
Memilih dan Mengonfigurasi Mesin Inferensi untuk LLM
Diterbitkan: 2024-04-02Pengantar Mesin Inferensi
Ada banyak teknik optimasi yang dikembangkan untuk mengurangi inefisiensi yang terjadi di berbagai tahapan proses inferensi. Sulit untuk menskalakan inferensi dalam skala besar dengan teknik/transformator vanilla. Mesin inferensi menggabungkan optimasi ke dalam satu paket dan memudahkan kita dalam proses inferensi.
Untuk pengujian ad hoc yang sangat kecil, atau referensi cepat, kita dapat menggunakan kode transformator vanilla untuk melakukan inferensi.
Lanskap mesin inferensi berkembang dengan cepat, karena kita memiliki banyak pilihan, penting untuk menguji dan membuat daftar yang terbaik dari yang terbaik untuk kasus penggunaan tertentu. Di bawah ini, adalah beberapa eksperimen mesin inferensi yang kami buat dan alasan kami mengetahui mengapa eksperimen tersebut berhasil untuk kasus kami.
Untuk model Vicuna-7B kami yang telah disetel dengan baik, kami telah mencobanya
- TGI
- vLLM
- Afrodit
- Optimal-Nvidia
- PowerInfer
- LLAMACPP
- Ctranslate2
Kami membuka halaman github dan panduan memulai cepatnya untuk menyiapkan mesin ini, PowerInfer, LlaamaCPP, Ctranslate2 tidak terlalu fleksibel dan tidak mendukung banyak teknik pengoptimalan seperti pengelompokan berkelanjutan, perhatian halaman, dan kinerja di bawah standar jika dibandingkan dengan mesin lain yang disebutkan .
Untuk mendapatkan throughput yang lebih tinggi, mesin inferensi/server harus memaksimalkan memori dan kemampuan komputasi dan baik klien maupun server harus bekerja secara paralel/asinkron dalam melayani permintaan agar server selalu bekerja. Seperti disebutkan sebelumnya, tanpa bantuan teknik optimasi seperti PagedAttention, Flash Attention, Continuous batching akan selalu menghasilkan kinerja yang kurang optimal.
TGI, vLLM, dan Aphrodite adalah kandidat yang lebih cocok dalam hal ini dan dengan melakukan beberapa eksperimen yang disebutkan di bawah, kami menemukan konfigurasi optimal untuk menghasilkan performa maksimum dari inferensi. Teknik seperti Pengelompokan berkelanjutan dan perhatian halaman diaktifkan secara default, penguraian kode spekulatif perlu diaktifkan secara manual di mesin inferensi untuk pengujian di bawah ini.
Analisis Perbandingan Mesin Inferensi
TGI
Untuk menggunakan TGI, kita bisa melalui bagian 'Memulai' di halaman github, di sini buruh pelabuhan adalah cara paling sederhana untuk mengkonfigurasi dan menggunakan mesin TGI.
Argumen peluncur pembuatan teks -> ini mencantumkan pengaturan berbeda yang dapat kita gunakan di sisi server. Beberapa yang penting,
- –max-input-length : menentukan panjang maksimum input ke model, hal ini memerlukan perubahan dalam banyak kasus, karena defaultnya adalah 1024.
- –total-maks-token: maks total token yaitu panjang token masukan + keluaran.
- –speculate, –quantiz, –max-concurrent-requests -> defaultnya hanya 128 yang jelas lebih kecil.
Untuk memulai model lokal yang disesuaikan,
menjalankan buruh pelabuhan –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generasi-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –spekulasi 2
Untuk memulai model dari hub,
model=”lmsys/vicuna-7b-v1.5″; volume=$PWD/data; token=”<hf_token>”; menjalankan buruh pelabuhan –gpus semua –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generasi-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –spekulasi 2
Anda dapat meminta chatGPT untuk menjelaskan perintah di atas untuk pemahaman lebih detail. Di sini kita memulai server inferensi pada port 9091. Dan kita dapat menggunakan klien bahasa apa pun untuk mengirim permintaan ke server. API Inferensi Pembuatan Teks -> menyebutkan semua titik akhir dan parameter muatan untuk permintaan.
Misalnya
payload=”<prompt di sini>”
curl -XPOST “0.0.0.0:9091/generate” -H “Tipe Konten: application/json” -d “{“inputs”: $payload, “parameters”: {“max_new_tokens”: 400,”do_sample”:false ,”best_of”: null,”repetition_penalty”: 1,”return_full_text”: false,”seed”: null,”stop_sequences”: null,”temperature”: 0.1,”top_k”: 100,”top_p”: 0.3,” truncate”: null,”tipikal_p”: null,”tanda air”: false,”decoder_input_details”: false}}”
Sedikit pengamatan,
- Latensi meningkat dengan max-token-tokens, yang jelas, jika kita memproses teks panjang, maka waktu keseluruhan akan meningkat.
- Berspekulasi membantu tetapi itu tergantung pada kasus penggunaan dan distribusi input-output.
- Kuantisasi Eetq paling membantu dalam meningkatkan throughput.
- Jika Anda memiliki multi GPU, menjalankan 1 API pada setiap GPU dan menempatkan API multi GPU ini di belakang penyeimbang beban akan menghasilkan throughput yang lebih tinggi dibandingkan sharding oleh TGI itu sendiri.
vLLM
Untuk memulai server vLLM, kita dapat menggunakan server/buruh pelabuhan REST API yang kompatibel dengan OpenAI. Sangat mudah untuk memulai, ikuti Deployment dengan Docker — vLLM, jika Anda ingin menggunakan model lokal, lampirkan volume dan gunakan jalur sebagai nama model,
menjalankan buruh pelabuhan –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – model /model
Di atas akan memulai server vLLM pada port 8000 yang disebutkan, seperti biasa Anda dapat bermain-main dengan argumen.
Buat permintaan posting dengan,
“`cangkang
payload=”<prompt di sini>”
curl -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “Jenis Konten: aplikasi/json” -d “{“prompt”: $payload,”model”:”/model” ,”max_tokens ”: 400,”top_p”: 0,3, “top_k”: 100, “suhu”: 0,1}”
“`
Afrodit
“`cangkang
pip install mesin aphrodite
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
“`
Atau
“`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –perangkat GPU=1 –ipc host alpindale/aphrodite-engine

“`
Aphrodite menyediakan instalasi pip dan buruh pelabuhan seperti yang disebutkan di bagian memulai. Docker umumnya relatif lebih mudah untuk dijalankan dan diuji. Opsi penggunaan, opsi server membantu kami cara membuat permintaan.
- Aphrodite dan vLLM keduanya menggunakan payload berbasis server openAI, sehingga Anda dapat memeriksa dokumentasinya.
- Kami mencoba deepspeed-mii, karena dalam keadaan transisi (saat kami mencoba) dari basis kode lama ke basis kode baru, sepertinya tidak dapat diandalkan dan mudah digunakan.
- Optimum-NVIDIA tidak mendukung optimasi besar lainnya dan menghasilkan kinerja suboptimal, tautan ref.
- Menambahkan intisari, kode yang kami gunakan untuk melakukan permintaan paralel ad hoc.
Metrik dan Pengukuran
Kami ingin mencoba dan menemukan:
- Tidak optimal. utas untuk klien/server mesin inferensi.
- Bagaimana throughput tumbuh dan meningkatkan memori
- Bagaimana throughput meningkatkan inti tensor.
- Pengaruh thread vs permintaan paralel oleh klien.
Cara yang sangat mendasar untuk mengamati pemanfaatannya adalah dengan menontonnya melalui linux utils nvidia-smi, nvtop, ini akan memberi tahu kita memori yang digunakan, pemanfaatan komputasi, kecepatan transfer data, dll.
Cara lainnya adalah dengan memprofilkan proses menggunakan GPU dengan nsys.
| S.Tidak | GPU | Memori vRAM | Mesin inferensi | benang | Waktu) | Berspekulasi |
| 1 | A6000 | 48 /48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48 /48GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48 /48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48 /48GB | TGI | 256 | 568 | – |
Berdasarkan percobaan di atas, thread 128/256 lebih baik daripada jumlah thread yang lebih rendah dan lebih dari 256 overhead mulai berkontribusi terhadap pengurangan throughput. Hal ini ternyata bergantung pada CPU dan GPU, dan memerlukan eksperimen sendiri. | ||||||
| 5 | A6000 | 48 /48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48 /48GB | TGI | 128 | 945 | 8 |
Nilai spekulasi yang lebih tinggi menyebabkan lebih banyak penolakan pada model kami yang telah disesuaikan sehingga mengurangi throughput. 1/2 karena nilai spekulasi baik-baik saja, ini bergantung pada model dan tidak dijamin berfungsi sama di seluruh kasus penggunaan. Namun kesimpulannya adalah decoding spekulatif meningkatkan throughput. | ||||||
| 7 | 3090 | 24/24GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24GB | TGI | 128 | 481 | 2 |
Meskipun 4090 memiliki vRAM yang lebih sedikit dibandingkan dengan A6000, performanya lebih baik karena jumlah inti tensor dan kecepatan bandwidth memori yang lebih tinggi. | ||||||
| 8 | A6000 | 24/48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2x24/48GB | TGI | 128 | 1205 | 2 |
Menyiapkan dan Mengonfigurasi TGI untuk Throughput Tinggi
Siapkan permintaan asinkron dalam bahasa skrip pilihan seperti python/ruby dan dengan menggunakan file yang sama untuk konfigurasi yang kami temukan:
- Waktu yang dibutuhkan meningkatkan panjang keluaran maksimum dari pembangkitan urutan.
- Thread 128/256 pada klien dan server lebih baik daripada 24, 64, 512. Saat menggunakan thread yang lebih rendah, komputasi kurang dimanfaatkan dan melampaui ambang batas seperti 128 overhead menjadi lebih tinggi sehingga throughput berkurang.
- Terdapat peningkatan sebesar 6% saat beralih dari permintaan asinkron ke paralel menggunakan 'GNU parallel' dibandingkan threading dalam bahasa seperti Go, Python/Ruby.
- 4090 memiliki throughput 12% lebih tinggi dibandingkan A6000. Meskipun 4090 memiliki vRAM yang lebih sedikit dibandingkan A6000, performanya lebih baik karena jumlah inti tensor dan kecepatan bandwidth memori yang lebih tinggi.
- Karena A6000 memiliki vRAM 48GB, untuk menyimpulkan apakah RAM tambahan membantu meningkatkan throughput atau tidak, kami mencoba menggunakan sebagian kecil memori GPU dalam percobaan 8 pada tabel, kami melihat RAM tambahan membantu meningkatkan tetapi tidak secara linier. Juga ketika mencoba memisahkan yaitu menghosting 2 API pada GPU yang sama dengan menggunakan setengah memori untuk setiap API, ini berperilaku seperti 2 API berurutan yang berjalan, alih-alih menerima permintaan secara paralel.
Pengamatan dan Metrik
Di bawah ini adalah grafik untuk beberapa percobaan dan waktu yang dibutuhkan untuk menyelesaikan kumpulan masukan tetap, semakin rendah waktu yang dibutuhkan semakin baik.
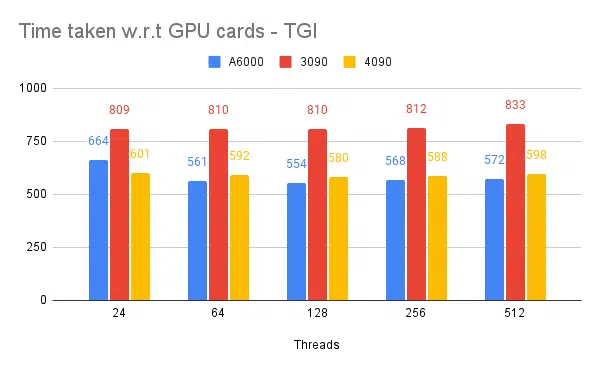
- Yang disebutkan adalah utas sisi klien. Sisi server perlu kami sebutkan saat memulai mesin inferensi.
Berspekulasi pengujian:
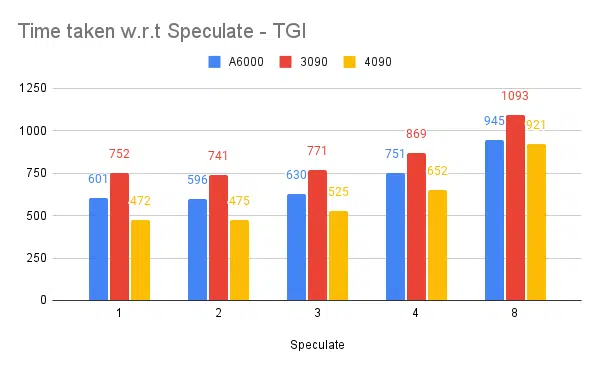
Pengujian Beberapa Mesin Inferensi:

Percobaan yang sama dilakukan dengan mesin lain seperti vLLM dan Aphrodite, kami mengamati hasil yang serupa, saat menulis artikel ini vLLM dan Aphrodite belum mendukung decoding spekulatif, sehingga kami memilih TGI karena memberikan throughput yang lebih tinggi daripada yang lain. untuk decoding spekulatif.
Selain itu, Anda dapat mengonfigurasi profiler GPU untuk meningkatkan kemampuan observasi, membantu mengidentifikasi area dengan penggunaan sumber daya berlebihan dan mengoptimalkan kinerja. Bacaan lebih lanjut: Alat Pengembang Nvidia Nsight - Max Katz
Kesimpulan
Kami melihat lanskap pembuatan inferensi terus berkembang dan peningkatan throughput di LLM memerlukan pemahaman yang baik tentang GPU, metrik kinerja, teknik pengoptimalan, dan tantangan yang terkait dengan tugas pembuatan teks. Ini membantu dalam memilih alat yang tepat untuk pekerjaan itu. Dengan memahami internal GPU dan hubungannya dengan inferensi LLM, seperti memanfaatkan inti tensor dan memaksimalkan bandwidth memori, pengembang dapat memilih GPU yang hemat biaya dan mengoptimalkan kinerja secara efektif.
Kartu GPU yang berbeda menawarkan kemampuan yang berbeda-beda, dan memahami perbedaannya sangat penting untuk memilih perangkat keras yang paling sesuai untuk tugas tertentu. Teknik seperti pengelompokan berkelanjutan, perhatian halaman, fusi kernel, dan perhatian kilat menawarkan solusi yang menjanjikan untuk mengatasi tantangan yang muncul dan meningkatkan efisiensi. TGI tampaknya merupakan pilihan terbaik untuk kasus penggunaan kami berdasarkan eksperimen dan hasil yang kami peroleh.
Baca artikel lain terkait model bahasa besar:
Memahami Arsitektur GPU untuk Optimasi Inferensi LLM
Teknik Tingkat Lanjut untuk Meningkatkan Throughput LLM