
Selezione e configurazione dei motori di inferenza per LLM
Pubblicato: 2024-04-02Introduzione ai motori di inferenza
Esistono molte tecniche di ottimizzazione sviluppate per mitigare le inefficienze che si verificano nelle diverse fasi del processo di inferenza. È difficile ridimensionare l'inferenza su larga scala con trasformatori/tecniche vanilla. I motori di inferenza racchiudono le ottimizzazioni in un unico pacchetto e ci facilitano nel processo di inferenza.
Per un insieme molto piccolo di test ad hoc o per un riferimento rapido, possiamo utilizzare il codice del trasformatore Vanilla per fare l'inferenza.
Il panorama dei motori di inferenza è in rapida evoluzione, poiché abbiamo molteplici scelte, è importante testare ed elencare il meglio del meglio per casi d'uso specifici. Di seguito sono riportati alcuni esperimenti sui motori di inferenza che abbiamo effettuato e i motivi per cui abbiamo scoperto perché ha funzionato nel nostro caso.
Per il nostro modello Vicuna-7B messo a punto, abbiamo provato
- TGI
- vLLM
- Afrodite
- Ottimale-Nvidia
- PowerInfer
- LLAMACPP
- Ctranslate2
Abbiamo esaminato la pagina github e la sua guida rapida per configurare questi motori, PowerInfer, LlaamaCPP, Ctranslate2 non sono molto flessibili e non supportano molte tecniche di ottimizzazione come batch continuo, attenzione alla pagina e prestazioni inferiori alla media rispetto ad altri motori menzionati .
Per ottenere un throughput più elevato, il motore/server di inferenza dovrebbe massimizzare la memoria e le capacità di calcolo e sia il client che il server devono funzionare in modo parallelo/asincrono per servire le richieste per mantenere il server sempre in funzione. Come accennato in precedenza, senza l'aiuto di tecniche di ottimizzazione come PagedAttention, Flash Attention e Continuous batching si otterranno sempre prestazioni non ottimali.
TGI, vLLM e Aphrodite sono candidati più adatti a questo riguardo e, eseguendo più esperimenti indicati di seguito, abbiamo trovato la configurazione ottimale per ottenere le massime prestazioni dall'inferenza. Tecniche come il batch continuo e l'attenzione alla pagina sono abilitate per impostazione predefinita, la decodifica speculativa deve essere abilitata manualmente nel motore di inferenza per i test seguenti.
Analisi comparativa dei motori di inferenza
TGI
Per utilizzare TGI, possiamo passare attraverso la sezione 'Inizia' della pagina github, qui docker è il modo più semplice per configurare e utilizzare il motore TGI.
Argomenti del programma di avvio della generazione di testo -> questo elenco delle diverse impostazioni che possiamo utilizzare sul lato server. Pochi importanti,
- –max-input-length : determina la lunghezza massima dell'input nel modello, ciò richiede modifiche nella maggior parte dei casi, poiché il valore predefinito è 1024.
- –token-max-totale: max token totali, ovvero lunghezza del token di input + output.
- –speculate, –quantiz, –max-concurrent-requests -> il valore predefinito è solo 128, che ovviamente è inferiore.
Per avviare un modello locale ottimizzato,
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text- generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Per avviare un modello dall'hub,
modello="lmsys/vicuna-7b-v1.5"; volume=$PWD/dati; token="<hf_token>"; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text- generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
Puoi chiedere a chatGPT di spiegare il comando precedente per una comprensione più dettagliata. Qui stiamo avviando il server di inferenza sulla porta 9091. E possiamo utilizzare un client di qualsiasi lingua per inviare una richiesta al server. API di inferenza per la generazione di testo -> menziona tutti gli endpoint e i parametri del payload per la richiesta.
Per esempio
payload="<richiesta qui>"
curl -XPOST “0.0.0.0:9091/generate” -H “Tipo contenuto: application/json” -d “{“inputs”: $payload, “parametri”: {“max_new_tokens”: 400,”do_sample”:false ,”best_of”: null,”repetition_penalty”: 1,”return_full_text”: false,”seed”: null,”stop_sequences”: null,”temperatura”: 0.1,”top_k”: 100,”top_p”: 0.3,” truncate": null", "tipico_p": null, "filigrana": false, "decoder_input_details": false}}"
Poche osservazioni,
- La latenza aumenta con max-token-tokens, il che è ovvio che, se stiamo elaborando un testo lungo, il tempo complessivo aumenterà.
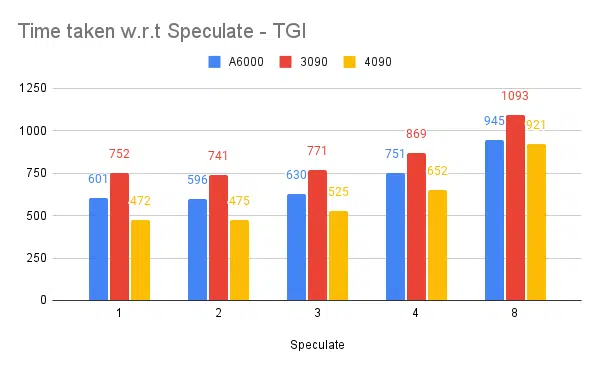
- La speculazione aiuta ma dipende dal caso d'uso e dalla distribuzione input-output.
- La quantizzazione Eetq aiuta maggiormente ad aumentare il throughput.
- Se disponi di una GPU multipla, eseguire 1 API su ciascuna GPU e avere queste API multi GPU dietro un bilanciatore del carico si traduce in un throughput più elevato rispetto allo sharding da parte di TGI stesso.
vLLM
Per avviare un server vLLM, possiamo utilizzare un server/docker API REST compatibile con OpenAI. È molto semplice iniziare, segui Deploying with Docker — vLLM, se intendi utilizzare un modello locale, quindi collega il volume e utilizza il percorso come nome del modello,
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest – modello/modello
Sopra verrà avviato un server vLLM sulla citata porta 8000, come sempre potete giocare con gli argomenti.
Effettua una richiesta di pubblicazione con,
«Conchiglia
payload="<richiesta qui>"
curl -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “Tipo contenuto: application/json” -d “{“prompt”: $payload,”model”:”/model” ”,max_tokens ": 400,"top_p": 0,3, "top_k": 100, "temperatura": 0,1}"
“`
Afrodite
«Conchiglia
pip installa il motore afrodite
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
“`
O
“`
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME="/model" -p 2242:7860 –gpus device=1 –ipc host alpindale/aphrodite-engine

“`
Aphrodite fornisce sia l'installazione pip che docker come menzionato nella sezione introduttiva. Docker è generalmente relativamente più facile da avviare e testare. Le opzioni di utilizzo e le opzioni del server ci aiutano a effettuare richieste.
- Aphrodite e vLLM utilizzano entrambi payload basati su server openAI, quindi puoi controllarne la documentazione.
- Abbiamo provato deepspeed-mii, poiché è in uno stato di transizione (quando abbiamo provato) dal legacy al nuovo codebase, non sembra affidabile e facile da usare.
- Optimum-NVIDIA non supporta altre ottimizzazioni importanti e determina prestazioni non ottimali, collegamento di riferimento.
- Aggiunto un concetto, il codice che abbiamo utilizzato per eseguire le richieste parallele ad hoc.
Metriche e misurazioni
Vogliamo provare e trovare:
- Ottimale n. di thread per il client/server del motore di inferenza.
- Come cresce la velocità effettiva rispetto all'aumento della memoria
- Come cresce il throughput rispetto ai tensor core.
- Effetto dei thread rispetto alla richiesta parallela da parte del client.
Un modo molto semplice per osservare l'utilizzo è guardarlo tramite le utilità Linux nvidia-smi, nvtop, questo ci dirà la memoria occupata, l'utilizzo del calcolo, la velocità di trasferimento dei dati ecc.
Un altro modo è profilare il processo utilizzando la GPU con nsys.
| S.No | GPU | Memoria vRAM | Motore di inferenza | Discussioni | Tempo (i) | Ipotizzare |
| 1 | A6000 | 48/48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48/48GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48/48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48/48GB | TGI | 256 | 568 | – |
Sulla base degli esperimenti di cui sopra, 128/256 thread sono migliori di un numero di thread inferiore e oltre 256 spese generali iniziano a contribuire alla riduzione del throughput. Si è scoperto che questo dipende dalla CPU e dalla GPU e richiede il proprio esperimento. | ||||||
| 5 | A6000 | 48/48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48/48 GB | TGI | 128 | 945 | 8 |
Un valore speculativo più elevato causa più rifiuti per il nostro modello ottimizzato e quindi riduce la produttività. 1/2 poiché il valore speculato va bene, è soggetto al modello e non è garantito che funzioni allo stesso modo nei casi d'uso. Ma la conclusione è che la decodifica speculativa migliora il throughput. | ||||||
| 7 | 3090 | 24/24 GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24 GB | TGI | 128 | 481 | 2 |
Anche se ha meno vRAM rispetto all'A6000, il 4090 ha prestazioni superiori grazie al maggior numero di tensor core e alla velocità della larghezza di banda della memoria. | ||||||
| 8 | A6000 | 24/48 GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2x24/48 GB | TGI | 128 | 1205 | 2 |
Impostazione e configurazione di TGI per un throughput elevato
Imposta la richiesta asincrona in un linguaggio di scripting di tua scelta come Python/Ruby e utilizzando lo stesso file per la configurazione abbiamo trovato:
- Il tempo impiegato aumenta rispetto alla lunghezza massima dell'output di generazione della sequenza.
- 128/256 thread su client e server sono migliori di 24, 64, 512. Quando si utilizzano thread inferiori, il calcolo viene sottoutilizzato e oltre una soglia come 128 il sovraccarico diventa maggiore e quindi la velocità effettiva si riduce.
- C'è un miglioramento del 6% quando si passa da richieste asincrone a richieste parallele utilizzando "GNU parallelo" invece del threading in linguaggi come Go, Python/Ruby.
- 4090 ha una produttività maggiore del 12% rispetto a A6000. Anche se ha meno vRAM rispetto all'A6000, il 4090 ha prestazioni superiori grazie al maggior numero di tensor core e alla velocità della larghezza di banda della memoria.
- Poiché l'A6000 ha 48 GB di vRAM, per concludere se la RAM aggiuntiva aiuta a migliorare il throughput o meno, abbiamo provato a utilizzare frazioni di memoria GPU nell'esperimento 8 della tabella, vediamo che la RAM aggiuntiva aiuta a migliorare ma non in modo lineare. Inoltre, quando si prova a dividere, ovvero a ospitare 2 API sulla stessa GPU utilizzando metà memoria per ciascuna API, si comporta come se fossero in esecuzione 2 API sequenziali, invece di accettare richieste in parallelo.
Osservazioni e metriche
Di seguito sono riportati i grafici di alcuni esperimenti e il tempo impiegato per completare un set di input fisso, è meglio abbassare il tempo impiegato.
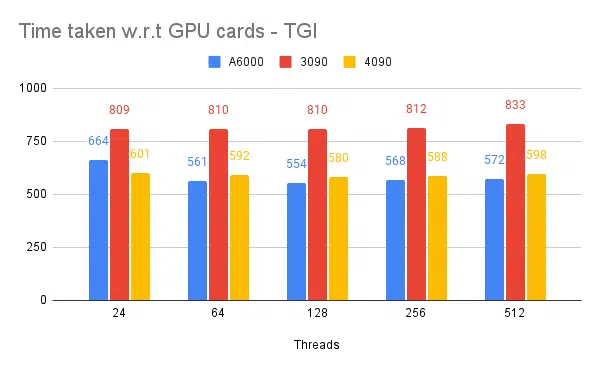
- Sono menzionati i thread lato client. Lato server che dobbiamo menzionare durante l'avvio del motore di inferenza.
Test speculativi:
Test di più motori di inferenza:

Stesso tipo di esperimenti condotti con altri motori come vLLM e Aphrodite osserviamo risultati simili, al momento della stesura di questo articolo vLLM e Aphrodite non supportano ancora la decodifica speculativa, il che ci lascia a scegliere TGI poiché fornisce un throughput più elevato rispetto al resto dovuto alla decodificazione speculativa.
Inoltre, puoi configurare i profiler GPU per migliorare l'osservabilità, aiutando nell'identificazione delle aree con un utilizzo eccessivo delle risorse e ottimizzando le prestazioni. Ulteriori informazioni: Strumenti per sviluppatori Nvidia Nsight - Max Katz
Conclusione
Vediamo che il panorama della generazione di inferenze è in continua evoluzione e il miglioramento della produttività in LLM richiede una buona conoscenza della GPU, delle metriche delle prestazioni, delle tecniche di ottimizzazione e delle sfide associate alle attività di generazione del testo. Questo aiuta nella scelta degli strumenti giusti per il lavoro. Comprendendo gli interni della GPU e il modo in cui corrispondono all'inferenza LLM, ad esempio sfruttando i tensor core e massimizzando la larghezza di banda della memoria, gli sviluppatori possono scegliere la GPU più conveniente e ottimizzare le prestazioni in modo efficace.
Schede GPU diverse offrono funzionalità diverse e comprendere le differenze è fondamentale per selezionare l'hardware più adatto per attività specifiche. Tecniche come il batching continuo, l'attenzione alla pagina, la fusione del kernel e l'attenzione flash offrono soluzioni promettenti per superare le sfide emergenti e migliorare l'efficienza. TGI sembra la scelta migliore per il nostro caso d'uso in base agli esperimenti e ai risultati che otteniamo.
Leggi altri articoli relativi al modello linguistico di grandi dimensioni:
Comprensione dell'architettura GPU per l'ottimizzazione dell'inferenza LLM
Tecniche avanzate per migliorare il throughput LLM