
Google zapomina o adresach URL w kolejce indeksowania
Opublikowany: 2021-12-21Błędy indeksowania nie są niespotykane. Google od dłuższego czasu ma problemy z indeksowaniem. Mogą przytrafić się każdemu bez winy właściciela serwisu, niezależnie od wielkości serwisu. Tylko w zeszłym roku miał miejsce przypadek błędów indeksowania obejmujących indeksowanie mobilne i kanonizację.
Kilka miesięcy temu osobiście doświadczyłem błędu indeksowania, kiedy okazało się, że mój Ultimate Guide to Indexing SEO nie został zindeksowany.
Po dokładnym zbadaniu okazało się, że Google zindeksował niewłaściwą wersję adresu URL bez wyraźnego powodu. Możesz dowiedzieć się więcej o tym konkretnym błędzie w moim artykule My Ultimate Guide to Indexing SEO Isn Indexed.
Na początku tego roku znalazłem kolejny błąd indeksowania, wskazujący na to, że Google może tracić kontrolę nad adresami URL w kolejce indeksowania.
Podzielmy to krok po kroku.
Zapomniany adres URL w kolejce indeksowania Google
6 października opublikowaliśmy artykuł: Rendering SEO: How Google Digests Your Content. Artykuł był zapisem rozmowy Bartosza Góralewicza z Onely, Martina Splitta z Google i Jasona Barnarda z Kalicube.
Niestety w ciągu trzech tygodni od daty publikacji artykuł nie przyniósł żadnego ruchu z Google.
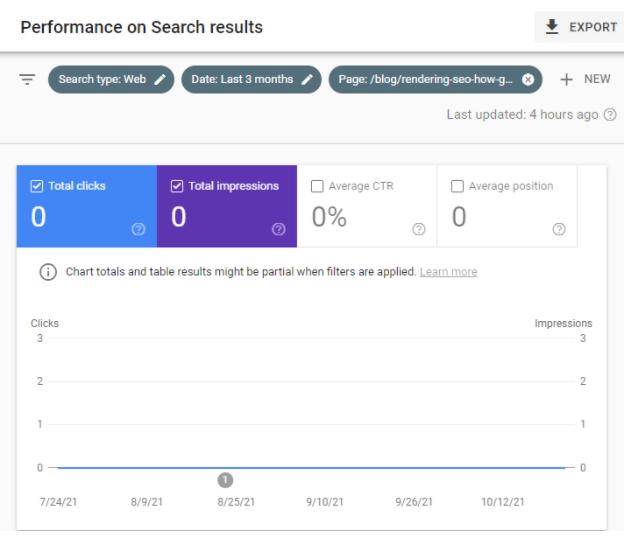
Wydało mi się to dziwne — kolejny interesujący artykuł nieindeksowany przez Google? Czy Google cierpi na inny błąd indeksowania?
Ponieważ staram się zrozumieć tajniki procesu indeksowania Google, postanowiłem przeprowadzić małe dochodzenie.
Sprawdziłem, co Google Search Console ma do powiedzenia na temat tego adresu URL.
GSC stwierdził, że ten adres URL to „Wykryty – obecnie nieindeksowany”.
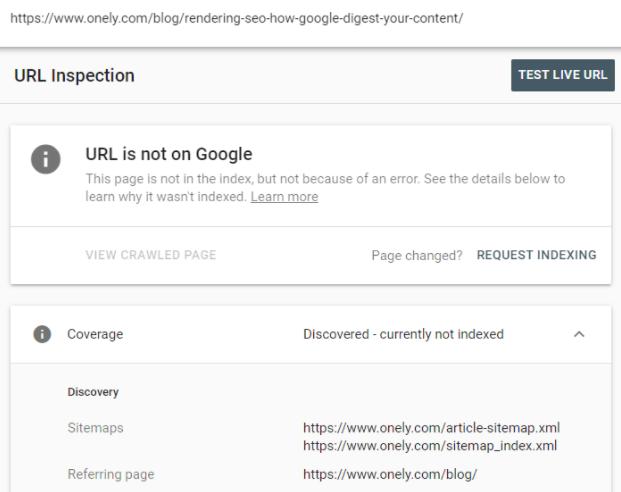
Gdy zajrzysz do dokumentacji Google, znajdziesz następujące wyjaśnienie stanu:
Odnalezione – obecnie nieindeksowane: Strona została znaleziona przez Google, ale jeszcze nie została zindeksowana.źródło: Google
Stan adresu URL wydawał się wysoce nieprawdopodobny. Nie mogłem uwierzyć, że Google nie zindeksowało tej strony w ciągu trzech tygodni od publikacji w stosunkowo niewielkiej witrynie.
Sprawdziłem więc nasze logi serwera.
Logi serwera pozwalają na zbadanie ruchu przychodzącego do Twojej witryny. Zawierają informacje o każdym żądaniu, w tym jego czas i datę, ciąg agenta użytkownika, adres IP itp. Dzięki tym informacjom mogłem sprawdzić, czy (i kiedy) Googlebot był na tej stronie.
Co zaskakujące, okazało się, że Googlebot odwiedził tę stronę w dniu, w którym opublikowaliśmy artykuł!
W tym momencie miałem dwie kluczowe informacje:
- Dane z Google Search Console, że Googlebot jeszcze nie odwiedził strony, nie były prawdziwe. Dzienniki serwera wykazały, że Googlebot odwiedził adres URL w dniu publikacji artykułu.
- Nie było to tylko zgłoszenie błędu z Google Search Console. Strona nie generowała żadnego ruchu organicznego, więc było wyraźnie więcej poważnych problemów niż tylko błędy w raporcie.
Więcej witryn cierpi z powodu błędu indeksowania Google
Chciałem dowiedzieć się więcej o tym błędzie i jego skali, więc zbadałem większą próbkę stron internetowych, aby wyciągnąć praktyczne wnioski.

Zebrałem logi serwera z czterech innych stron internetowych i zagłębiłem się w dane.
Okazało się, że 100% zbadanych przeze mnie witryn cierpi na ten właśnie problem. Googlebot odwiedził wiele adresów URL , które zostały błędnie sklasyfikowane przez Google Search Console jako:
- Odnalezione – aktualnie nieindeksowane lub
- Nieznany.
W przypadku statusu Nieznany wygląda na to, że Google twierdzi, że nigdy nie odwiedził strony i nie ma pamięci nawet o odkryciu adresu URL.

Odkryłem, że problem występował na jednej z testowanych stron nawet 6 miesięcy po pierwszym odwiedzeniu go przez Google. Według logów serwera ostatnia wizyta miała miejsce 7 marca, ale 27 października status nadal był nieznany.
Wygląda na to, że Google czasami zapomina o adresach URL w pewnym momencie procesu indeksowania. Nie jest jasne, czy wyszukiwarka po prostu gubi niektóre adresy URL, czy celowo je pomija.
Tak czy inaczej konsekwencje są poważne. Zapomniane strony nie uzyskują żadnego ruchu organicznego.
Możliwe rozwiązanie błędu
Dan Shure podzielił się ciekawym przypadkiem związanym z błędem zapomnianego adresu URL.
Czy „Odnaleziono — ale obecnie nie zindeksowano” może umieścić adres URL na jakiejś „czarnej liście”?
Pomyślałem, że podzielę się czymś dziwnym i interesującym, co wydarzyło się z kilkoma wpisami na blogu klienta..
(1/5) (Nienawidzę robić wątków, ale to wymaga trochę szczegółów)
— Dan Shure (@dan_shure) 8 listopada 2021
Wygląda na to, że zmiana adresu URL wystarczyła do rozwiązania problemu.
Dan Shure nie był jedynym, który testował to rozwiązanie. Frank Olivo zindeksował prawie ⅓ swoich artykułów, zmieniając ich adresy URL!
To zadziałało w przypadku około 12 z 38 artykułów, w których to wypróbowaliśmy. Wszystkie zindeksowane tego samego dnia, w którym ponownie opublikowaliśmy. Pozostałe artykuły są wciąż „odkrywane” prawie miesiąc później.
— Frank Olivo (@FrancoOlivo) 7 grudnia 2021
Możliwe, że te adresy URL znalazły się we wzorcach adresów URL niskiej jakości, więc Google ich nie indeksował i dlatego sklasyfikował je jako „Odkryte – obecnie nieindeksowane” w Google Search Console.
Możesz przekonać Google do traktowania strony jako nowej i ponownego jej indeksowania, zmieniając adres URL. To rozwiązanie może pomóc w zindeksowaniu strony, ale jest to tylko obejście. Nie zapobiega to ponownemu wystąpieniu problemu. Google powinien rozwiązać problem, a błąd powinien zostać naprawiony na stałe.
Zawijanie
Jak opisano w artykule, istnieje poważny problem z indeksowaniem. Nie jest to tak oczywiste i spektakularne jak poprzednie błędy indeksowania (np. związane z kanonizacją), ale nadal może negatywnie wpłynąć na każdą stronę internetową.
Jeśli jesteś pracownikiem Google i chcesz zbadać problem, mogę udostępnić kilka przykładowych adresów URL, których dotyczy ten problem.
Czy zauważyłeś ten błąd lub podobny błąd indeksowania w swojej witrynie? Daj mi znać!