
Hukuk Yüksek Lisansı İçin Çıkarım Motorlarını Seçme ve Yapılandırma
Yayınlanan: 2024-04-02Çıkarım Motorlarına Giriş
Çıkarım sürecinin farklı aşamalarında ortaya çıkan verimsizlikleri azaltmak için geliştirilen birçok optimizasyon tekniği vardır. Çıkarımı basit transformatör/tekniklerle ölçekte ölçeklendirmek zordur. Çıkarım motorları optimizasyonları tek bir pakette toplayarak çıkarım sürecinde bize kolaylık sağlar.
Çok küçük bir anlık test seti veya hızlı referans için, çıkarımı yapmak üzere vanilya transformatör kodunu kullanabiliriz.
Çıkarım motorlarının ortamı hızla gelişiyor; birden fazla seçeneğimiz olduğundan, belirli kullanım durumları için en iyinin en iyisini test etmek ve kısa listeye almak önemlidir. Aşağıda yaptığımız bazı çıkarım motoru deneyleri ve bizim durumumuz için neden işe yaradığını bulmamızın nedenleri yer almaktadır.
İnce ayarlı Vicuna-7B modelimiz için şunları denedik:
- TGI
- vLLM
- Afrodit
- Optimum-Nvidia
- PowerInfer
- LLAMACPP
- Ctranslate2
Bu motorları ayarlamak için github sayfasını ve onun hızlı başlangıç kılavuzunu inceledik, PowerInfer, LlaamaCPP, Ctranslate2 çok esnek değiller ve bahsedilen diğer motorlarla karşılaştırıldığında sürekli gruplama, sayfalanmış dikkat ve ortalamanın altında performans gibi pek çok optimizasyon tekniğini desteklemiyor .
Daha yüksek verim elde etmek için çıkarım motoru/sunucusu, belleği ve bilgi işlem yeteneklerini en üst düzeye çıkarmalı ve hem istemci hem de sunucu, sunucuyu her zaman çalışır durumda tutmak için istekleri sunarken paralel/asenkron bir şekilde çalışmalıdır. Daha önce de belirtildiği gibi, PagedAttention, Flash Attention, Sürekli toplu işleme gibi optimizasyon tekniklerinin yardımı olmadan her zaman optimumun altında performansa yol açacaktır.
TGI, vLLM ve Afrodit bu açıdan daha uygun adaylardır ve aşağıda belirtilen birçok deneyi yaparak, çıkarımdan maksimum performansı çıkaracak en uygun konfigürasyonu bulduk. Sürekli toplu işlem ve sayfalanmış dikkat gibi teknikler varsayılan olarak etkindir; spekülatif kod çözmenin aşağıdaki testler için çıkarım motorunda manuel olarak etkinleştirilmesi gerekir.
Çıkarım Motorlarının Karşılaştırmalı Analizi
TGI
TGI'yı kullanmak için github sayfasının 'Başlarken' bölümüne gidebiliriz, burada docker TGI motorunu yapılandırmanın ve kullanmanın en basit yoludur.
Metin oluşturma başlatıcı argümanları -> bu liste, sunucu tarafında kullanabileceğimiz farklı ayarları gösterir. Birkaç önemli olan,
- –max-input-length : modelin maksimum giriş uzunluğunu belirler, varsayılan 1024 olduğu için bu çoğu durumda değişiklik gerektirir.
- –max-toplam-belirteçler: max toplam jetonlar, yani giriş + çıkış jeton uzunluğu.
- –speculate, –quantiz, –max-concurrent-requests -> varsayılan yalnızca 128'dir ve bu açıkça daha azdır.
Yerel ince ayarlı bir modeli başlatmak için,
docker run –gpus cihazı=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-toplam-tokens 4000 –spekülasyon 2
Hub'dan bir model başlatmak için,
model=”lmsys/vicuna-7b-v1.5″; hacim=$PWD/veri; jeton=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text- Generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-toplam-tokens 4000 –spekülasyon 2
Daha detaylı anlaşılması için chatGPT'den yukarıdaki komutu açıklamasını isteyebilirsiniz. Burada çıkarım sunucusunu 9091 portunda başlatıyoruz. Sunucuya istek göndermek için herhangi bir dildeki istemciyi kullanabiliriz. Metin Oluşturma Çıkarımı API'si -> istek için tüm uç noktalardan ve yük parametrelerinden bahseder.
Örneğin
yük=”<burada sor>”
curl -XPOST “0.0.0.0:9091/generate” -H “Content-Type: application/json” -d “{“inputs”: $payload, “parameters”: {“max_new_tokens”: 400,”do_sample”:false ,”best_of”: null,”repetition_penalty”: 1,”return_full_text”: false,”seed”: null,”stop_sequences”: null,”temperature”: 0,1,”top_k”: 100,”top_p”: 0,3,” kes”: null,”typical_p”: null,”filigran”: false,”decoder_input_details”: false}}”
Birkaç gözlem,
- Gecikme maksimum token-tokenlarla artar; bu da açıktır ki eğer uzun metinleri işliyorsak toplam süre artacaktır.
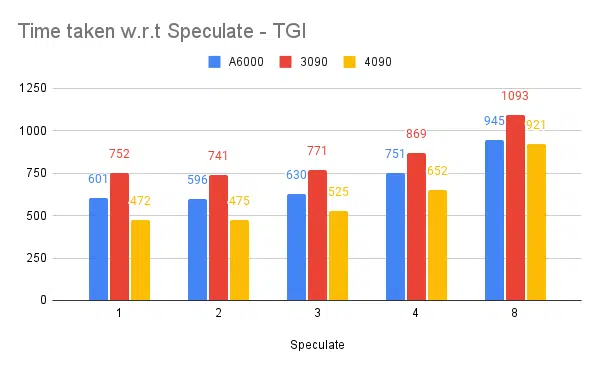
- Spekülasyon yardımcı olur ancak kullanım durumuna ve girdi-çıktı dağıtımına bağlıdır.
- Eetq nicemleme, verimi artırmada en fazla yardımcı olur.
- Çoklu GPU'nuz varsa, her GPU'da 1 API çalıştırmak ve bu çoklu GPU API'lerini bir yük dengeleyicinin arkasında bulundurmak, TGI'nın kendisi tarafından yapılan parçalamadan daha yüksek verim sağlar.
vLLM
Bir vLLM sunucusunu başlatmak için OpenAI uyumlu bir REST API sunucusu/docker kullanabiliriz. Başlamak çok basit, Docker — vLLM ile Dağıtımı takip edin, eğer yerel bir model kullanacaksanız, birimi ekleyin ve yolu model adı olarak kullanın,
docker run –çalışma zamanı nvidia –gpus cihazı=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:en son – model / model
Yukarıda belirtilen 8000 bağlantı noktasında bir vLLM sunucusu başlatılacaktır, her zaman olduğu gibi argümanlarla oynayabilirsiniz.
Gönderi isteğinde bulunun,
“`kabuk
yük=”<burada sor>”
curl -XPOST -m 1200 “0.0.0.0:8000/v1/tamamlamalar” -H “İçerik Türü: application/json” -d “{“istem”: $payload,”model”:”/model” ,”max_tokens ”: 400,”top_p”: 0,3, “top_k”: 100, “sıcaklık”: 0,1}”
“`
Afrodit
“`kabuk
pip kurulumu afrodit motoru
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
“`
Veya
“`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus cihazı=1 –ipc host alpindale/aphrodite-engine
“`
Aphrodite, başlangıç bölümünde de belirtildiği gibi hem pip hem de docker kurulumunu sağlar. Docker'ın döndürülmesi ve test edilmesi genellikle nispeten daha kolaydır. Kullanım seçenekleri, sunucu seçenekleri nasıl istekte bulunacağımıza yardımcı olur.

- Aphrodite ve vLLM'nin her ikisi de openAI sunucu tabanlı veri yüklerini kullanır, dolayısıyla belgelerini kontrol edebilirsiniz.
- Deepspeed-mii'yi denedik, eski kod tabanından yeni kod tabanına geçiş aşamasında olduğundan (denediğimizde) güvenilir ve kullanımı kolay görünmüyor.
- Optimum-NVIDIA diğer önemli optimizasyonları desteklemez ve optimumun altında performansla sonuçlanır, ref bağlantısı.
- Geçici paralel istekleri gerçekleştirmek için kullandığımız kodun özeti eklendi.
Metrikler ve Ölçümler
Deneyip bulmak istiyoruz:
- Optimum hayır. istemci/çıkarım motoru sunucusu için iş parçacığı sayısı.
- Bellekteki artışla verim nasıl artıyor?
- Tensör çekirdeklerine göre verim nasıl artıyor?
- İş parçacıklarının istemci tarafından paralel isteklere karşı etkisi.
Kullanımı gözlemlemenin çok temel yolu, linux utils nvidia-smi, nvtop aracılığıyla izlemektir; bu bize kullanılan belleği, hesaplama kullanımını, veri aktarım hızını vb. söyleyecektir.
Başka bir yol da nsys ile GPU kullanarak sürecin profilini çıkarmaktır.
| S.Hayır | GPU | vRAM Bellek | Çıkarım motoru | İş Parçacığı | Zamanlar) | Spekülasyon yapmak |
| 1 | A6000 | 48 /48 GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48 /48 GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48 /48 GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48 /48 GB | TGI | 256 | 568 | – |
Yukarıdaki deneylere dayanarak, 128/256 iş parçacığı, düşük iş parçacığı sayısından daha iyidir ve 256'nın ötesinde genel gider, verimin azalmasına katkıda bulunmaya başlar. Bunun CPU ve GPU'ya bağlı olduğu ve kişinin kendi deneyini gerektirdiği bulunmuştur. | ||||||
| 5 | A6000 | 48 /48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48 /48GB | TGI | 128 | 945 | 8 |
Daha yüksek spekülasyon değeri, ince ayarlı modelimizin daha fazla reddedilmesine neden olur ve dolayısıyla verimi azaltır. Spekülasyon değeri olarak 1/2 iyidir, bu modele bağlıdır ve kullanım durumlarında aynı şekilde çalışacağı garanti edilmez. Ancak sonuç, spekülatif kod çözmenin verimi arttırdığıdır. | ||||||
| 7 | 3090 | 24/24GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24GB | TGI | 128 | 481 | 2 |
4090, A6000'e kıyasla daha az vRAM'e sahip olsa da, daha yüksek tensör çekirdek sayısı ve bellek bant genişliği hızı nedeniyle daha iyi performans gösteriyor. | ||||||
| 8 | A6000 | 24/ 48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2x24/ 48GB | TGI | 128 | 1205 | 2 |
Yüksek Verim için TGI'yi Ayarlama ve Yapılandırma
Python/Ruby gibi seçilen bir betik dilinde ve yapılandırma için aynı dosyayı kullanarak eşzamansız istek ayarlayın:
- Harcanan zaman, dizi oluşturmanın maksimum çıktı uzunluğunu artırır.
- İstemci ve sunucudaki 128/256 iş parçacığı 24, 64, 512'den daha iyidir. Daha düşük iş parçacıkları kullanıldığında, hesaplama yetersiz kullanılır ve 128 gibi bir eşiğin ötesinde ek yük artar ve dolayısıyla verim düşer.
- Go, Python/Ruby gibi dillerde iş parçacığı kullanmak yerine 'GNU paralel' kullanarak eşzamansız isteklerden paralel isteklere geçişte %6'lık bir iyileşme vardır.
- 4090, A6000'den %12 daha yüksek verime sahiptir. 4090, A6000'e kıyasla daha az vRAM'e sahip olsa da, daha yüksek tensör çekirdek sayısı ve bellek bant genişliği hızı nedeniyle daha iyi performans gösteriyor.
- A6000 48 GB vRAM'e sahip olduğundan, ekstra RAM'in verimi artırmaya yardımcı olup olmadığı sonucuna varmak için tablonun 8. deneyinde GPU belleğinin kesirlerini kullanmayı denedik, ekstra RAM'in iyileştirmeye yardımcı olduğunu ancak doğrusal olarak olmadığını görüyoruz. Ayrıca, her API için yarım bellek kullanarak aynı GPU'da 2 API barındırmak gibi bölmeyi denediğinizde, istekleri paralel olarak kabul etmek yerine 2 sıralı API çalışıyormuş gibi davranır.
Gözlemler ve Metrikler
Aşağıda bazı deneylere ait grafikler ve sabit bir girdi setini tamamlamak için harcanan süre verilmiştir; daha düşük süre daha iyidir.
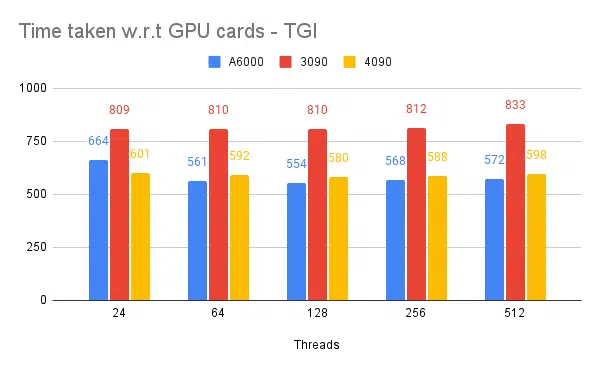
- Bahsedilen istemci tarafı iş parçacıklarıdır. Çıkarım motorunu başlatırken sunucu tarafına değinmemiz gerekiyor.
Spekülasyon testi:
Çoklu Çıkarım Motorları testi:

vLLM ve Afrodit gibi diğer motorlarla yapılan aynı tür deneylerde benzer türde sonuçlar gözlemledik, bu makaleyi yazarken vLLM ve Afrodit henüz spekülatif kod çözmeyi desteklemiyor, bu da bize kalan süreden daha yüksek verim sağladığı için TGI'yı seçmemizi sağlıyor. spekülatif kod çözme.
Ek olarak, aşırı kaynak kullanımına sahip alanların belirlenmesine yardımcı olmak ve performansı optimize etmek için GPU profil oluşturucularını gözlemlenebilirliği artıracak şekilde yapılandırabilirsiniz. Daha fazla bilgi edinin: Nvidia Nsight Geliştirici Araçları - Max Katz
Çözüm
Çıkarım üretme ortamının sürekli olarak geliştiğini ve Yüksek Lisans'ta verimliliğin artırılmasının GPU'nun, performans ölçümlerinin, optimizasyon tekniklerinin ve metin oluşturma görevleriyle ilgili zorlukların iyi anlaşılmasını gerektirdiğini görüyoruz. Bu, iş için doğru araçların seçilmesine yardımcı olur. Geliştiriciler, GPU'nun dahili bileşenlerini ve bunların LLM çıkarımına nasıl karşılık geldiğini anlayarak, örneğin tensör çekirdeklerinden yararlanarak ve bellek bant genişliğini maksimuma çıkararak, uygun maliyetli GPU'yu seçebilir ve performansı etkili bir şekilde optimize edebilir.
Farklı GPU kartları farklı yetenekler sunar ve farklılıkları anlamak, belirli görevler için en uygun donanımı seçmek açısından çok önemlidir. Sürekli gruplama, sayfalanmış dikkat, çekirdek birleştirme ve flaş dikkat gibi teknikler, ortaya çıkan zorlukların üstesinden gelmek ve verimliliği artırmak için umut verici çözümler sunar. Elde ettiğimiz deneylere ve sonuçlara göre TGI, kullanım durumumuz için en iyi seçim gibi görünüyor.
Büyük dil modeliyle ilgili diğer makaleleri okuyun:
LLM Çıkarım Optimizasyonu için GPU Mimarisini Anlamak
Yüksek Lisans Verimini Artırmaya Yönelik Gelişmiş Teknikler