
LLM の推論エンジンの選択と構成
公開: 2024-04-02推論エンジンの概要
推論プロセスのさまざまな段階で発生する非効率を軽減するために開発された最適化手法が多数あります。 バニラのトランスフォーマー/テクニックを使用して推論を大規模に拡張することは困難です。 推論エンジンは最適化を 1 つのパッケージにまとめて、推論プロセスを容易にします。
非常に小規模なアドホック テストやクイック リファレンスの場合は、バニラのトランスフォーマー コードを使用して推論を行うことができます。
推論エンジンの状況は急速に進化しており、選択肢が複数あるため、特定のユースケースに最適なものをテストして絞り込むことが重要です。 以下に、私たちが行ったいくつかの推論エンジンの実験と、それが今回のケースでうまく機能した理由を示します。
微調整された Vicuna-7B モデルでは、次のことを試しました。
- TGI
- vLLM
- アフロディーテ
- Optimum-Nvidia
- パワーインファー
- LLAMACPP
- Ctranslate2
これらのエンジンをセットアップするには、github ページとそのクイック スタート ガイドを参照しました。PowerInfer、LlaamaCPP、Ctranslate2 は柔軟性があまり高くなく、継続的なバッチ処理、ページ化されたアテンション、他の前述のエンジンと比較した場合の平均以下のパフォーマンスの維持など、多くの最適化手法をサポートしていません。 。
より高いスループットを得るには、推論エンジン/サーバーはメモリと計算能力を最大化する必要があり、サーバーが常に動作し続けるように、クライアントとサーバーの両方がリクエストを処理する並列/非同期方法で動作する必要があります。 前に述べたように、PagesAttention、Flash Attending、Continuous バッチ処理などの最適化手法を利用しないと、常に次善のパフォーマンスが発生します。
この点では、TGI、vLLM、および Aphrodite がより適切な候補であり、以下に示す複数の実験を行うことで、推論から最大のパフォーマンスを引き出す最適な構成を見つけました。 連続バッチ処理やページング アテンションなどの手法はデフォルトで有効になっていますが、以下のテストでは推論エンジンで投機的デコードを手動で有効にする必要があります。
推論エンジンの比較分析
TGI
TGI を使用するには、github ページの「Get Started」セクションに進みます。ここでは docker が TGI エンジンを構成して使用する最も簡単な方法です。
テキスト生成ランチャー引数 -> このリストには、サーバー側で使用できるさまざまな設定が示されています。 重要なものはいくつかありますが、
- –max-input-length : モデルへの入力の最大長を決定します。デフォルトは 1024 であるため、ほとんどの場合変更が必要です。
- –max-total-tokens:最大 合計トークン、つまり入力 + 出力トークンの長さ。
- –speculate、-quantiz、-max-concurrent-requests -> デフォルトは 128 のみですが、これは明らかに少ないです。
ローカルで微調整されたモデルを開始するには、
docker run –gpus device=1 –shm-size 1g -p 9091:80 -v /path/to/fine_tuned_v1:/model ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id /model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
ハブからモデルを開始するには、
モデル=”lmsys/vicuna-7b-v1.5″; ボリューム=$PWD/データ; token=”<hf_token>”; docker run –gpus all –shm-size 1g -e HUGGING_FACE_HUB_TOKEN=$token -p 9091:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4.4 –model-id $model – dtype float16 –num-shard 1 –max-input-length 3600 –max-total-tokens 4000 –speculate 2
さらに詳しく理解するために、chatGPT に上記のコマンドの説明を依頼できます。 ここでは、9091 ポートで推論サーバーを起動しています。 また、任意の言語のクライアントを使用して、サーバーにリクエストを送信できます。 テキスト生成推論 API -> リクエスト用のすべてのエンドポイントとペイロード パラメーターについて説明します。
例えば
payload=”<ここにプロンプト>”
curl -XPOST "0.0.0.0:9091/generate" -H "Content-Type: application/json" -d "{"inputs": $payload, "parameters": {"max_new_tokens": 400,"do_sample":false 、”best_of”:null、”repetition_penalty”:1、”return_full_text”:false、”seed”:null、”stop_sequences”:null、”温度”:0.1、”top_k”:100、”top_p”:0.3、” truncate”: null、”typical_p”: null、”watermark”: false、”decoder_input_details”: false}}”
観察はほとんどなく、
- max-token-token が増加するとレイテンシーが増加します。これは、長いテキストを処理する場合、全体の時間が増加することは明らかです。
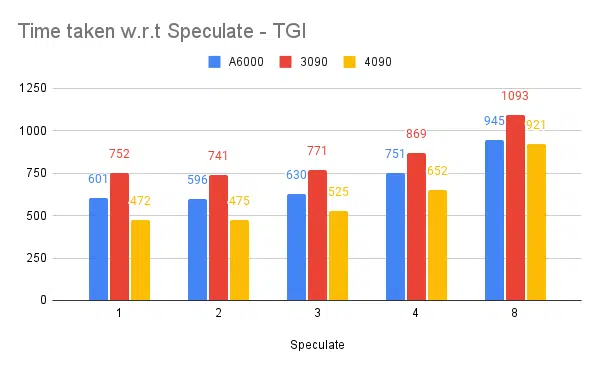
- 推測は役に立ちますが、ユースケースと入出力の分散に依存します。
- Eetq 量子化は、スループットの向上に最も役立ちます。
- マルチ GPU を使用している場合、各 GPU で 1 つの API を実行し、これらのマルチ GPU API をロードバランサーの背後に配置すると、TGI 自体によるシャーディングよりも高いスループットが得られます。
vLLM
vLLM サーバーを起動するには、OpenAI 互換の REST API サーバー/ドッカーを使用できます。 開始するのは非常に簡単です。Docker によるデプロイ (vLLM) に従ってください。ローカル モデルを使用する場合は、ボリュームをアタッチし、パスをモデル名として使用します。
docker run –runtime nvidia –gpus device=1 –shm-size 1g -v /path/to/fine_tuned_v1:/model -v ~/.cache/ -p 8000:8000 –ipc=host vllm/vllm-openai:latest –モデル/モデル
上記では、いつものように引数を指定して、前述の 8000 ポートで vLLM サーバーを起動します。
投稿リクエストを行うには、
「シェル」
payload=”<ここにプロンプト>”
curl -XPOST -m 1200 “0.0.0.0:8000/v1/completions” -H “Content-Type: application/json” -d “{“prompt”: $payload,”model”:”/model” ,”max_tokens ”:400、”top_p”:0.3、”top_k”:100、”温度”:0.1}”
「」
アフロディーテ
「シェル」

pip インストール aphrodite エンジン
python -m aphrodite.endpoints.openai.api_server –model PygmalionAI/pygmalion-2-7b
「」
または
「」
docker run -v /path/to/fine_tuned_v1:/model -d -e MODEL_NAME=”/model” -p 2242:7860 –gpus device=1 –ipc host alpindale/aphrodite-engine
「」
Aphrodite は、「はじめに」セクションで説明したように、pip と docker の両方のインストールを提供します。 一般に、Docker は起動してテストするのが比較的簡単です。 使用方法オプション、サーバー オプションは、リクエストの作成方法に役立ちます。
- Aphrodite と vLLM はどちらも openAI サーバー ベースのペイロードを使用しているため、そのドキュメントを確認できます。
- deepspeed-mii を試してみました。試した時点ではレガシーコードベースから新しいコードベースへの過渡状態にあったため、信頼性も使いやすさも見えません。
- Optimum-NVIDIA は他の主要な最適化をサポートしていないため、パフォーマンスが最適以下になります (参照リンク)。
- アドホック並列リクエストを実行するために使用したコードである Gist を追加しました。
指標と測定値
私たちは次のことを試して見つけたいと考えています。
- 最適な番号クライアント/推論エンジンサーバーのスレッドの数。
- メモリの増加に応じてスループットがどのように増加するか
- Tensor コアに関してスループットがどのように増加するか。
- スレッドとクライアントによる並列リクエストの影響。
使用率を観察する非常に基本的な方法は、linux utils nvidia-smi、nvtop を介して観察することです。これにより、占有メモリ、コンピューティング使用率、データ転送速度などがわかります。
もう 1 つの方法は、nsys で GPU を使用してプロセスをプロファイリングすることです。
| S.いいえ | GPU | vRAMメモリ | 推論エンジン | スレッド | 時間(秒) | 推測する |
| 1 | A6000 | 48/48GB | TGI | 24 | 664 | – |
| 2 | A6000 | 48/48GB | TGI | 64 | 561 | – |
| 3 | A6000 | 48/48GB | TGI | 128 | 554 | – |
| 4 | A6000 | 48/48GB | TGI | 256 | 568 | – |
上記の実験に基づくと、128/256 スレッドはそれより低いスレッド番号よりも優れており、256 を超えるとオーバーヘッドがスループットの低下に寄与し始めます。 これは CPU と GPU に依存することが判明しており、独自の実験が必要です。 | ||||||
| 5 | A6000 | 48/48GB | TGI | 128 | 596 | 2 |
| 6 | A6000 | 48/48GB | TGI | 128 | 945 | 8 |
推測値が高くなると、微調整されたモデルの拒否が増加し、スループットが低下します。 推測値として 1 / 2 は問題ありませんが、これはモデルに依存し、ユースケース全体で同じように動作することは保証されません。 しかし、結論としては、投機的デコードによりスループットが向上します。 | ||||||
| 7 | 3090 | 24/24GB | TGI | 128 | 741 | 2 |
| 7 | 4090 | 24/24GB | TGI | 128 | 481 | 2 |
4090 は、A6000 と比較して vRAM が少ないにもかかわらず、Tensor コア数とメモリ帯域幅の速度が高いため、パフォーマンスは優れています。 | ||||||
| 8 | A6000 | 24/48GB | TGI | 128 | 707 | 2 |
| 9 | A6000 | 2×24/48GB | TGI | 128 | 1205 | 2 |
高スループットのための TGI のセットアップと構成
Python/Ruby などの選択したスクリプト言語で非同期リクエストを設定し、構成に同じファイルを使用します。
- シーケンス生成の最大出力長よりもかかる時間が増加します。
- クライアントとサーバー上の 128/256 スレッドは、24、64、512 スレッドよりも優れています。これより低いスレッドを使用すると、コンピューティングが十分に活用されず、128 などのしきい値を超えるとオーバーヘッドが高くなり、スループットが低下します。
- Go、Python/Ruby などの言語でスレッド化する代わりに「GNU 並列」を使用して非同期リクエストから並列リクエストにジャンプすると、6% の改善が見られます。
- 4090 は A6000 よりも 12% 高いスループットを備えています。 4090 は、A6000 と比較して vRAM が少ないにもかかわらず、Tensor コア数とメモリ帯域幅の速度が高いため、パフォーマンスは優れています。
- A6000 には 48 GB の vRAM が搭載されているため、追加の RAM がスループットの向上に役立つかどうかを結論付けるために、表の実験 8 で GPU メモリの一部を使用してみました。追加の RAM は向上に役立ちますが、直線的ではないことがわかります。 また、分割しようとした場合、つまり、各 API に半分のメモリを使用して同じ GPU 上で 2 つの API をホストすると、リクエストを並行して受け入れるのではなく、2 つの連続した API が実行されているように動作します。
観察と指標
以下はいくつかの実験のグラフと、固定入力セットを完了するのにかかる時間を示しています。かかる時間が短いほど優れています。
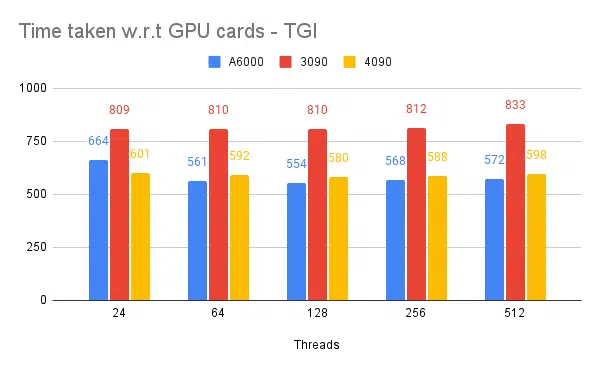
- クライアント側のスレッドについて説明します。 サーバー側では、推論エンジンを開始するときに言及する必要があります。
推測テスト:
複数の推論エンジンのテスト:

vLLM や Aphrodite などの他のエンジンで同じ種類の実験を行ったところ、同様の結果が観察されました。この記事を書いている時点では、vLLM と Aphrodite はまだ投機的デコードをサポートしていないため、残りの時間よりも高いスループットが得られる TGI を選択することになります。投機的なデコードに。
さらに、可観測性を強化するように GPU プロファイラーを構成して、リソースが過剰に使用されている領域の特定とパフォーマンスの最適化に役立てることができます。 詳細: Nvidia Nsight 開発者ツール — Max Katz
結論
推論生成の状況は常に進化しており、LLM のスループットを向上させるには、GPU、パフォーマンス メトリクス、最適化手法、およびテキスト生成タスクに関連する課題を十分に理解する必要があります。 これは、作業に適したツールを選択するのに役立ちます。 GPU の内部構造と、テンソル コアの活用やメモリ帯域幅の最大化など、GPU の内部構造が LLM 推論にどのように対応するかを理解することで、開発者はコスト効率の高い GPU を選択し、パフォーマンスを効果的に最適化できます。
さまざまな GPU カードが提供する機能はさまざまであり、特定のタスクに最適なハードウェアを選択するには、その違いを理解することが重要です。 連続バッチ処理、ページ アテンション、カーネル フュージョン、フラッシュ アテンションなどの技術は、発生する課題を克服し、効率を向上させるための有望なソリューションを提供します。 私たちが得た実験と結果に基づいて、TGI が私たちのユースケースに最適な選択肢であると考えられます。
大規模言語モデルに関連する他の記事を読んでください。
LLM 推論最適化のための GPU アーキテクチャを理解する
LLM スループットを向上させるための高度なテクニック