
使用 Google Analytics 和 Google Trends API 通過 R 跟踪性能
已發表: 2021-12-15為什麼 Google 趨勢數據如此強大?
我們都知道,谷歌會捕獲大量關於我們的數據。 通過每天數十億次的搜索,谷歌可以比政府更了解我們的社會和民眾的情緒。 例如,搜索趨勢數據可以通過查看與特定症狀相關的搜索查詢的增加,在媒體宣布疾病爆發之前就識別出疾病爆發。 不出所料,已經進行了研究以按地區預測不斷上升的 COVID-19 病例。
這些天來,谷歌本質上是世界情緒晴雨表和谷歌搜索趨勢數據最好的東西? 免費。
為什麼使用 Google 趨勢 API?
Google 趨勢是許多數字營銷人員工具包的一個關鍵功能。 可以分析搜索查詢隨時間的流行度以顯示市場意識。 將這些數據與其他來源的數據疊加可以提供否則會被遺漏的洞察力。
該博客提供了這樣一個示例,展示瞭如何將Google 趨勢數據與網站的自然流量疊加在一起——這可用於了解 SEO 性能。 如果您的自然流量開始下滑,這是由於市場興趣下降還是因為您的熱門搜索查詢排名不高?
谷歌趨勢和谷歌分析都有可用的 R 包,對於那些對編程有基本了解的人來說非常容易使用。 對於 Google 趨勢,我們將使用 gtrendsR 包,然後對於 Google Analytics,我們將使用 googleAnalyticsR 包,我們在上一篇文章中介紹過 - 將 Google Analytics API 與 R 結合使用。提供的示例代碼應該可以直接複製/粘貼和調整以滿足您的需求。
我們將使用一家銷售軟飲料的公司的示例,該公司希望了解他們銷售的產品隨時間推移的受歡迎程度。
Google Trends API – 如何提取搜索趨勢數據
這些數據最容易獲得,主要是因為不需要 API 密鑰。 首先,只需使用install.packages(“gtrendsR”)安裝包並使用library(gtrendsR)加載庫。 選擇所需的關鍵字可能很困難——我們建議您查看 Search Console 中按展示次數排序的頂級非品牌字詞。
# Load Libraries and Set Up Query Conditions # library(gtrendsR) keywords = c(“Soft drinks”, “Fizzy drinks”, “Pepsi”, “Lemonade”, “Fanta”) country = c('GB') time = (“2020-01-01 2021-10-31”) channel = 'web' # Run Query # data1 = gtrends(keywords, gprop = channel, geo = country, time = time) data_trend = data$interest_over_time如上面的代碼所示,您的請求中可以包含額外的變量:gprop、geo 和 time:
- Gprop 代表 Google 的屬性,即新聞、圖像和 YouTube——但是如果留空,則默認為 web。
- Geo 根據其兩位數的 ISO 代碼代表國家 - 但如果留空,則默認為全球。
- 時間表示請求的開始和結束日期。
gtrendsR 包一次限制為 5 個關鍵字,因此如果您想運行多個查詢,則可以使用如下所示的循環。 如果您正在評估一組搜索詞的整體流行度,我們建議您這樣做,因為此循環會在匯總每個關鍵字的每週更改之前分別運行每個關鍵字。 因此,一個人的流行度變化對另一個人的流行度沒有直接影響。
list1 = list() for (i in 1:length(keywords)){ trends = gtrends(keywords[i], gprop =channel,geo=country, time = time ) time_trend=trends$interest_over_time time_trend$keyword <- keywords[i] list1 [[i]] <- time_trend } data1 <- do.call("rbind", list1)需要注意的一件事是,谷歌趨勢提供每週數據,但每週從星期日開始。 因此,我們需要從周日開始按週匯總我們的 Google Analytics 數據——有一個有用的軟件包可以幫助我們做到這一點,我們將在後面介紹。

Google Analytics API – 如何拉動自然流量
我們建議閱讀我們之前的文章以更詳細地了解 googleAnalyticsR 包。 本文向您展示瞭如何將自然流量過濾到特定目標網頁。 如果您的公司在多個市場中,這可能會很有用。 即,如果您銷售碳酸飲料和巧克力棒,那麼在評估碳酸飲料的市場興趣時,您不希望將有機流量包括到巧克力棒頁面。
否則,下面的代碼允許您使用此包和 R 訪問您網站的所有自然流量。
我們建議一次運行每一行代碼,以便您輕鬆發現任何錯誤。
有關有助於腳本自動化的更“專業”的身份驗證方式,請查看此更詳細的說明。
下面的代碼每天都會吸引自然流量。 然後使用 floor_date 函數從周日開始按週聚合流量,以匹配 Search Console 數據(僅限於週日至週六的每週數據)。
# Load Libraries and Setup Query - make sure to set your View ID # library(googleAnalyticsR) library(dplyr) library(lubridate) ga_auth() set_view_ID <- #ENTER_VIEW_ID# organicTraffic <- dim_filter("channelGrouping", "EXACT", "Organic Search") organicFilter <- filter_clause_ga4(list(organicTraffic),”AND” ) # Run Query, Aggregate Daily Traffic to Weekly Traffic and Rename Columns # data2 <- google_analytics (set_view_ID, date_range = c(“2021-01-01”, ”2021-10-31”), metrics = "sessions", dimensions = "date", dim_filters = organicFilter, anti_sample = TRUE) data2$week <- floor_date(as.Date(data2$date, "%Y-%m-%d"), unit="week") data2 <- data2 %>% group_by(week) %>% summarise(sum(sessions)) names(data2)[1] <- "week" names(data2)[2] <- "sessions" # Merge Search Trends and Organic Traffic # merged_data <- merge(data1, data2)合併數據集並獲得洞察力
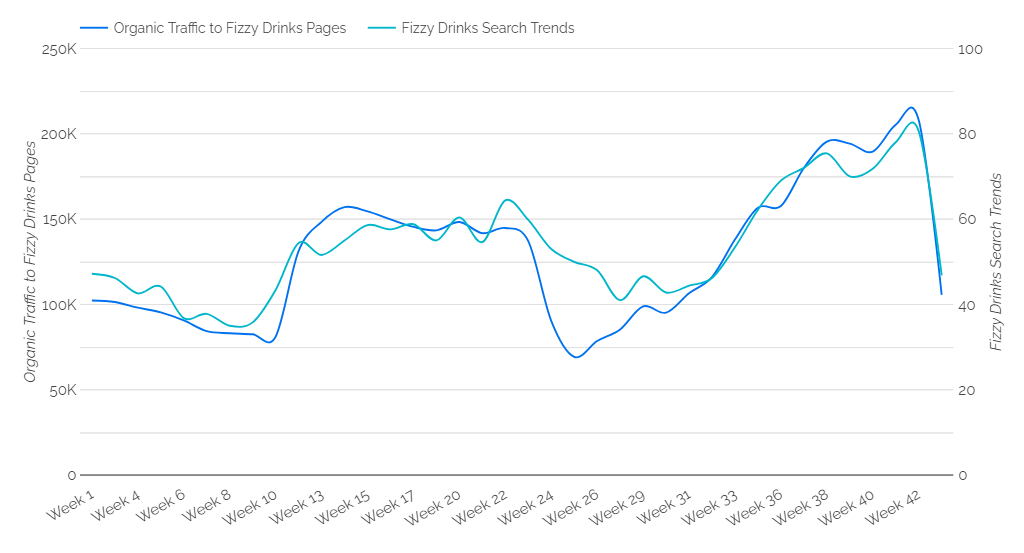
在上面的最後一行代碼中,我們將數據集合併為 3 列:週開始日期、自然會話和相對搜索趨勢。 現在,這兩個數據集可以輕鬆地疊加在圖表中進行分析(例如,請參見下圖)。
搜索趨勢數據的聚合意味著我們可以看到隨著時間的推移所有搜索查詢的相對受歡迎程度,從而深入了解市場興趣的變化。
我們建議使用左右軸隨時間在圖表上疊加搜索趨勢數據和自然流量,以評估趨勢。 您可能會看到它們之間存在正相關關係,流量隨著搜索受歡迎程度的增加而增加。 可能存在線條與另一條線偏離的點,表明關鍵字排名發生了變化。 您是否在 Google 的搜索結果頁面上上下移動?
下圖顯示了示例數據,左軸為自然流量,右軸為搜索趨勢。 在下圖中,第 24 週的兩個指標之間存在明顯差異。儘管自然流量顯著下降,但搜索趨勢保持相對一致,表明關鍵詞排名下降到驅動大量流量的頁面 - 這些排名隨後到第 33 週開始。
這只是 Search Console API 的一個用例。 它在營銷領域還可以發揮許多其他作用,例如生成可用於反應性數字公關故事的實時搜索詞趨勢報告,或觀察競爭對手的品牌知名度。
渴望了解更多? 聯繫我們與我們高級網絡分析團隊中的某個人交談!