
Лучшие сообщения из блога PromptCloud, опубликованные в 2018 году
Опубликовано: 2018-12-26Мы уже в сумерках этого года, и это идеальное время для нас, чтобы оглянуться на то, что мы создали. Кроме того, стоит отметить, что во время закрытия года списки лучших гарантируют, что люди ничего не упустят.
Итак, эта подборка представляет вам 10 самых популярных статей, связанных с веб-данными, размещенных в нашем блоге. Это поможет вам, если что-то проскользнуло.
Не теряя времени, приступим.
Стратегия очистки и оптимизации цен на отели
Мы начали год с интересного решения для гостиничных сетей, которые хотели поддерживать конкурентоспособные цены и в то же время оставаться прибыльными. Мы говорили о разработке стратегии ценообразования на основе трех основных факторов — прогнозирования спроса, оценки реакции рынка и анализа конкуренции. Все эти факторы имеют несколько подфакторов, которые будут взвешены при моделировании цен с учетом различных ограничений.
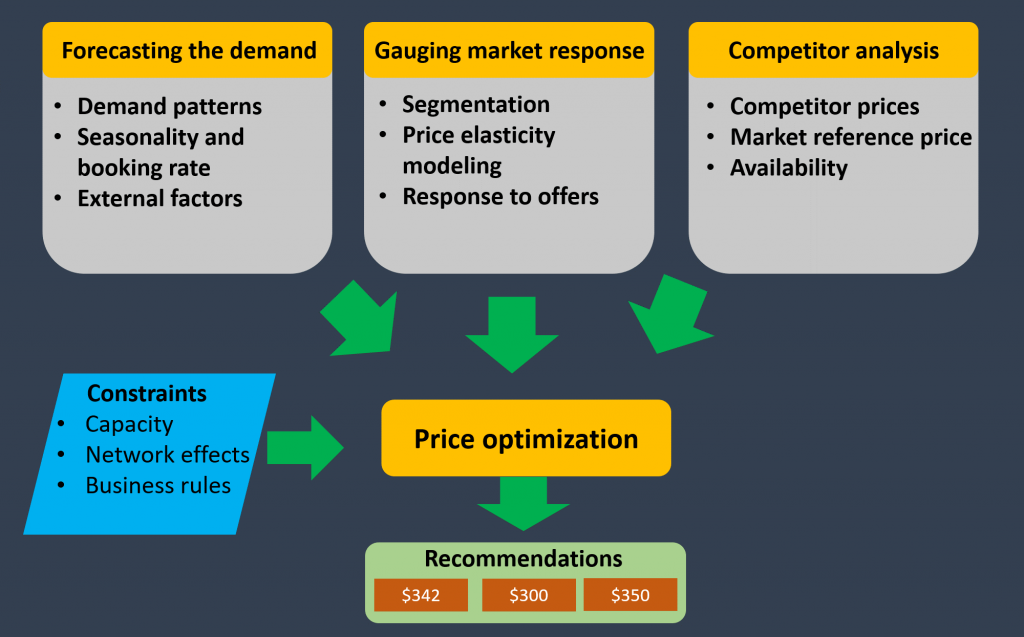
Наконец, сочетание этих моделей с уникальными преимуществами гостиничного бизнеса позволило бы выявить цены, привлекательные для клиентов.
Визуализация комментариев YouTube к трейлерам фильмов, номинированных на «Оскар»
В этом посте мы провели интересное исследование в сфере развлечений и сосредоточились на Оскаре, поскольку именно об этом говорили все вокруг. Мы извлекли комментарии YouTube из трейлеров фильмов, номинированных на «Оскар», и создали визуализацию.
Вот что мы проанализировали:
- Популярность фильмов на основе количества комментариев
- Распределение длины обзора
- Основные термины, используемые в обзорах
- Анализ настроений
- Связь между словами - сетевой граф биграмм
- Облако слов, чтобы найти наиболее часто встречающиеся слова в комментариях к трейлеру «Форма воды».

Вот что мы обнаружили:
- Популярность фильма напрямую не связана с победой или номинацией.
- «Форма воды» вызвала неоднозначные комментарии
- Номинация на «Оскар» может изменить восприятие фильма зрителями
Как убедить своего босса собирать веб-данные
Затем мы решили помочь вам убедить вашего босса собирать веб-данные для повышения производительности и эффективности вашей компании. Мы сосредоточились на том, что вы могли бы использовать в своем арсенале, и придумали несколько важных моментов. Вы могли бы объяснить, как вы могли бы -
- Используйте данные, чтобы лучше ориентироваться на клиентов.
- Преобразуйте неиспользуемые данные из пассива в ценный актив.
- Топливная инновация.
- Ускорьте принятие решений.
- Повысить общую эффективность.
Все с использованием данных веб-скрапинга!
Неизбежный священный брак машинного обучения и парсинга веб-страниц
К середине года, когда все ели торт с надписью «Машинное обучение», мы решили сделать этот кусок. Сначала мы обсудили веб-скрапинг, затем машинное обучение, а затем фактически объяснили, что вместо человека, который постоянно придумывает новые правила для парсинга, машина может поддерживать работу парсера.

Первоначально потребуется фаза обучения в течение некоторого времени, когда настоящий человек будет поддерживать работу скребка и вознаграждать или наказывать его в зависимости от его действий, чтобы заставить его учиться и переучиваться.
Помогает ли искусственный интеллект быстрому росту моды?
Быстрая мода — это современный термин, используемый розничными торговцами модной одеждой для обозначения того, что модели быстро перемещаются с подиума, чтобы отразить текущие модные тенденции. И в настоящее время в мире моды простые алгоритмы, подсказывающие тренды, устарели. Команда данных и команда дизайнеров используют продвинутый ИИ для точной настройки предложения — от выбора цвета и материала до полос и аксессуаров. Мы знаем это, так как в настоящее время мы ежедневно предоставляем миллионы данных о моде для поддержки некоторых поставщиков ИИ, ориентированных на моду.

Выяснение того, что понравится покупателям в следующем сезоне, оказывается делом математических решений в сочетании с творческим подходом дизайнеров.

Визуализация данных и анализ текстов песен Тейлор Свифт
Анализ данных может быть применен к творческим областям, таким как «музыка», чтобы выяснить основную тему и меняющуюся тенденцию с годами. Итак, это исследование было сосредоточено на Тейлор Свифт, которая получила множество наград.
На ее 94 треках был проведен анализ, чтобы создать несколько увлекательных диаграмм и графиков.
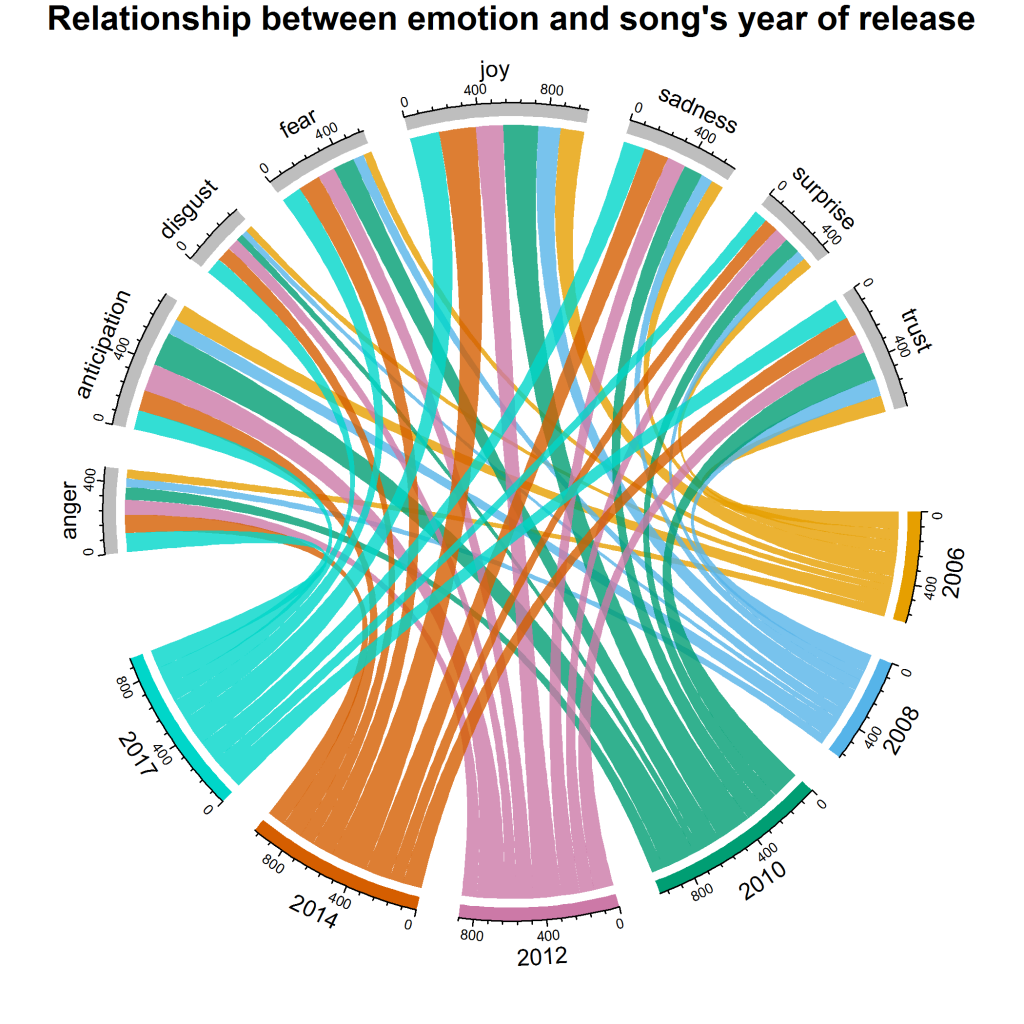
Вот краткий обзор:
- Исследовательский анализ — мы провели анализ количества слов на основе отдельных треков и альбомов, анализ временных рядов количества слов, а также распределение количества слов.
- Интеллектуальный анализ текста. Здесь мы построили облако слов, используя все песни, которые мы исследовали. Мы также создали сеть биграмм и выполнили различные типы анализа настроений.
Этот набор данных доступен в Datastock , чтобы вы могли поиграть с ним!
Что нужно знать о парсинге данных IoT
Одним из модных словечек года был IoT (Интернет вещей), и мы решили объяснить возможности, которые кроются в этой области. Хотя веб-скрейпинг еще не является популярной средой для сбора данных, веб-скрапинг может помочь многое понять о различных устройствах IoT — как происходит взаимодействие, какие данные могут быть подвержены взлому и т. д. поскольку их точки подключения могут предоставить огромные возможности для людей, желающих проанализировать всю экосистему IoT и создать новые и более эффективные бизнес-процессы.
Парсинг в эпоху GDPR — влияние и возможности
Когда такие гиганты, как Facebook и Google, попали под сканер из-за проблем с конфиденциальностью и безопасностью данных, в Европе вступил в силу GDPR или Общий регламент по защите данных. Это вынудило многие компании изменить операционные процедуры, хранение данных и обработку рабочих процессов, а в некоторых случаях даже пересмотреть всю инфраструктуру.
Тем не менее, этот много обсуждаемый законодательный орган также привел к множеству запретов и возможностей в области веб-скрейпинга. В этой статье мы углубимся в то, какие изменения вступят в силу для парсинга данных компаний и частных лиц.
Анализ данных выявил самый жуткий город в США
В течение месяца Хэллоуина мы решили пойти с жуткими духами и написать статью, в которой мы проанализировали различные города США на основе количества мест с привидениями, которые в них были.
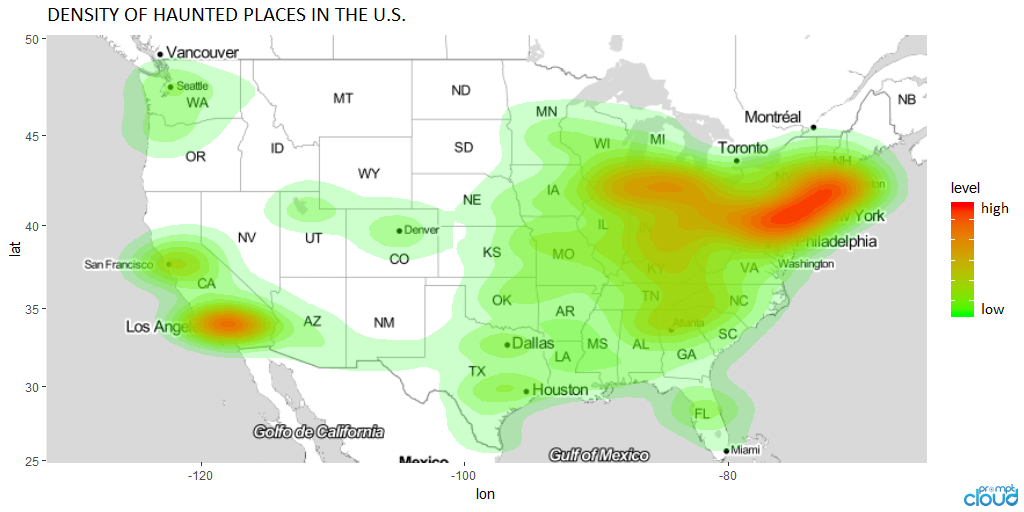
Мы создали частотную диаграмму по штатам и городам, а также тепловую карту США, чтобы убедиться, что вы знаете, каковы шансы вас напугать. Анализ карты слов также помог понять, как люди описывают жуткие места и какие слова чаще встречаются в описании этих мест.
Почему веб-скрейпинг — лучшая альтернатива API?
Одну из самых обсуждаемых статей мы оставили на конец года (надеясь, что людям будет веселее от праздничного настроения). Подходя к сути, если вы использовали API для своих нужд данных, вы должны знать, насколько легко их использовать; все, что вам нужно сделать, это передать некоторые параметры, и вы получите в ответ JSON/XML, который затем сможете использовать.

Функциональные возможности API обычно не меняются часто, и даже если незначительное изменение произойдет, вы получите обновленную документацию для него. Итак, лучше ли это, чем веб-скрейпинг? Что ж, как вы, возможно, слышали, проще не всегда лучше. Прочтите эту статью на конец года, чтобы узнать больше.
На этом мы завершаем обзор статей за 2018 год, которые вы должны прочитать. Комментарий, если вы хотите, чтобы в этом списке была какая-то другая статья из нашего блога!
