
Jak korzystać z raportu dotyczącego indeksu Google Search Console
Opublikowany: 2021-12-28Pokrycie indeksu to raport w Google Search Console, który pokazuje stan przeszukiwania i indeksowania wszystkich adresów URL wykrytych przez Google dla Twojej witryny.
Pomaga śledzić stan indeksowania witryny i informuje o problemach technicznych uniemożliwiających prawidłowe indeksowanie i indeksowanie stron.
Regularne sprawdzanie raportu Pokrycie indeksu pomoże Ci wykryć i zrozumieć problemy oraz dowiedzieć się, jak je rozwiązać.
W tym artykule opiszę:
- Co to jest raport Pokrycie indeksu,
- Kiedy i jak z niego korzystać,
- Statusy wyświetlane w raporcie, w tym rodzaje problemów, ich znaczenie i sposoby ich naprawy.
Kiedy wprowadzono raport dotyczący pokrycia indeksu?
Google przedstawił raport Pokrycie indeksu w styczniu 2018 r. , kiedy zaczął udostępniać odnowioną wersję Search Console dla wszystkich użytkowników .
Oprócz pokrycia indeksu ulepszona Search Console zawierała inne cenne raporty:
- Raport skuteczności wyszukiwania,
- Raporty o ulepszeniach w wyszukiwarce: stanach AMP i stronach z ofertami pracy.
Google powiedział, że przeprojektowanie Google Search Console było motywowane opiniami użytkowników. Celem było:
- Dodaj więcej praktycznych informacji,
- wspierać współpracę różnych zespołów korzystających z narzędzia,
- Oferuj szybsze pętle zwrotne między Google a witrynami użytkowników.
Aktualizacja raportu Pokrycie indeksu w 2021 r.
W styczniu 2021 r. firma Google ulepszyła raport Pokrycie indeksów , aby zgłaszane problemy z indeksowaniem były dokładniejsze i bardziej zrozumiałe dla użytkowników.
Zmiany w raporcie polegały na:
- Usunięcie ogólnego problemu „anomalii indeksowania”,
- Tworzenie stron, które zostały przesłane, ale zablokowane przez plik robots.txt i zostały zindeksowane, zgłaszane jako „zindeksowane, ale zablokowane” (w ostrzeżeniach) zamiast „przesłane, ale zablokowane” (błąd),
- Dodanie problemu o nazwie „indeksowane bez treści” (do ostrzeżeń),
- Zwiększenie dokładności raportowania miękkich problemów 404.
Potok indeksowania Google
Zanim zagłębimy się w szczegóły raportu, omówmy kroki, jakie musi podjąć Google, aby zindeksować i ostatecznie uszeregować strony internetowe.
Aby strona została sklasyfikowana i pokazana użytkownikom, musi zostać wykryta, zindeksowana i zindeksowana.
Odkrycie
Google musi najpierw odkryć stronę, aby móc ją zaindeksować.
Odkrycie może nastąpić na kilka sposobów.
Najczęstsze z nich to śledzenie przez Googlebota wewnętrznych lub zewnętrznych linków do strony lub znajdowanie jej za pomocą mapy witryny XML , która jest plikiem zawierającym listę i porządkujących adresy URL w Twojej domenie.
Pełzanie
Indeksowanie polega na tym, że wyszukiwarki przeglądają strony internetowe i analizują ich zawartość.
Istotnym aspektem indeksowania jest budżet indeksowania , czyli ilość czasu i zasobów, które wyszukiwarki mogą i chcą przeznaczyć na indeksowanie Twojej witryny. Wyszukiwarki mają ograniczone możliwości indeksowania i mogą indeksować tylko część stron w witrynie. Przeczytaj więcej o optymalizacji budżetu indeksowania.
Indeksowanie
Podczas indeksowania Google ocenia strony i dodaje je do indeksu – bazy danych wszystkich stron internetowych, z której Google może korzystać do generowania wyników wyszukiwania. Ten etap obejmuje również renderowanie , które pomaga Google zobaczyć układ i treść stron. Informacje zbierane przez Google na temat strony pomagają zdecydować, jak wyświetlać ją w wynikach wyszukiwania.
Ale tylko dlatego, że Google może znaleźć i zaindeksować Twoją stronę, nie oznacza, że zostanie ona zaindeksowana.
Indeksowanie przez Google staje się coraz bardziej skomplikowane. Dzieje się tak głównie dlatego, że sieć się rozwija, a strony internetowe stają się coraz cięższe.
Ale tutaj jest kluczowy aspekt indeksowania, o którym należy pamiętać: nie powinieneś indeksować wszystkich swoich stron.
Zamiast tego upewnij się, że indeks zawiera tylko Twoje strony z wysokiej jakości treścią cenną dla użytkowników. Niektóre strony mogą zawierać treści o niskiej jakości lub zduplikowane, a jeśli wyszukiwarki je zobaczą, może to negatywnie wpłynąć na to, jak postrzegają Twoją witrynę jako całość.
Dlatego ważne jest, aby stworzyć strategię indeksowania i zdecydować, które strony powinny, a które nie powinny być indeksowane. Przygotowując strategię indeksowania, możesz zoptymalizować budżet indeksowania, podążać za jasnym celem indeksowania i odpowiednio naprawiać wszelkie problemy.
Jeśli chcesz dowiedzieć się więcej o indeksowaniu, zacznij od zapoznania się z naszym przewodnikiem po indeksowaniu SEO.
Zaszeregowanie
Zaindeksowane strony mogą być klasyfikowane i pojawiać się w wynikach wyszukiwania dla odpowiednich zapytań.
Google decyduje o tym, jak pozycjonować strony na podstawie wielu czynników rankingowych, takich jak ilość i jakość linków, szybkość strony, przyjazność dla urządzeń mobilnych, trafność treści i wiele innych.
Jak korzystać z raportu Pokrycie indeksu?
Aby przejść do raportu Pokrycie indeksu, zaloguj się na swoje konto Google Search Console. Następnie w menu po lewej stronie wybierz „Pokrycie” w sekcji Indeks:
Zobaczysz wtedy raport. Zaznaczając każdy lub wszystkie statusy, możesz wybrać, co chcesz wizualizować na wykresie:

Raport pokaże adresy URL, które odpowiadają w następujących czterech stanach, związanych z różnymi problemami napotkanymi przez Google na określonych stronach:
- Błąd – krytyczne problemy podczas przeszukiwania lub indeksowania.
- Prawidłowe z ostrzeżeniami — adresy URL, które są zindeksowane, ale zawierają kilka niekrytycznych błędów.
- Prawidłowy — adresy URL, które zostały poprawnie zindeksowane.
- Excluded – strony, które nie zostały zaindeksowane z powodu problemów – to najważniejsza sekcja, na której należy się skupić.
„Wszystkie przesłane strony” a „Wszystkie znane strony”
W lewym górnym rogu możesz wybrać, czy chcesz wyświetlić „Wszystkie znane strony”, co jest opcją domyślną, pokazującą adresy URL wykryte przez Google w dowolny sposób, czy „Wszystkie przesłane strony”, w tym tylko adresy URL przesłane w mapie witryny.
Powinieneś zauważyć wyraźną różnicę między stanem „Wszystkie przesłane strony” a „Wszystkie znane strony” – „Wszystkie znane strony” zwykle zawierają więcej adresów URL i więcej z nich jest zgłaszanych jako wykluczone. Dzieje się tak, ponieważ mapy witryn powinny zawierać tylko indeksowane adresy URL, podczas gdy większość witryn zawiera wiele stron, które nie powinny być indeksowane. Jednym z przykładów są adresy URL z parametrami śledzenia w witrynach eCommerce. Boty wyszukiwarek, takie jak Googlebot, mogą znajdować te strony na różne sposoby, ale nie powinny ich znajdować w mapie witryny.
Dlatego zawsze bądź uważny podczas otwierania raportu Pokrycie indeksu i upewnij się, że patrzysz na dane, które Cię interesują.
Sprawdzanie statusów adresów URL
Aby zobaczyć szczegóły problemów znalezionych dla każdego ze stanów, spójrz poniżej wykresu:

W tej sekcji wyświetlany jest stan, konkretny typ problemu i liczba stron, których dotyczy problem.
Możesz również zobaczyć stan walidacji – po naprawieniu problemu możesz poinformować Google, że problem został rozwiązany i poprosić o weryfikację poprawki.
Jest to możliwe na górze raportu po kliknięciu w problem:
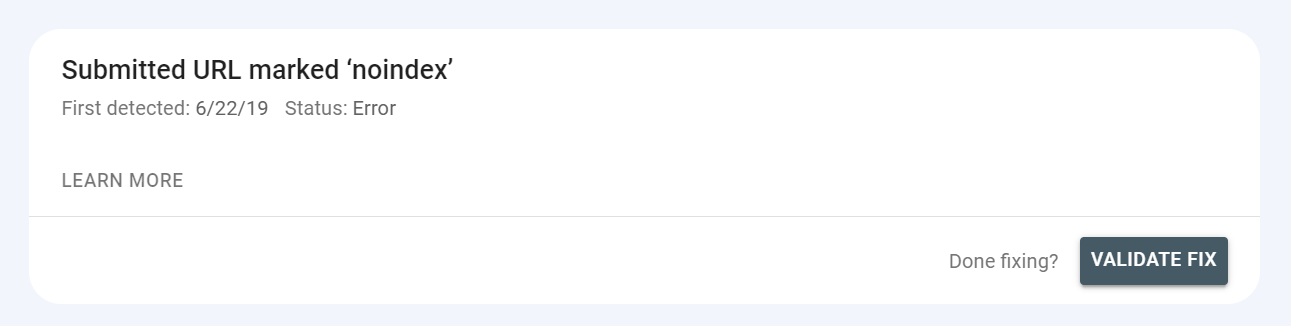
Status walidacji może być wyświetlany jako „naprawiony”. Ale może również pokazywać „niepowodzenie” lub „nie rozpoczęto” – powinieneś priorytetowo rozwiązać problemy, które odpowiadają tym statusom.
Możesz także zobaczyć trend dla każdego statusu – czy liczba adresów URL rośnie, spada, czy utrzymuje się na tym samym poziomie.
Po kliknięciu jednego z typów zobaczysz, które adresy URL odpowiadają na ten problem. Ponadto możesz sprawdzić, kiedy każdy adres URL był ostatnio indeksowany – jednak informacje te nie zawsze są aktualne ze względu na możliwe opóźnienia w raportach Google.
Dostępny jest również wykres przedstawiający daty i zmiany w czasie.
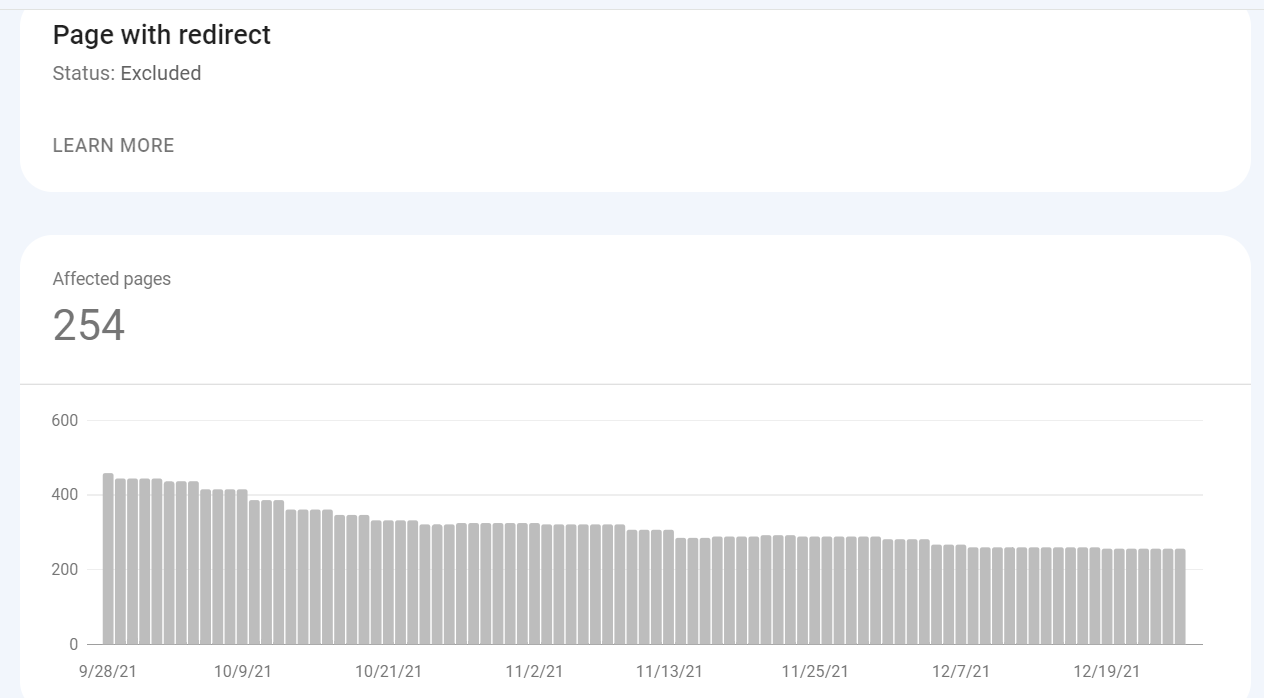
Oto kilka ważnych kwestii, o których należy pamiętać podczas korzystania z raportu:
- Zawsze sprawdzaj, czy przeglądasz wszystkie przesłane strony, czy wszystkie znane strony. Różnica między stanem stron w mapie witryny a wszystkimi stronami odkrytymi przez Google może być bardzo wyraźna.
- Raport może pokazywać zmiany z opóźnieniem, więc za każdym razem, gdy publikujesz nową zawartość, daj jej co najmniej kilka dni na przeszukanie i zindeksowanie.
- Google będzie wysyłać Ci powiadomienia e-mail o wszelkich szczególnie palących problemach napotkanych w Twojej witrynie.
- Twoim celem powinno być zindeksowanie kanonicznych wersji stron, które mają znaleźć użytkownicy i boty.
- Wraz z rozwojem witryny i tworzeniem większej ilości treści, spodziewaj się wzrostu liczby zindeksowanych stron w raporcie.
Jak często należy sprawdzać raport?
Należy regularnie sprawdzać raport Pokrycie indeksów, aby wykryć wszelkie błędy podczas przeszukiwania i indeksowania stron. Generalnie staraj się sprawdzać raport przynajmniej raz w miesiącu.
Jeśli jednak wprowadzisz jakiekolwiek znaczące zmiany w swojej witrynie, takie jak dostosowanie układu, struktury adresów URL lub przeprowadzenie migracji witryny, monitoruj wyniki częściej, aby wykryć jakikolwiek negatywny wpływ. Następnie zalecam odwiedzanie raportu przynajmniej raz w tygodniu i zwracanie szczególnej uwagi na status Wykluczone .
Narzędzie do sprawdzania adresów URL
Zanim zagłębię się w szczegóły każdego stanu w raporcie Pokrycie indeksu, chciałbym wspomnieć o jeszcze jednym narzędziu w Search Console, które zapewni cenny wgląd w zindeksowane lub zindeksowane strony.
Narzędzie do sprawdzania adresów URL zawiera szczegółowe informacje o wersji strony zindeksowanej przez Google.
Możesz go znaleźć w Google Search Console w pasku wyszukiwania u góry strony.
Po prostu wklej adres URL, który chcesz sprawdzić – zobaczysz wtedy następujące dane:
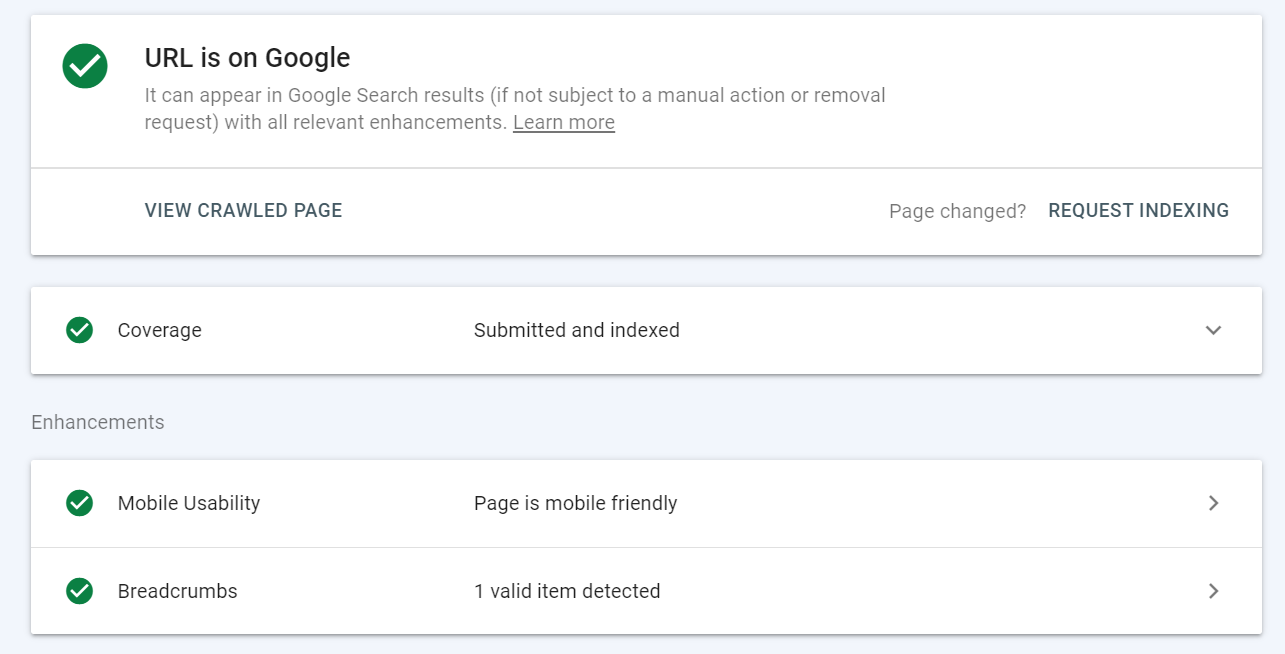
Możesz użyć narzędzia do sprawdzania adresów URL, aby:
- Sprawdź stan indeksowania adresu URL, a w przypadku problemów sprawdź, co to jest i rozwiąż je,
- Dowiedz się, czy adres URL jest indeksowalny,
- Wyświetl wyrenderowaną wersję adresu URL,
- Żądaj indeksowania adresu URL – np. jeśli strona się zmieniła,
- Zobacz załadowane zasoby, takie jak JavaScript,
- Zobacz, do jakich ulepszeń może odpowiadać adres URL – np. na podstawie implementacji danych strukturalnych i tego, czy strona jest przyjazna dla urządzeń mobilnych.
Jeśli napotkasz jakiekolwiek problemy w raporcie Pokrycie indeksu, użyj narzędzia do sprawdzania adresów URL, aby je zweryfikować i przetestować adresy URL, aby lepiej zrozumieć, co należy naprawić.
Statusy w raporcie Pokrycie indeksu i rodzaje problemów
Czas przyjrzeć się każdemu z czterech stanów w raporcie i:
- Omów konkretne typy problemów, które mogą pokazać,
- Co powoduje te problemy i
- Jak powinieneś się do nich zwracać.
Błąd
Sekcja błędów zawiera adresy URL, które nie zostały zindeksowane z powodu błędów napotkanych przez Google.
Za każdym razem, gdy zobaczysz problem zawierający „Przesłane”, dotyczy on adresów URL, które zostały przesłane do indeksowania, co zazwyczaj odbywa się za pomocą mapy witryny, i w ten sposób Google je odkrył. Upewnij się, że mapa witryny zawiera tylko adresy URL, które chcesz zindeksować.

Błąd serwera (5xx)
Jak wskazuje nazwa, odnosi się to do błędów serwera z kodami stanu 5xx , takimi jak 502 Bad Gateway lub 503 Usługa niedostępna.
Należy regularnie monitorować tę sekcję, ponieważ Googlebot będzie miał problemy z indeksowaniem stron z błędami serwera. Może być konieczne skontaktowanie się z administratorem serwera, aby naprawić te błędy lub sprawdzić, czy nie są one spowodowane przez ostatnie aktualizacje lub zmiany w Twojej witrynie.
Sprawdź sugestie Google, jak naprawić błędy serwera.
Błąd przekierowania
Przekierowania przenoszą boty wyszukiwarek i użytkowników ze starego adresu URL na nowy. Są one zwykle implementowane, gdy stare adresy URL ulegają zmianie lub ich zawartość już nie istnieje.
Błędy przekierowania wskazują na następujące problemy:
- Łańcuch przekierowań (który występuje w przypadku wielu przekierowań między adresami URL) jest zbyt długi,
- Pętla przekierowań – adresy URL przekierowują do siebie,
- URL przekierowania, który przekroczył maksymalną długość adresu URL,
- W łańcuchu przekierowań znaleziono błędny lub pusty adres URL.
Sprawdź i napraw przekierowania dla każdego adresu URL, którego dotyczy problem – jeśli nie masz pewności, od czego zacząć, postępuj zgodnie z moim przewodnikiem po przekierowaniach.
Przesłany adres URL zablokowany przez plik robots.txt
Te adresy URL zostały przesłane w mapie witryny, ale są zablokowane w pliku robots.txt. Robots.txt to plik zawierający instrukcje, jak roboty powinny indeksować Twoją witrynę. Jeśli ten adres URL powinien zostać zaindeksowany, Google musi go najpierw zaindeksować, więc przejdź do pliku robots.txt i dostosuj dyrektywy.
Przesłany adres URL oznaczony jako „noindex”
Podobnie jak w przypadku poprzedniego błędu, te strony zostały przesłane do zindeksowania, ale są blokowane przez tag lub nagłówek noindex w odpowiedzi HTTP . „Noindex” zapobiega indeksowaniu strony — jeśli adresy URL, których dotyczy problem, powinny być indeksowane, usuń dyrektywę noindex.
Przesłany adres URL wydaje się być miękkim 404
Miękki błąd 404 oznacza, że strona zwraca status 200 OK, ale jej zawartość sprawia, że wygląda na błąd , np. dlatego, że jest pusta lub zawiera słabą treść. Przejrzyj strony z tym błędem i sprawdź, czy istnieje sposób na zmianę ich zawartości lub przekierowanie.
Przesłany adres URL zwraca nieautoryzowane żądanie (401)
Kod stanu 401 Unauthorized oznacza, że żądanie nie może zostać zrealizowane, ponieważ konieczne jest zalogowanie się przy użyciu ważnego identyfikatora użytkownika i hasła. Googlebot nie może indeksować stron ukrytych za loginami – w takim przypadku usuń wymóg autoryzacji lub zweryfikuj Googlebota, aby mógł uzyskać dostęp do stron.
Nie znaleziono przesłanego adresu URL (404)
Strony błędu 404 wskazują, że żądanej strony nie można znaleźć , ponieważ uległa zmianie lub została usunięta. Strony błędów istnieją w każdej witrynie i generalnie kilka z nich nie zaszkodzi Twojej witrynie. Jednak za każdym razem, gdy użytkownik napotka stronę błędu, może to prowadzić do negatywnych doświadczeń.
Jeśli widzisz ten problem w raporcie, przejrzyj adresy URL, których dotyczy problem, i sprawdź, czy możesz naprawić błędy. Na przykład możesz ustawić przekierowania 301 do działających stron. Upewnij się też, że mapa witryny nie zawiera żadnych adresów URL, które zwracają kod stanu HTTP inny niż 200 OK.
Zwrócony adres URL 403
Kod statusu 403 Forbidden oznacza , że serwer rozumie żądanie, ale odmawia jego autoryzacji. Możesz przyznać dostęp anonimowym odwiedzającym, aby Googlebot mógł uzyskać dostęp do adresu URL, lub, jeśli nie jest to możliwe, usunąć adres URL z map witryn.
Przesłany adres URL zablokowany z powodu innego problemu 4xx
Twoje adresy URL mogą nie zostać zindeksowane z powodu błędów 4xx, które nie zostały określone w innych typach błędów. Błędy 4xx ogólnie odnoszą się do problemów spowodowanych przez klienta.
Możesz dowiedzieć się więcej o przyczynach każdego problemu, korzystając z narzędzia do sprawdzania adresów URL . Jeśli nie możesz rozwiązać problemu, usuń adres URL z mapy witryny.
Obowiązuje z ostrzeżeniami
Adresy URL z ostrzeżeniami zostały zindeksowane, ale mogą wymagać Twojej uwagi.
Zindeksowany, choć zablokowany przez robots.txt
Strona została zindeksowana, ale blokują ją dyrektywy w pliku robots.txt. Zazwyczaj te strony nie byłyby indeksowane, ale prawdopodobnie Google znalazł odsyłające do nich linki i uznał je za ważne.
Sprawdź strony, których dotyczy problem – jeśli powinny zostać zindeksowane, zaktualizuj plik robots.txt, aby dać do nich dostęp Google. Jeśli te strony nie powinny być indeksowane, poszukaj linków do nich prowadzących. Jeśli chcesz, aby adresy URL były przeszukiwane, ale nie indeksowane, zaimplementuj dyrektywy noindex.
Strona zindeksowana bez treści
Te adresy URL są zindeksowane, ale Google nie może odczytać ich zawartości.
Najczęstsze przyczyny tego problemu to:
- Cloaking – pokazywanie różnych treści użytkownikom i wyszukiwarkom,
- Strona jest pusta,
- Google nie może renderować strony,
- Strona ma format, którego Google nie może zindeksować.
Odwiedź te strony samodzielnie i sprawdź, czy zawartość jest widoczna. Przejdź również do narzędzia do sprawdzania adresów URL, aby dowiedzieć się, jak Googlebot je widzi. Następnie, po naprawieniu problemu lub braku jakichkolwiek problemów, możesz poprosić Google o jego ponowne zindeksowanie.
Ważny
Ten stan pokazuje adresy URL, które są poprawnie zindeksowane. Jednak nadal dobrze jest monitorować tę sekcję raportu, aby sprawdzić, czy jakiekolwiek adresy URL nie powinny być indeksowane.
Przesłane i zindeksowane
Są to adresy URL, które są poprawnie zindeksowane i przesłane za pośrednictwem mapy witryny.
Zindeksowany, nie przesłany w mapie witryny
W tej sytuacji adres URL został zindeksowany, mimo że nie jest uwzględniony w mapie witryny.
Powinieneś sprawdzić, w jaki sposób Google dociera do tego adresu URL. Możesz znaleźć te informacje w narzędziu do sprawdzania adresów URL.
Adresy URL w tej sekcji często zawierają paginację witryny, co jest poprawne, ponieważ w mapach witryn nie należy podawać paginacji. Sprawdź adresy URL i sprawdź, czy należy je dodać do mapy witryny.
Wyłączony
Są to strony, które nie zostały zindeksowane. Jak możesz zauważyć, wiele problemów tutaj spowodowanych jest aspektami podobnymi do tych w poprzednich sekcjach. Główna różnica polega na tym, że Google nie uważa, że wykluczenie poniższych adresów URL jest spowodowane błędem.
Może się okazać, że wiele adresów URL w tej sekcji zostało wykluczonych z właściwych powodów. Jednak ważne jest, aby regularnie sprawdzać, które adresy URL nie są indeksowane i dlaczego, aby upewnić się, że krytyczne adresy URL nie są pomijane w indeksie.
Wykluczone przez tag „noindex”
Strona nie została przesłana do indeksowania, ale Googlebot ją znalazł i nie mógł jej zindeksować z powodu tagu noindex. Przejrzyj te adresy URL, aby upewnić się, że właściwe są blokowane w indeksie. Jeśli którykolwiek z adresów URL powinien zostać zindeksowany, usuń tag.
Zablokowane przez narzędzie do usuwania stron
Te adresy URL zostały zablokowane przez Google za pomocą narzędzia Google do usuwania . Jednak ta metoda działa tylko tymczasowo i zazwyczaj po 90 dniach Google może ponownie wyświetlić je w wynikach wyszukiwania. Jeśli chcesz zablokować stronę na stałe, możesz ją usunąć lub przekierować albo użyć tagu noindex.
Zablokowany przez plik robots.txt
Adresy URL zostały zablokowane w pliku robots.txt, ale nie zostały przesłane do indeksowania. Powinieneś przejrzeć te adresy URL i sprawdzić, czy zamierzasz je zablokować.
Pamiętaj, że używanie dyrektyw robots.txt nie jest kuloodpornym sposobem zapobiegania indeksowaniu stron. Google może nadal indeksować stronę bez jej odwiedzania, np. jeśli inne strony zawierają do niej linki. Aby utrzymać stronę poza indeksem Google, użyj innej metody, takiej jak ochrona hasłem lub tag noindex.
Zablokowane z powodu nieautoryzowanego żądania (401)
W tym przypadku firma Google otrzymała kod odpowiedzi 401 i nie została upoważniona do uzyskania dostępu do adresów URL.
Ma to tendencję do występowania w środowiskach pomostowych lub innych stronach chronionych hasłem.
Jeśli te adresy URL nie powinny być indeksowane, ten stan jest prawidłowy. Aby jednak trzymać te adresy URL poza zasięgiem Google, upewnij się, że Twoje środowisko testowe nie zostanie znalezione przez Google. Na przykład usuń wszelkie istniejące linki wewnętrzne lub zewnętrzne, które do niego prowadzą.
Zindeksowana – obecnie nieindeksowana
Googlebot zindeksował adres URL, ale czeka na decyzję, czy powinien zostać zindeksowany.
Powodów może być wiele. Na przykład może nie być problemu, a Google wkrótce zindeksuje ten adres URL. Jednak często Google będzie czekać z zaindeksowaniem strony, jeśli jej zawartość nie jest wysokiej jakości lub wygląda podobnie do wielu innych stron w witrynie. Google umieszcza go następnie w kolejce z niższym priorytetem i skupia się na indeksowaniu bardziej wartościowych stron.
Jeśli chcesz dowiedzieć się, co może być przyczyną tego stanu i jak rozwiązać wszelkie problemy, przeczytaj nasz artykuł o tym, jak naprawić błąd „Zindeksowane — obecnie nieindeksowane”.
Odkryte – obecnie nieindeksowane
Oznacza to, że Google znalazł adres URL – na przykład w mapie witryny – ale jeszcze go nie zindeksował.
Pamiętaj, że w niektórych przypadkach może to po prostu oznaczać, że Google wkrótce go zindeksuje. Ten problem może być również związany z problemami z budżetem indeksowania – Google może uznać Twoją witrynę za niską jakość , ponieważ ma niską wydajność lub zawiera cienkie treści.
Możliwe, że Google nie znalazł żadnych linków prowadzących do tego adresu URL lub napotkał strony z silniejszymi linkami sygnalizującymi, że będzie on najpierw zaindeksowany. Jeśli istnieje wiele stron lepszej jakości lub bardziej aktualnych, Google może pomijać indeksowanie tego adresu URL miesiącami lub nawet nigdy go nie indeksować.
Alternatywna strona z odpowiednim znacznikiem kanonicznym
Ten adres URL jest duplikatem strony kanonicznej oznaczonej poprawnym tagiem i wskazuje na stronę kanoniczną. Tagi kanoniczne służą do określania adresu URL reprezentującego podstawową wersję strony. Jest to sposób na zapobieganie problemom z powielaniem treści, gdy istnieje wiele identycznych lub podobnych stron.
W tej sytuacji nie musisz dokonywać żadnych zmian.
Duplikuj bez kanonicznego wybranego przez użytkownika
Ta strona ma duplikaty i nie określono wersji kanonicznej. Oznacza to, że Google nie postrzega określonych adresów URL jako kanonicznych.
Możesz użyć narzędzia do sprawdzania adresów URL, aby dowiedzieć się, który URL wybrał Google jako kanoniczny. Najlepiej samodzielnie wybrać wersję kanoniczną i odpowiednio ją oznaczyć w swoich adresach URL za pomocą tagu rel="canonical".
Duplikat, Google wybrał inny kanoniczny niż użytkownik
Wybrałeś stronę kanoniczną, ale Google wybrał inną stronę jako kanoniczną.
Strona, którą chcesz mieć jako kanoniczną, może nie być tak silnie połączona wewnętrznie jak strona niekanoniczna, którą Google może następnie wybrać jako wersję kanoniczną.
Jednym ze sposobów rozwiązania tego problemu jest konsolidacja zduplikowanych adresów URL. Jeśli chcesz dowiedzieć się więcej o możliwych przyczynach i rozwiązaniach problemu, przeczytaj nasz przewodnik, jak naprawić duplikat, Google wybrał inny problem kanoniczny niż problem użytkownika.
Nie znaleziono (404)
Są to strony błędu 404, które nie zostały przesłane w mapie witryny, ale Google nadal je znalazł.
Google mógł je odkryć za pomocą linków lub dlatego, że istniały wcześniej, a później zostały usunięte.
Jeśli Twoim zamiarem było, aby ta strona nie została odnaleziona, nie musisz nic robić. Inną opcją jest użycie przekierowania 301, aby przenieść 404 na działającą stronę.
Strona z przekierowaniem
Te strony przekierowują, więc nie zostały zindeksowane. Strony tutaj na ogół nie wymagają Twojej uwagi.
Aby na stałe przekierować stronę, upewnij się, że zaimplementowałeś przekierowanie 301 do najbliższej alternatywnej strony. Przekierowanie stron 404 na stronę główną może spowodować , że Google potraktuje je jako miękkie błędy 404.
Miękki 404
Jak wspomniano, te adresy URL przypominają strony błędów, ale nie zwracają kodów stanu 404. Na przykład mogą to być niestandardowe strony 404 zawierające przyjazną dla użytkownika treść kierującą na inne strony, ale zwracające kod HTTP 200 OK.
Aby naprawić miękkie błędy 404, możesz:
- Dodaj lub ulepsz treść pod tymi adresami URL,
- 301 przekierowuje ich do najbardziej pasujących alternatyw lub
- Skonfiguruj serwer tak, aby zwracał prawidłowe kody 404 lub 410.
Zduplikowany, przesłany adres URL nie został wybrany jako kanoniczny
Obejmuje to adresy URL przesłane w mapie witryny, ale bez określonych wersji kanonicznych.
Google uważa te adresy URL za duplikaty innych adresów URL i zdecydował się na kanonizację tych adresów URL za pomocą wybranych przez Google kanonicznych adresów URL. Należy dodać kanoniczne adresy URL wskazujące na preferowane wersje adresów URL.
Zablokowany z powodu zakazu dostępu (403)
Google nie mógł uzyskać dostępu do tych adresów URL i otrzymał kod błędu 403 Forbidden. Jeśli Google nie powinien uzyskać dostępu do tych adresów URL, lepiej użyć tagu noindex.
Zablokowany z powodu innego problemu 4xx
Te adresy URL odpowiadają innym kodom stanu 4xx — sprawdź te strony, aby dowiedzieć się, jaki jest błąd. Następnie albo napraw go zgodnie z określonym kodem, który się pojawi, albo pozostaw strony bez zmian.
Wniosek
Raport Pokrycie indeksu zawiera szczegółowy przegląd problemów związanych z indeksowaniem i indeksowaniem oraz wskazuje, w jaki sposób należy je rozwiązać, co czyni go ważnym źródłem danych SEO.
Stan przeszukiwania i indeksowania Twojej witryny nie jest prosty — nie wszystkie Twoje strony powinny zostać przeszukane lub zindeksowane. Upewnienie się, że takie strony nie są dostępne dla robotów wyszukiwarek, jest tak samo ważne, jak prawidłowe indeksowanie najcenniejszych stron.
Raport odzwierciedla fakt, że stan indeksowania nie jest ani czarny, ani biały. Podkreśla zakres stanów, w których mogą znajdować się Twoje adresy URL, pokazując zarówno poważne błędy, jak i drobne problemy, które nie zawsze wymagają działania.
Ostatecznie powinieneś regularnie przeglądać raport Google dotyczący pokrycia indeksów i interweniować, gdy nie jest on zgodny z Twoją strategią indeksowania.