
Combiner Google Analytics et Shopify : créer un entrepôt de données de commerce électronique dans BigQuery
Publié: 2023-02-15Google Analytics est un excellent outil qui vous permet de comprendre le comportement des utilisateurs de ceux qui visitent votre site Web. Tandis que Shopify est fantastique pour fournir une couverture détaillée des performances du point de vue du commerce électronique. Les deux sont excellents dans ce qu'ils font, mais il arrive un moment où les données de Shopify et Google Analytics (GA) prises isolément ne parviennent pas à fournir les informations plus approfondies que vous pourriez souhaiter. Bien que chacun ait la capacité de fournir des informations puissantes, il existe un niveau de compréhension beaucoup plus élevé qui peut être obtenu en combinant les données.
Dans cet exemple particulier, nous expliquerons comment nous y sommes parvenus pour nos amis de Pooch & Mutt, une entreprise basée au Royaume-Uni qui produit des aliments pour chiens naturels et sains. Nous voulions améliorer les informations en prenant les données collectées dans Google Analytics et en les utilisant conjointement avec les données de commerce électronique de Shopify, ainsi que les données d'abonnement de Recharge et en les associant aux anciennes données d'abonnement de Bold. En utilisant cette variété de sources de données, nous pourrions construire une image plus riche et plus complète.
Ce blog cherchera à fournir un aperçu de la façon dont nous agrégeons ces données, puis à décrire les processus de réflexion derrière leur combinaison pour extraire et visualiser ces informations basées sur les données. Plus précisément, nous expliquerons comment nous avons procédé pour répondre aux trois questions suivantes ;
- Quels canaux génèrent des abonnements ?
- Combinaisons de paniers au-delà de GA ; quels sont les paniers les plus appréciés des abonnés et des non-abonnés et lesquels sont les plus rémunérateurs ?
- Combien de temps et combien d'achats en moyenne faut-il avant qu'un utilisateur devienne abonné ?
Méthodologie
Avant de répondre à ces questions, voyons d'abord comment nous avons collecté toutes les données de leurs plates-formes respectives dans un emplacement centralisé et créé un tableau que nous pourrions utiliser pour rassembler ces données.
Structure de données
Nous avons choisi d'utiliser BigQuery (BQ) pour centraliser les données en raison de sa polyvalence et de sa capacité à gérer la combinaison d'ensembles de données. L'organigramme ci-dessous met en évidence les liens généraux entre les données et la manière dont cela a été réalisé :
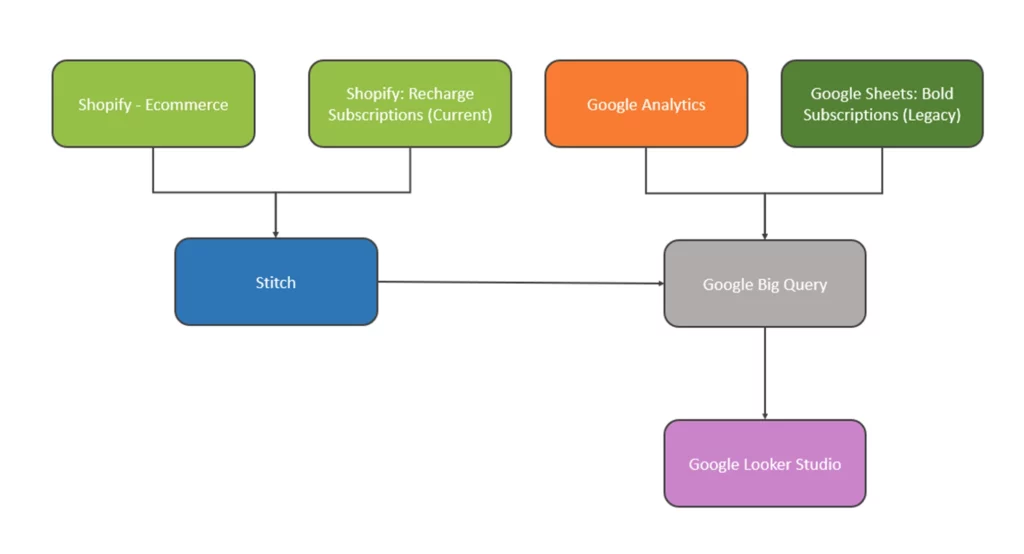
Point
Stitch est un outil abordable qui vous permet d'extraire et de charger des données dans des entrepôts de données prédéfinis.
Nous nous sommes facilement connectés à Shopify et Recharge via Stitch, où nous avons simplement sélectionné les tables que nous voulions. Dans ce cas, les tableaux les plus importants sont les « clients » et les « abonnements » de Recharge, et les « commandes » de Shopify.
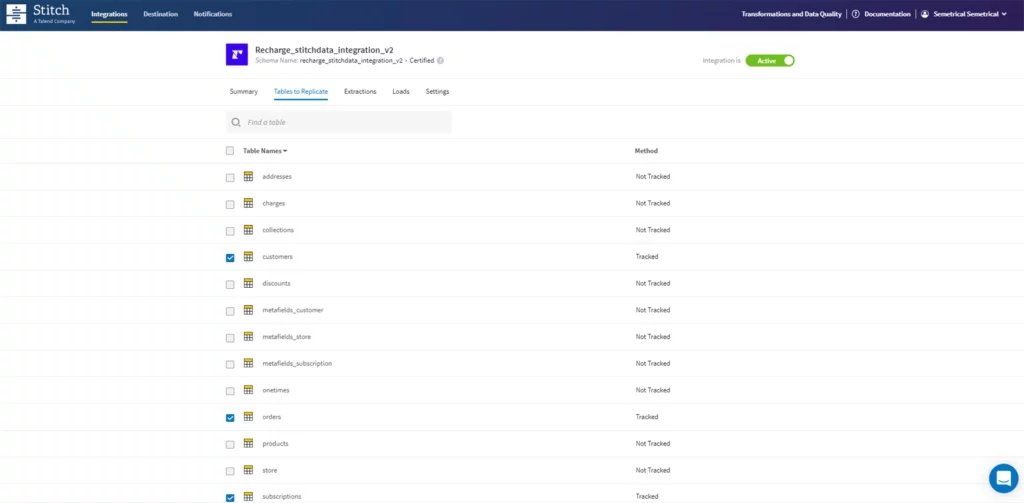

Ces informations sont ensuite synchronisées avec BQ toutes les 6 heures via le processus de planification automatisé de Stitch.
Gras
Pour les données historiques sur les abonnés, nous avons pris une exportation finale et l'avons téléchargée sur BQ via Google Sheets.
Google Analytics
Alors que Stitch peut également être utilisé pour cela, nous avons choisi d'utiliser RStudio pour obtenir ces données dans BQ. Si vous souhaitez en savoir plus sur la façon dont vous pouvez le faire, vous pouvez lire un blog de notre propre expert R Studio Danny Smith sur la façon d'utiliser l'API GA avec R.
Construire une table maîtresse
Une fois que nous avions toutes les données requises dans BQ, nous pouvions commencer à les combiner. Les étapes que nous avons suivies pour ce faire sont les suivantes :
- Nous avons combiné et aligné les anciennes données d'abonnés de Bold avec les données d'abonnés actuelles de Recharge.
- Nous avons ensuite extrait les données de commerce électronique de GA qui incluent les ID de commande (par exemple, SPFYXXXXX), ainsi que la source, le support et le canal.
- Nous avons créé de nouvelles colonnes basées sur les tableaux des données GA et des abonnés syndiqués avant de rejoindre les données de commande Shopify. Dans ce cas, certaines de ces colonnes supplémentaires incluses ;
- Identifiant de l'abonné "actif"
- Date d'origine de la souscription
- Source, support et canal de commande
- Première ou nouvelle commande client
- Ensuite, nous avons sélectionné les champs pertinents à partir des données de commande Shopify auxquelles nous voulions joindre ces nouvelles données. Quelques exemples clés sont;
- N ° de client
- numéro de commande
- Date de commande
- UGS
- Quantité d'articles
- Prix de l'article
- Prix total de la commande
- Code de réduction
- Montant de la remise
- Tag (utilisé comme méthode supplémentaire pour classer les abonnés par rapport aux non-abonnés)
- La dernière étape ici consistait à créer quelques colonnes supplémentaires pour traiter plus facilement les lignes en double pour différents éléments dans le même ordre ;
- Prix moyen
- Avgdiscount
- Statut d'abonné (tags + s'ils sont présents dans le tableau Bold & Recharge)
Nous avons ensuite programmé cette requête pour qu'elle s'exécute une fois par jour et avons utilisé le résultat comme table maître pour les requêtes supplémentaires. Cela signifiait que nous n'avions pas à exécuter la requête complète plusieurs fois, car il s'agit d'un tableau statique qui ne se met à jour que lorsqu'il est programmé, plutôt qu'à chaque fois qu'une demande est faite via le tableau de bord Looker Studio.

Connaissances
Maintenant que nous avons couvert la méthodologie et décrit les étapes suivies pour obtenir toutes les données dont nous avons besoin, nous pouvons passer à la discussion sur la manière dont nous avons utilisé ces données pour répondre à nos questions.
Quels canaux génèrent des abonnements ?
- Pour calculer cela, nous avons examiné les premières commandes passées par les clients, en utilisant le champ que nous avons créé dans la table principale qui renvoie soit "Premier" soit "Répéter" en fonction de la date de la première commande.
- À l'aide des colonnes supplémentaires de groupement de chaînes et de statut d'abonné dans le tableau principal, nous sommes en mesure d'examiner les premières commandes de personnes qui sont devenues abonnés, soit lors du premier achat, soit lors d'un achat répété, et à quelle chaîne elles ont été attribuées dans GA .
- En supprimant l'étape consistant à ne regarder que les abonnés, nous pourrions également voir quels canaux génèrent principalement les premiers achats.
Combinaisons de paniers au-delà de GA ; quels sont les paniers les plus appréciés des abonnés et des non-abonnés, et lesquels sont les plus rémunérateurs ?
- En utilisant la fonction STRING_AGG, nous avons pu combiner les différents produits d'une seule commande sur une seule ligne, séparés par ' | '. Cela crée essentiellement un panier pour chaque commande.
- En plus de ces informations, nous avons additionné les revenus de chacun de ces articles en tant que "Total du panier", l'objectif étant d'avoir une ligne par commande avec toutes les informations pertinentes.
- Bien sûr, il y a beaucoup d'écart entre les produits (saveur, taille, etc.), nous avons donc ajouté une colonne qui a supprimé cet écart pour examiner les combinaisons de base du panier de produits.
- Nous avons ensuite utilisé 'ROW_NUMBER() OVER (PARTITION BY Transaction_ID) AS Identifier' pour attribuer des valeurs séquentielles à chaque commande. Cela a ensuite été utilisé comme filtre dans le tableau de bord pour isoler les lignes individuelles qui contenaient encore toutes les informations.
Combien de temps et combien d'achats en moyenne faut-il avant qu'un utilisateur devienne abonné ?
- À l'aide de notre table principale, nous avons extrait tous les identifiants de clients dont nous savions qu'ils étaient abonnés et avons pris leur première date d'abonnement.
- Nous avons ensuite pris la date minimum de commande et utilisé la fonction DATE_DIFF pour calculer la différence entre ces dates en 'jours'.
- La dernière étape a attiré le canal et le nombre moyen de jours avant de s'abonner, ce qui a abouti à un tableau indiquant le nombre moyen de jours avant que les clients ne deviennent généralement abonnés.
- Pour calculer le nombre moyen de commandes passées par les clients avant de devenir abonnés, nous avons simplement divisé le nombre d'identifiants de commande uniques par le nombre d'identifiants clients uniques lorsqu'ils étaient « abonnés » et qu'ils avaient des dates de commande inférieures à la date d'abonnement minimum.
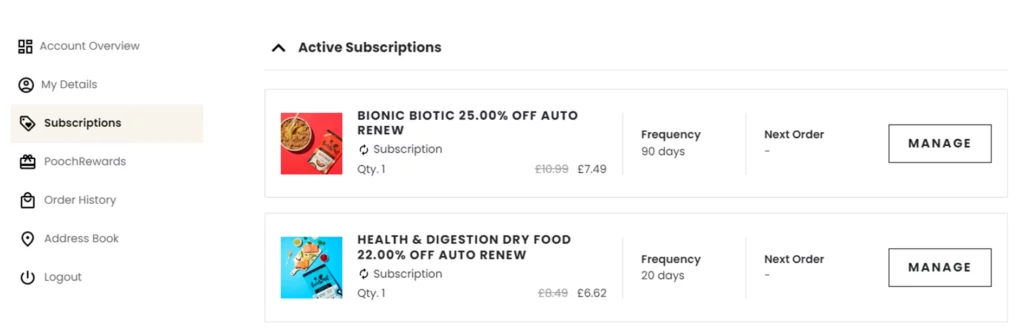
Ce ne sont là que quelques exemples au niveau de la surface des vues que nous avons générées à l'aide de ces rapports. Avec les données, les possibilités sont infinies - d'autres exemples de ce projet incluent l'examen de la valeur à vie du client sous différents angles et l'évaluation de l'utilisation des codes de réduction et de leur impact sur le comportement à vie des clients. Grâce à ces informations, ils peuvent être utilisés pour compléter les décisions commerciales. Par exemple, sachant qu'il faut en moyenne 3 commandes avant de devenir abonné, vous pouvez chercher à partager des offres et des incitations qui incitent les clients à s'abonner après 2 achats. Les résultats peuvent alors être mesurés ultérieurement.
Résumé
Cette étude de cas démontre le potentiel d'informations extrêmement précieuses basées sur les données qui peuvent être obtenues grâce à la combinaison de plusieurs sources de données, de GA à Shopify et au-delà. Une fois cette infrastructure créée, elle peut être maintenue de manière dynamique et utilisée pour rendre compte de nombreux aspects différents de l'entreprise.
Si les questions auxquelles nous avons répondu dans ce blog sont similaires à celles qui pourraient vous intéresser pour votre propre entreprise, vous pouvez nous contacter en remplissant notre formulaire de contact.