
El futuro del web scraping: predicciones y tecnologías emergentes
Publicado: 2024-03-22El futuro del web scraping se encuentra en un momento apasionante, en el que los avances tecnológicos y los cambios en las políticas de uso de datos están dando forma a su trayectoria. A medida que las empresas y los investigadores dependen cada vez más de datos extraídos de la web para inteligencia competitiva, investigación de mercado y automatización, las herramientas y metodologías del web scraping están evolucionando para satisfacer estas demandas de manera más eficiente y ética. A continuación se muestran algunas predicciones y tecnologías emergentes que probablemente influirán en el futuro del web scraping:
Mayor integración de la IA y el aprendizaje automático
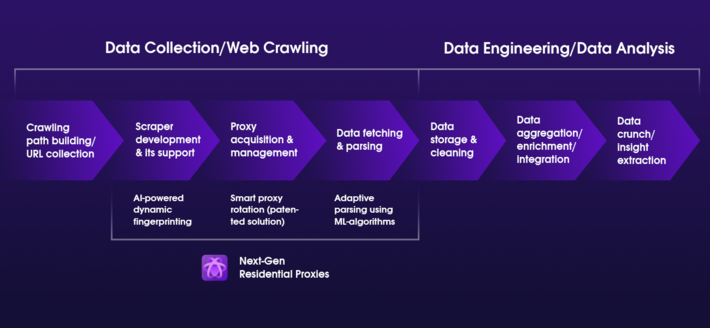
La integración de la Inteligencia Artificial (IA) y el Aprendizaje Automático (ML) en las tecnologías de web scraping marca un cambio transformador en la forma en que abordamos la extracción de datos de la web. Estas tecnologías avanzadas no sólo prometen perfeccionar el proceso en términos de eficiencia y eficacia, sino que también abren nuevas perspectivas para el análisis y la aplicación de datos que antes eran impensables. Profundicemos en cómo la IA y el ML están preparados para revolucionar el web scraping:
Fuente: https://www.datasciencecentral.com/how-to-overcome-web-scraping-challenges-with-ai-amp-ml-technology/
Los algoritmos de IA y ML pueden mejorar significativamente la precisión de la extracción de datos al comprender la semántica del contenido web. Por ejemplo, los modelos de IA entrenados en procesamiento del lenguaje natural (PLN) pueden discernir el contexto y el significado detrás del texto en una página web, lo que permite extraer información más relevante y precisa. Esto es particularmente beneficioso en sectores como la investigación de mercado o el análisis competitivo, donde la calidad y relevancia de los datos impactan directamente en los conocimientos derivados.
Avances en el procesamiento del lenguaje natural (PNL)
Los avances en el procesamiento del lenguaje natural (PLN) están cambiando rápidamente el panorama de la extracción de datos, particularmente del contenido web no estructurado que constituye una parte importante de Internet. La PNL, una rama de la inteligencia artificial, se centra en la interacción entre computadoras y humanos a través del lenguaje natural. Su integración en tecnologías de web scraping no es solo una mejora; es una revolución que amplía los horizontes de lo que se puede lograr mediante la extracción de datos. Exploremos más a fondo las profundidades de esta integración y sus implicaciones.
La capacidad de medir el sentimiento del público hacia productos, servicios o marcas es invaluable para las empresas. Los avances de la PNL han hecho que el análisis de sentimientos sea más sofisticado, lo que permite un análisis detallado de los comentarios de los clientes y las menciones en las redes sociales. Esto no sólo resalta si los sentimientos son positivos o negativos; profundiza en la intensidad de estos sentimientos y los aspectos específicos a los que pertenecen. Un análisis tan detallado puede guiar el desarrollo de productos, las estrategias de marketing y las mejoras en el servicio al cliente.
Medidas y contramedidas anti-scraping más sólidas
A medida que el web scraping se vuelve más frecuente, es probable que los sitios web implementen medidas anti-scraping más sofisticadas para proteger sus datos. Esto podría incluir CAPTCHA más complejos, análisis de comportamiento para detectar bots y técnicas de representación dinámica de datos. En respuesta, las tecnologías de scraping deberán evolucionar para sortear estas barreras, posiblemente aprovechando la IA para imitar más fielmente los patrones de navegación humana o adoptando métodos más sofisticados de resolución de CAPTCHA.
Scraping Ético y Cumplimiento de Normas Legales
Con las crecientes preocupaciones sobre la privacidad y la protección de datos, las prácticas éticas de web scraping se volverán más críticas. Esto incluye adherirse a los archivos robots.txt, respetar las leyes de derechos de autor y cumplir con las regulaciones internacionales de protección de datos como GDPR. Las herramientas y plataformas que priorizan el scraping ético y la privacidad de los datos ganarán importancia, y es posible que veamos el desarrollo de marcos y directrices estandarizados para el web scraping ético.
Mayor énfasis en la extracción de datos en tiempo real
La aceleración de la transformación digital en todas las industrias ha marcado el comienzo de una era en la que la agilidad y la velocidad no sólo son valiosas; son primordiales. En este contexto, el énfasis en la extracción de datos en tiempo real representa una evolución crítica en las tecnologías de web scraping, con el objetivo de igualar el ritmo de toma de decisiones requerido en los mercados en rápido movimiento de hoy. Las implicaciones de este cambio hacia los datos en tiempo real son profundas, afectan todo, desde el comercio financiero hasta el servicio al cliente, y sientan las bases para innovaciones que podrían redefinir las ventajas competitivas.
En el sector financiero, la extracción de datos en tiempo real no sólo es beneficiosa; es esencial. La diferencia de unos pocos segundos puede afectar significativamente las decisiones y los resultados comerciales. Las herramientas avanzadas de web scraping que pueden ofrecer noticias financieras, precios de acciones y sentimiento del mercado en tiempo real se están convirtiendo en activos indispensables para los comerciantes y analistas financieros.
El sector minorista está adoptando cada vez más modelos de precios dinámicos que ajustan los precios en función de la demanda del mercado, los precios de la competencia y los niveles de inventario. La extracción de datos en tiempo real permite a los minoristas monitorear estas variables continuamente y ajustar sus estrategias de precios al instante. Esta capacidad puede mejorar significativamente la competitividad, especialmente en el comercio electrónico, donde la comparación de precios es común entre los consumidores. Los minoristas que aprovechan los datos en tiempo real pueden optimizar los precios para mejorar los volúmenes de ventas y los márgenes de beneficio mientras mantienen la competitividad del mercado.
Servicios de scraping basados en la nube
A medida que la economía digital continúa expandiéndose, se intensifica la demanda de una toma de decisiones basada en datos. Esto ha llevado a una mayor dependencia del web scraping como método para recopilar grandes cantidades de datos necesarios para análisis, investigaciones de mercado e inteligencia competitiva. Los servicios de web scraping basados en la nube están a la vanguardia de esta tendencia y revolucionan la forma en que las organizaciones abordan la extracción de datos al ofrecer soluciones potentes, escalables y fáciles de usar. A continuación se ofrece una mirada más profunda al mundo de los servicios de scraping basados en la nube y su impacto potencial:
Ventajas de los servicios de scraping basados en la nube
1. Escalabilidad : una de las ventajas más importantes de los servicios basados en la nube es su capacidad de escalar sin esfuerzo. Ya sea que esté buscando extraer datos de un puñado de páginas o de millones, estas plataformas pueden asignar recursos dinámicamente para satisfacer la demanda, garantizando una extracción de datos eficiente sin la necesidad de intervención manual.
2. Rentabilidad : al aprovechar los recursos compartidos en la nube, estos servicios pueden ofrecer modelos de precios competitivos que hacen que el web scraping sea accesible para empresas de todos los tamaños. Esto elimina la necesidad de realizar importantes inversiones iniciales en hardware y software, lo que reduce las barreras de entrada para el uso de tecnologías de web scraping.
3. Mantenimiento y actualizaciones : los servicios basados en la nube se encargan de todos los aspectos del mantenimiento y las actualizaciones, garantizando que la tecnología de scraping se mantenga actualizada con los últimos estándares web y prácticas de seguridad. Esto descarga una carga significativa a los usuarios, permitiéndoles concentrarse en analizar los datos en lugar de preocuparse por los aspectos técnicos del scraping.
4. Funciones avanzadas : estas plataformas a menudo vienen equipadas con funciones avanzadas que mejoran la eficiencia y eficacia de las operaciones de web scraping. La rotación automática de IP ayuda a evadir las medidas anti-scraping al realizar solicitudes desde diferentes direcciones IP, mientras que el procesamiento de datos de alta velocidad garantiza que se puedan extraer y analizar grandes volúmenes de datos rápidamente.
5. Capacidades de integración : muchos servicios de scraping basados en la nube ofrecen API e integraciones con plataformas y herramientas de análisis de datos populares. Esto permite flujos de trabajo fluidos en los que los datos extraídos se pueden introducir automáticamente en modelos analíticos, paneles o bases de datos para análisis en tiempo real.

Tecnologías de scraping sin navegador
Las tecnologías emergentes pueden ofrecer formas más eficientes de simular entornos de navegador o incluso evitar por completo la necesidad de un navegador para tareas de scraping. Esto podría reducir significativamente los recursos necesarios para las operaciones de web scraping, permitiendo una recopilación de datos más rápida y eficiente.
Conclusión
El futuro del web scraping es a la vez prometedor y desafiante. A medida que avancen las tecnologías, el equilibrio entre el acceso a los datos disponibles públicamente y el respeto de la privacidad y los límites legales será crucial. La innovación en IA, ML y PNL, junto con el compromiso con las prácticas de scraping ético, darán forma al desarrollo de herramientas de web scraping, haciendo que los datos sean más accesibles y valiosos para las empresas y los investigadores de todo el mundo. En este panorama en evolución, mantenerse informado sobre los cambios tecnológicos y regulatorios será clave para aprovechar todo el potencial del web scraping.
Preguntas frecuentes
¿Qué son las tecnologías de web scraping?
Las tecnologías de web scraping se refieren a los métodos, herramientas y software utilizados para extraer datos de sitios web. Este proceso implica acceder mediante programación a páginas web, analizar el código HTML y luego extraer información útil como texto, imágenes, enlaces y metadatos. Los datos extraídos se pueden guardar en un archivo o base de datos local en un formato estructurado para su análisis, generación de informes o procesamiento posterior. El web scraping se utiliza ampliamente en diversas industrias para tareas como investigación de mercado, análisis competitivo, seguimiento de precios, generación de leads y agregación de contenido.
Componentes clave de las tecnologías de web scraping:
- Solicitudes HTTP : el núcleo del web scraping es la capacidad de enviar solicitudes HTTP mediante programación para recuperar páginas web. Para este propósito se utilizan comúnmente herramientas como curl en la línea de comandos, bibliotecas como solicitudes en Python o HttpClient en .NET.
- Análisis de HTML : una vez que se recupera el contenido HTML de una página web, es necesario analizarlo para extraer los datos requeridos. Las bibliotecas de análisis HTML como BeautifulSoup y lxml en Python, o Jsoup en Java, proporcionan funcionalidades para navegar por la estructura de documentos HTML y extraer datos basados en etiquetas, clases o ID.
- Automatización de navegadores web : para sitios web dinámicos que dependen en gran medida de JavaScript para cargar contenido, se utilizan herramientas que automatizan los navegadores web. Estas herramientas, como Selenium, Puppeteer y Playwright, imitan la interacción humana con el navegador, permitiendo la ejecución de llamadas JavaScript y AJAX necesarias para acceder al contenido.
- Almacenamiento de datos : los datos extraídos generalmente se almacenan en bases de datos o se escriben en archivos en formatos como CSV, JSON o Excel para su posterior análisis o procesamiento.
- Limpieza y formato de datos : los datos extraídos a menudo requieren limpieza y transformación para eliminar caracteres innecesarios, corregir el formato o convertir tipos de datos. Este paso es crucial para garantizar que los datos sean precisos y utilizables.
¿Qué herramienta se utiliza para el web scraping?
Hay varias herramientas y bibliotecas disponibles para web scraping, que se adaptan a diferentes niveles de experiencia, lenguajes de programación y necesidades específicas. A continuación se ofrece una descripción general de algunas herramientas populares utilizadas para el web scraping:
Hermosa sopa
- Idioma : Python
- Uso : Ideal para análisis HTML y XML sencillos y extracción de datos de sitios web estáticos.
- Características : Fácil de usar para principiantes, potente cuando se combina con la biblioteca de solicitudes de Python para recuperar contenido web.
raspado
- Idioma : Python
- Uso : Ideal para crear rastreadores web escalables y raspar sitios web complejos.
- Características : proporciona un marco completo para el rastreo y el raspado web, admite canalizaciones de elementos, exportación de datos y middleware para manejar diferentes escenarios.
Selenio
- Idioma : admite varios idiomas, incluidos Python, Java, C#, Ruby y JavaScript.
- Uso : Inicialmente diseñado para automatizar navegadores web con fines de prueba, también se utiliza para extraer contenido dinámico renderizado a través de JavaScript.
- Características : Puede controlar un navegador web para imitar el comportamiento de navegación humana, lo que permite extraer datos de sitios web que requieren inicio de sesión o interacción.
Titiritero
- Idioma : JavaScript (Node.js)
- Uso : Adecuado para raspar sitios web dinámicos y aplicaciones de una sola página que dependen en gran medida de JavaScript.
- Características : Proporciona una API de alto nivel para controlar Chrome o Chromium a través del protocolo DevTools, lo que permite tareas como renderizar JavaScript, tomar capturas de pantalla y generar archivos PDF de páginas web.
Dramaturgo
- Idioma : Node.js, Python, C# y Java
- Uso : similar a Puppeteer pero diseñado para admitir múltiples navegadores (Chrome, Firefox y WebKit).
- Funciones : Automatiza las acciones del navegador para el raspado web, las pruebas en todos los navegadores y la captura de capturas de pantalla y videos.
animador
- Idioma : JavaScript (Node.js)
- Uso : Lo mejor para la manipulación DOM del lado del servidor, similar a jQuery, que permite un raspado rápido y eficiente de sitios web estáticos.
- Características : Analiza el marcado y proporciona una API para atravesar/manipular la estructura de datos resultante; más ligero que Puppeteer para contenido estático.
octoparse
- Idioma : N/A (herramienta basada en GUI)
- Uso : Adecuado para no programadores o aquellos que prefieren una interfaz visual a escribir código.
- Características : Una interfaz de apuntar y hacer clic para seleccionar datos para extracción, manejando sitios web tanto estáticos como dinámicos. Ofrece servicios en la nube para ejecutar rastreadores.
ParseHub
- Idioma : N/A (herramienta basada en GUI)
- Uso : Diseñado para usuarios sin conocimientos de programación para extraer sitios web utilizando una potente herramienta visual.
- Características : Admite sitios web con mucho AJAX y JavaScript, con una interfaz fácil de usar para seleccionar puntos de datos y exportar datos.
¿Cuáles son los diferentes métodos utilizados para el web scraping?
El web scraping abarca varios métodos para extraer datos de sitios web, cada uno de ellos adecuado a diferentes tipos de contenido web y necesidades del usuario. A continuación se ofrece una descripción general de algunos métodos de web scraping utilizados habitualmente:
Solicitudes HTTP
Este método implica enviar solicitudes HTTP para recuperar directamente el contenido HTML de las páginas web. Es más eficaz para sitios web estáticos donde el contenido no depende de la ejecución de JavaScript. Las bibliotecas como las solicitudes en Python y HttpClient en .NET son populares para realizar solicitudes HTTP.
Pros : Simple y rápido para contenido estático.
Contras : Ineficaz para contenido dinámico cargado a través de JavaScript.
Análisis HTML
Una vez que tenga el contenido HTML, las bibliotecas de análisis como Beautiful Soup (Python), Cheerio (Node.js) o Jsoup (Java) pueden navegar por el árbol HTML DOM y extraer datos específicos. Este método es ideal para extraer datos de páginas estáticas o de la fuente HTML después de la ejecución de JavaScript.
Ventajas : Extracción flexible y precisa de elementos de datos.
Contras : Requiere comprensión de la estructura de la página web.
Automatización del navegador
Herramientas como Selenium, Puppeteer y Playwright automatizan un navegador web real, lo que le permite extraer contenido dinámico que requiere la ejecución de JavaScript o la interacción con la página (por ejemplo, hacer clic en botones, completar formularios). Estas herramientas pueden imitar el comportamiento de navegación humana, lo que las hace poderosas para tareas complejas de scraping.
Ventajas : puede manejar sitios web dinámicos con mucho JavaScript.
Contras : consume más recursos y es más lento que las solicitudes HTTP directas.
Solicitudes de API
Muchos sitios web cargan datos de forma dinámica a través de API. Al inspeccionar el tráfico de la red (utilizando herramientas como la pestaña Red en las DevTools del navegador), puede identificar los puntos finales de la API y solicitar datos directamente. Este método es eficaz y, a menudo, devuelve datos en un formato estructurado como JSON.
Ventajas : Rápido y eficiente, proporciona datos estructurados.
Desventajas : requiere comprensión de los puntos finales de la API y puede implicar autenticación.
Navegadores sin cabeza
Los navegadores sin cabeza son como los navegadores normales pero sin una interfaz gráfica de usuario. Herramientas como Puppeteer y Playwright pueden ejecutarse en modo sin cabeza, ejecutando JavaScript y renderizando páginas web en segundo plano. Este método es útil para pruebas automatizadas y extracción de contenido dinámico.
Ventajas : Representación completa de contenido dinámico, incluida la ejecución de JavaScript.
Contras : similar a la automatización del navegador, requiere más recursos que otros métodos.
Marcos de raspado web
Los marcos como Scrapy (Python) ofrecen un entorno completo para el web scraping, proporcionando funciones para extraer datos, seguir enlaces y manejar errores. Estos marcos están diseñados para crear rastreadores web escalables y administrar múltiples tareas de raspado simultáneamente.
Ventajas : solución integral con funciones integradas para proyectos complejos de scraping.
Desventajas : Puede que tenga una curva de aprendizaje más pronunciada para los principiantes.
Reconocimiento óptico de caracteres (OCR)
Para extraer datos de imágenes o documentos escaneados, las tecnologías OCR como Tesseract pueden convertir representaciones visuales de texto en texto legible por máquina. Este método es particularmente útil para extraer datos de archivos PDF, imágenes o captchas.
Ventajas : permite la extracción de texto de imágenes y documentos escaneados.
Desventajas : puede provocar imprecisiones en imágenes de baja calidad o diseños complejos.