Slack、Google Sheetなど)などの運用ツールにデータを同期する一連のメソッドまたはプロセスです。
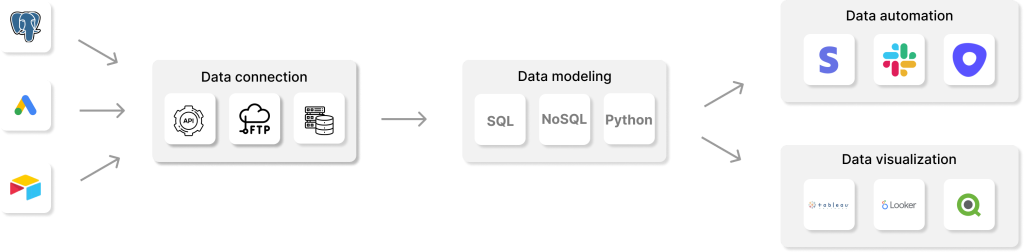
このプロセスの背後にある考え方は、エンタープライズデータのまとまりのある信頼できるビューを提供する単一の包括的なデータソースを作成することです。 リバースETLプロセスは通常、既存のETLプロセスを拡張するために使用され、定義された時間間隔で実行されます。 さらに、リバースETLにより、運用分析が可能になります。
オペレーショナルアナリティクスとビジネスインテリジェンス
オペレーショナルアナリティクスは、データ、予測分析、およびビジネスインテリジェンスツールを使用して、ビジネスオペレーションに関する洞察を得て、アクティブ化されたデータのおかげでリアルタイムのアクションを生成します。
ビジネスインテリジェンス(BI)は、Investopediaによって、企業の活動によって生成されたデータを収集、保存、および分析する手続き型および技術的なインフラストラクチャとして定義されています。
ビジネスインテリジェンスは、履歴データの分析に重点を置いています。
何が起こったのか、そしてその理由を理解するのに役立ちます。 これは、データ比較、ベンチマーク、およびその他の統計手法を通じてパターンと傾向を特定することにより、ビジネスの意思決定をサポートするために使用されます。
たとえば、特定の期間に行われた注文の数、平均注文値、および注文の総数を示すレポートを作成することは理にかなっています。
運用分析は、リアルタイムと将来に焦点を当てた概念です。 これは、現在何が起こるかに焦点を当て、次に何が起こるかを予測して、将来のチャンスを最大限に活用できるようにします。
要約すると、オペレーショナルアナリティクスは、私たちが今どこで行動する必要があるかを示し、ビジネスインテリジェンスは、何が間違って行われ、何が改善のポイントであるかを明らかにします。
運用分析は、Google、Facebook、Netflixなどのデジタル巨人に限定されなくなりました。 リアルタイムデータのおかげで、最新のデータスタックを使用する企業は、より多くのデータ主導の意思決定を行うことができます。
組織の進化が必要
企業が最新のデータスタックを実装する場合、データの管理方法には3つの大きな変化があります。
ITからビジネスユーザーへの移行
これまで、IT部門は、部門やアナリストからのデータの要求に対応していました。 TableauやLookerなどのセルフサービス分析ツールの開発により、ビジネスユーザーはデータに直接アクセスして分析できるようになりました。
この変化は、企業がデータを中心にリソースを編成する方法に大きな影響を及ぼします。
バッチからリアルタイムのデータ処理まで
。 データパイプラインがより合理化され、組織全体でデータにアクセスしやすくなるにつれて、イベントが発生してから分析されるまでの遅延時間を短縮する必要があります。
これは、より多くの企業が、長期間にわたってデータを集約するのではなく、データのリアルタイム処理を検討していることを意味します。
サイロ化されたデータベースからフェデレーション所有権(ドメイン)まで
従来のデータアーキテクチャは、サイロ化されたデータベースとフェデレーション所有権を中心に構築されているため、データレイク、データマート、データウェアハウスが急増しています。
これらのアーキテクチャは、集中型の計算とストレージインフラストラクチャに重点を置いています。 クラウドサービスが成熟し、近代化するにつれて、データスタックを設計するためのアプローチも成熟するはずです。
今日のデータアーキテクチャは、さまざまなテクノロジーに分散している最新のアプリケーションの規模と複雑さを処理できなければなりません。 ここで、データメッシュの概念が登場します。これは、あらゆるタイプのデータに安全にアクセスして簡単に管理し、あらゆるアプリケーションでどこからでも利用できるようにする新しいアーキテクチャです。
利害関係者に依存する
最新のデータスタックに関しては、主に3つのタイプの利害関係者がいます。
内部の利害関係者
これらは、日常業務でデータを使用する組織内の人々です。
たとえば、営業チームは、各顧客がもたらす収益の量と、その収益を増やす方法に関心がある場合があります。 または、マーケティングチームは、どのタイプのコンテンツが最も多くのWebサイトトラフィックを促進するかに関心があるかもしれません。
内部の利害関係者は、収集するデータ、そのデータの構造化方法、およびデータの分析に使用するツールについて発言権を持っている必要があります。
外部の利害関係者
これらはあなたの会社の外から来た人々ですが、彼らはまだあなたの成功に賭けています。
たとえば、ビジネスがサービスとしてのソフトウェア(SaaS)企業である場合、製品のユーザーは外部の利害関係者です。 あなたのビジネスが製品をオンラインで販売し、それらを全国または世界中に出荷する場合、顧客とサプライヤーは外部の利害関係者です。
そのデータを適切かつ効率的に配信できるように、彼らがあなたから何を必要としているかを理解することが重要です。
サードパーティの利害関係者
これらは、組織外の人々であり、会社にもサービスを提供しています。 たとえば、原材料を提供するベンダーや、テクノロジーインフラストラクチャのセットアップを支援するITコンサルタントなどです。 データの観点からブラインドハエを避けたい場合は、データ分析をマスターする必要があります。 これには、4つの壁の外側でのデータの開発がますます必要になります。
最新のデータスタックは、チームごとに定義されたドメインとノーコード環境で使用できる機能のおかげで、データのより効率的な共有により、会社とその利害関係者の間の関係を強化します。
データドメインはすべて同じドメインで動作するため、チーム間の関係を強化します。
たとえば、マーケティングチームは、新しい製品またはサービスにサインアップする人の数と、サインアップ後にそれが生み出す収益を知りたいと考えています。 製品チームによって生成されたデータは、どちらも同様のスペースで機能するため、マーケティングチームに関連しています。
結論
ご覧のとおり、データスタックを設定する際に考慮すべきことがたくさんあります。 関係するさまざまなコンポーネントのすべてを考えると、これは大きな仕事であり、すべての可動部品の周りに腕を動かすのは難しい場合があります。
データスタックが必要な理由と、それがビジネスにどのように役立つかを理解することで、実装の明確なプロセスとタイムラインを設定することで、長期的な計画を立てることができます。 最新のデータスタックを使用する利点は、個々のプロジェクトやイニシアチブだけでなく、全体としてより良い意思決定を行うのに役立つ強力な基盤を確立するという点でも、途中の課題を上回ることです。