
GoogleはインデックスキューのURLについて忘れています
公開: 2021-12-21インデックス作成のバグは前代未聞ではありません。 グーグルはかなり前からインデックス作成に問題を抱えています。 それらは、Webサイトのサイズに関係なく、Webサイトの所有者の過失がなくても誰にでも発生する可能性があります。 昨年、モバイルのインデックス作成と正規化に関連するインデックス作成のバグが発生しました。
数ヶ月前、私の究極のインデックス作成ガイドSEOがインデックスに登録されていなかったことが判明したとき、私は個人的にインデックス作成のバグを経験しました。
徹底的に調査した結果、Googleが明確な理由もなく間違ったバージョンのURLをインデックスに登録していることがわかりました。 この特定のバグについて詳しくは、私の記事「SEOのインデックス作成に関する究極のガイド」で詳しく知ることができます。
今年の初めに、Googleがインデックスキュー内のURLを追跡できなくなっている可能性があることを示す、別のインデックスバグを発見しました。
少しずつ分解していきましょう。
GoogleのインデックスキューでURLを忘れた
10月6日に、記事「 SEOのレンダリング:Googleがコンテンツを消化する方法」を公開しました。 この記事は、OnelyのBartosz Goralewicz、GoogleのMartin Splitt、KalicubeのJasonBarnardの間の会話の記録でした。
残念ながら、公開日から3週間の間、この記事はGoogleからのトラフィックをまったくもたらしませんでした。
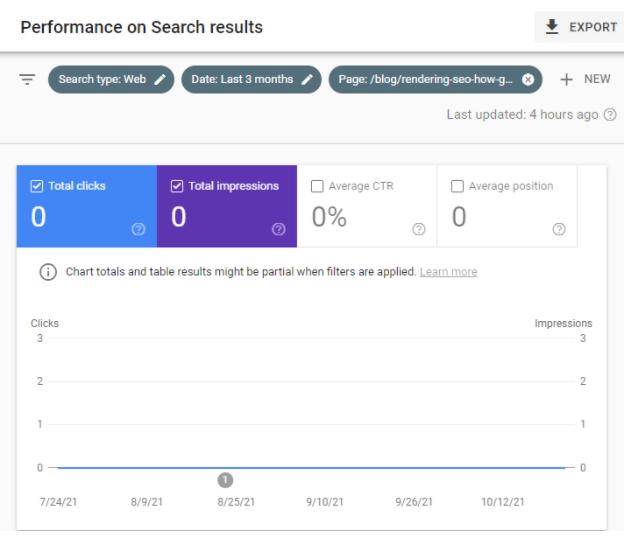
私はそれが奇妙だと思った—グーグルによって索引付けされていない別の興味深い記事? Googleは別のインデックス作成のバグに悩まされていますか?
私はGoogleのインデックス作成プロセスの詳細を理解しようと努力しているので、少し調査することにしました。
このURLについてGoogle検索コンソールが何を言っているかを確認しました。
GSCは、このURLは「検出されました–現在インデックスに登録されていません」と述べています。
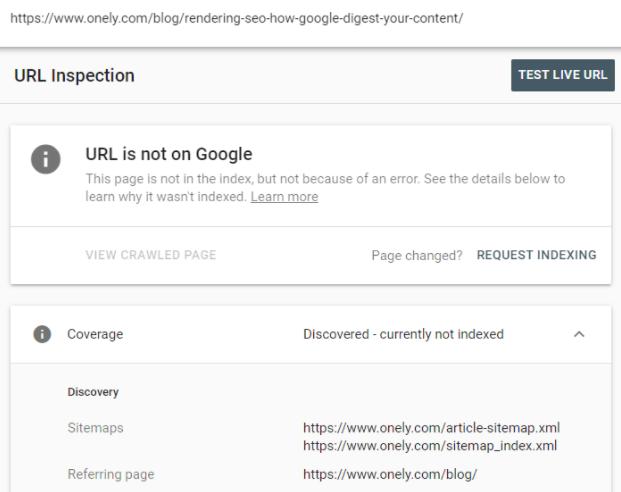
Googleのドキュメントを調べると、ステータスに関する次の説明が見つかります。
検出済み–現在インデックスに登録されていません:ページはGoogleによって検出されましたが、まだクロールされていません。出典: Google
URLのステータスは非常にありそうもないようでした。 比較的小さなウェブサイトで公開されてから3週間以内にGoogleがこのページをクロールしなかったとは信じられませんでした。
そこで、サーバーログを確認しました。
サーバーログを使用すると、Webサイトに到達するトラフィックを調べることができます。 日時、ユーザーエージェント文字列、IPアドレスなど、各リクエストに関する情報が含まれています。この情報のおかげで、Googlebotがこのページにあるかどうか(いつ)を確認できました。

驚いたことに、記事を公開した日にGooglebotがそのページにアクセスしたことがわかりました。
この時点で、私は2つの重要な情報を持っていました。
- GooglebotがまだページにアクセスしていないというGoogle検索コンソールのデータは真実ではありませんでした。 サーバーログは、記事が公開された日にGooglebotがURLにアクセスしたことを証明しました。
- これは、Google検索コンソールからの単なる報告バグではありませんでした。 このページにはオーガニックトラフィックが発生していなかったため、レポートの間違いよりも明らかに重大な問題がありました。
より多くのウェブサイトがGoogleのインデックスバグに苦しんでいます
このバグとその規模についてもっと知りたいと思ったので、より多くのWebサイトのサンプルを調べて、実用的な結論を導き出しました。
他の4つのWebサイトからサーバーログを収集し、データを掘り下げました。
私が調べたウェブサイトの100%がこの問題に苦しんでいることがわかりました。 GooglebotがアクセスしたURLは複数ありましたが、GoogleSearchConsoleによって次のように誤って分類されました。
- 検出済み–現在インデックスが作成されていない、または
- わからない。
不明ステータスの場合、 Googleはページにアクセスしたことがなく、URLを検出したことすら記憶していないと述べているようです。

Googleが最初にアクセスしてから6か月後でも、テストしたページの1つに問題が存在することを発見しました。 サーバーのログによると、最後の訪問は3月7日でしたが、10月27日、ステータスはまだ不明でした。
Googleは、インデックス作成パイプラインのある時点でURLを忘れることがあるようです。 検索エンジンが一部のURLを見失っているだけなのか、それとも意図的にそれらを省略しているのかは不明です。
いずれにせよ、結果は深刻です。 忘れられたページは、オーガニックトラフィックを取得しません。
バグの可能な解決策
Dan Shureは、忘れられたURLのバグに関連する興味深い事例を共有しました。
「発見されたが、現在はインデックスに登録されていない」と、URLをある種の「ブラックリスト」に入れることができますか?
クライアントのいくつかのブログ投稿で起こった奇妙で面白いことを共有したいと思いました。
(1/5)(スレッドを実行するのは嫌いですが、これには少し詳細が必要です)
— Dan Shure(@dan_shure)2021年11月8日
この問題を解決するには、URLを変更するだけで十分だったようです。
このソリューションをテストしたのはDanShureだけではありません。 フランク・オリヴォは、URLを変更することで、彼の記事のほぼ1/3をインデックスに登録しました。
これは、私たちが試した38の記事のうち約12で機能しました。 再公開した同じ日にすべてのインデックスが作成されました。 残りの記事は、ほぼ1か月後もまだ「発見」されています。
—フランク・オリヴォ(@FrancoOlivo)2021年12月7日
これらのURLは低品質のURLのパターンに該当する可能性があるため、Googleはそれらをクロールしておらず、Google検索コンソールで「検出済み–現在インデックスに登録されていません」として分類しました。
ページを新しいものとして扱い、URLを変更して再度クロールするように、Googleを説得することができます。 このソリューションは、ページのインデックスを作成するのに役立つ場合がありますが、これは回避策にすぎません。 問題の再発を防ぐことはできません。 Googleは問題に対処する必要があり、バグは恒久的に修正する必要があります。
まとめ
記事で説明されているように、インデックス作成には重大な問題があります。 これは、以前のインデックス作成のバグ(たとえば、正規化に関連する)ほど明白で壮観ではありませんが、それでもWebサイトに悪影響を与える可能性があります。
あなたがGoogleの従業員であり、問題を調査したい場合は、この問題が発生したサンプルURLをいくつか共有できます。
このバグまたはサイトの同様のインデックス作成のバグに気づきましたか? お知らせ下さい!