
網路抓取的未來:預測與新興技術
已發表: 2024-03-22隨著技術的進步和資料使用政策的變化塑造了其發展軌跡,網路抓取的未來正處於一個令人興奮的時刻。 隨著企業和研究人員越來越依賴網路抓取資料來獲取競爭情報、市場研究和自動化,網路抓取的工具和方法正在不斷發展,以便更有效、更合乎道德地滿足這些需求。 以下是一些可能影響網路抓取未來的預測和新興技術:
人工智慧和機器學習的進一步融合
將人工智慧 (AI) 和機器學習 (ML) 整合到網路抓取技術中,標誌著我們從網路提取資料的方式發生了變革。 這些先進技術不僅有望在效率和有效性方面改進流程,而且還為數據分析和應用開闢了以前不可想像的新前景。 讓我們更深入探討人工智慧和機器學習如何徹底改變網頁抓取:
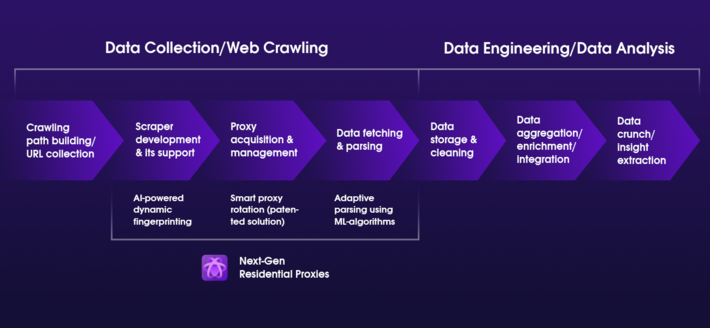
資料來源:https://www.datasciencecentral.com/how-to-overcome-web-scraping-challenges-with-ai-amp-ml-technology/
人工智慧和機器學習演算法可以透過理解網頁內容的語義來顯著提高資料提取的精確度。 例如,經過自然語言處理(NLP)訓練的人工智慧模型可以識別網頁上文字背後的上下文和含義,從而提取更相關和更精確的資訊。 這對於市場研究或競爭分析等領域尤其有利,因為這些領域數據的品質和相關性直接影響所得出的見解。
自然語言處理 (NLP) 的進步
自然語言處理 (NLP) 的進步正在迅速改變資料擷取的格局,特別是從構成網路重要組成部分的非結構化 Web 內容中提取資料。 NLP是人工智慧的一個分支,專注於電腦與人類透過自然語言互動。 它與網頁抓取技術的整合不僅是一種增強,而且是一種增強。 這是一場革命,擴大了透過數據提取所能實現的範圍。 讓我們進一步探討這種整合的深度及其影響。
衡量大眾對產品、服務或品牌的情緒的能力對企業來說是無價的。 NLP 的進步使情緒分析變得更加複雜,可以對客戶回饋和社群媒體提及進行細微分析。 這不僅強調了情緒是正面的還是負面的;也強調了情緒是正面的還是負面的。 它深入研究了這些情緒的強度以及它們所涉及的具體方面。 此類詳細的分析可以指導產品開發、行銷策略和客戶服務改進。
更穩健的防刮措施及對策
隨著網頁抓取變得越來越普遍,網站可能會實施更複雜的反抓取措施來保護其資料。 這可能包括更複雜的驗證碼、偵測機器人的行為分析以及動態資料渲染技術。 作為回應,抓取技術需要發展以克服這些障礙,可能利用人工智慧來更接近地模仿人類瀏覽模式或採用更複雜的驗證碼解決方法。
道德抓取和遵守法律標準
隨著人們對隱私和資料保護的日益關注,道德的網路抓取實踐將變得更加重要。 這包括遵守 robots.txt 檔案、尊重版權法以及遵守 GDPR 等國際資料保護法規。 優先考慮道德抓取和資料隱私的工具和平台將受到重視,我們可能會看到道德網路抓取的標準化框架和指南的發展。
更加重視即時資料擷取
跨產業數位轉型的加速迎來了一個時代,敏捷性和速度不僅有價值,而且具有價值。 它們是最重要的。 在這種背景下,對即時資料擷取的重視代表了網頁抓取技術的關鍵演變,旨在適應當今快速變化的市場所需的決策節奏。 這種向即時數據轉變的影響是深遠的,影響著從金融交易到客戶服務的方方面面,並為重新定義競爭優勢的創新奠定了基礎。
在金融領域,即時資料擷取不僅有益,而且有益。 這是必要的。 幾秒鐘的差異可能會顯著影響交易決策和結果。 可以即時提供財經新聞、股票價格和市場情緒的先進網頁抓取工具正在成為交易員和金融分析師不可或缺的資產。
零售業越來越多地採用動態定價模型,根據市場需求、競爭對手定價和庫存水準調整價格。 即時數據提取使零售商能夠持續監控這些變數並立即調整其定價策略。 這種能力可以顯著提高競爭力,尤其是在消費者之間進行價格比較的電子商務領域。 零售商利用即時數據可以優化定價,以提高銷售和利潤率,同時保持市場競爭力。
基於雲端的抓取服務
隨著數位經濟的不斷擴張,對數據驅動決策的需求日益加劇。 這導致人們越來越依賴網路抓取作為收集分析、市場研究和競爭情報所需的大量數據的方法。 基於雲端的網路抓取服務處於這一趨勢的前沿,透過提供強大、可擴展且用戶友好的解決方案,徹底改變了組織處理資料提取的方式。 以下是對基於雲端的抓取服務及其潛在影響的更深入的了解:
基於雲端的抓取服務的優勢
1. 可擴展性:基於雲端的服務最顯著的優勢之一是它們能夠輕鬆擴展。 無論您是想從幾頁還是數百萬頁中抓取數據,這些平台都可以動態分配資源來滿足需求,確保高效的數據提取,而無需手動幹預。
2. 成本效益:透過利用雲端中的共享資源,這些服務可以提供有競爭力的定價模型,使各種規模的企業都可以存取網路抓取。 這消除了對硬體和軟體進行大量前期投資的需要,從而降低了使用網路抓取技術的進入障礙。
3. 維護和升級:基於雲端的服務處理維護和更新的各個方面,確保抓取技術與最新的網路標準和安全實踐保持同步。 這減輕了用戶的巨大負擔,使他們能夠專注於分析數據,而不是擔心抓取的技術細節。
4. 進階功能:這些平台通常配備進階功能,可提高網頁抓取操作的效率和效能。 自動 IP 輪調有助於透過從不同的 IP 位址發出請求來逃避反抓取措施,而高速資料處理可確保快速提取和分析大量資料。
5. 整合能力:許多基於雲端的抓取服務提供 API 以及與流行資料分析工具和平台的整合。 這允許無縫的工作流程,提取的數據可以自動輸入到分析模型、儀表板或資料庫中進行即時分析。
無瀏覽器抓取技術
新興技術可能會提供更有效的方法來模擬瀏覽器環境,甚至完全不需要瀏覽器來執行抓取任務。 這可以顯著減少網路抓取操作所需的資源,從而實現更快、更有效率的資料收集。

結論
網路抓取的未來既充滿希望又充滿挑戰。 隨著科技的進步,取得公開資料與尊重隱私和法律界線之間的平衡將至關重要。 人工智慧、機器學習和自然語言處理的創新,加上對道德抓取實踐的承諾,將塑造網路抓取工具的發展,使資料對全球企業和研究人員來說更容易存取和更有價值。 在這個不斷發展的環境中,隨時了解技術和監管變化將是充分利用網路抓取潛力的關鍵。
經常問的問題
什麼是網路抓取技術?
網路抓取技術是指用於從網站中提取資料的方法、工具和軟體。 此過程涉及以程式設計方式存取網頁、解析 HTML 程式碼,然後提取文字、圖像、連結和元資料等有用資訊。 提取的資料可以以結構化格式儲存到本機檔案或資料庫中,以供分析、報告或進一步處理。 網路抓取廣泛應用於各個產業,用於執行市場研究、競爭分析、價格監控、潛在客戶開發和內容聚合等任務。
網頁抓取技術的關鍵組成部分:
- HTTP 請求:網頁抓取的核心是以程式設計方式傳送 HTTP 請求以檢索網頁的能力。 命令列中的curl等工具、Python中的requests等函式庫或.NET中的HttpClient通常用於此目的。
- HTML 解析:取得網頁的 HTML 內容後,需要解析以擷取所需的資料。 HTML 解析庫(例如 Python 中的 BeautifulSoup 和 lxml 或 Java 中的 Jsoup)提供了導航 HTML 文件結構並根據標籤、類別或 ID 提取資料的功能。
- Web 瀏覽器自動化:對於嚴重依賴 JavaScript 載入內容的動態網站,需要使用自動化 Web 瀏覽器的工具。 這些工具(例如 Selenium、Puppeteer 和 Playwright)模仿人類與瀏覽器的交互,允許執行存取內容所需的 JavaScript 和 AJAX 呼叫。
- 資料儲存:擷取的資料通常儲存在資料庫中或以 CSV、JSON 或 Excel 等格式寫入文件,以便進一步分析或處理。
- 資料清理和格式化:提取的資料通常需要清理和轉換以刪除不必要的字元、修正格式或轉換資料類型。 此步驟對於確保數據準確且可用至關重要。
使用哪種工具進行網頁抓取?
有各種工具和函式庫可用於網頁抓取,以滿足不同程度的專業知識、程式語言和特定需求。 以下是一些用於網頁抓取的流行工具的概述:
美麗的湯
- 語言:Python
- 用途:最適合簡單的 HTML 和 XML 解析以及從靜態網站提取資料。
- 特點:對於初學者來說很容易使用,與Python的requests庫結合使用來獲取網頁內容時功能強大。
刮痧
- 語言:Python
- 用途:非常適合建立可擴展的網路爬蟲和抓取複雜的網站。
- 特點:提供完整的網頁抓取和爬行框架,支援專案管道、資料匯出和處理不同場景的中間件。
碳粉匣
- 語言:支援多種語言,包括 Python、Java、C#、Ruby 和 JavaScript。
- 用途:最初設計用於自動化 Web 瀏覽器以進行測試,它也用於抓取透過 JavaScript 呈現的動態內容。
- 功能:可以控制網頁瀏覽器模仿人類瀏覽行為,從而可以從需要登入或互動的網站上抓取資料。
傀儡師
- 語言:JavaScript (Node.js)
- 用途:適合抓取嚴重依賴 JavaScript 的動態網站和單頁應用程式。
- 功能:提供進階 API 透過 DevTools 協定控制 Chrome 或 Chromium,允許執行渲染 JavaScript、截取螢幕截圖和產生網頁 PDF 等任務。
劇作家
- 語言:Node.js、Python、C# 和 Java
- 用途:與 Puppeteer 類似,但設計為支援多種瀏覽器(Chrome、Firefox 和 WebKit)。
- 功能:自動執行瀏覽器操作以進行網頁抓取、跨瀏覽器測試以及擷取螢幕截圖和影片。
凱裡歐
- 語言:JavaScript (Node.js)
- 用途:最適合伺服器端 DOM 操作,類似 jQuery,可以快速有效率地抓取靜態網站。
- 功能:解析標記並提供用於遍歷/操作結果資料結構的 API; 對於靜態內容,比 Puppeteer 更輕。
章魚分析
- 語言:N/A(基於 GUI 的工具)
- 用途:適合非程式設計師或那些喜歡視覺化介面而不是編寫程式碼的人。
- 特點:點擊式介面,用於選擇要提取的數據,處理靜態和動態網站。 它提供用於運行爬蟲的雲端服務。
解析中心
- 語言:N/A(基於 GUI 的工具)
- 用途:專為沒有程式設計知識的使用者而設計,可以使用強大的視覺化工具抓取網站。
- 特點:支援AJAX和JavaScript密集型網站,具有使用者友善的介面,用於選擇資料點和匯出資料。
網頁抓取有哪些不同的方法?
網路抓取包含從網站提取資料的各種方法,每種方法適合不同類型的網路內容和使用者需求。 以下是一些常用的網頁抓取方法的概述:
HTTP 請求
此方法涉及發送 HTTP 請求以直接檢索網頁的 HTML 內容。 它對於內容不依賴 JavaScript 執行的靜態網站最有效。 Python 中的 requests 和 .NET 中的 HttpClient 等函式庫通常用於發出 HTTP 請求。
優點:靜態內容簡單、快速。
缺點:對於透過 JavaScript 載入的動態內容無效。
HTML解析
取得 HTML 內容後,Beautiful Soup (Python)、Cheerio (Node.js) 或 Jsoup (Java) 等解析庫就可以導覽 HTML DOM 樹並擷取特定資料。 此方法非常適合在 JavaScript 執行後從靜態頁面或 HTML 來源中提取資料。
優點:靈活、精確地擷取資料元素。
缺點:需了解網頁結構。
瀏覽器自動化
Selenium、Puppeteer 和 Playwright 等工具可以自動化真正的 Web 瀏覽器,讓您可以抓取需要 JavaScript 執行或與頁面互動(例如,點擊按鈕、填寫表單)的動態內容。 這些工具可以模仿人類的瀏覽行為,使其能夠有效執行複雜的抓取任務。
優點:可以處理動態的、大量 JavaScript 的網站。
缺點:比直接 HTTP 請求更耗費資源且速度較慢。
API請求
許多網站透過 API 動態載入資料。 透過檢查網路流量(使用瀏覽器 DevTools 中的「網路」標籤等工具),您可以識別 API 端點並直接要求資料。 此方法非常高效,並且通常以 JSON 等結構化格式傳回資料。
優點:快速高效,提供結構化資料。
缺點:需要了解 API 端點,並且可能涉及身份驗證。
無頭瀏覽器
無頭瀏覽器就像普通瀏覽器一樣,但沒有圖形使用者介面。 Puppeteer 和 Playwright 等工具可以在無頭模式下執行,在背景執行 JavaScript 並渲染網頁。 此方法對於動態內容的自動化測試和抓取非常有用。
優點:動態內容的完整呈現,包括 JavaScript 執行。
缺點:與瀏覽器自動化類似,它比其他方法更消耗資源。
網頁抓取框架
Scrapy (Python) 等框架為網頁抓取提供了成熟的環境,提供了提取資料、追蹤連結和處理錯誤的功能。 這些框架旨在建立可擴展的網路爬蟲並同時管理多個抓取任務。
優點:具有適用於複雜抓取專案的內建功能的綜合解決方案。
缺點:對於初學者來說可能有更陡峭的學習曲線。
光學字元辨識 (OCR)
為了從圖像或掃描文件中抓取數據,Tesseract 等 OCR 技術可以將文字的視覺表示形式轉換為機器可讀的文字。 此方法對於從 PDF、圖像或驗證碼中提取資料特別有用。
優點:可以從圖像和掃描文件中提取文字。
缺點:低品質影像或複雜佈局可能會導致不準確。