
So verwenden Sie den Indexabdeckungsbericht der Google Search Console
Veröffentlicht: 2021-12-28Die Indexabdeckung ist ein Bericht in der Google Search Console, der den Crawling- und Indexierungsstatus aller URLs anzeigt, die Google für Ihre Website entdeckt hat.
Es hilft Ihnen , den Indexierungsstatus Ihrer Website zu verfolgen und hält Sie über technische Probleme auf dem Laufenden, die verhindern, dass Ihre Seiten korrekt gecrawlt und indexiert werden.
Die regelmäßige Überprüfung des Berichts zur Indexabdeckung hilft Ihnen dabei, Probleme zu erkennen und zu verstehen und zu lernen, wie Sie diese beheben können.
In diesem Artikel beschreibe ich:
- Was der Bericht zur Indexabdeckung ist,
- Wann und wie Sie es verwenden sollten,
- Die im Bericht angezeigten Status, einschließlich Arten von Problemen, was sie bedeuten und wie sie behoben werden können.
Wann wurde der Bericht zur Indexabdeckung eingeführt?
Google führte den Bericht zur Indexabdeckung im Januar 2018 ein, als es damit begann, eine überarbeitete Version der Search Console für alle Nutzer herauszugeben .
Abgesehen von der Indexabdeckung enthielt die verbesserte Search Console weitere wertvolle Berichte:
- Der Suchleistungsbericht,
- Berichte zu Suchverbesserungen: AMP-Status und Stellenausschreibungsseiten.
Google sagte, die Neugestaltung der Google Search Console sei durch das Feedback der Nutzer motiviert gewesen. Das Ziel war:
- Fügen Sie weitere umsetzbare Erkenntnisse hinzu,
- Unterstützung der Zusammenarbeit verschiedener Teams, die das Tool verwenden,
- Bieten Sie schnellere Feedbackschleifen zwischen Google und den Websites der Nutzer.
Die Aktualisierung des Indexabdeckungsberichts 2021
Im Januar 2021 verbesserte Google den Bericht zur Indexabdeckung , um die gemeldeten Indexierungsprobleme für die Nutzer genauer und klarer zu machen.
Die Änderungen am Bericht bestanden aus:
- Entfernen des generischen Problemtyps „Crawl-Anomalie“,
- Erstellen von Seiten, die gesendet, aber von robots.txt blockiert und indexiert wurden, als „indiziert, aber blockiert“ (in Warnungen) anstelle von „eingereicht, aber blockiert“ (Fehler),
- Hinzufügen eines Problems namens „Indiziert ohne Inhalt“ (zu Warnungen),
- Präzisere Berichterstattung über Soft 404-Probleme.
Die Indizierungspipeline von Google
Bevor wir uns mit den Einzelheiten des Berichts befassen, lassen Sie uns die Schritte besprechen, die Google unternehmen muss, um Webseiten zu indizieren und schließlich zu ranken.
Damit eine Seite eingestuft und den Benutzern angezeigt werden kann, muss sie entdeckt, gecrawlt und indiziert werden.
Entdeckung
Google muss zuerst eine Seite entdecken, um sie crawlen zu können.
Die Entdeckung kann auf verschiedene Arten erfolgen.
Am häufigsten verfolgt der Googlebot interne oder externe Links zu einer Seite oder findet sie über eine XML-Sitemap , eine Datei, die die URLs Ihrer Domain auflistet und organisiert.
Krabbeln
Crawling besteht darin, dass Suchmaschinen Webseiten durchsuchen und deren Inhalt analysieren.
Ein wesentlicher Aspekt des Crawlings ist das Crawling-Budget , also die Menge an Zeit und Ressourcen, die Suchmaschinen für das Crawlen Ihrer Website aufwenden können und wollen. Suchmaschinen haben begrenzte Crawling-Fähigkeiten und können nur einen Teil der Seiten einer Website crawlen. Lesen Sie mehr über die Optimierung Ihres Crawl-Budgets.
Indizierung
Bei der Indexierung wertet Google die Seiten aus und fügt sie dem Index hinzu – einer Datenbank aller Webseiten, die Google zur Generierung von Suchergebnissen verwenden kann. Diese Phase besteht auch aus dem Rendern , das Google hilft, das Layout und den Inhalt der Seiten zu sehen. Die Informationen, die Google über eine Seite sammelt, helfen bei der Entscheidung, wie sie in den Suchergebnissen angezeigt wird.
Aber nur weil Google Ihre Seite finden und crawlen kann, bedeutet das nicht, dass sie indexiert wird.
Von Google indiziert zu werden, wird immer komplizierter. Dies liegt hauptsächlich daran, dass das Web wächst und Websites schwerer werden.
Aber hier ist der entscheidende Indexierungsaspekt, den Sie sich merken sollten: Sie sollten nicht alle Ihre Seiten indizieren lassen.
Stellen Sie stattdessen sicher, dass der Index nur Ihre Seiten mit qualitativ hochwertigen Inhalten enthält, die für Benutzer wertvoll sind. Einige Seiten können minderwertigen oder doppelten Inhalt haben, und wenn Suchmaschinen sie sehen, kann sich dies negativ darauf auswirken, wie sie Ihre Website als Ganzes sehen.
Aus diesem Grund ist es wichtig, eine Indexierungsstrategie zu entwickeln und zu entscheiden, welche Seiten indexiert werden sollen und welche nicht. Durch die Vorbereitung einer Indexierungsstrategie können Sie Ihr Crawling-Budget optimieren, ein klares Indexierungsziel verfolgen und alle Probleme entsprechend beheben.
Wenn Sie mehr über die Indexierung erfahren möchten, lesen Sie zunächst unseren Leitfaden zur Indexierung von SEO.
Rangfolge
Seiten, die indiziert sind, können eingestuft werden und in den Suchergebnissen für relevante Suchanfragen erscheinen.
Google entscheidet, wie Seiten eingestuft werden, basierend auf zahlreichen Ranking-Faktoren, wie z. B. der Menge und Qualität der Links, der Seitengeschwindigkeit, der Handyfreundlichkeit, der Inhaltsrelevanz und vielen anderen.
Wie verwende ich den Indexabdeckungsbericht?
Um zum Indexabdeckungsbericht zu gelangen, melden Sie sich bei Ihrem Google Search Console-Konto an. Wählen Sie dann im Menü auf der linken Seite im Abschnitt Index „Abdeckung“ aus:
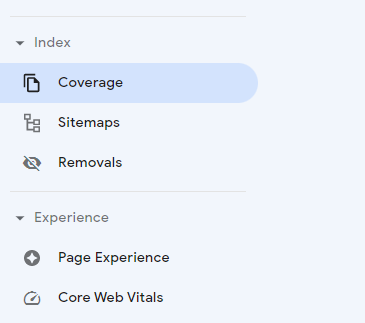
Sie sehen dann den Bericht. Indem Sie jeden oder alle Status ankreuzen, können Sie auswählen, was Sie auf dem Diagramm visualisieren möchten:

Der Bericht zeigt URLs, die mit den folgenden vier Status antworten, verbunden mit verschiedenen Problemen, die Google auf bestimmten Seiten festgestellt hat:
- Fehler – kritische Probleme beim Crawlen oder Indizieren.
- Gültig mit Warnungen – URLs, die indexiert sind, aber einige unkritische Fehler enthalten.
- Gültig – URLs, die korrekt indexiert wurden.
- Ausgeschlossen – Seiten, die aufgrund von Problemen nicht indexiert wurden – dies ist der wichtigste Abschnitt, auf den Sie sich konzentrieren sollten.
„Alle eingereichten Seiten“ vs. „Alle bekannten Seiten“
In der oberen linken Ecke können Sie auswählen, ob Sie „Alle bekannten Seiten“ anzeigen möchten, was die Standardoption ist, die URLs anzeigt, die Google auf irgendeine Weise entdeckt hat, oder „Alle eingereichten Seiten“, einschließlich nur URLs, die in einer Sitemap eingereicht wurden.
Sie sollten einen deutlichen Unterschied zwischen dem Status „Alle eingereichten Seiten“ und „Alle bekannten Seiten“ feststellen – „Alle bekannten Seiten“ enthalten normalerweise mehr URLs und mehr von ihnen werden als ausgeschlossen gemeldet. Das liegt daran, dass Sitemaps nur indexierbare URLs enthalten sollten, während die meisten Websites viele Seiten enthalten, die nicht indexiert werden sollten. Ein Beispiel sind URLs mit Tracking-Parametern auf E-Commerce-Websites. Suchmaschinen-Bots wie Googlebot können diese Seiten auf verschiedene Weise finden, aber sie sollten sie nicht in Ihrer Sitemap finden.
Seien Sie also immer vorsichtig, wenn Sie den Indexabdeckungsbericht öffnen, und vergewissern Sie sich, dass Sie sich die Daten ansehen, die Sie interessieren.
Überprüfung des URL-Status
Um die Details zu den Problemen zu sehen, die für jeden der Status gefunden wurden, sehen Sie unter dem Diagramm nach:

Dieser Abschnitt zeigt den Status, die Art des Problems und die Anzahl der betroffenen Seiten an.
Sie können auch den Validierungsstatus sehen – nachdem Sie ein Problem behoben haben, können Sie Google darüber informieren, dass es behoben wurde, und darum bitten, die Lösung zu validieren.
Dies ist oben im Bericht möglich, nachdem Sie auf das Problem geklickt haben:
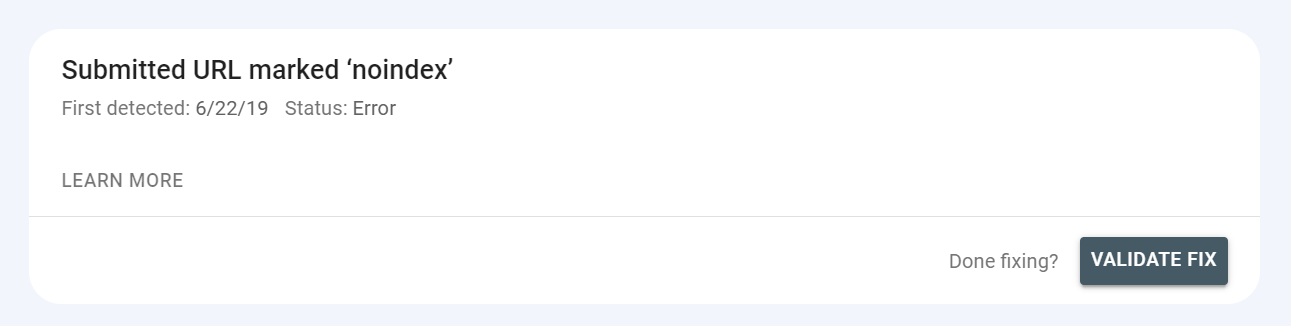
Der Validierungsstatus kann als „fest“ angezeigt werden. Es kann aber auch „fehlgeschlagen“ oder „nicht gestartet“ angezeigt werden – Sie sollten die Behebung von Problemen priorisieren, die mit diesen Status reagieren.
Sie können auch den Trend für jeden Status sehen – ob die Anzahl der URLs gestiegen, gesunken oder auf dem gleichen Niveau geblieben ist.
Nachdem Sie auf einen der Typen geklickt haben, sehen Sie, welche URLs auf dieses Problem reagieren. Außerdem können Sie prüfen, wann jede URL zuletzt gecrawlt wurde – diese Information ist jedoch aufgrund möglicher Verzögerungen bei der Berichterstattung von Google nicht immer aktuell.
Es gibt auch ein Diagramm, das die Daten zeigt und wie sich das Problem im Laufe der Zeit verändert hat.
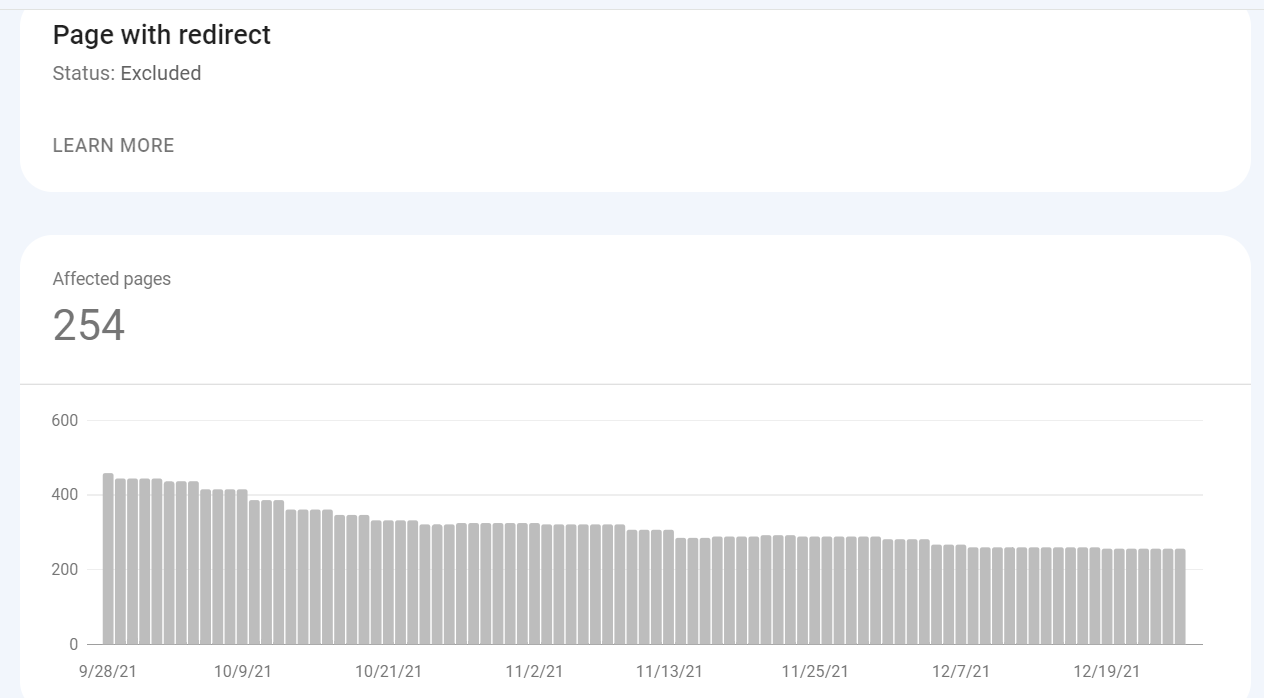
Hier sind einige wichtige Überlegungen, die Sie bei der Verwendung des Berichts beachten sollten:
- Überprüfen Sie immer, ob Sie sich alle eingereichten Seiten oder alle bekannten Seiten ansehen. Der Unterschied zwischen dem Status der Seiten in Ihrer Sitemap und allen Seiten, die Google entdeckt hat, kann sehr deutlich sein.
- Der Bericht zeigt Änderungen möglicherweise mit Verzögerung an. Wenn Sie also neue Inhalte veröffentlichen, geben Sie ihnen mindestens ein paar Tage Zeit, um gecrawlt und indexiert zu werden.
- Google sendet Ihnen E-Mail-Benachrichtigungen über besonders dringende Probleme, die auf Ihrer Website aufgetreten sind.
- Ihr Ziel sollte es sein, die kanonischen Versionen der Seiten zu indizieren, die Benutzer und Bots finden sollen.
- Wenn Ihre Website wächst und Sie mehr Inhalt erstellen, können Sie davon ausgehen, dass die Anzahl der indizierten Seiten im Bericht zunimmt.
Wie oft sollten Sie den Bericht überprüfen?
Sie sollten den Indexabdeckungsbericht regelmäßig überprüfen , um Fehler beim Crawlen und Indexieren Ihrer Seiten zu erkennen. Versuchen Sie im Allgemeinen, den Bericht mindestens einmal im Monat zu überprüfen.
Wenn Sie jedoch wesentliche Änderungen an Ihrer Website vornehmen, z. B. das Layout oder die URL-Struktur anpassen oder eine Website-Migration durchführen, überwachen Sie die Ergebnisse häufiger, um negative Auswirkungen zu erkennen. Dann empfehle ich, den Bericht mindestens einmal pro Woche zu besuchen und besonders auf den Ausgeschlossen-Status zu achten .
URL-Prüftool
Bevor ich auf die Einzelheiten der einzelnen Status im Bericht zur Indexabdeckung eingehe, möchte ich ein weiteres Tool in der Search Console erwähnen, das Ihnen wertvolle Einblicke in Ihre gecrawlten oder indexierten Seiten gibt.
Das URL-Inspektionstool liefert Details zur indexierten Seitenversion von Google.
Sie finden es in der Google Search Console in einer Suchleiste oben auf der Seite.
Fügen Sie einfach eine URL ein, die Sie überprüfen möchten – Sie sehen dann die folgenden Daten:
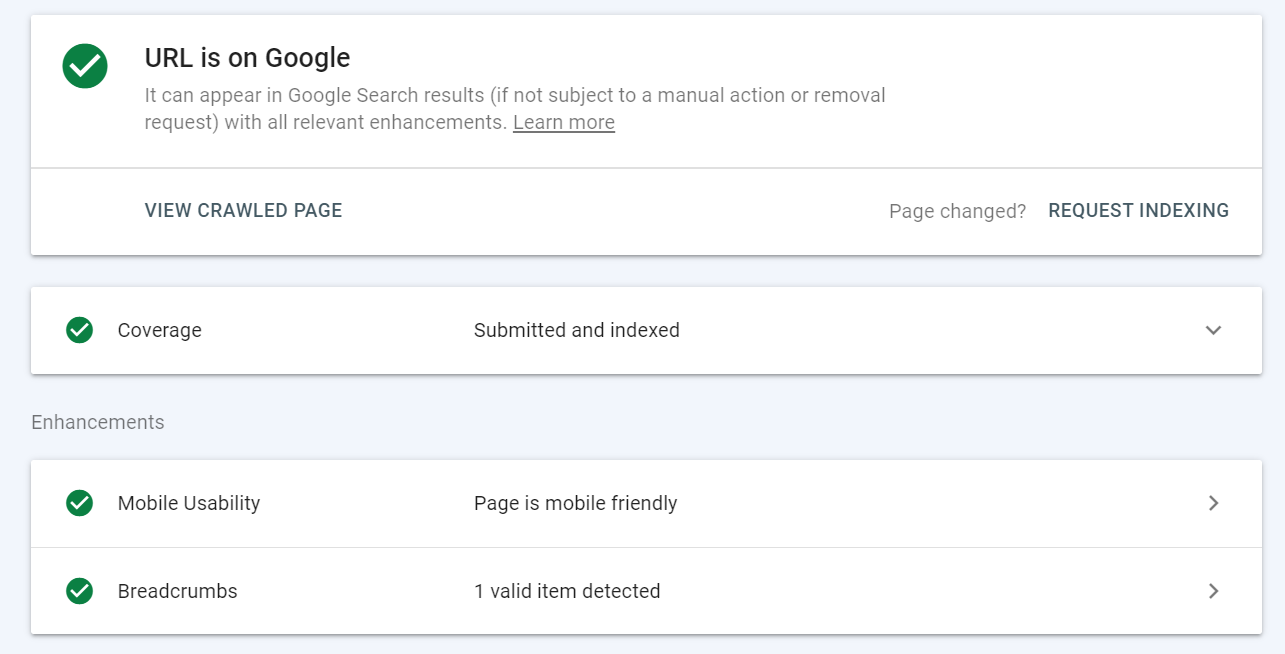
Sie können das URL-Prüftool für Folgendes verwenden:
- Überprüfen Sie den Indexstatus einer URL und sehen Sie bei Problemen, was sie sind, und beheben Sie sie,
- Erfahren Sie, ob eine URL indexierbar ist,
- Anzeigen der gerenderten Version einer URL,
- Indexierung einer URL anfordern – z. B. wenn sich eine Seite geändert hat,
- Geladene Ressourcen anzeigen, z. B. JavaScript,
- Sehen Sie, für welche Erweiterungen eine URL geeignet ist – z. B. basierend auf der Implementierung strukturierter Daten und ob die Seite für Mobilgeräte optimiert ist.
Wenn Sie im Indexabdeckungsbericht auf Probleme stoßen, verwenden Sie das URL-Prüftool, um sie zu überprüfen, und testen Sie die URLs, um besser zu verstehen, was behoben werden sollte.
Status im Indexabdeckungsbericht und Arten von Problemen
Es ist an der Zeit, sich jeden der vier Status im Bericht anzusehen und:
- Besprechen Sie die spezifischen Problemtypen, die sie zeigen können,
- Was verursacht diese Probleme und
- Wie Sie sie ansprechen sollten.
Fehler
Der Fehlerabschnitt enthält URLs, die aufgrund von Fehlern, auf die Google gestoßen ist, nicht indexiert wurden.
Wann immer Sie ein Problem sehen, das „Eingereicht“ enthält, handelt es sich um URLs, die zur Indexierung eingereicht wurden, was im Allgemeinen über eine Sitemap erfolgt, und so hat Google sie entdeckt. Stellen Sie sicher, dass Ihre Sitemap nur URLs enthält, die Sie indexieren möchten.

Serverfehler (5xx)
Wie der Name schon sagt, bezieht es sich auf Serverfehler mit 5xx-Statuscodes , wie z. B. 502 Bad Gateway oder 503 Service Unavailable.
Sie sollten diesen Abschnitt regelmäßig überwachen, da der Googlebot Probleme beim Indizieren von Seiten mit Serverfehlern haben wird. Möglicherweise müssen Sie sich an Ihren Serveradministrator wenden, um diese Fehler zu beheben oder zu überprüfen, ob sie durch kürzlich durchgeführte Upgrades oder Änderungen an Ihrer Website verursacht wurden.
Sehen Sie sich die Vorschläge von Google zur Behebung von Serverfehlern an.
Umleitungsfehler
Weiterleitungen übertragen Suchmaschinen-Bots und Benutzer von einer alten URL auf eine neue. Sie werden normalerweise implementiert, wenn sich alte URLs ändern oder deren Inhalt nicht mehr existiert.
Umleitungsfehler weisen auf die folgenden Probleme hin:
- Weiterleitungskette (die auftritt, wenn es mehrere Weiterleitungen zwischen URLs gibt) ist zu lang,
- Umleitungsschleife – URLs leiten aufeinander um,
- Umleitungs-URL, die die maximale URL-Länge überschritten hat,
- In der Weiterleitungskette wurde eine falsche oder leere URL gefunden.
Überprüfen und beheben Sie die Weiterleitungen für jede betroffene URL – wenn Sie sich nicht sicher sind, wo Sie anfangen sollen, folgen Sie meiner Anleitung zu Weiterleitungen.
Eingesendete URL durch robots.txt blockiert
Diese URLs wurden in einer Sitemap eingereicht, sind aber in robots.txt blockiert. Robots.txt ist eine Datei mit Anweisungen, wie Robots Ihre Website crawlen sollen. Wenn diese URL indexiert werden soll, muss Google sie zuerst crawlen, also gehen Sie zu Ihrer robots.txt-Datei und passen Sie die Anweisungen an.
Eingereichte URL mit der Kennzeichnung „noindex“
Ähnlich wie beim vorherigen Fehler wurden diese Seiten zur Indexierung übermittelt, aber durch ein noindex-Tag oder einen Header in der HTTP-Antwort blockiert . „Noindex“ verhindert, dass eine Seite indexiert wird – wenn die betroffenen URLs indexiert werden sollen, entfernen Sie die noindex-Direktive.
Die übermittelte URL scheint ein Soft 404 zu sein
Ein weicher 404-Fehler bedeutet, dass eine Seite einen 200 OK-Status zurückgibt, aber ihr Inhalt lässt sie wie einen Fehler aussehen , z. B. weil sie leer ist oder dünnen Inhalt enthält. Überprüfen Sie Seiten mit diesem Fehler und prüfen Sie, ob es eine Möglichkeit gibt, ihren Inhalt zu ändern oder sie umzuleiten.
Die gesendete URL gibt eine nicht autorisierte Anfrage zurück (401)
Der Statuscode 401 Unauthorized bedeutet, dass eine Anfrage nicht abgeschlossen werden kann, da eine Anmeldung mit einer gültigen Benutzer-ID und einem gültigen Passwort erforderlich ist. Der Googlebot kann hinter Logins verborgene Seiten nicht indexieren – entfernen Sie in diesem Fall entweder die Autorisierungsanforderung oder verifizieren Sie den Googlebot, damit er auf die Seiten zugreifen kann.
Eingereichte URL nicht gefunden (404)
404-Fehlerseiten weisen darauf hin, dass die angeforderte Seite nicht gefunden werden konnte, weil sie geändert oder gelöscht wurde. Fehlerseiten gibt es auf jeder Website und im Allgemeinen schaden einige davon Ihrer Website nicht. Wenn ein Benutzer jedoch auf eine Fehlerseite stößt, kann dies zu einer negativen Erfahrung führen.
Wenn Sie dieses Problem im Bericht sehen, gehen Sie die betroffenen URLs durch und prüfen Sie, ob Sie die Fehler beheben können. Beispielsweise könnten Sie 301-Weiterleitungen auf Arbeitsseiten einrichten. Stellen Sie außerdem sicher, dass Ihre Sitemap keine URLs enthält, die einen anderen HTTP-Statuscode als 200 OK zurückgeben.
Die übermittelte URL hat 403 zurückgegeben
Der Statuscode 403 Forbidden bedeutet, dass der Server die Anfrage versteht, sich aber weigert, sie zu autorisieren. Sie können entweder anonymen Besuchern Zugriff gewähren, damit der Googlebot auf die URL zugreifen kann, oder, falls dies nicht möglich ist, die URL aus den Sitemaps entfernen.
Die übermittelte URL wurde aufgrund eines anderen 4xx-Problems blockiert
Ihre URLs werden möglicherweise aufgrund von 4xx-Problemen, die nicht in anderen Fehlertypen angegeben sind, nicht indexiert . 4xx-Fehler beziehen sich im Allgemeinen auf Probleme, die vom Client verursacht werden.
Mit dem URL-Prüftool können Sie mehr darüber erfahren, was die einzelnen Probleme verursacht . Wenn Sie den Fehler nicht beheben können, entfernen Sie die URL aus Ihrer Sitemap.
Gültig mit Warnungen
Gültige URLs mit Warnungen wurden indexiert, erfordern aber möglicherweise Ihre Aufmerksamkeit.
Indiziert, obwohl von robots.txt blockiert
Eine Seite wurde indexiert, aber Anweisungen in der robots.txt-Datei blockieren sie. Normalerweise werden diese Seiten nicht indexiert, aber es ist wahrscheinlich, dass Google Links gefunden hat, die auf sie verweisen, und sie als wichtig erachtet.
Überprüfen Sie die betroffenen Seiten – wenn sie indexiert werden sollen, aktualisieren Sie Ihre robots.txt-Datei, um Google Zugriff darauf zu geben. Wenn diese Seiten nicht indexiert werden sollen, suchen Sie nach Links, die auf sie verweisen. Wenn Sie möchten, dass die URLs gecrawlt, aber nicht indexiert werden, implementieren Sie die noindex-Direktiven.
Seite ohne Inhalt indexiert
Diese URLs sind indexiert, aber Google konnte ihren Inhalt nicht lesen.
Häufige Ursachen für dieses Problem sind:
- Cloaking – Anzeigen unterschiedlicher Inhalte für Benutzer und Suchmaschinen,
- Die Seite ist leer,
- Google kann die Seite nicht rendern,
- Die Seite hat ein Format, das Google nicht indexieren kann.
Besuchen Sie diese Seiten selbst und prüfen Sie, ob der Inhalt sichtbar ist. Gehen Sie auch zum URL-Inspektionstool, um zu erfahren, wie der Googlebot es sieht. Nachdem Sie das Problem behoben oder keine Probleme festgestellt haben, können Sie eine Neuindizierung bei Google beantragen.
Gültig
Dieser Status zeigt URLs an, die korrekt indexiert sind. Es ist jedoch trotzdem ratsam, diesen Berichtsabschnitt zu überwachen, um festzustellen, ob URLs nicht indexiert werden sollten.
Eingereicht und indexiert
Dies sind URLs, die korrekt indexiert und über eine Sitemap übermittelt werden.
Indexiert, nicht in Sitemap eingereicht
In diesem Fall wurde eine URL indexiert, obwohl sie nicht in der Sitemap enthalten ist.
Sie sollten überprüfen, wie Google zu dieser URL gelangt. Diese Informationen finden Sie im URL-Prüftool.
URLs in diesem Abschnitt enthalten häufig die Paginierung der Website, was korrekt ist, da Paginierungen nicht in Sitemaps eingereicht werden sollten. Überprüfen Sie die URLs und prüfen Sie, ob sie zur Sitemap hinzugefügt werden sollen.
Ausgeschlossen
Dies sind Seiten, die nicht indiziert wurden. Wie Sie vielleicht bemerken, werden viele Probleme hier durch ähnliche Aspekte wie in den vorherigen Abschnitten verursacht. Der Hauptunterschied besteht darin, dass Google nicht der Meinung ist, dass das Ausschließen der folgenden URLs auf einen Fehler zurückzuführen ist.
Möglicherweise stellen Sie fest, dass viele URLs in diesem Abschnitt aus den richtigen Gründen ausgeschlossen wurden. Es ist jedoch wichtig, regelmäßig zu überprüfen, welche URLs nicht indexiert sind und warum, um sicherzustellen, dass Ihre kritischen URLs nicht aus dem Index herausgehalten werden.
Ausgeschlossen durch 'noindex'-Tag
Eine Seite wurde nicht zur Indexierung eingereicht, aber der Googlebot hat sie gefunden und konnte sie aufgrund eines noindex-Tags nicht indexieren. Gehen Sie diese URLs durch, um sicherzustellen, dass die richtigen für den Index blockiert werden. Wenn eine der URLs indexiert werden soll, entfernen Sie das Tag.
Vom Tool zum Entfernen von Seiten blockiert
Diese URLs wurden mit dem Entfernungstool von Google von Google blockiert . Diese Methode funktioniert jedoch nur vorübergehend, und Google zeigt sie in der Regel nach 90 Tagen wieder in den Suchergebnissen an. Wenn Sie eine Seite dauerhaft blockieren möchten, können Sie sie entfernen oder umleiten oder ein noindex-Tag verwenden.
Blockiert durch robots.txt
Die URLs wurden in der robots.txt-Datei blockiert, aber nicht zur Indexierung übermittelt. Sie sollten diese URLs durchgehen und prüfen, ob Sie beabsichtigt haben, sie zu blockieren.
Denken Sie daran, dass die Verwendung von robots.txt-Anweisungen keine sichere Methode ist, um die Indexierung von Seiten zu verhindern. Google kann eine Seite dennoch indexieren, ohne sie besucht zu haben, zB wenn andere Seiten darauf verlinken. Verwenden Sie eine andere Methode, um eine Seite aus dem Index von Google herauszuhalten, z. B. den Passwortschutz oder das Noindex-Tag.
Wegen nicht autorisierter Anfrage gesperrt (401)
In diesem Fall erhielt Google einen 401-Antwortcode und war nicht berechtigt, auf die URLs zuzugreifen.
Dies tritt in der Regel in Staging-Umgebungen oder anderen passwortgeschützten Seiten auf.
Wenn diese URLs nicht indexiert werden sollen, ist dieser Status in Ordnung. Um diese URLs außerhalb der Reichweite von Google zu halten, stellen Sie jedoch sicher, dass Ihre Staging-Umgebung von Google nicht gefunden werden kann. Entfernen Sie beispielsweise alle vorhandenen internen oder externen Links, die darauf verweisen.
Gecrawlt – derzeit nicht indiziert
Der Googlebot hat eine URL gecrawlt, wartet aber auf die Entscheidung, ob sie indexiert werden soll.
Dafür kann es viele Gründe geben. Beispielsweise liegt möglicherweise kein Problem vor und Google wird diese URL bald indizieren. Aber häufig wartet Google mit der Indexierung einer Seite, wenn ihr Inhalt nicht von der Qualität ist oder vielen anderen Seiten auf der Website ähnlich sieht. Google stellt es dann mit niedrigerer Priorität in die Warteschlange und konzentriert sich auf die Indizierung wertvollerer Seiten.
Wenn Sie erfahren möchten, was diesen Status verursachen könnte und wie Sie Probleme beheben können, lesen Sie unbedingt unseren Artikel zur Behebung von „Gecrawlt – derzeit nicht indiziert“.
Entdeckt – derzeit nicht indiziert
Das bedeutet, dass Google eine URL – beispielsweise in einer Sitemap – gefunden , aber noch nicht gecrawlt hat.
Denken Sie daran, dass dies in einigen Fällen einfach bedeuten kann, dass Google es bald crawlen wird. Dieses Problem kann auch mit Problemen mit dem Crawling-Budget zusammenhängen – Google sieht Ihre Website möglicherweise als minderwertig an, weil es an Leistung mangelt oder dünne Inhalte enthält.
Möglicherweise hat Google keine Links gefunden, die auf diese URL verweisen, oder auf Seiten mit stärkeren Linksignalen gestoßen, die zuerst gecrawlt werden. Wenn es viele qualitativ bessere oder aktuellere Seiten gibt, kann Google das Crawlen dieser URL monatelang überspringen oder gar nicht crawlen.
Alternative Seite mit dem richtigen Canonical-Tag
Diese URL ist ein Duplikat einer kanonischen Seite, die mit dem richtigen Tag gekennzeichnet ist, und verweist auf die kanonische Seite. Canonical-Tags werden verwendet, um eine URL anzugeben, die die primäre Version einer Seite darstellt. Auf diese Weise können Probleme mit doppelten Inhalten verhindert werden, wenn viele identische oder ähnliche Seiten vorhanden sind.
In dieser Situation müssen Sie keine Änderungen vornehmen.
Duplizieren ohne vom Benutzer ausgewählte kanonische
Es gibt Duplikate für diese Seite und es ist keine kanonische Version angegeben. Das bedeutet, dass Google die angegebenen URLs nicht als kanonisch ansieht.
Sie können das URL-Inspektionstool verwenden, um zu erfahren, welche URL Google als kanonisch ausgewählt hat. Am besten wählst du die kanonische Version selbst aus und kennzeichnest sie in deinen URLs mit dem rel=“canonical“-Tag entsprechend aus.
Duplizieren, Google hat eine andere kanonische als der Benutzer ausgewählt
Sie haben eine kanonische Seite ausgewählt, aber Google hat eine andere Seite als kanonisch ausgewählt.
Die Seite, die Sie als kanonisch haben möchten, ist möglicherweise nicht so stark intern verlinkt wie eine nicht kanonische Seite, die Google dann möglicherweise als kanonische Version auswählt.
Eine Möglichkeit, dieses Problem zu lösen, besteht darin, Ihre doppelten URLs zu konsolidieren. Wenn Sie mehr über mögliche Ursachen und Lösungen für den Status erfahren möchten, lesen Sie unseren Leitfaden zur Behebung des Duplikats, Google hat ein anderes kanonisches als ein Benutzerproblem ausgewählt.
Nicht gefunden (404)
Das sind 404-Fehlerseiten, die nicht in einer Sitemap eingereicht wurden , Google sie aber trotzdem gefunden hat.
Google könnte sie durch Links entdeckt haben oder weil sie vorher existierten und später gelöscht wurden.
Wenn Sie beabsichtigt haben, dass diese Seite nicht gefunden wird, müssen Sie nichts unternehmen. Eine weitere Option ist die Verwendung einer 301-Weiterleitung, um den 404 auf eine funktionierende Seite zu verschieben.
Seite mit Weiterleitung
Diese Seiten werden weitergeleitet, sodass sie nicht indiziert wurden. Seiten hier würden im Allgemeinen nicht Ihre Aufmerksamkeit erfordern.
Um eine Seite dauerhaft umzuleiten, stellen Sie sicher, dass Sie eine 301-Umleitung auf die nächstgelegene alternative Seite implementiert haben. Das Umleiten von 404-Seiten auf die Startseite kann dazu führen, dass Google sie als weiche 404-Seiten behandelt.
Weich 404
Wie bereits erwähnt, ähneln diese URLs Fehlerseiten, geben jedoch keine 404-Statuscodes zurück. Dies können beispielsweise benutzerdefinierte 404-Seiten sein, die benutzerfreundliche Inhalte enthalten, die auf andere Seiten verweisen, aber einen 200-OK-HTTP-Code zurückgeben.
Um weiche 404-Fehler zu beheben, haben Sie folgende Möglichkeiten:
- Inhalte auf diesen URLs hinzufügen oder verbessern,
- 301 leitet sie zu den am besten passenden Alternativen um, oder
- Konfigurieren Sie Ihren Server so, dass er die richtigen 404- oder 410-Codes zurückgibt.
Doppelte, übermittelte URL nicht als kanonisch ausgewählt
Dazu gehören URLs, die in einer Sitemap eingereicht wurden, jedoch keine kanonischen Versionen angegeben sind.
Google betrachtet diese URLs als Duplikate anderer URLs und hat beschlossen, diese URLs mit von Google ausgewählten kanonischen URLs zu kanonisieren. Sie sollten kanonische URLs hinzufügen, die auf die bevorzugten URL-Versionen verweisen.
Gesperrt wegen Zugriff verboten (403)
Google konnte nicht auf diese URLs zugreifen und hat den Fehlercode 403 Forbidden erhalten. Wenn Google auf diese URLs nicht zugreifen soll, ist es besser, ein noindex-Tag zu verwenden.
Aufgrund eines anderen 4xx-Problems blockiert
Diese URLs antworten mit anderen 4xx-Statuscodes – überprüfen Sie diese Seiten, um zu erfahren, was der Fehler ist. Korrigieren Sie es dann entweder gemäß dem spezifischen Code, der angezeigt wird, oder lassen Sie die Seiten so, wie sie sind.
Fazit
Der Indexabdeckungsbericht zeigt einen detaillierten Überblick über Ihre Crawling- und Indexierungsprobleme und weist darauf hin, wie sie angegangen werden sollten, was ihn zu einer wichtigen Quelle für SEO-Daten macht.
Der Crawling- und Indexierungsstatus Ihrer Website ist nicht einfach – nicht alle Ihre Seiten sollten gecrawlt oder indexiert werden. Sicherzustellen, dass solche Seiten für Suchmaschinen-Bots nicht zugänglich sind, ist ebenso wichtig wie die korrekte Indizierung Ihrer wertvollsten Seiten.
Der Bericht spiegelt die Tatsache wider, dass Ihr Indizierungsstatus weder schwarz noch weiß ist. Es hebt die verschiedenen Zustände hervor, in denen sich Ihre URLs befinden könnten, und zeigt sowohl schwerwiegende Fehler als auch kleinere Probleme an, die nicht immer Maßnahmen erfordern.
Letztendlich sollten Sie regelmäßig den Bericht zur Indexabdeckung von Google durchsuchen und eingreifen, wenn er nicht mit Ihrer Indexierungsstrategie übereinstimmt.