
使用 Google Analytics 和 Google Trends API 通过 R 跟踪性能
已发表: 2021-12-15为什么 Google 趋势数据如此强大?
我们都知道,谷歌会捕获大量关于我们的数据。 通过每天数十亿次的搜索,谷歌可以比政府更了解我们的社会和民众的情绪。 例如,搜索趋势数据可以通过查看与特定症状相关的搜索查询的增加,在媒体宣布疾病爆发之前就识别出疾病爆发。 不出所料,已经进行了研究以按地区预测不断上升的 COVID-19 病例。
这些天来,谷歌本质上是世界情绪晴雨表和谷歌搜索趋势数据最好的东西? 免费。
为什么使用 Google 趋势 API?
Google 趋势是许多数字营销人员工具包的一个关键功能。 可以分析搜索查询随时间的流行度以显示市场意识。 将这些数据与其他来源的数据叠加可以提供否则会被遗漏的洞察力。
该博客提供了这样一个示例,展示了如何将Google 趋势数据与网站的自然流量叠加在一起——这可用于了解 SEO 性能。 如果您的自然流量开始下滑,这是由于市场兴趣下降还是因为您的热门搜索查询排名不高?
谷歌趋势和谷歌分析都有可用的 R 包,对于那些对编程有基本了解的人来说非常容易使用。 对于 Google 趋势,我们将使用 gtrendsR 包,然后对于 Google Analytics,我们将使用 googleAnalyticsR 包,我们在上一篇文章中介绍过 - 将 Google Analytics API 与 R 结合使用。提供的示例代码应该可以直接复制/粘贴和调整以满足您的需求。
我们将使用一家销售软饮料的公司的示例,该公司希望了解他们销售的产品随时间推移的受欢迎程度。
Google Trends API – 如何提取搜索趋势数据
这些数据最容易获得,主要是因为不需要 API 密钥。 首先,只需使用install.packages(“gtrendsR”)安装包并使用library(gtrendsR)加载库。 选择所需的关键字可能很困难——我们建议您查看 Search Console 中按展示次数排序的顶级非品牌字词。
# Load Libraries and Set Up Query Conditions # library(gtrendsR) keywords = c(“Soft drinks”, “Fizzy drinks”, “Pepsi”, “Lemonade”, “Fanta”) country = c('GB') time = (“2020-01-01 2021-10-31”) channel = 'web' # Run Query # data1 = gtrends(keywords, gprop = channel, geo = country, time = time) data_trend = data$interest_over_time如上面的代码所示,您的请求中可以包含额外的变量:gprop、geo 和 time:
- Gprop 代表 Google 的属性,即新闻、图像和 YouTube——但是如果留空,则默认为 web。
- Geo 根据其两位数的 ISO 代码代表国家 - 但如果留空,则默认为全球。
- 时间表示请求的开始和结束日期。
gtrendsR 包一次限制为 5 个关键字,因此如果您想运行多个查询,则可以使用如下所示的循环。 如果您正在评估一组搜索词的整体流行度,我们建议您这样做,因为此循环会在汇总每个关键字的每周更改之前分别运行每个关键字。 因此,一个人的流行度变化对另一个人的流行度没有直接影响。
list1 = list() for (i in 1:length(keywords)){ trends = gtrends(keywords[i], gprop =channel,geo=country, time = time ) time_trend=trends$interest_over_time time_trend$keyword <- keywords[i] list1 [[i]] <- time_trend } data1 <- do.call("rbind", list1)需要注意的一件事是,谷歌趋势提供每周数据,但每周从星期日开始。 因此,我们需要从周日开始按周汇总我们的 Google Analytics 数据——有一个有用的软件包可以帮助我们做到这一点,我们将在后面介绍。

Google Analytics API – 如何拉动自然流量
我们建议阅读我们之前的文章以更详细地了解 googleAnalyticsR 包。 本文向您展示了如何将自然流量过滤到特定目标网页。 如果您的公司在多个市场中,这可能会很有用。 即,如果您销售碳酸饮料和巧克力棒,那么在评估碳酸饮料的市场兴趣时,您不希望将有机流量包括到巧克力棒页面。
否则,下面的代码允许您使用此包和 R 访问您网站的所有自然流量。
我们建议一次运行每一行代码,以便您轻松发现任何错误。
有关有助于脚本自动化的更“专业”的身份验证方式,请查看此更详细的说明。
下面的代码每天都会吸引自然流量。 然后使用 floor_date 函数从周日开始按周聚合流量,以匹配 Search Console 数据(仅限于周日至周六的每周数据)。
# Load Libraries and Setup Query - make sure to set your View ID # library(googleAnalyticsR) library(dplyr) library(lubridate) ga_auth() set_view_ID <- #ENTER_VIEW_ID# organicTraffic <- dim_filter("channelGrouping", "EXACT", "Organic Search") organicFilter <- filter_clause_ga4(list(organicTraffic),”AND” ) # Run Query, Aggregate Daily Traffic to Weekly Traffic and Rename Columns # data2 <- google_analytics (set_view_ID, date_range = c(“2021-01-01”, ”2021-10-31”), metrics = "sessions", dimensions = "date", dim_filters = organicFilter, anti_sample = TRUE) data2$week <- floor_date(as.Date(data2$date, "%Y-%m-%d"), unit="week") data2 <- data2 %>% group_by(week) %>% summarise(sum(sessions)) names(data2)[1] <- "week" names(data2)[2] <- "sessions" # Merge Search Trends and Organic Traffic # merged_data <- merge(data1, data2)合并数据集并获得洞察力
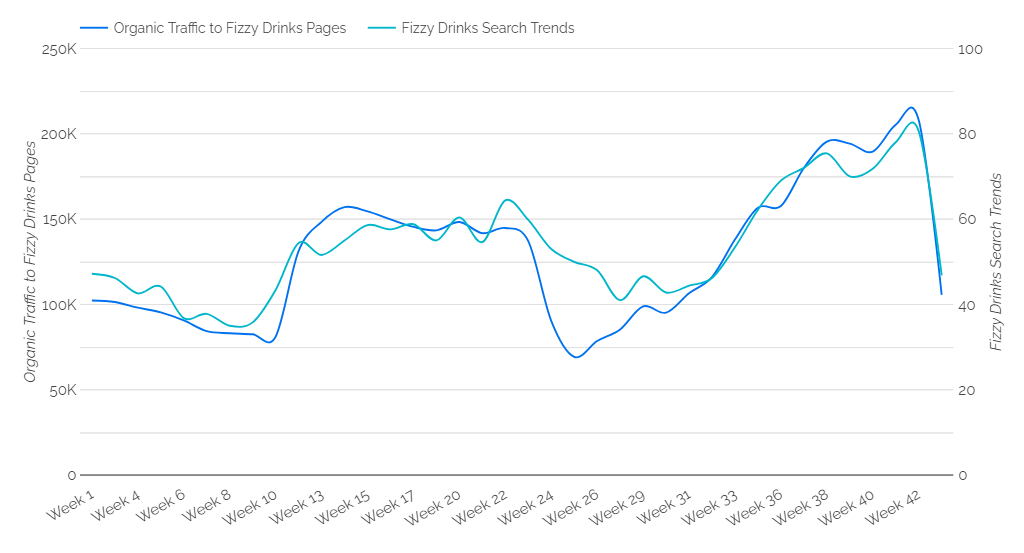
在上面的最后一行代码中,我们将数据集合并为 3 列:周开始日期、自然会话和相对搜索趋势。 现在,这两个数据集可以轻松地叠加在图表中进行分析(例如,请参见下图)。
搜索趋势数据的聚合意味着我们可以看到随着时间的推移所有搜索查询的相对受欢迎程度,从而深入了解市场兴趣的变化。
我们建议使用左右轴随时间在图表上叠加搜索趋势数据和自然流量,以评估趋势。 您可能会看到它们之间存在正相关关系,流量随着搜索受欢迎程度的增加而增加。 可能存在线条与另一条线偏离的点,表明关键字排名发生了变化。 您是否在 Google 的搜索结果页面上上下移动?
下图显示了示例数据,左轴为自然流量,右轴为搜索趋势。 在下图中,第 24 周的两个指标之间存在明显差异。尽管自然流量显着下降,但搜索趋势保持相对一致,表明关键词排名下降到驱动大量流量的页面 - 这些排名随后到第 33 周开始。
这只是 Search Console API 的一个用例。 它在营销领域还可以发挥许多其他作用,例如生成可用于反应性数字公关故事的实时搜索词趋势报告,或观察竞争对手的品牌知名度。
渴望了解更多? 联系我们与我们高级网络分析团队中的某个人交谈!