
Jak zoptymalizować zduplikowane treści pod kątem SEO
Opublikowany: 2022-08-03Zduplikowana treść to taka sama lub podobna treść, która istnieje na wielu stronach, w jednej domenie lub w różnych witrynach.
Zduplikowana treść jest problematyczna dla wyszukiwarek, ponieważ widząc tę samą treść w wielu lokalizacjach, nie wiedzą, który adres URL powinien być:
- Indeksowane,
- Przypisano odpowiednie sygnały rankingowe i
- Wyżej wymieniony w wynikach wyszukiwania.
Może to prowadzić do obniżenia pozycji w rankingu, marnowania budżetu na indeksowanie i problemów z indeksowaniem Twojej witryny, a w konsekwencji do rozproszenia potencjału biznesowego Twoich stron .
Ze względu na swoją firmę musisz zrozumieć, co może powodować duplikowanie treści i jak zoptymalizować aspekty witryny, aby uniknąć wszelkich problemów – przyjrzyjmy się temu.
Jak zduplikowana treść wpływa na SEO
Zduplikowana treść nie zawsze jest problemem – jeśli użyjesz technicznego SEO, aby utrzymać ją pod kontrolą, nie zaszkodzi to Twojemu ruchowi organicznemu. Ale jeśli pozostawisz zduplikowane treści niezoptymalizowane, może to mieć śmiertelne konsekwencje.
Oto główne sposoby, w jakie zduplikowana treść może negatywnie wpłynąć na Twoją witrynę:
Niższe rankingi
Wiele wersji tej samej treści sprawia, że wyszukiwarki mają trudności z podjęciem decyzji, która strona powinna zostać zaindeksowana i zaprezentowana w wynikach wyszukiwania .
W takim przypadku żadna z Twoich zduplikowanych stron nigdy nie osiągnie pełnego potencjału rankingowego, jeśli zostaną przeszukane i zaindeksowane w pierwszej kolejności.
Ograniczony transfer uprawnień do linków
Wyszukiwarki mogą mieć trudności z dokładnym przypisaniem sygnałów rankingowych z linków zwrotnych do zduplikowanych stron .
Jeśli ta sama treść istnieje na kilku stronach, wiele adresów URL może otrzymać linki z innych domen. Ale całkowity autorytet linków zostanie następnie podzielony między strony, ograniczając potencjał rankingowy Twojego elementu treści.
Problemy z indeksowaniem i zmarnowany budżet na indeksowanie
Jeśli masz dużą witrynę internetową, często problemem jest budżet indeksowania . A wyszukiwarki mogą marnować budżet na indeksowanie zduplikowanych stron .
Zawsze chcesz, aby budżet indeksowania był przeznaczany na indeksowanie wartościowych treści. Gdy pozostawisz niezoptymalizowaną zduplikowaną treść w swojej domenie, boty wyszukiwarek mogą marnować część swoich zasobów, niepotrzebnie indeksując tę samą treść w kółko.
To nie tylko opóźni ich odkrycie innych treści w Twojej witrynie, ale może również zniechęcić ich do powrotu do Twojej witryny tak często.
W takim przypadku ryzykujesz problemy z indeksowaniem . Należy pamiętać, że przez większość czasu Google przyjrzy się różnym sygnałom, takim jak mapy witryn, linki wewnętrzne i zewnętrzne, przekierowania i inne, i wybierze do zindeksowania jeden adres URL spośród wielu. Problem polega na tym, że może to nie być wersja, którą chcesz zindeksować.
Jeśli Google nie może zaindeksować niektórych Twoich stron, możesz mieć trudności z zaindeksowaniem najważniejszych, unikalnych stron.
Co więcej, widząc duże ilości zduplikowanych stron, wyszukiwarki mogą postrzegać całą Twoją witrynę jako niskiej jakości , zakładając, że inne strony zawierają podobną treść. Mogą wtedy wahać się, czy przydzielić zasoby do indeksowania Twojej witryny w przyszłości.
Czy powielanie treści może skutkować karą Google?
Być może słyszałeś sprzeczne opinie na temat tego, czy powielanie treści może spowodować nałożenie kary Google.
Zduplikowana treść nie spowoduje nałożenia kary na Twoją witrynę, chyba że jest wynikiem złośliwych działań .
Skrobanie treści jest przykładem praktyki manipulacyjnej związanej z duplikowaniem treści. Dzieje się tak, gdy ktoś pobiera treść z Twoich stron, aby ponownie opublikować ją w swojej witrynie.
Takie praktyki są stosunkowo rzadkie, ponieważ zazwyczaj powodują problemy tylko wtedy, gdy witryna skrobania jest bardziej autorytatywna i zdoła przewyższyć witrynę, która pierwotnie opublikowała treść.
Możesz dodać zabezpieczenie chroniące zawartość przed takimi praktykami, wdrażając samoodnoszące się znaczniki kanoniczne wskazujące na istniejące strony, aby poinformować wyszukiwarki, że oryginalna zawartość pochodzi od Ciebie.
W rzadkich przypadkach, w których Google wykryje, że zduplikowana treść może zostać wyświetlona w celu manipulowania naszymi rankingami i oszukania naszych użytkowników, wprowadzimy również odpowiednie korekty w indeksowaniu i rankingu odpowiednich witryn. W rezultacie może ucierpieć pozycja witryny w rankingu lub witryna może zostać całkowicie usunięta z indeksu Google, w którym to przypadku nie będzie już wyświetlana w wynikach wyszukiwania.źródło: dokumentacja Google
Google potrafi rozróżnić typy zduplikowanych treści i rozumie, które zduplikowane treści nie manipulowały rankingami wyszukiwania.
Przykłady niezłośliwych zduplikowanych treści mogą obejmować:
- Fora dyskusyjne, które mogą generować zarówno zwykłe, jak i uproszczone strony kierowane na urządzenia mobilne
- Produkty w sklepie internetowym, które są wyświetlane lub połączone z wieloma różnymi adresami URL
- Wersje stron internetowych tylko do drukarki
źródło: dokumentacja Google
Jeśli nie kradniesz celowo treści z innych witryn , nie musisz się martwić.
Jakie są przyczyny duplikowania treści
Zwykle nie potrzebujesz wielu wersji tej samej treści w swojej witrynie.
Dlatego zduplikowane treści pojawiają się raczej z powodu błędów niż świadomych decyzji.
Najczęściej zduplikowane treści pojawiają się z powodu słabego rozwoju stron internetowych i wadliwych implementacji na stronie , takich jak błędne konfiguracje serwerów lub niezoptymalizowane platformy CMS.
Duplikaty możemy znaleźć na wszystkich typach witryn, ale niektóre są na to bardziej podatne, zwłaszcza duże witryny z tysiącami lub milionami stron.
W szczególności witryny eCommerce mogą radzić sobie z nadmierną ilością zduplikowanych stron, które są trudne do śledzenia.
Zduplikowane treści w witrynach eCommerce często dotyczą następujących aspektów:
- Strony produktów zawierają niewiele treści lub zawierają tylko ogólne opisy produktów na wielu stronach. Jeśli strona zawiera opis danego produktu podany przez producenta, mogą one pojawiać się również w innych domenach, a Google może potraktować to jako zduplikowaną treść.
- Strony kategorii mają filtry, które wyświetlają listy tych samych produktów na wielu stronach.
Identyczna treść w wielu adresach URL dotyczy również artykułów na blogu .
Witryny mogą zawierać artykuły porównawcze, wymieniające cechy produktów lub narzędzi, w których wiele fragmentów treści może opisywać te same narzędzia, produkty lub funkcje na wielu stronach.
Sekcje bloga mogą zawierać artykuły pasujące do wielu kategorii – w rezultacie wiele adresów URL może prowadzić do tego samego artykułu.
Witryny z wiadomościami często wykorzystują tagi , które gromadzą treści na pokrewne tematy, ale w niektórych sytuacjach strony mogą używać wielu tagów i pojawiać się w wielu lokalizacjach w witrynie.
Ryzyko powielania treści dotyczy również witryn wyświetlających wykazy pochodzące z baz danych wykorzystywanych przez inne domeny , takie jak marketplace’y czy strony z nieruchomościami. W związku z tym identyczne reklamy lub posty mogą pojawiać się w kilku domenach.
Wiele witryn korzysta z treści tworzonych przez użytkowników . Choć potencjalnie korzystny, może być kolejnym źródłem duplikatów treści – dotyczy to każdej witryny zawierającej posty, reklamy, strony profilowe itp. utworzone przez użytkowników. Często użytkownicy mogą napisać tylko kilka słów, używając tekstu skopiowanego lub będącego spamem, lub dodać tylko link do swojej witryny na stronie profilu.
Nie jest to wyczerpująca lista przyczyn duplikacji treści, ale powinna dać wyobrażenie o tym, jaki rodzaj treści naraża Twoją witrynę na ryzyko i powinien być monitorowany.
Sposoby zarządzania duplikatami treści
W zależności od jakości i roli zduplikowanych stron w hierarchii witryny możesz chcieć rozwiązać je różnymi metodami.
Oto, jakie masz opcje i co powinieneś wiedzieć o każdym rozwiązaniu:
Użyj znaczników kanonicznych
Tagi kanoniczne informują wyszukiwarki, która strona zawiera główną wersję danej treści i powinna zostać zindeksowana.
Możesz poinformować wyszukiwarki poprzez kanonizację, że dana strona powinna być traktowana jako kopia określonego adresu URL . Sygnały rankingowe, takie jak autorytet linków zastosowany do tej strony przez wyszukiwarki, powinny być przypisane do określonego adresu URL.
Implementacja tagów kanonicznych wymaga mniej czasu na opracowanie niż inne rozwiązania, takie jak przekierowania, ponieważ są one dodawane na stronie, a nie na poziomie serwera. Pamiętaj, aby dodać znaczniki kanoniczne do sekcji <head> kodu HTML – jeśli umieścisz go w <body>, nie będzie to przestrzegane.
Chociaż boty wyszukiwarek zazwyczaj stosują się do dyrektywy kanonicznej, w niektórych przypadkach mogą ją zignorować i wybrać inną stronę kanoniczną. Może się tak zdarzyć, jeśli wyszukiwarki widzą silniejsze sygnały wskazujące na inny adres URL, takie jak więcej linków wewnętrznych lub autorytatywne linki zwrotne.
Dodaj przekierowania
Innym rozwiązaniem do zwalczania duplikatów treści jest implementacja przekierowań z niepreferowanych adresów URL do ich preferowanych wersji.
Jeśli na stałe przekierowujesz adres URL, użyj przekierowania 301, które zazwyczaj będzie najlepszą opcją, jeśli chodzi o zarządzanie zduplikowanymi treściami.
Przekierowania pomagają skonsolidować sygnały rankingowe pod jednym adresem URL , dlatego Google powinien indeksować tylko stronę docelową.
Zaimplementuj tag noindex
Możesz dodać tag noindex do stron, które są duplikatami i nie powinny być indeksowane przez wyszukiwarki, ale powinny pozostać widoczne dla użytkowników .
Upewnij się jednak, że nie blokujesz indeksowania tych stron – jeśli to zrobisz, boty nie będą mogły zobaczyć tagu noindex.
Usuń zduplikowane strony
Możesz usunąć zduplikowane strony , jeśli nie służą one Twoim odwiedzającym lub Twojej firmie i nie planujesz ich ulepszać.
Możesz je usunąć, zmieniając ich kod stanu na 404 lub 410 .

Oba kody statusu mają te same długoterminowe konsekwencje. Jedyna różnica polega na tym, że 410 może usunąć strony z indeksu i ograniczyć ich indeksowanie szybciej niż 404.
Najlepsze praktyki dotyczące zduplikowanych treści
Przejdźmy przez aspekty, które należy wziąć pod uwagę w przypadku duplikatów stron, aby rozwiązać potencjalne problemy.
Zdecyduj, czy zduplikowane strony powinny być indeksowane
Zastanów się, czy zezwolić wyszukiwarkom na indeksowanie zduplikowanych stron . W dużej mierze zależy to od rodzaju duplikatów treści i tego, co zamierzasz z nią zrobić.
Google musi mieć możliwość indeksowania stron, które zawierają przekierowania – w przeciwnym razie ich nie zobaczy. Sytuacja jest podobna, jeśli dodałeś tagi noindex – Google musi zindeksować stronę, aby odkryć tag noindex i podążać za nim.
Ponadto po wprowadzeniu ulepszeń w duplikatach , na przykład przez dodanie unikalnej treści, Google będzie musiało zindeksować stronę w celu ponownej oceny jej jakości.
Jeśli masz zduplikowaną treść, która nie ma wartości dla Twojej witryny i nie możesz wprowadzić w niej zmian, ogranicz możliwość indeksowania jej przez wyszukiwarki, implementując odpowiednią dyrektywę w pliku robots.txt .
Dostosuj strukturę adresów URL
Niespójne struktury adresów URL mogą powodować wiele zduplikowanych treści.
Oto aspekty adresów URL, na które należy zwrócić uwagę:
Wwws i non-wwws lub HTTP i HTTPS
W swojej witrynie możesz mieć adresy URL, do których można uzyskać dostęp bez www, np . example.com , oraz za pośrednictwem adresów zawierających www, takich jak www.example.com .
Ta sama kwestia dotyczy protokołu: adresy URL mogą zawierać http://example.com lub https://example.com .
Większość nowoczesnych stron internetowych korzysta z protokołu HTTPS, ponieważ zapewnia bezpieczniejszą komunikację. Ale czasami nadal możesz mieć strony, które są nadal dostępne w HTTP. A jeśli przeszedłeś na HTTPS i nie przekierowałeś witryny z HTTP, możesz nawet utworzyć dwie wersje tego.
Niezależnie od tego, czy dodajesz www, czy nie, i niezależnie od używanego protokołu, upewnij się, że jest spójny .
Jeśli odkryjesz adresy URL, które nie są zgodne z wybranym wzorcem, zaimplementuj przekierowania 301 dla niepreferowanych sposobów, które prowadzą do preferowanej wersji.
Małe i wielkie litery
Google traktuje adresy URL z rozróżnianiem wielkości liter . Tak więc dla Google example.com/page i example.com/PAGE będą to dwie różne strony.
W adresach URL zwyczajowo używa się małych liter, więc użytkownikom łatwiej jest je wpisywać bez błędów.
Jeśli jednak używasz obudów zamiennie, możesz utworzyć różne adresy URL z tą samą treścią.
Jeśli znajdziesz takie zdarzenia, wybierz adres URL z preferowaną wielkością liter i przekieruj do niego nieprawidłową wersję .
Ukośniki na końcu
Identyczne adresy URL z końcowym ukośnikiem i bez niego będą również wyświetlane jako różne strony — na przykład example.com i example.com/ .
Jeszcze raz upewnij się, że trzymasz się tego samego wzorca adresu URL i w razie potrzeby przekieruj niewłaściwe strony .
Parametry śledzenia lub filtrowania
Parametry filtrowania w witrynach eCommerce często prowadzą do duplikowania stron.
Jeśli dostępnych jest wiele filtrów, można je wybierać w różnych kombinacjach, generując góry adresów URL o tej samej lub prawie identycznej treści. Przykładem może być https://www.example.com/ubrania/sukienki?size=medium .
Parametry są również używane do celów śledzenia , co jest kolejnym źródłem duplikatów treści. Na przykład możesz dodać parametry UTM, aby śledzić wizyty z określonych źródeł, takich jak Twitter czy newsletter. Oto przykład: https://example.com/page?utm_source=twitter .
Sparametryzowane adresy URL należy przekształcić kanonicznie na wersje adresów URL bez parametrów śledzenia .
Identyfikatory sesji
Sesje mogą przechowywać informacje o odwiedzających na potrzeby analityki internetowej, gdzie każdemu użytkownikowi odwiedzającemu witrynę przypisywany jest inny identyfikator sesji przechowywany w adresie URL. Może to wyglądać tak: https://example.com?sessionId=jsdfo74256sdfh .
Jeśli do każdego adresu URL żądanego przez odwiedzającego zostanie dołączony identyfikator sesji, będzie wiele zduplikowanych stron, ponieważ treść pod tymi adresami URL jest taka sama.
Kanonizuj adresy URL z dołączonymi identyfikatorami sesji do adresów URL bez nich.
Adresy URL tylko do druku
Posiadanie wersji strony do druku pod oddzielnym adresem URL oznacza, że istnieją dwie wersje tej samej treści, na przykład https://www.example.com/page/ i https://www.example.com/print /strona/ .
Zaimplementuj kanoniczny adres URL z wersji do druku do standardowej wersji strony.
Zoptymalizuj swoje treści
Możesz wprowadzić dalsze poprawki, koncentrując się na treści na swoich stronach.
Najważniejsze jest to, że jeśli masz wartościowe strony, które powinny być w rankingu i generować ruch, upewnij się, że zawierają unikatowe, wysokiej jakości treści skierowane do konkretnych intencji użytkownika.
Choć jest to czasochłonne i czasochłonne, na dłuższą metę będzie się opłacać.
Oto kilka aspektów treści, które należy wziąć pod uwagę podczas optymalizacji:
Ulepsz strony produktów
Podaj unikalne opisy produktów zamiast kopiować ogólny opis od producenta.
Często zadawane pytania to doskonałe miejsce na zamieszczenie dodatkowych informacji o Twoich produktach lub usługach. Bądź jednak ostrożny – jeśli wymienisz dokładne szczegóły wymienione w opisie produktu, może to być częściowe powielenie treści.
Dostosuj strony kategorii
Każda strona kategorii powinna być niepowtarzalna i trafna . Przejrzyj swoje kategorie i zastanów się, czy każda z nich jest konieczna – jak przydatne są dla użytkowników?
Rozważ usunięcie niektórych lub połączenie ich w jeden. Zrób to samo dla wszystkich opcji filtrowania lub sortowania dostępnych w kategoriach.
Konsoliduj treść
Jeśli masz kilka artykułów omawiających pokrewne tematy, rozważ połączenie ich w jeden większy fragment treści , który może być jego najbardziej wszechstronną wersją.
W ten sposób możesz tworzyć przydatne treści, które zawierają wszystkie informacje w jednym miejscu, zamiast rozpraszać je na kilka adresów URL, minimalizując liczbę podobnych stron.
Lepiej może być również umieszczenie w rankingu jednego artykułu wysokiej jakości niż wielu przeciętnych artykułów, które dotyczą tego samego tematu.
Twórz dodatkowe treści
Zastanów się nad stworzeniem dodatkowych treści , które mogą sprawić, że strony będą bardziej wyjątkowe i wartościowe, a także zwiększą ich szanse na dobrą indeksację i dobrą pozycję w rankingu. Pomyśl o poprawie komfortu użytkownika i o tym, co najbardziej pomoże odwiedzającym .
Załóżmy na przykład, że masz stronę internetową z ofertami pracy.
W takim przypadku możesz stworzyć kalkulator wynagrodzeń. Możesz podać dodatkowe informacje, których odwiedzający mogą szukać, przedstawiając różne rodzaje umów, wyjaśniając każde odliczenie, przedstawiając zalety i wady różnych form zatrudnienia i tak dalej.
Przeglądaj strony z niewielką zawartością i zastanów się, czy możesz coś dodać.
Ale jeśli nie możesz ich ulepszyć, a oferują one użytkownikom ograniczoną wartość i nie mogą przyciągać ruchu organicznego do Twojej witryny, najlepiej dodać tag noindex, aby zapobiec ich indeksowaniu.
Wykorzystaj treści generowane przez użytkowników
Unikalne, kompleksowe treści tworzone przez użytkowników mogą być korzystne dla Twojej witryny. Na przykład możesz zachęcić klientów do wystawiania recenzji i wyświetlania ich na Twoich stronach.
Opinie mogą dostarczać rzeczywistych opisów, w jaki sposób klienci korzystają z Twoich produktów lub ich doświadczeń z Twoimi usługami, wzbogacając Twoją witrynę.
W szczególności strony produktów mogą korzystać z dogłębnych, bezstronnych recenzji zawierających zdjęcia i szczegółowe informacje o produkcie.
Wdrożenie określonych mechanizmów, takich jak minimalna liczba znaków, które użytkownik musi napisać, aby opublikować recenzję lub reklamę w Twojej witrynie, to doskonałe podejście do zapobiegania szczupłej lub powielanej treści generowanej przez użytkowników.
Zoptymalizuj wyświetlanie międzynarodowych treści
Jeśli masz kilka wersji językowych swojej witryny o tej samej treści, różne wersje językowe nie zostaną uznane za duplikaty.
Może to jednak być problematyczne , jeśli masz te same treści i używasz ich do kierowania reklam do osób w różnych regionach, które mówią tym samym językiem . Na przykład możesz mieć tę samą treść w różnych anglojęzycznych wersjach witryn – jednej dla Stanów Zjednoczonych, jednej dla Kanady i jednej dla Wielkiej Brytanii.
Jeśli udostępniasz te same treści różnym odbiorcom, zaimplementuj tagi hreflang, aby zasygnalizować Google, do jakiego języka i kraju chcesz dotrzeć.
Czasami, nawet gdy atrybuty hreflang są na miejscu, Google może sklasyfikować treść jako duplikat i po prostu złożyć dwie lub więcej wersji razem. W wielu przypadkach może to nie być poważny problem, ale może negatywnie wpłynąć na wrażenia użytkownika.
Dlatego należy po prostu unikać wyświetlania tej samej treści na wielu stronach.
Postaraj się zlokalizować swoje treści , zwłaszcza na strategicznych rynkach międzynarodowych . Lokalizacja to nie tylko tłumaczenie – musisz dostosować ją do konkretnego kraju, na który kierujesz reklamy, biorąc pod uwagę lokalne słownictwo, zwyczaje, walutę itp.
Zarządzaj linkami wewnętrznymi
Po wybraniu preferowanej wersji adresów URL sprawdź linki wewnętrzne witryny i upewnij się, że każdy z nich wskazuje właściwą wersję adresu URL.
Syndykuj zawartość poprawnie
Podczas dystrybucji treści oryginalne źródło musi być wybrane jako kanoniczne.
Podobnie, gdy inna witryna dystrybuuje Twoje treści, upewnij się, że zawierają one link do Twojej oryginalnej treści i wskazują prawidłowy adres URL.
Wyłącz dostęp do środowisk przejściowych
Środowiska pomostowe lub testowe zawierają kopię witryny dostępnej w środowisku produkcyjnym. Dlatego nie powinny być możliwe do przeszukiwania ani indeksowania w wyszukiwarkach. Aby uniemożliwić dostęp do nich botom i użytkownikom, zaimplementuj uwierzytelnianie HTTP.
Uniemożliwianie indeksowania wewnętrznych stron wyników wyszukiwania
Odwiedzający korzystający z Twoich wewnętrznych wyników wyszukiwania wyświetlają różne odmiany Twoich stron, zazwyczaj wyświetlając identyczne lub podobne adresy URL.
Upewnij się, że nie umieszczasz linków do wewnętrznych stron wyników wyszukiwania, aby boty nie mogły podążać ścieżką, aby je znaleźć i zindeksować.
Do tych stron należy dodać tagi noindex , aby nie zostały zindeksowane. Jeśli jednak zauważysz, że boty nadmiernie indeksują te strony, możesz ograniczyć ich dostęp w pliku robots.txt.
Warto zauważyć, że w niektórych przypadkach możesz chcieć zindeksować niektóre z Twoich wewnętrznych stron wyszukiwania – ale tylko niektóre z nich. Jeśli przeanalizujesz, w jaki sposób Twoi użytkownicy szukają Twoich treści w Google i zauważysz, że wewnętrzna strona wyszukiwania może idealnie odpowiadać intencji użytkownika, możesz ją zindeksować.
Zapobiegaj problemom z duplikatami treści powodowanymi przez CMS
Platformy CMS powodują swój udział w problemach ze zduplikowaną treścią.
Na przykład WordPress automatycznie generuje strony tagów i kategorii . Takie strony mogą być poważnym marnotrawstwem zasobów robotów indeksujących.
WordPress tworzy również paginację komentarzy , gdzie strony podzielone na strony pokazują oryginalną treść i wyświetlają tylko różne komentarze na dole.
Może się również okazać, że Twój CMS tworzy osobne strony dla obrazów , które nie zawierają żadnej innej treści.
Dodaj tagi noindex do niechcianych stron lub wyłącz te funkcje w swoim CMS.
Jak znaleźć zduplikowane problemy z treścią w swojej witrynie?
Istnieje kilka szybkich metod sprawdzenia, czy Twoje treści nie zostały zduplikowane.
Możesz użyć narzędzia takiego jak Copyscape , aby zobaczyć, jakie treści z Twoich stron pojawiają się w sieci.

Aby dowiedzieć się o problemach ze zduplikowaną treścią w Twojej witrynie, użyj Sitelinera , który pozwala odkryć, w jaki sposób strony w Twojej witrynie dopasowują się do treści.
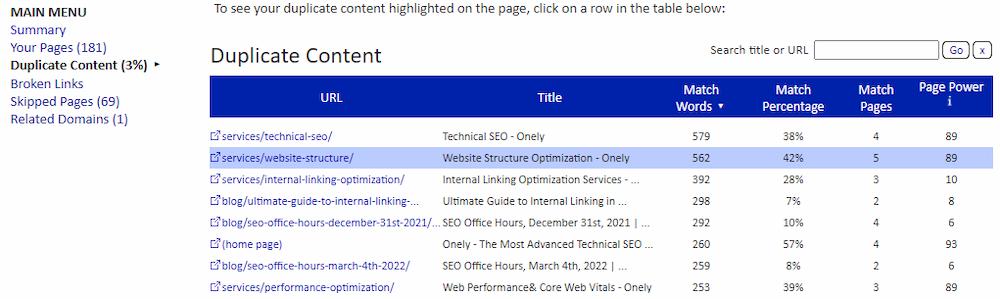
Raport dotyczący pokrycia indeksów Google
Aby bardziej szczegółowo przeanalizować problemy ze zduplikowanymi treściami, zapoznaj się z raportem Pokrycie indeksu Google Search Console, który pokaże konkretne problemy i sposoby ich rozwiązania.
Możesz tam znaleźć następujące błędy, które wskazują na problemy z indeksowaniem związane ze zduplikowaną zawartością:
Duplikuj bez kanonicznego wybranego przez użytkownika
Google znalazł zduplikowane adresy URL, które nie są kanonizowane do preferowanej wersji. Możesz sprawdzić, który adres URL został wybrany jako kanoniczny, przechodząc do narzędzia do sprawdzania adresów URL .
Aby rozwiązać ten problem, zalecamy samodzielne wybranie kanonicznego adresu URL .
Duplikat, Google wybrał inny kanoniczny niż użytkownik
Google zignorował określony kanoniczny adres URL i wybrał inny, który uznał za bardziej odpowiedni.
Ten problem wskazuje, że Google nie znalazł wystarczających sygnałów wskazujących na określony adres URL reprezentujący główną wersję danej treści – dowiedz się, jak naprawić Duplikat, Google wybrał inny kanoniczny niż użytkownik .
Zduplikowany, przesłany adres URL nie został wybrany jako kanoniczny
Ten stan wskazuje, że przesłałeś adresy URL bez kanonicznego adresu URL i że Google uważa przesłane adresy za duplikaty, więc wybrało inny kanoniczny adres URL.
Chociaż ten stan jest podobny do Duplikatu, Google wybrał inny kanoniczny niż użytkownik, różnica polega na tym, że wyraźnie zażądałeś zindeksowania tych adresów URL bez dołączania kanonicznego adresu URL .
Po raz kolejny musisz dodać tagi kanoniczne do preferowanego adresu URL.
Streszczenie
Zduplikowana treść nie spowoduje nałożenia na Google kar, ale może skutecznie spowolnić rozwój Twojej witryny w sieci.
Dlatego powinieneś być świadomy wszelkich zduplikowanych stron i monitorować swoje implementacje, aby upewnić się, że nie ma mechanizmu, który tworzy wiele stron bez Twojego nadzoru.
Tworzenie unikalnych treści na stronach, zapewnianie spójności adresów URL oraz implementacja tagów kanonicznych i przekierowań tam, gdzie to konieczne, to świetne sposoby na prawidłowe indeksowanie i pozycjonowanie stron przez Google.