
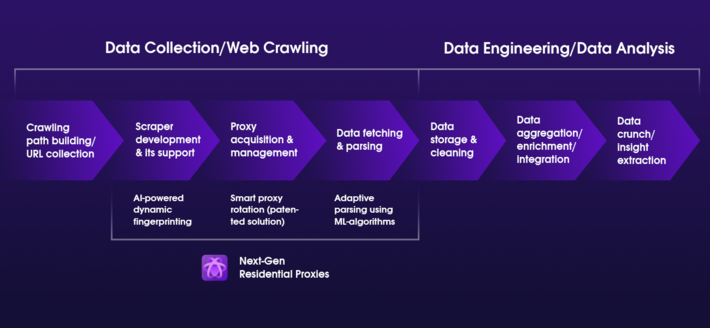
อนาคตของการขูดเว็บ: การคาดการณ์และเทคโนโลยีเกิดใหม่
เผยแพร่แล้ว: 2024-03-22อนาคตของการขูดเว็บกำลังอยู่ในช่วงหัวเลี้ยวหัวต่อที่น่าตื่นเต้น โดยมีความก้าวหน้าทางเทคโนโลยีและการเปลี่ยนแปลงนโยบายการใช้ข้อมูลที่กำหนดทิศทางของมัน ในขณะที่ธุรกิจและนักวิจัยพึ่งพาข้อมูลที่คัดลอกมาจากเว็บมากขึ้นสำหรับข่าวกรองด้านการแข่งขัน การวิจัยตลาด และระบบอัตโนมัติ เครื่องมือและวิธีการของการแยกเว็บก็กำลังพัฒนาเพื่อตอบสนองความต้องการเหล่านี้อย่างมีประสิทธิภาพและมีจริยธรรมมากขึ้น ต่อไปนี้เป็นการคาดการณ์และเทคโนโลยีใหม่ ๆ ที่อาจส่งผลต่ออนาคตของการขูดเว็บ:
บูรณาการที่เพิ่มขึ้นของ AI และการเรียนรู้ของเครื่อง
การบูรณาการปัญญาประดิษฐ์ (AI) และการเรียนรู้ของเครื่อง (ML) เข้ากับเทคโนโลยีการขูดเว็บถือเป็นการเปลี่ยนแปลงครั้งสำคัญในวิธีที่เราจัดการกับการดึงข้อมูลจากเว็บ เทคโนโลยีขั้นสูงเหล่านี้ไม่เพียงแต่สัญญาว่าจะปรับปรุงกระบวนการในแง่ของประสิทธิภาพและประสิทธิผล แต่ยังเปิดมุมมองใหม่สำหรับการวิเคราะห์ข้อมูลและการใช้งานที่ไม่เคยคิดมาก่อน เรามาเจาะลึกลงไปว่า AI และ ML พร้อมที่จะปฏิวัติการขูดเว็บอย่างไร:
ที่มา: https://www.datasciencecentral.com/how-to-overcome-web-scraping-challenges-with-ai-amp-ml-technology/
อัลกอริธึม AI และ ML สามารถปรับปรุงความแม่นยำในการดึงข้อมูลได้อย่างมาก โดยการทำความเข้าใจความหมายของเนื้อหาเว็บ ตัวอย่างเช่น โมเดล AI ที่ได้รับการฝึกอบรมด้านการประมวลผลภาษาธรรมชาติ (NLP) สามารถแยกแยะบริบทและความหมายเบื้องหลังข้อความบนหน้าเว็บได้ ทำให้สามารถดึงข้อมูลที่เกี่ยวข้องและแม่นยำยิ่งขึ้นได้ สิ่งนี้มีประโยชน์อย่างยิ่งในภาคส่วนต่างๆ เช่น การวิจัยตลาดหรือการวิเคราะห์การแข่งขัน ซึ่งคุณภาพและความเกี่ยวข้องของข้อมูลส่งผลโดยตรงต่อข้อมูลเชิงลึกที่ได้รับ
ความก้าวหน้าในการประมวลผลภาษาธรรมชาติ (NLP)
ความก้าวหน้าในการประมวลผลภาษาธรรมชาติ (NLP) กำลังเปลี่ยนแปลงภูมิทัศน์ของการดึงข้อมูลไปอย่างรวดเร็ว โดยเฉพาะอย่างยิ่งจากเนื้อหาเว็บที่ไม่มีโครงสร้างซึ่งถือเป็นส่วนสำคัญของอินเทอร์เน็ต NLP ซึ่งเป็นสาขาหนึ่งของปัญญาประดิษฐ์ มุ่งเน้นไปที่ปฏิสัมพันธ์ระหว่างคอมพิวเตอร์กับมนุษย์ผ่านภาษาธรรมชาติ การบูรณาการเข้ากับเทคโนโลยีการขูดเว็บไม่ได้เป็นเพียงการปรับปรุงเท่านั้น เป็นการปฏิวัติที่ขยายขอบเขตอันไกลโพ้นของสิ่งที่สามารถทำได้ผ่านการดึงข้อมูล มาสำรวจความลึกของการบูรณาการนี้และผลที่ตามมากันดีกว่า
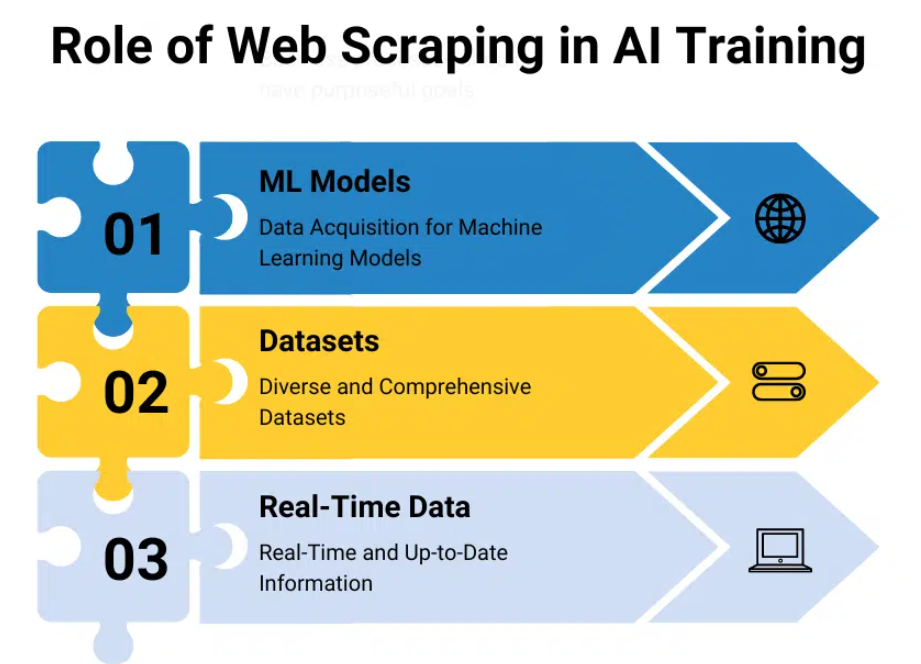
ความสามารถในการวัดความรู้สึกของสาธารณะต่อผลิตภัณฑ์ บริการ หรือแบรนด์เป็นสิ่งที่ประเมินค่าไม่ได้สำหรับธุรกิจ ความก้าวหน้าของ NLP ทำให้การวิเคราะห์ความรู้สึกมีความซับซ้อนมากขึ้น ช่วยให้สามารถวิเคราะห์ความคิดเห็นของลูกค้าและการกล่าวถึงบนโซเชียลมีเดียได้อย่างละเอียด สิ่งนี้ไม่เพียงแค่เน้นว่าความรู้สึกเป็นบวกหรือลบเท่านั้น โดยจะเจาะลึกถึงความรุนแรงของความรู้สึกเหล่านี้และแง่มุมเฉพาะที่เกี่ยวข้อง การวิเคราะห์โดยละเอียดดังกล่าวสามารถเป็นแนวทางในการพัฒนาผลิตภัณฑ์ กลยุทธ์ทางการตลาด และการปรับปรุงการบริการลูกค้า
มาตรการป้องกันการขูดและการตอบโต้ที่แข็งแกร่งยิ่งขึ้น
เนื่องจากการขูดเว็บแพร่หลายมากขึ้น เว็บไซต์จึงมีแนวโน้มที่จะใช้มาตรการป้องกันการขูดที่ซับซ้อนมากขึ้นเพื่อปกป้องข้อมูลของตน ซึ่งอาจรวมถึง CAPTCHA ที่ซับซ้อนมากขึ้น การวิเคราะห์พฤติกรรมเพื่อตรวจจับบอท และเทคนิคการแสดงข้อมูลแบบไดนามิก ในการตอบสนอง เทคโนโลยีขูดจะต้องพัฒนาเพื่อนำทางอุปสรรคเหล่านี้ อาจใช้ประโยชน์จาก AI เพื่อเลียนแบบรูปแบบการสืบค้นข้อมูลของมนุษย์อย่างใกล้ชิดมากขึ้น หรือใช้วิธีการแก้ปัญหา CAPTCHA ที่ซับซ้อนมากขึ้น
การขูดลอกอย่างมีจริยธรรมและการปฏิบัติตามมาตรฐานทางกฎหมาย
ด้วยความกังวลที่เพิ่มขึ้นเกี่ยวกับความเป็นส่วนตัวและการปกป้องข้อมูล แนวทางปฏิบัติในการขูดเว็บอย่างมีจริยธรรมจึงมีความสำคัญมากขึ้น ซึ่งรวมถึงการปฏิบัติตามไฟล์ robots.txt การเคารพกฎหมายลิขสิทธิ์ และการปฏิบัติตามกฎระเบียบการคุ้มครองข้อมูลระหว่างประเทศ เช่น GDPR เครื่องมือและแพลตฟอร์มที่ให้ความสำคัญกับการคัดลอกข้อมูลอย่างมีจริยธรรมและความเป็นส่วนตัวของข้อมูลจะได้รับความโดดเด่น และเราอาจเห็นการพัฒนากรอบงานที่เป็นมาตรฐานและแนวทางสำหรับการคัดลอกเว็บอย่างมีจริยธรรม
เน้นมากขึ้นในการดึงข้อมูลแบบเรียลไทม์
การเร่งการเปลี่ยนแปลงทางดิจิทัลในอุตสาหกรรมต่างๆ ทำให้เกิดยุคที่ความคล่องตัวและความเร็วไม่ได้เป็นเพียงคุณค่าเท่านั้น พวกเขาเป็นสิ่งสำคัญยิ่ง ในบริบทนี้ การเน้นที่การดึงข้อมูลแบบเรียลไทม์แสดงถึงวิวัฒนาการที่สำคัญในเทคโนโลยีการขูดเว็บ โดยมีเป้าหมายเพื่อให้สอดคล้องกับก้าวของการตัดสินใจที่จำเป็นในตลาดที่เคลื่อนไหวอย่างรวดเร็วในปัจจุบัน ผลกระทบของการเปลี่ยนแปลงไปสู่ข้อมูลแบบเรียลไทม์นั้นลึกซึ้ง ส่งผลกระทบต่อทุกสิ่งตั้งแต่การซื้อขายทางการเงินไปจนถึงการบริการลูกค้า และการกำหนดเวทีสำหรับนวัตกรรมที่สามารถกำหนดความได้เปรียบในการแข่งขันใหม่
ในภาคการเงิน การดึงข้อมูลแบบเรียลไทม์ไม่เพียงแต่เป็นประโยชน์เท่านั้น มันเป็นสิ่งจำเป็น ความแตกต่างของไม่กี่วินาทีสามารถส่งผลกระทบอย่างมากต่อการตัดสินใจและผลลัพธ์ในการซื้อขาย เครื่องมือขูดเว็บขั้นสูงที่สามารถนำเสนอข่าวสารทางการเงิน ราคาหุ้น และความเชื่อมั่นของตลาดแบบเรียลไทม์ กลายเป็นทรัพย์สินที่ขาดไม่ได้สำหรับเทรดเดอร์และนักวิเคราะห์ทางการเงิน
ภาคการค้าปลีกมีการใช้โมเดลการกำหนดราคาแบบไดนามิกมากขึ้น ซึ่งปรับราคาตามความต้องการของตลาด การกำหนดราคาของคู่แข่ง และระดับสินค้าคงคลัง การดึงข้อมูลแบบเรียลไทม์ช่วยให้ผู้ค้าปลีกสามารถตรวจสอบตัวแปรเหล่านี้ได้อย่างต่อเนื่องและปรับกลยุทธ์การกำหนดราคาได้ทันที ความสามารถนี้สามารถช่วยเพิ่มขีดความสามารถในการแข่งขันได้อย่างมาก โดยเฉพาะอย่างยิ่งในอีคอมเมิร์ซ ซึ่งการเปรียบเทียบราคาเป็นเรื่องปกติในหมู่ผู้บริโภค ผู้ค้าปลีกที่ใช้ประโยชน์จากข้อมูลแบบเรียลไทม์สามารถปรับราคาให้เหมาะสมเพื่อเพิ่มปริมาณการขายและอัตรากำไร ในขณะเดียวกันก็รักษาความสามารถในการแข่งขันในตลาดไว้ได้
บริการขูดบนคลาวด์
ในขณะที่เศรษฐกิจดิจิทัลขยายตัวอย่างต่อเนื่อง ความต้องการการตัดสินใจที่ขับเคลื่อนด้วยข้อมูลก็ทวีความรุนแรงมากขึ้น สิ่งนี้นำไปสู่การพึ่งพา Web Scraping มากขึ้นซึ่งเป็นวิธีการรวบรวมข้อมูลจำนวนมหาศาลที่จำเป็นสำหรับการวิเคราะห์ การวิจัยตลาด และข้อมูลทางการแข่งขัน บริการขูดเว็บบนคลาวด์ถือเป็นแนวหน้าของเทรนด์นี้ โดยปฏิวัติวิธีที่องค์กรต่างๆ เข้าถึงการดึงข้อมูลโดยนำเสนอโซลูชันที่ทรงพลัง ปรับขนาดได้ และใช้งานง่าย ต่อไปนี้เป็นข้อมูลเชิงลึกเกี่ยวกับโลกของบริการขูดบนระบบคลาวด์และผลกระทบที่อาจเกิดขึ้น:
ข้อดีของบริการขูดบนคลาวด์
1. ความสามารถในการขยายขนาด : หนึ่งในข้อได้เปรียบที่สำคัญที่สุดของบริการบนคลาวด์ก็คือความสามารถในการขยายขนาดได้อย่างง่ายดาย ไม่ว่าคุณกำลังมองหาการดึงข้อมูลจากไม่กี่หน้าหรือหลายล้านหน้า แพลตฟอร์มเหล่านี้สามารถจัดสรรทรัพยากรแบบไดนามิกเพื่อตอบสนองความต้องการ ทำให้มั่นใจได้ว่าการดึงข้อมูลมีประสิทธิภาพโดยไม่จำเป็นต้องมีการแทรกแซงด้วยตนเอง
2. ความคุ้มค่าด้านต้นทุน : ด้วยการใช้ประโยชน์จากทรัพยากรที่ใช้ร่วมกันในระบบคลาวด์ บริการเหล่านี้สามารถนำเสนอโมเดลราคาที่แข่งขันได้ ซึ่งทำให้ธุรกิจทุกขนาดสามารถเข้าถึงการขูดเว็บได้ ซึ่งช่วยลดความจำเป็นในการลงทุนล่วงหน้าจำนวนมากในฮาร์ดแวร์และซอฟต์แวร์ ช่วยลดอุปสรรคในการเข้าสู่การใช้เทคโนโลยีการขูดเว็บ
3. การบำรุงรักษาและการอัพเกรด : บริการบนคลาวด์จัดการทุกด้านของการบำรุงรักษาและการอัปเดต ทำให้มั่นใจได้ว่าเทคโนโลยีขูดจะเป็นปัจจุบันด้วยมาตรฐานเว็บและแนวปฏิบัติด้านความปลอดภัยล่าสุด ซึ่งช่วยลดภาระที่สำคัญของผู้ใช้ ทำให้พวกเขามุ่งเน้นไปที่การวิเคราะห์ข้อมูล แทนที่จะกังวลเกี่ยวกับเทคนิคของการคัดลอก
4. คุณสมบัติขั้นสูง : แพลตฟอร์มเหล่านี้มักจะมาพร้อมกับคุณสมบัติขั้นสูงที่ช่วยเพิ่มประสิทธิภาพและประสิทธิผลของการดำเนินการขูดเว็บ การหมุนเวียน IP อัตโนมัติช่วยหลีกเลี่ยงมาตรการป้องกันการคัดลอกโดยส่งคำขอจากที่อยู่ IP ที่แตกต่างกัน ในขณะที่การประมวลผลข้อมูลความเร็วสูงช่วยให้มั่นใจได้ว่าสามารถแยกและวิเคราะห์ข้อมูลจำนวนมากได้อย่างรวดเร็ว
5. ความสามารถในการบูรณาการ : บริการขูดบนคลาวด์จำนวนมากเสนอ API และการผสานรวมกับเครื่องมือและแพลตฟอร์มการวิเคราะห์ข้อมูลยอดนิยม ช่วยให้เกิดขั้นตอนการทำงานที่ราบรื่น โดยที่ข้อมูลที่แยกออกมาสามารถป้อนเข้าสู่โมเดลการวิเคราะห์ แดชบอร์ด หรือฐานข้อมูลโดยอัตโนมัติสำหรับการวิเคราะห์แบบเรียลไทม์
เทคโนโลยีการขูดแบบไร้เบราว์เซอร์

เทคโนโลยีเกิดใหม่อาจเสนอวิธีที่มีประสิทธิภาพมากขึ้นในการจำลองสภาพแวดล้อมของเบราว์เซอร์ หรือแม้กระทั่งหลีกเลี่ยงความจำเป็นในการใช้เบราว์เซอร์โดยสิ้นเชิงในการคัดลอกงาน สิ่งนี้สามารถลดทรัพยากรที่จำเป็นสำหรับการดำเนินการขูดเว็บได้อย่างมาก ทำให้สามารถรวบรวมข้อมูลได้เร็วและมีประสิทธิภาพยิ่งขึ้น
บทสรุป
อนาคตของการขูดเว็บมีทั้งความหวังและความท้าทาย เมื่อเทคโนโลยีก้าวหน้าไป ความสมดุลระหว่างการเข้าถึงข้อมูลที่เปิดเผยต่อสาธารณะและการเคารพความเป็นส่วนตัวและขอบเขตทางกฎหมายจะมีความสำคัญ นวัตกรรมใน AI, ML และ NLP ควบคู่ไปกับความมุ่งมั่นในแนวทางปฏิบัติในการขูดอย่างมีจริยธรรม จะกำหนดรูปแบบการพัฒนาเครื่องมือขูดเว็บ ทำให้สามารถเข้าถึงข้อมูลได้มากขึ้นและมีคุณค่าสำหรับธุรกิจและนักวิจัยทั่วโลก ในภูมิทัศน์ที่กำลังพัฒนานี้ การรับทราบข้อมูลเกี่ยวกับการเปลี่ยนแปลงทางเทคโนโลยีและกฎระเบียบจะเป็นกุญแจสำคัญในการใช้ประโยชน์จากศักยภาพสูงสุดของการขูดเว็บ
คำถามที่พบบ่อย
เทคโนโลยีการขูดเว็บคืออะไร?
เทคโนโลยีการขูดเว็บหมายถึงวิธีการ เครื่องมือ และซอฟต์แวร์ที่ใช้ในการดึงข้อมูลจากเว็บไซต์ กระบวนการนี้เกี่ยวข้องกับการเข้าถึงหน้าเว็บโดยทางโปรแกรม แยกวิเคราะห์โค้ด HTML จากนั้นดึงข้อมูลที่เป็นประโยชน์ เช่น ข้อความ รูปภาพ ลิงก์ และข้อมูลเมตา ข้อมูลที่แยกออกมาสามารถบันทึกลงในไฟล์หรือฐานข้อมูลในเครื่องในรูปแบบที่มีโครงสร้างสำหรับการวิเคราะห์ การรายงาน หรือการประมวลผลเพิ่มเติม Web scraping ถูกนำมาใช้กันอย่างแพร่หลายในอุตสาหกรรมต่างๆ สำหรับงานต่างๆ เช่น การวิจัยตลาด การวิเคราะห์การแข่งขัน การตรวจสอบราคา การสร้างโอกาสในการขาย และการรวมเนื้อหา
ส่วนประกอบสำคัญของเทคโนโลยีการขูดเว็บ:
- คำขอ HTTP : หัวใจหลักของการขูดเว็บคือความสามารถในการส่งคำขอ HTTP โดยทางโปรแกรมเพื่อดึงข้อมูลหน้าเว็บ เครื่องมือเช่น curl ในบรรทัดคำสั่ง ไลบรารีเช่นคำขอใน Python หรือ HttpClient ใน .NET มักใช้เพื่อจุดประสงค์นี้
- การแยกวิเคราะห์ HTML : เมื่อดึงเนื้อหา HTML ของหน้าเว็บแล้ว จะต้องแยกวิเคราะห์เพื่อแยกข้อมูลที่จำเป็น ไลบรารีการแยกวิเคราะห์ HTML เช่น BeautifulSoup และ lxml ใน Python หรือ Jsoup ใน Java มีฟังก์ชันการใช้งานเพื่อนำทางโครงสร้างของเอกสาร HTML และแยกข้อมูลตามแท็ก คลาส หรือ ID
- เว็บเบราว์เซอร์อัตโนมัติ : สำหรับเว็บไซต์ไดนามิกที่ต้องอาศัย JavaScript อย่างมากในการโหลดเนื้อหา จะมีการใช้เครื่องมือที่ทำให้เว็บเบราว์เซอร์อัตโนมัติ เครื่องมือเหล่านี้ เช่น Selenium, Puppeteer และ Playwright เลียนแบบการโต้ตอบของมนุษย์กับเบราว์เซอร์ ทำให้สามารถเรียกใช้ JavaScript และ AJAX ที่จำเป็นในการเข้าถึงเนื้อหาได้
- การจัดเก็บข้อมูล : โดยทั่วไปข้อมูลที่แยกออกมาจะถูกจัดเก็บไว้ในฐานข้อมูลหรือเขียนลงในไฟล์ในรูปแบบเช่น CSV, JSON หรือ Excel เพื่อการวิเคราะห์หรือประมวลผลเพิ่มเติม
- การล้างข้อมูลและการจัดรูปแบบ : ข้อมูลที่แยกออกมามักต้องมีการล้างและการแปลงเพื่อลบอักขระที่ไม่จำเป็น แก้ไขการจัดรูปแบบ หรือแปลงประเภทข้อมูล ขั้นตอนนี้มีความสำคัญอย่างยิ่งเพื่อให้แน่ใจว่าข้อมูลมีความถูกต้องและใช้งานได้
เครื่องมือใดใช้สำหรับการขูดเว็บ?
มีเครื่องมือและไลบรารีมากมายสำหรับการขูดเว็บ ซึ่งรองรับระดับความเชี่ยวชาญ ภาษาการเขียนโปรแกรม และความต้องการเฉพาะที่แตกต่างกัน ต่อไปนี้คือภาพรวมของเครื่องมือยอดนิยมบางส่วนที่ใช้สำหรับการขูดเว็บ:
ซุปที่สวยงาม
- ภาษา : หลาม
- การใช้งาน : ดีที่สุดสำหรับการแยกวิเคราะห์ HTML และ XML แบบธรรมดา และการดึงข้อมูลจากเว็บไซต์แบบคงที่
- คุณสมบัติ : ใช้งานง่ายสำหรับผู้เริ่มต้น มีประสิทธิภาพเมื่อรวมกับไลบรารีคำขอของ Python เพื่อดึงเนื้อหาเว็บ
ขูด
- ภาษา : หลาม
- ใช้ : เหมาะสำหรับการสร้างโปรแกรมรวบรวมข้อมูลเว็บที่ปรับขนาดได้และขูดเว็บไซต์ที่ซับซ้อน
- คุณสมบัติ : มอบกรอบการทำงานที่สมบูรณ์สำหรับการขูดและการรวบรวมข้อมูลเว็บ รองรับไปป์ไลน์รายการ การส่งออกข้อมูล และมิดเดิลแวร์สำหรับการจัดการสถานการณ์ที่แตกต่างกัน
ซีลีเนียม
- ภาษา : รองรับหลายภาษา รวมถึง Python, Java, C#, Ruby และ JavaScript
- การใช้งาน : ในตอนแรกออกแบบมาเพื่อทำให้เว็บเบราว์เซอร์ทำงานอัตโนมัติเพื่อการทดสอบ และยังใช้สำหรับคัดลอกเนื้อหาไดนามิกที่แสดงผลผ่าน JavaScript อีกด้วย
- คุณสมบัติ : สามารถควบคุมเว็บเบราว์เซอร์เพื่อเลียนแบบพฤติกรรมการท่องเว็บของมนุษย์ ทำให้สามารถดึงข้อมูลจากเว็บไซต์ที่ต้องเข้าสู่ระบบหรือโต้ตอบได้
นักเชิดหุ่น
- ภาษา : จาวาสคริปต์ (Node.js)
- การใช้งาน : เหมาะสำหรับการคัดลอกเว็บไซต์ไดนามิกและแอปพลิเคชันหน้าเดียวที่ต้องอาศัย JavaScript เป็นจำนวนมาก
- คุณลักษณะ : ให้ API ระดับสูงเพื่อควบคุม Chrome หรือ Chromium ผ่าน DevTools Protocol ช่วยให้ทำงานต่างๆ เช่น แสดงผล JavaScript ถ่ายภาพหน้าจอ และสร้าง PDF ของหน้าเว็บ
นักเขียนบทละคร
- ภาษา : Node.js, Python, C# และ Java
- การใช้งาน : คล้ายกับ Puppeteer แต่ออกแบบมาเพื่อรองรับเบราว์เซอร์หลายตัว (Chrome, Firefox และ WebKit)
- คุณสมบัติ : ดำเนินการเบราว์เซอร์โดยอัตโนมัติสำหรับการขูดเว็บ การทดสอบข้ามเบราว์เซอร์ และการจับภาพหน้าจอและวิดีโอ
ไชโย
- ภาษา : จาวาสคริปต์ (Node.js)
- การใช้งาน : เหมาะสำหรับการจัดการ DOM ฝั่งเซิร์ฟเวอร์ คล้ายกับ jQuery ช่วยให้สามารถคัดลอกเว็บไซต์แบบคงที่ได้อย่างรวดเร็วและมีประสิทธิภาพ
- คุณลักษณะ : แยกวิเคราะห์มาร์กอัปและจัดเตรียม API สำหรับการสำรวจ/จัดการโครงสร้างข้อมูลผลลัพธ์ เบากว่า Puppeteer สำหรับเนื้อหาคงที่
ออคโตพาร์ส
- ภาษา : N/A (เครื่องมือที่ใช้ GUI)
- การใช้งาน : เหมาะสำหรับผู้ที่ไม่ใช่โปรแกรมเมอร์หรือผู้ที่ชอบอินเทอร์เฟซแบบภาพมากกว่าการเขียนโค้ด
- คุณสมบัติ : อินเทอร์เฟซแบบชี้และคลิกเพื่อเลือกข้อมูลสำหรับการแยก จัดการเว็บไซต์ทั้งแบบคงที่และไดนามิก ให้บริการคลาวด์สำหรับโปรแกรมรวบรวมข้อมูลที่ทำงานอยู่
ParseHub
- ภาษา : N/A (เครื่องมือที่ใช้ GUI)
- การใช้งาน : ออกแบบมาสำหรับผู้ใช้ที่ไม่มีความรู้ด้านการเขียนโปรแกรมเพื่อขูดเว็บไซต์โดยใช้เครื่องมือภาพอันทรงพลัง
- คุณสมบัติ : รองรับเว็บไซต์ที่เน้น AJAX และ JavaScript พร้อมอินเทอร์เฟซที่ใช้งานง่ายสำหรับการเลือกจุดข้อมูลและส่งออกข้อมูล
วิธีการขูดเว็บที่แตกต่างกันมีอะไรบ้าง?
การขูดเว็บครอบคลุมวิธีการต่างๆ ในการดึงข้อมูลจากเว็บไซต์ ซึ่งแต่ละวิธีเหมาะสมกับเนื้อหาเว็บประเภทต่างๆ และความต้องการของผู้ใช้ ต่อไปนี้เป็นภาพรวมของวิธีการขูดเว็บที่ใช้กันทั่วไป:
คำขอ HTTP
วิธีการนี้เกี่ยวข้องกับการส่งคำขอ HTTP เพื่อดึงเนื้อหา HTML ของหน้าเว็บโดยตรง มีประสิทธิภาพสูงสุดสำหรับเว็บไซต์แบบคงที่ซึ่งเนื้อหาไม่ได้ขึ้นอยู่กับการทำงานของ JavaScript ไลบรารีเช่นคำขอใน Python และ HttpClient ใน .NET เป็นที่นิยมในการส่งคำขอ HTTP
ข้อดี : ง่ายและรวดเร็วสำหรับเนื้อหาคงที่
จุดด้อย : ไม่มีประสิทธิภาพสำหรับเนื้อหาแบบไดนามิกที่โหลดผ่าน JavaScript
การแยกวิเคราะห์ HTML
เมื่อคุณมีเนื้อหา HTML แล้ว การแยกวิเคราะห์ไลบรารี เช่น Beautiful Soup (Python), Cheerio (Node.js) หรือ Jsoup (Java) สามารถนำทางแผนผัง HTML DOM และแยกข้อมูลเฉพาะได้ วิธีการนี้เหมาะสำหรับการดึงข้อมูลจากเพจแบบสแตติกหรือซอร์ส HTML หลังจากเรียกใช้งาน JavaScript
ข้อดี : การแยกองค์ประกอบข้อมูลได้อย่างยืดหยุ่นและแม่นยำ
จุดด้อย : ต้องมีความเข้าใจโครงสร้างหน้าเว็บ
เบราว์เซอร์อัตโนมัติ
เครื่องมือต่างๆ เช่น Selenium, Puppeteer และ Playwright จะทำให้เว็บเบราว์เซอร์จริงทำงานโดยอัตโนมัติ ช่วยให้คุณสามารถคัดลอกเนื้อหาแบบไดนามิกที่ต้องใช้ JavaScript หรือการโต้ตอบกับเพจ (เช่น การคลิกปุ่ม การกรอกแบบฟอร์ม) เครื่องมือเหล่านี้สามารถเลียนแบบพฤติกรรมการท่องเว็บของมนุษย์ ทำให้มีประสิทธิภาพสำหรับงานขูดที่ซับซ้อน
ข้อดี : สามารถจัดการเว็บไซต์ไดนามิกที่เน้น JavaScript ได้
จุดด้อย : ต้องใช้ทรัพยากรมากขึ้นและช้ากว่าคำขอ HTTP โดยตรง
คำขอ API
เว็บไซต์หลายแห่งโหลดข้อมูลแบบไดนามิกผ่าน API ด้วยการตรวจสอบการรับส่งข้อมูลเครือข่าย (โดยใช้เครื่องมือเช่นแท็บเครือข่ายใน DevTools ของเบราว์เซอร์) คุณสามารถระบุตำแหน่งข้อมูล API และขอข้อมูลได้โดยตรง วิธีการนี้มีประสิทธิภาพและมักจะส่งคืนข้อมูลในรูปแบบที่มีโครงสร้างเช่น JSON
ข้อดี : รวดเร็วและมีประสิทธิภาพ ให้ข้อมูลที่มีโครงสร้าง
จุดด้อย : ต้องมีความเข้าใจเกี่ยวกับจุดสิ้นสุด API และอาจเกี่ยวข้องกับการตรวจสอบสิทธิ์
เบราว์เซอร์หัวขาด
เบราว์เซอร์ที่ไม่มีส่วนหัวก็เหมือนกับเบราว์เซอร์ทั่วไป แต่ไม่มีอินเทอร์เฟซผู้ใช้แบบกราฟิก เครื่องมืออย่าง Puppeteer และ Playwright สามารถทำงานในโหมดไม่มีหัว เรียกใช้งาน JavaScript และเรนเดอร์หน้าเว็บในเบื้องหลัง วิธีการนี้มีประโยชน์สำหรับการทดสอบอัตโนมัติและการคัดลอกเนื้อหาแบบไดนามิก
ข้อดี : การเรนเดอร์เนื้อหาไดนามิกเต็มรูปแบบ รวมถึงการทำงานของ JavaScript
จุดด้อย : คล้ายกับการทำงานอัตโนมัติของเบราว์เซอร์ คือใช้ทรัพยากรมากกว่าวิธีอื่นๆ
กรอบการขูดเว็บ
เฟรมเวิร์กเช่น Scrapy (Python) นำเสนอสภาพแวดล้อมที่ครบครันสำหรับการขูดเว็บ โดยให้คุณสมบัติในการดึงข้อมูล การติดตามลิงก์ และการจัดการข้อผิดพลาด เฟรมเวิร์กเหล่านี้ได้รับการออกแบบสำหรับการสร้างโปรแกรมรวบรวมข้อมูลเว็บที่ปรับขนาดได้และจัดการงานขูดหลายรายการพร้อมกัน
ข้อดี : โซลูชันที่ครอบคลุมพร้อมคุณสมบัติในตัวสำหรับโครงการขูดที่ซับซ้อน
จุดด้อย : อาจมีช่วงการเรียนรู้ที่สูงชันสำหรับผู้เริ่มต้น
การรู้จำอักขระด้วยแสง (OCR)
สำหรับการคัดลอกข้อมูลจากรูปภาพหรือเอกสารที่สแกน เทคโนโลยี OCR เช่น Tesseract สามารถแปลงการแสดงข้อความด้วยภาพให้เป็นข้อความที่เครื่องอ่านได้ วิธีนี้มีประโยชน์อย่างยิ่งในการดึงข้อมูลจาก PDF รูปภาพ หรือ captcha
ข้อดี : เปิดใช้งานการแยกข้อความจากรูปภาพและเอกสารที่สแกน
จุดด้อย : อาจส่งผลให้เกิดความไม่ถูกต้องกับรูปภาพคุณภาพต่ำหรือรูปแบบที่ซับซ้อน