
Aprendizado de máquina versus análise preditiva: diferença e uso
Publicados: 2021-01-12Aprendizado de máquina
O aprendizado de máquina é uma técnica computacional na qual diferentes algoritmos podem ser usados para gerar modelos a partir de dados em tempo real. Esses modelos são então usados para produzir resultados consumíveis a partir de novos dados. À medida que mais dados são inseridos no sistema com o tempo, o modelo evolui automaticamente com base em seus novos aprendizados. O Machine Learning requer grandes quantidades de dados para funcionar bem e fornecer resultados mais precisos. O crescimento dos dados, gerados a partir de fontes como IoT e web scraping, ajudou a impulsionar o Machine Learning.
Embora você possa, teoricamente, executar qualquer algoritmo em qualquer conjunto de dados, para obter os melhores resultados, o tipo e o formato dos dados precisam ser avaliados primeiro. O aprendizado de máquina permite o processamento de dados em tempo real, e a maioria dos modelos consome um fluxo contínuo de dados e cresce por conta própria.
O termo Machine Learning pode ser usado tanto para aprendizado supervisionado quanto para aprendizado não supervisionado. No aprendizado supervisionado – o conjunto de dados é marcado e o modelo é o primeiro a ser executado nos dados marcados para aprender com eles. Em seguida, ele é executado em dados não marcados, para produzir previsões. No caso de aprendizado não supervisionado, todos os dados não são marcados e os algoritmos geralmente usam diferentes pontos de dados para encontrar padrões, semelhanças e diferenças no conjunto de dados. Você pode entender a diferença através de um caso de uso de cada um:
uma). No Aprendizado Supervisionado, você pode treinar sua máquina em imagens rotuladas de cães e gatos e, uma vez treinado, você pode inserir imagens não rotuladas de gatos e cães e testar os recursos preditivos da máquina.
b). No aprendizado não supervisionado, você forneceria várias imagens não rotuladas de cães e gatos e testaria se a máquina pode separá-los.
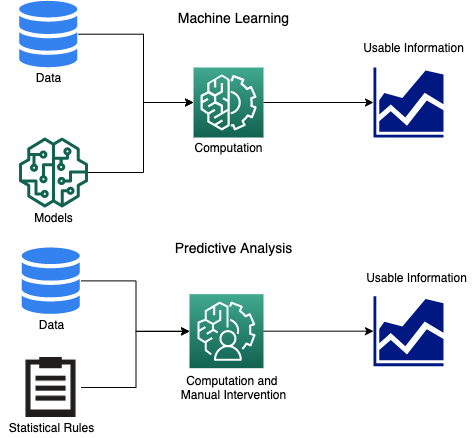
Análise Preditiva
O uso da Análise Preditiva existe muito antes do início da IA ou mesmo do crescimento das máquinas computacionais modernas. Envolve a compactação de grandes quantidades de dados que serão mais legíveis por humanos. Em sua forma mais simples, pode calcular médias, contagens ou medianas. Geralmente é usado para encontrar uma resposta para uma pergunta específica, como:
uma). Quais são as categorias mais vendidas em sites de comércio eletrônico no inverno?
b). Quais são as palavras-chave que podem ser incluídas em um artigo para garantir que ele alcance um grande público?
Embora envolva o estudo de dados históricos e atuais, o estresse está principalmente em um grande conjunto de dados históricos e não pode ser usado em um fluxo contínuo de dados. Qualquer Análise Preditiva combina três componentes principais:
uma). Dados: A qualidade, quantidade e amplitude dos dados definirão o sucesso de uma Análise Preditiva. Caso os dados fiquem aquém em qualquer uma dessas 3 frentes, é provável que vejamos um resultado tendencioso.
b). Suposições: Mesmo antes de um estudo ser realizado, há certas suposições feitas sobre os dados disponíveis. Por exemplo, se você está calculando as vendas acumuladas dos últimos 10 anos para descobrir o possível crescimento no ano atual, está assumindo que as métricas de crescimento seguirão o mesmo padrão.
c). Técnicas Estatísticas: Técnicas de aprendizado estatístico, como regressão e árvores de decisão, formam a computação central necessária para consumir os dados disponíveis e, portanto, entender essas técnicas é essencial antes de lidar com os dados.
Qual é melhor?
Tanto o Machine Learning quanto a Análise Preditiva são técnicas computacionais e ambas são executadas em máquinas hoje. Seria difícil afirmar qual é o melhor, pois ambos tratam de declarações de problemas diferentes. No entanto, podemos discutir alguns dos prós e contras de cada um.
O aprendizado de máquina é uma ciência mais avançada e pode ser usado em praticamente qualquer tipo de dados, seja imagens de satélite ou um conjunto de dados de detalhes do aluno. A quantidade de dados que você alimenta para um modelo de Machine Learning e sua limpeza juntos determinam o desempenho do seu modelo na vida real.
O Predictive Analytics é mais adequado para declarações de problemas em que você já tem uma pergunta e um breve entendimento de onde os dados podem levá-lo. Geralmente é guiado por dados históricos. No entanto, nos casos em que esses dados não estiverem disponíveis, ou se as tendências históricas não corresponderem aos dados atuais, devido a certos desvios, eles podem se mostrar inutilizáveis.
| Aprendizado de máquina | Análise Preditiva |
| Usa modelos de algoritmo, que são criados usando dados de treinamento | Usa um conjunto de regras predefinidas que podem ser atualizadas |
| Pode se adaptar automaticamente e aprender com novos dados | Geralmente precisa ser ajustado para lidar com casos extremos e alterações |
| Você pode usar um dos algoritmos pré-existentes que melhor se adapte aos dados disponíveis | Você precisa escrever o código para seu caso de uso específico |
| Ele pode ser executado sem dados históricos, pois também pode ser executado em uma transmissão ao vivo de dados | Os dados históricos são necessários antes de criar um conjunto de regras |
| Solução orientada a dados | Solução baseada em casos de uso |
| Modelos de Machine Learning podem levar mais tempo para ficarem prontos | Os modelos de análise preditiva podem estar prontos para testes muito mais rápidos |
Tabela: Análise Preditiva vs Aprendizado de Máquina

Como a Análise Preditiva envolve o estudo de dados históricos, inferências ou modelos podem ser gerados rapidamente e aplicados aos dados atuais. Por outro lado, os modelos de Machine Learning geralmente precisam treinar em um fluxo de dados por um período prolongado para poder lidar com casos extremos e melhorar sua precisão.
A desvantagem é a incapacidade do modelo Predictive Analytics de se adaptar às variações nos fluxos de dados. Desvios nos dados podem inutilizar um modelo do Predictive Analytics e a equipe de dados precisaria voltar para a tabela para fazer algumas alterações manuais. Os modelos de aprendizado de máquina, ao treinar em um fluxo de dados diversificado e contínuo, podem se adaptar facilmente às alterações ou desvios presentes nos dados.
A sobreposição
A melhoria das previsões e a adaptação em tempo real são incorporadas ao design dos modelos de Machine Learning. Por outro lado, o Predictive Analytics funciona em um conjunto de dados estático, e qualquer alteração no conjunto de dados requer a recalibração de diferentes parâmetros. A principal diferença está no fato de que a intervenção humana é invocada para interpretar os resultados e associações no caso de Predictive Analytics.
No entanto, em certos casos, a Análise Preditiva pode pegar carona no Machine Learning para gerar resultados mais precisos – e nesse cenário pode se tornar um subconjunto do Machine Learning. Se você já tem uma declaração de problema específica, mas não tem certeza sobre a direção, o Machine Learning pode produzir insights úteis. Em um processo diferente, o Machine Learning também pode ser usado para processar os dados brutos e produzir um conjunto de dados mais consumível que pode ser usado para Análise Preditiva.
No entanto, em certos casos, a Análise Preditiva pode pegar carona no Machine Learning para gerar resultados mais precisos – e nesse cenário pode se tornar um subconjunto do Machine Learning. Se você já tem uma declaração de problema específica, mas não tem certeza sobre a direção, o Machine Learning pode produzir insights úteis. Em um processo diferente, o Machine Learning também pode ser usado para processar os dados brutos e produzir um conjunto de dados mais consumível que pode ser usado para Análise Preditiva.
Quais são os Casos de Uso?
UMA). Campanhas de marketing
As campanhas de marketing se tornaram digitais em uma tentativa de aumentar as taxas de conversão e reduzir os gastos. As campanhas de marketing direcionadas geralmente usam a Análise Preditiva para consumir dados do passado, bem como dados de campanhas realizadas por outras empresas. As empresas também usam dados demográficos do usuário, como localização, idade, sexo, estado civil, data de nascimento, para apresentar produtos ao cliente certo no momento certo.
O histórico de pesquisa anterior e os padrões de compra também são usados para decidir quais produtos mostrar aos clientes. Dessa forma, dois clientes não veem os mesmos produtos na página inicial.
B). Gerenciamento de armazenagem
Grandes empresas de comércio eletrônico usam informações relacionadas ao histórico de pesquisa e padrões de compra anteriores para decidir quais itens manter em qual depósito, especialmente quando têm vários depósitos espalhados por cidades ou países. Essas otimizações não apenas reduzem o custo para a empresa, mas também garantem que os prazos de entrega dos produtos sejam mais curtos para os clientes.
O aprendizado de máquina teve um crescimento rápido e algoritmos como redes neurais tiveram usos importantes, como detecção de células cancerígenas e previsão de vendas. Alguns dos principais casos de uso do Machine Learning hoje incluem:
uma). Reconhecimento de Imagem
b). Reconhecimento de fala
c). Previsão de tráfego
d). Bots autônomos
e). Filtragem de spam e malware
f). Assistentes virtuais
g). Detecção de fraude
h). Diagnóstico médico
Onde você pode obter os dados?
Normalmente, a mesma equipe de Data Science de uma empresa de tecnologia trabalha em Machine Learning e Análise Preditiva e aplica qualquer um deles com base na declaração do problema em mãos. Não importa qual processo é aplicado, nada pode ser alcançado sem os dados corretos.
O Web Scraping é uma das maneiras mais populares de coletar dados hoje e os provedores de DaaS, como o PromptCloud, ajudam seus clientes a obter os dados certos para diferentes tipos de objetivos. Nossa equipe faz da coleta de dados um processo de duas etapas – você nos fornece os requisitos e nós fornecemos os dados. Não importa qual algoritmo você usa e qual tecnologia você utiliza, nosso feed de dados limpo pode capacitar sua empresa a ficar à frente da curva.