
Masa Depan Web Scraping: Prediksi dan Teknologi yang Muncul
Diterbitkan: 2024-03-22Masa depan web scraping berada pada titik yang menarik, dengan kemajuan teknologi dan perubahan kebijakan penggunaan data yang membentuk lintasannya. Ketika bisnis dan peneliti semakin bergantung pada data web scraping untuk intelijen kompetitif, riset pasar, dan otomatisasi, alat dan metodologi web scraping berkembang untuk memenuhi tuntutan ini dengan lebih efisien dan etis. Berikut adalah beberapa prediksi dan teknologi baru yang mungkin mempengaruhi masa depan web scraping:
Peningkatan Integrasi AI dan Pembelajaran Mesin
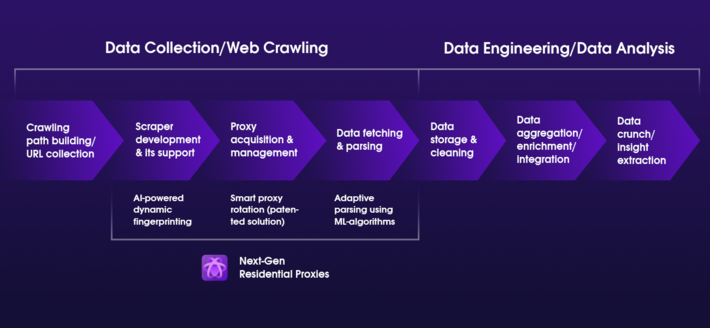
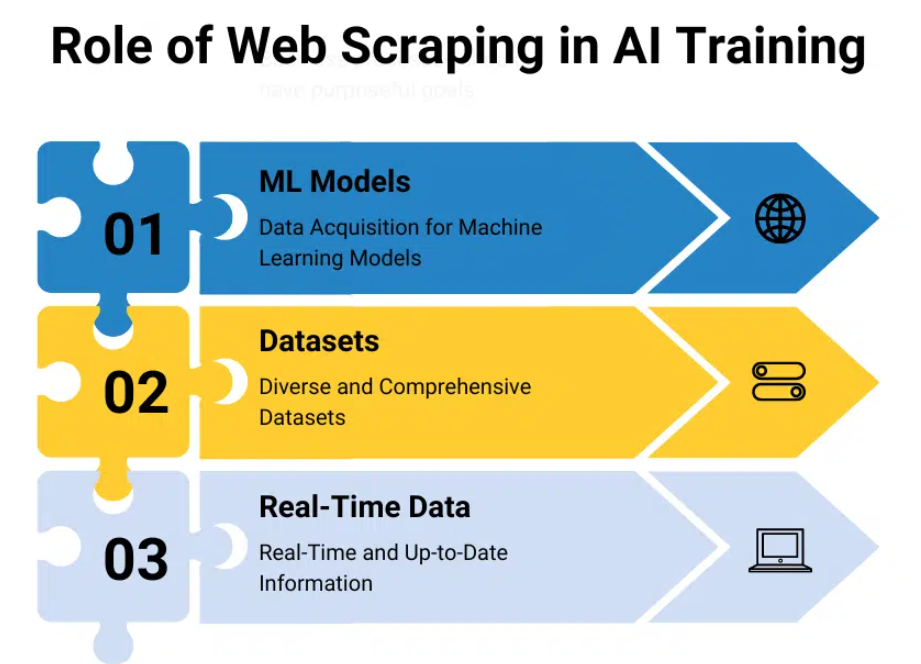
Integrasi Kecerdasan Buatan (AI) dan Pembelajaran Mesin (ML) ke dalam teknologi pengikisan web menandai perubahan transformatif dalam cara kita mendekati ekstraksi data dari web. Teknologi canggih ini tidak hanya menjanjikan penyempurnaan proses dalam hal efisiensi dan efektivitas namun juga membuka pandangan baru untuk analisis data dan penerapan yang sebelumnya tidak terpikirkan. Mari pelajari lebih dalam bagaimana AI dan ML siap merevolusi web scraping:
Sumber: https://www.datasciencecentral.com/how-to-overcome-web-scraping-challenges-with-ai-amp-ml-technology/
Algoritme AI dan ML dapat meningkatkan presisi ekstraksi data secara signifikan dengan memahami semantik konten web. Misalnya, model AI yang dilatih dalam Natural Language Processing (NLP) dapat memahami konteks dan makna di balik teks pada halaman web, sehingga memungkinkan ekstraksi informasi yang lebih relevan dan tepat. Hal ini khususnya bermanfaat dalam sektor seperti riset pasar atau analisis persaingan, di mana kualitas dan relevansi data berdampak langsung pada wawasan yang diperoleh.
Kemajuan dalam Pemrosesan Bahasa Alami (NLP)
Kemajuan dalam Pemrosesan Bahasa Alami (NLP) dengan cepat mengubah lanskap ekstraksi data, terutama dari konten web tidak terstruktur yang merupakan bagian penting dari internet. NLP, salah satu cabang kecerdasan buatan, berfokus pada interaksi antara komputer dan manusia melalui bahasa alami. Integrasinya ke dalam teknologi web scraping bukan sekadar peningkatan; ini adalah revolusi yang memperluas cakrawala tentang apa yang dapat dicapai melalui ekstraksi data. Mari kita telusuri lebih dalam integrasi ini dan implikasinya.
Kemampuan untuk mengukur sentimen masyarakat terhadap produk, layanan, atau merek sangat berharga bagi bisnis. Kemajuan NLP telah membuat analisis sentimen menjadi lebih canggih, memungkinkan analisis mendalam atas umpan balik pelanggan dan sebutan di media sosial. Hal ini tidak hanya menyoroti apakah sentimen itu positif atau negatif; ini menyelidiki intensitas sentimen-sentimen ini dan aspek-aspek spesifik yang terkait dengannya. Analisis terperinci tersebut dapat memandu pengembangan produk, strategi pemasaran, dan peningkatan layanan pelanggan.
Tindakan dan Penanggulangan Anti Goresan yang Lebih Kuat
Ketika web scraping menjadi lebih umum, situs web cenderung menerapkan tindakan anti-scraping yang lebih canggih untuk melindungi data mereka. Hal ini dapat mencakup CAPTCHA yang lebih kompleks, analisis perilaku untuk mendeteksi bot, dan teknik rendering data dinamis. Sebagai responnya, teknologi scraping perlu berevolusi untuk mengatasi hambatan ini, mungkin memanfaatkan AI untuk meniru pola penjelajahan manusia secara lebih dekat atau mengadopsi metode penyelesaian CAPTCHA yang lebih canggih.
Pengikisan Etis dan Kepatuhan terhadap Standar Hukum
Dengan meningkatnya kekhawatiran terhadap privasi dan perlindungan data, praktik web scraping yang etis akan menjadi semakin penting. Hal ini termasuk mematuhi file robots.txt, menghormati undang-undang hak cipta, dan mematuhi peraturan perlindungan data internasional seperti GDPR. Alat dan platform yang memprioritaskan pengikisan etis dan privasi data akan semakin menonjol, dan kita mungkin melihat pengembangan kerangka kerja dan pedoman standar untuk pengikisan web yang etis.
Penekanan Lebih Besar pada Ekstraksi Data Real-time
Percepatan transformasi digital di berbagai industri telah mengantarkan kita pada era di mana kelincahan dan kecepatan tidak hanya penting; mereka adalah yang terpenting. Dalam konteks ini, penekanan pada ekstraksi data real-time mewakili evolusi penting dalam teknologi web scraping, yang bertujuan untuk menyesuaikan kecepatan pengambilan keputusan yang diperlukan di pasar yang bergerak cepat saat ini. Implikasi dari pergeseran menuju data real-time ini sangat besar, berdampak pada segala hal mulai dari perdagangan finansial hingga layanan pelanggan, dan menyiapkan landasan bagi inovasi yang dapat mendefinisikan kembali keunggulan kompetitif.
Di sektor keuangan, ekstraksi data real-time tidak hanya bermanfaat; itu penting. Perbedaan beberapa detik dapat berdampak signifikan terhadap keputusan dan hasil perdagangan. Alat pengikis web canggih yang dapat menyampaikan berita keuangan, harga saham, dan sentimen pasar secara real-time menjadi aset yang sangat diperlukan bagi para pedagang dan analis keuangan.
Sektor ritel semakin banyak mengadopsi model penetapan harga dinamis yang menyesuaikan harga berdasarkan permintaan pasar, harga pesaing, dan tingkat inventaris. Ekstraksi data real-time memungkinkan pengecer memantau variabel-variabel ini secara terus-menerus dan menyesuaikan strategi harga mereka secara instan. Kemampuan ini dapat meningkatkan daya saing secara signifikan, terutama dalam e-commerce, dimana perbandingan harga merupakan hal yang biasa di kalangan konsumen. Pengecer yang memanfaatkan data real-time dapat mengoptimalkan harga untuk meningkatkan volume penjualan dan margin keuntungan sekaligus mempertahankan daya saing pasar.
Layanan Pengikisan Berbasis Cloud
Seiring dengan berkembangnya ekonomi digital, permintaan akan pengambilan keputusan berbasis data semakin meningkat. Hal ini menyebabkan meningkatnya ketergantungan pada web scraping sebagai metode untuk mengumpulkan sejumlah besar data yang diperlukan untuk analisis, riset pasar, dan intelijen kompetitif. Layanan web scraping berbasis cloud berada di garis depan tren ini, merevolusi cara organisasi mendekati ekstraksi data dengan menawarkan solusi yang kuat, terukur, dan ramah pengguna. Berikut ini pandangan lebih mendalam tentang dunia layanan scraping berbasis cloud dan potensi dampaknya:
Keuntungan Layanan Scraping Berbasis Cloud
1. Skalabilitas : Salah satu keuntungan paling signifikan dari layanan berbasis cloud adalah kemampuannya untuk melakukan penskalaan dengan mudah. Baik Anda ingin mengambil data dari beberapa halaman atau jutaan, platform ini dapat secara dinamis mengalokasikan sumber daya untuk memenuhi permintaan, memastikan ekstraksi data yang efisien tanpa memerlukan intervensi manual.
2. Efektivitas Biaya : Dengan memanfaatkan sumber daya bersama di cloud, layanan ini dapat menawarkan model harga kompetitif yang membuat web scraping dapat diakses oleh bisnis dari semua ukuran. Hal ini menghilangkan kebutuhan investasi awal yang besar pada perangkat keras dan perangkat lunak, sehingga mengurangi hambatan masuk dalam memanfaatkan teknologi web scraping.
3. Pemeliharaan dan Peningkatan : Layanan berbasis cloud menangani semua aspek pemeliharaan dan pembaruan, memastikan bahwa teknologi scraping tetap mengikuti standar web dan praktik keamanan terkini. Hal ini meringankan beban yang signifikan bagi pengguna, memungkinkan mereka untuk fokus menganalisis data daripada mengkhawatirkan teknis pengikisan.
4. Fitur Lanjutan : Platform ini sering kali dilengkapi dengan fitur canggih yang meningkatkan efisiensi dan efektivitas operasi web scraping. Rotasi IP otomatis membantu menghindari tindakan anti-scraping dengan membuat permintaan dari alamat IP yang berbeda, sementara pemrosesan data berkecepatan tinggi memastikan bahwa data dalam jumlah besar dapat diekstraksi dan dianalisis dengan cepat.
5. Kemampuan Integrasi : Banyak layanan scraping berbasis cloud menawarkan API dan integrasi dengan alat dan platform analisis data populer. Hal ini memungkinkan alur kerja yang lancar di mana data yang diekstraksi dapat secara otomatis dimasukkan ke dalam model analitik, dasbor, atau database untuk analisis real-time.
Teknologi Pengikisan Tanpa Browser
Teknologi yang muncul mungkin menawarkan cara yang lebih efisien untuk menyimulasikan lingkungan browser atau bahkan mengabaikan kebutuhan browser sama sekali untuk melakukan tugas scraping. Hal ini dapat secara signifikan mengurangi sumber daya yang diperlukan untuk operasi web scraping, sehingga memungkinkan pengumpulan data lebih cepat dan efisien.

Kesimpulan
Masa depan web scraping menjanjikan sekaligus menantang. Seiring dengan kemajuan teknologi, keseimbangan antara mengakses data yang tersedia untuk umum dan menghormati privasi serta batasan hukum akan menjadi sangat penting. Inovasi dalam AI, ML, dan NLP, serta komitmen terhadap praktik pengikisan yang etis, akan membentuk pengembangan alat pengikisan web, menjadikan data lebih mudah diakses dan berharga bagi bisnis dan peneliti di seluruh dunia. Dalam lanskap yang terus berkembang ini, tetap mendapatkan informasi tentang perubahan teknologi dan peraturan akan menjadi kunci untuk memanfaatkan potensi penuh dari web scraping.
Pertanyaan yang Sering Diajukan
Apa itu teknologi web scraping?
Teknologi pengikisan web mengacu pada metode, alat, dan perangkat lunak yang digunakan untuk mengekstrak data dari situs web. Proses ini melibatkan akses terprogram ke halaman web, penguraian kode HTML, dan kemudian mengekstraksi informasi berguna seperti teks, gambar, tautan, dan metadata. Data yang diekstraksi dapat disimpan ke dalam file lokal atau database dalam format terstruktur untuk analisis, pelaporan, atau pemrosesan lebih lanjut. Pengikisan web banyak digunakan di berbagai industri untuk tugas-tugas seperti riset pasar, analisis kompetitif, pemantauan harga, perolehan prospek, dan agregasi konten.
Komponen Utama Teknologi Pengikisan Web:
- Permintaan HTTP : Inti dari web scraping adalah kemampuan mengirim permintaan HTTP secara terprogram untuk mengambil halaman web. Alat seperti curl di baris perintah, perpustakaan seperti permintaan di Python, atau HttpClient di .NET biasanya digunakan untuk tujuan ini.
- Parsing HTML : Setelah konten HTML halaman web diambil, konten tersebut perlu diurai untuk mengekstrak data yang diperlukan. Pustaka penguraian HTML seperti BeautifulSoup dan lxml dengan Python, atau Jsoup di Java, menyediakan fungsionalitas untuk menavigasi struktur dokumen HTML dan mengekstrak data berdasarkan tag, kelas, atau ID.
- Otomatisasi Peramban Web : Untuk situs web dinamis yang sangat bergantung pada JavaScript untuk memuat konten, alat yang mengotomatisasi peramban web digunakan. Alat-alat ini, seperti Selenium, Puppeteer, dan Playwright, meniru interaksi manusia dengan browser, memungkinkan eksekusi panggilan JavaScript dan AJAX yang diperlukan untuk mengakses konten.
- Penyimpanan Data : Data yang diekstraksi biasanya disimpan dalam database atau ditulis ke file dalam format seperti CSV, JSON, atau Excel untuk analisis atau pemrosesan lebih lanjut.
- Pembersihan dan Pemformatan Data : Data yang diekstraksi sering kali memerlukan pembersihan dan transformasi untuk menghapus karakter yang tidak perlu, memperbaiki pemformatan, atau mengonversi tipe data. Langkah ini penting untuk memastikan data akurat dan dapat digunakan.
Alat apa yang digunakan untuk web scraping?
Berbagai alat dan perpustakaan tersedia untuk web scraping, melayani berbagai tingkat keahlian, bahasa pemrograman, dan kebutuhan spesifik. Berikut ikhtisar beberapa alat populer yang digunakan untuk web scraping:
Sup yang Indah
- Bahasa : Python
- Penggunaan : Terbaik untuk penguraian HTML dan XML sederhana serta ekstraksi data dari situs web statis.
- Fitur : Mudah digunakan untuk pemula, kuat bila dikombinasikan dengan perpustakaan permintaan Python untuk mengambil konten web.
tergores
- Bahasa : Python
- Kegunaan : Ideal untuk membangun perayap web yang skalabel dan menyalin situs web yang kompleks.
- Fitur : Menyediakan kerangka kerja lengkap untuk pengikisan dan perayapan web, mendukung saluran item, ekspor data, dan middleware untuk menangani berbagai skenario.
Selenium
- Bahasa : Mendukung berbagai bahasa termasuk Python, Java, C#, Ruby, dan JavaScript.
- Penggunaan : Awalnya dirancang untuk mengotomatiskan browser web untuk tujuan pengujian, ini juga digunakan untuk menyalin konten dinamis yang dirender melalui JavaScript.
- Fitur : Dapat mengontrol browser web untuk meniru perilaku penelusuran manusia, sehingga memungkinkan untuk mengikis data dari situs web yang memerlukan login atau interaksi.
Dalang
- Bahasa : JavaScript (Node.js)
- Kegunaan : Cocok untuk menyalin situs web dinamis dan aplikasi satu halaman yang sangat bergantung pada JavaScript.
- Fitur : Menyediakan API tingkat tinggi untuk mengontrol Chrome atau Chromium melalui Protokol DevTools, memungkinkan tugas seperti merender JavaScript, mengambil tangkapan layar, dan membuat PDF halaman web.
Dramawan
- Bahasa : Node.js, Python, C#, dan Java
- Kegunaan : Mirip dengan Puppeteer tetapi dirancang untuk mendukung banyak browser (Chrome, Firefox, dan WebKit).
- Fitur : Mengotomatiskan tindakan browser untuk web scraping, pengujian di seluruh browser, dan mengambil tangkapan layar dan video.
ceria
- Bahasa : JavaScript (Node.js)
- Penggunaan : Terbaik untuk manipulasi DOM sisi server, mirip dengan jQuery, memungkinkan pengikisan situs web statis dengan cepat dan efisien.
- Fitur : Mengurai markup dan menyediakan API untuk melintasi/memanipulasi struktur data yang dihasilkan; lebih ringan dari Dalang untuk konten statis.
Gurita
- Bahasa : T/A (alat berbasis GUI)
- Penggunaan : Cocok untuk non-programmer atau mereka yang lebih menyukai antarmuka visual daripada menulis kode.
- Fitur : Antarmuka tunjuk-dan-klik untuk memilih data yang akan diekstraksi, menangani situs web statis dan dinamis. Ia menawarkan layanan cloud untuk menjalankan crawler.
ParseHub
- Bahasa : T/A (alat berbasis GUI)
- Penggunaan : Dirancang untuk pengguna tanpa pengetahuan pemrograman untuk mengikis situs web menggunakan alat visual yang kuat.
- Fitur : Mendukung situs web yang banyak menggunakan AJAX dan JavaScript, dengan antarmuka yang ramah pengguna untuk memilih titik data dan mengekspor data.
Apa saja metode berbeda yang digunakan untuk web scraping?
Pengikisan web mencakup berbagai metode untuk mengekstrak data dari situs web, masing-masing disesuaikan dengan jenis konten web dan kebutuhan pengguna yang berbeda. Berikut ikhtisar beberapa metode web scraping yang umum digunakan:
Permintaan HTTP
Metode ini melibatkan pengiriman permintaan HTTP untuk mengambil konten HTML halaman web secara langsung. Ini paling efektif untuk situs web statis yang kontennya tidak bergantung pada eksekusi JavaScript. Perpustakaan seperti permintaan dengan Python dan HttpClient di .NET populer untuk membuat permintaan HTTP.
Kelebihan : Sederhana dan cepat untuk konten statis.
Kekurangan : Tidak efektif untuk konten dinamis yang dimuat melalui JavaScript.
Penguraian HTML
Setelah Anda memiliki konten HTML, pustaka parsing seperti Beautiful Soup (Python), Cheerio (Node.js), atau Jsoup (Java) dapat menavigasi pohon DOM HTML dan mengekstrak data tertentu. Metode ini ideal untuk mengekstraksi data dari halaman statis atau sumber HTML setelah eksekusi JavaScript.
Kelebihan : Ekstraksi elemen data yang fleksibel dan tepat.
Kekurangan : Membutuhkan pemahaman tentang struktur halaman web.
Otomatisasi Peramban
Alat seperti Selenium, Puppeteer, dan Playwright mengotomatiskan browser web sebenarnya, memungkinkan Anda mengikis konten dinamis yang memerlukan eksekusi JavaScript atau interaksi dengan halaman (misalnya, mengklik tombol, mengisi formulir). Alat-alat ini dapat meniru perilaku penjelajahan manusia, menjadikannya kuat untuk tugas-tugas pengikisan yang rumit.
Kelebihan : Dapat menangani situs web dinamis dan banyak JavaScript.
Kekurangan : Lebih boros sumber daya dan lebih lambat dibandingkan permintaan HTTP langsung.
Permintaan API
Banyak situs web memuat data secara dinamis melalui API. Dengan memeriksa lalu lintas jaringan (menggunakan alat seperti tab Jaringan di DevTools browser), Anda dapat mengidentifikasi titik akhir API dan meminta data secara langsung. Metode ini efisien dan sering kali mengembalikan data dalam format terstruktur seperti JSON.
Kelebihan : Cepat dan efisien, menyediakan data terstruktur.
Kontra : Memerlukan pemahaman tentang titik akhir API dan mungkin melibatkan autentikasi.
Browser Tanpa Kepala
Browser tanpa kepala sama seperti browser biasa tetapi tanpa antarmuka pengguna grafis. Alat seperti Puppeteer dan Playwright dapat berjalan dalam mode tanpa kepala, mengeksekusi JavaScript dan merender halaman web di latar belakang. Metode ini berguna untuk pengujian otomatis dan pengikisan konten dinamis.
Kelebihan : Render penuh konten dinamis, termasuk eksekusi JavaScript.
Kekurangan : Mirip dengan otomatisasi browser, metode ini lebih boros sumber daya dibandingkan metode lainnya.
Kerangka Pengikisan Web
Kerangka kerja seperti Scrapy (Python) menawarkan lingkungan lengkap untuk web scraping, menyediakan fitur untuk mengekstraksi data, mengikuti tautan, dan menangani kesalahan. Kerangka kerja ini dirancang untuk membangun perayap web yang skalabel dan mengelola beberapa tugas pengikisan secara bersamaan.
Kelebihan : Solusi komprehensif dengan fitur bawaan untuk proyek scraping yang kompleks.
Kekurangan : Mungkin memiliki kurva belajar yang lebih curam untuk pemula.
Pengenalan Karakter Optik (OCR)
Untuk mengambil data dari gambar atau dokumen yang dipindai, teknologi OCR seperti Tesseract dapat mengubah representasi visual teks menjadi teks yang dapat dibaca mesin. Metode ini sangat berguna untuk mengekstrak data dari PDF, gambar, atau captcha.
Kelebihan : Memungkinkan ekstraksi teks dari gambar dan dokumen yang dipindai.
Kekurangan : Dapat mengakibatkan ketidakakuratan pada gambar berkualitas rendah atau tata letak yang rumit.