
Como otimizar conteúdo duplicado para SEO
Publicados: 2022-08-03Conteúdo duplicado é o mesmo conteúdo ou conteúdo semelhante que existe em várias páginas, em um domínio ou em sites diferentes.
O conteúdo duplicado é problemático para os mecanismos de pesquisa porque, ao ver o mesmo conteúdo em vários locais, eles não sabem qual URL deve ser:
- Indexado,
- Sinais de classificação relevantes atribuídos e
- Listado mais alto nos resultados da pesquisa.
Isso pode levar a classificações mais baixas, desperdício de orçamento de rastreamento e problemas de indexação para seu site, consequentemente dissipando o potencial de negócios de suas páginas .
Para o bem do seu negócio, você precisa entender o que pode causar conteúdo duplicado e como otimizar os aspectos do seu site para evitar problemas – vamos explorá-lo.
Como o conteúdo duplicado afeta o SEO
Conteúdo duplicado nem sempre é um problema – se você usar SEO técnico para mantê-lo sob controle, isso não prejudicará seu tráfego orgânico. Mas se você deixar o conteúdo duplicado sem otimização, isso pode ter consequências mortais.
Aqui estão as principais maneiras pelas quais o conteúdo duplicado pode afetar negativamente seu site:
Classificações mais baixas
Várias versões do mesmo conteúdo fazem com que os mecanismos de pesquisa tenham dificuldade para decidir qual página deve ser indexada e apresentada nos resultados da pesquisa .
Quando for esse o caso, nenhuma de suas páginas duplicadas poderá atingir totalmente seu potencial de classificação, se elas forem rastreadas e indexadas em primeiro lugar.
Transferência reduzida de autoridade de link
Os motores de busca podem ter dificuldade em atribuir com precisão os sinais de classificação de backlinks para páginas duplicadas .
Se o mesmo conteúdo existir em algumas páginas, vários URLs podem receber links de outros domínios. Mas a autoridade total do link será dividida entre as páginas, limitando o potencial de classificação do seu conteúdo.
Problemas de indexação e orçamento de rastreamento desperdiçado
Se você tem um site grande, o orçamento de rastreamento costuma ser uma preocupação. E os mecanismos de pesquisa podem desperdiçar o orçamento de rastreamento ao rastrear páginas duplicadas .
Você sempre deseja que o orçamento de rastreamento seja gasto no rastreamento de conteúdo valioso. Quando você deixa conteúdo duplicado não otimizado em seu domínio, os bots de mecanismos de pesquisa podem desperdiçar alguns de seus recursos rastreando desnecessariamente o mesmo conteúdo repetidamente.
Isso não apenas atrasará a descoberta de outros conteúdos em seu site, mas também poderá desencorajá-los a voltar ao seu site com tanta frequência.
Se for esse o caso, você corre o risco de lidar com problemas de indexação . Lembre-se de que, na maioria das vezes, o Google analisará os diferentes sinais, como sitemaps, links internos e externos, redirecionamentos e outros, e escolherá um URL entre muitos para indexar. O problema é que pode não ser a versão que você deseja indexar.
Se o Google não conseguir rastrear algumas de suas páginas, você pode ter dificuldades para indexar suas páginas essenciais e exclusivas.
Além disso, ver grandes quantidades de páginas duplicadas pode fazer com que os mecanismos de pesquisa percebam todo o seu site como de baixa qualidade , supondo que outras páginas contenham conteúdo semelhante. Eles podem hesitar em alocar recursos para rastrear seu site no futuro.
Conteúdo duplicado pode levar a uma penalidade do Google?
Você pode ter ouvido opiniões conflitantes sobre se o conteúdo duplicado pode resultar em uma penalidade do Google.
Conteúdo duplicado não fará com que seu site seja penalizado, a menos que resulte de atividades maliciosas .
A raspagem de conteúdo é um exemplo de prática de manipulação relacionada a conteúdo duplicado. Ocorre quando alguém pega o conteúdo de suas páginas para republicá-lo em seu site.
Tais práticas são relativamente raras porque geralmente só causam problemas se o site de raspagem tiver mais autoridade e conseguir superar o site que publicou originalmente o conteúdo.
Você pode adicionar uma proteção para proteger seu conteúdo de tais práticas implementando tags canônicas autorreferenciais que apontam para suas páginas existentes para informar aos mecanismos de pesquisa que o conteúdo original vem de você.
Nos raros casos em que o Google percebe que conteúdo duplicado pode ser exibido com a intenção de manipular nossas classificações e enganar nossos usuários, também faremos os ajustes apropriados na indexação e classificação dos sites envolvidos. Como resultado, a classificação do site pode ser prejudicada ou o site pode ser totalmente removido do índice do Google e, nesse caso, não aparecerá mais nos resultados de pesquisa.fonte: documentação do Google
O Google pode diferenciar entre os tipos de conteúdo duplicado e entende qual conteúdo duplicado não pareceu manipular as classificações de pesquisa.
Exemplos de conteúdo duplicado não malicioso podem incluir:
- Fóruns de discussão que podem gerar páginas regulares e simplificadas direcionadas a dispositivos móveis
- Itens em uma loja online que são exibidos ou vinculados por vários URLs distintos
- Versões somente para impressão de páginas da web
fonte: documentação do Google
Se você não estiver roubando intencionalmente conteúdo de outros sites , não precisa se preocupar.
Quais são as causas do conteúdo duplicado
Normalmente, você não precisa de várias versões do mesmo conteúdo em seu site.
Portanto, o conteúdo duplicado tende a existir devido a erros e não a decisões conscientes.
Na maioria das vezes, o conteúdo duplicado aparece devido ao desenvolvimento deficiente da Web e implementações defeituosas no site , como configurações de servidor incorretas ou plataformas CMS não otimizadas.
Podemos encontrar duplicatas em todos os tipos de sites, mas alguns são mais propensos a isso, especialmente sites enormes com milhares ou milhões de páginas.
Em particular, os sites de comércio eletrônico podem lidar com quantidades excessivas de páginas duplicadas que são difíceis de acompanhar.
O conteúdo duplicado em sites de comércio eletrônico geralmente se aplica aos seguintes aspectos:
- As páginas de produtos têm pouco ou nenhum conteúdo ou incluem apenas descrições genéricas de produtos em muitas páginas. Se uma página contiver a descrição do fabricante de um determinado produto, ela também poderá aparecer em outros domínios, e o Google poderá tratá-la como conteúdo duplicado.
- As páginas de categoria têm filtros que exibem listas dos mesmos produtos em várias páginas.
Conteúdo idêntico em vários URLs também diz respeito a artigos de blog .
Os sites podem incluir artigos de comparação, listagem de recursos de produtos ou ferramentas, onde muitos conteúdos podem descrever as mesmas ferramentas, produtos ou funcionalidades em várias páginas.
As seções do blog podem ter artigos que correspondem a várias categorias – como resultado, vários URLs podem levar ao mesmo artigo.
Os sites de notícias geralmente utilizam tags que coletam conteúdo sobre tópicos relacionados, mas em algumas situações, as páginas podem usar várias tags e aparecer em vários locais do site.
O risco de conteúdo duplicado também diz respeito a sites que exibem listagens provenientes de bancos de dados usados por outros domínios , como marketplaces ou sites imobiliários. Consequentemente, anúncios ou postagens idênticas podem aparecer em vários domínios.
Muitos sites utilizam conteúdo gerado pelo usuário . Embora potencialmente benéfico, pode ser outra fonte de conteúdo duplicado – isso se aplica a qualquer site que contenha postagens, anúncios, páginas de perfil etc., criados pelos usuários. Muitas vezes, os usuários podem escrever apenas algumas palavras, usando texto copiado ou spam, ou apenas adicionar um link para seu site na página de perfil.
Esta não é de forma alguma uma lista exaustiva do que causa conteúdo duplicado, mas deve dar uma ideia de que tipo de conteúdo coloca seu site em risco e deve ser monitorado.
Maneiras de gerenciar conteúdo duplicado
Dependendo da qualidade e da função de suas páginas duplicadas na hierarquia do site, você pode querer abordá-las por meio de métodos diferentes.
Veja quais são suas opções e o que você deve saber sobre cada solução:
Usar tags canônicas
As tags canônicas informam aos mecanismos de pesquisa qual página contém a versão principal de determinado conteúdo e deve ser indexada.
Você pode informar aos mecanismos de pesquisa por meio da canonização que uma determinada página deve ser tratada como uma cópia de um URL especificado . Os sinais de classificação, como a autoridade do link aplicada a esta página pelos mecanismos de pesquisa, devem ser creditados no URL especificado.
A implementação de tags canônicas requer menos tempo de desenvolvimento do que outras soluções, como redirecionamentos, porque elas são adicionadas na página e não no nível do servidor. Certifique-se de adicionar tags canônicas à seção <head> do HTML – se você colocá-lo no <body>, ele não será respeitado.
Embora os bots de mecanismos de pesquisa normalmente sigam a diretiva canônica, em alguns casos, eles podem ignorá-la e escolher uma página canônica diferente. Isso pode acontecer se os mecanismos de pesquisa virem sinais mais fortes apontando para outro URL, como mais links internos ou backlinks autorizados.
Adicionar redirecionamentos
Outra solução para combater conteúdo duplicado é implementar redirecionamentos de URLs não preferenciais para suas versões preferidas.
Se você estiver redirecionando permanentemente uma URL, use um redirecionamento 301, que normalmente será a melhor opção quando se trata de gerenciar conteúdo duplicado.
Os redirecionamentos ajudam a consolidar os sinais de classificação em um URL , portanto, o Google deve indexar apenas a página de destino.
Implementar uma tag noindex
Você pode adicionar uma tag noindex a páginas duplicadas e que não devem ser indexadas por mecanismos de pesquisa, mas devem permanecer visíveis para os usuários .
No entanto, certifique-se de não bloquear o rastreamento dessas páginas – se o fizer, os bots não poderão ver a tag noindex.
Remover páginas duplicadas
Você pode remover páginas duplicadas se elas não servirem para seus visitantes ou sua empresa e você não planeja fazer melhorias nelas.

Você pode removê-los alterando seu código de status para 404 ou 410 .
Ambos os códigos de status têm as mesmas consequências de longo prazo. A única diferença é que 410 pode remover páginas do índice e limitar seu rastreamento mais rápido que o 404.
Práticas recomendadas para lidar com conteúdo duplicado
Vamos analisar os aspectos que você precisa considerar com páginas duplicadas para resolver possíveis problemas.
Decida se as páginas duplicadas devem ser rastreadas
Considere se você deve permitir que os mecanismos de pesquisa rastreiem suas páginas duplicadas . Depende muito do tipo de conteúdo duplicado e do que você pretende fazer com ele.
O Google precisa ser capaz de rastrear páginas se elas contiverem redirecionamentos – caso contrário, ele não as verá. O caso é semelhante se você adicionou tags noindex – o Google precisa rastrear uma página para descobrir uma tag noindex e segui-la.
Além disso, se você tiver feito melhorias em suas duplicatas , como adicionar conteúdo exclusivo, o Google precisará rastrear a página para reavaliar sua qualidade.
Se você tiver conteúdo duplicado que não agrega valor ao seu site e não puder fazer alterações nele, restrinja a capacidade dos mecanismos de pesquisa de rastreá-lo implementando a diretiva apropriada em robots.txt .
Ajuste sua estrutura de URL
Estruturas de URL inconsistentes podem causar muito conteúdo duplicado.
Aqui estão os aspectos dos URLs aos quais você deve prestar atenção:
Wwws e não wwws ou HTTP e HTTPS
Você pode ter URLs em seu site que podem ser acessados sem wwws como example.com e por meio de URLs que incluem wwws, como www.example.com .
O mesmo problema diz respeito ao protocolo: os URLs podem incluir http://example.com ou https://example.com .
A maioria dos sites modernos usa HTTPS, pois oferece uma comunicação mais segura. Mas, às vezes, você ainda pode ter algumas páginas que ainda estão acessíveis em HTTP. E, se você mudou para HTTPS e não redirecionou o site do HTTP, você pode até criar duas versões dele.
Independentemente de você adicionar www ou não, e qualquer protocolo usado, certifique-se de que seja consistente .
Se você descobrir qualquer URL que não siga o padrão selecionado, implemente redirecionamentos 301 para formas não preferenciais que levem à versão preferencial.
Caracteres minúsculos e maiúsculos
O Google trata os URLs como diferenciando maiúsculas de minúsculas . Assim, para o Google, example.com/page e example.com/PAGE serão duas páginas diferentes.
É comum usar caracteres minúsculos em URLs, por isso é mais fácil para os usuários digitá-los sem erros.
No entanto, se você usar os casos de forma intercambiável, poderá criar URLs diferentes com o mesmo conteúdo.
Se você encontrar alguma ocorrência como essa, escolha o URL com a capitalização preferida e redirecione a versão incorreta para ele .
Barras à direita
URLs idênticos com e sem uma barra no final também serão vistos como páginas diferentes – como example.com e example.com/ .
Mais uma vez, certifique-se de seguir o mesmo padrão de URL e redirecione as páginas erradas, se necessário.
Parâmetros de rastreamento ou filtragem
Parâmetros de filtragem em sites de comércio eletrônico geralmente levam a páginas duplicadas.
Se muitos filtros estiverem disponíveis, eles podem ser selecionados em diferentes combinações, gerando montanhas de URLs com o mesmo conteúdo ou quase idêntico. Um exemplo disso poderia ser https://www.example.com/clothes/dresses?size=medium .
Os parâmetros também costumam ser usados para fins de rastreamento , que é outra fonte de conteúdo duplicado. Por exemplo, você pode adicionar parâmetros UTM para rastrear visitas de fontes específicas, como Twitter ou boletim informativo. Aqui está um exemplo: https://example.com/page?utm_source=twitter .
Você deve canonizar seus URLs parametrizados para as versões de URL sem parâmetros de acompanhamento .
IDs de sessão
As sessões podem armazenar informações do visitante para análise da web, onde cada usuário que visita um site recebe um ID de sessão diferente armazenado na URL. Poderia ser assim: https://example.com?sessionId=jsdfo74256sdfh .
Se cada URL solicitado por um visitante receber um ID de sessão anexado, haverá muitas páginas duplicadas porque o conteúdo desses URLs é o mesmo.
Canonicalize os URLs com IDs de sessão anexados aos URLs sem eles.
URLs somente para impressão
Ter uma versão para impressão de uma página em um URL separado significa que há duas versões do mesmo conteúdo, por exemplo, https://www.example.com/page/ e https://www.example.com/print /página/ .
Implemente um URL canônico da versão para impressão para a versão padrão da página.
Otimize seu conteúdo
Você pode fazer outros ajustes concentrando-se no conteúdo de suas páginas.
A conclusão é que, se você tiver páginas valiosas que devem classificar e direcionar tráfego, certifique-se de que elas contenham conteúdo exclusivo e de alta qualidade que segmente a intenção específica do usuário.
Apesar de consumir tempo e recursos, valerá a pena a longo prazo.
Aqui estão alguns aspectos de conteúdo a serem considerados em sua otimização:
Melhore as páginas de produtos
Forneça descrições exclusivas do produto em vez de copiar a descrição genérica do fabricante.
Um FAQ é um excelente lugar para incluir informações adicionais sobre seus produtos ou serviços. Tenha cuidado, porém – se você listar os detalhes exatos mencionados na descrição do produto, pode ser uma duplicação de conteúdo parcial.
Ajustar páginas de categoria
Cada página de categoria deve ser única e relevante . Navegue pelas suas categorias e pense se cada uma é necessária – quão úteis elas são para os usuários?
Considere remover alguns ou combiná-los em um. Faça o mesmo para todas as opções de filtragem ou classificação disponíveis nas categorias.
Consolidar conteúdo
Se você tiver alguns artigos discutindo tópicos relacionados, considere consolidá-los em um conteúdo maior que pode ser sua versão mais abrangente.
Dessa forma, você pode criar conteúdo útil que forneça todas as informações em um só lugar, em vez de dispersá-las em algumas URLs, minimizando o número de páginas semelhantes.
Também pode ser melhor classificar com um artigo de alta qualidade do que vários medíocres que visam o mesmo assunto.
Crie conteúdo complementar
Considere a criação de conteúdo complementar que pode tornar as páginas mais exclusivas e valiosas e aumentar suas chances de serem indexadas e classificadas bem. Pense em melhorar a experiência do usuário e o que mais ajudará os visitantes .
Por exemplo, suponha que você tenha um site com ofertas de emprego.
Nesse caso, você pode criar uma calculadora de salário. Você pode fornecer informações adicionais que os visitantes podem procurar descrevendo os diferentes tipos de contratos, explicando cada dedução, fornecendo prós e contras para várias formas de emprego e assim por diante.
Navegue pelas páginas com pouco conteúdo e pense se há algo que você possa adicionar.
Mas se você não puder melhorá-los e eles oferecerem valor limitado aos usuários e não puderem direcionar o tráfego orgânico para seu site, é melhor adicionar uma tag noindex para evitar que sejam indexados.
Utilize conteúdo gerado pelo usuário
Conteúdo exclusivo e abrangente criado por usuários pode ser benéfico para seu site. Por exemplo, você pode incentivar os clientes a deixar comentários e exibi-los em suas páginas.
As avaliações podem fornecer descrições reais de como os clientes usam seus produtos ou a experiência deles com seus serviços, enriquecendo seu site.
Em particular, as páginas de produtos podem se beneficiar de análises detalhadas e imparciais contendo imagens e informações específicas sobre o produto.
A implementação de mecanismos específicos, como um número mínimo de caracteres que um usuário precisa escrever para postar um comentário ou anúncio em seu site, é uma excelente abordagem para evitar conteúdo pequeno ou duplicado gerado pelo usuário.
Otimize a veiculação de conteúdo internacional
Se você tiver algumas versões de idioma do seu site com o mesmo conteúdo, as diferentes versões de idioma não serão consideradas duplicadas.
No entanto, pode ser problemático se você tiver o mesmo conteúdo e usá-lo para segmentar pessoas em diferentes regiões que falam o mesmo idioma . Por exemplo, você pode ter o mesmo conteúdo em diferentes versões de sites em inglês – uma para os EUA, uma para o Canadá e outra para o Reino Unido.
Se você estiver veiculando o mesmo conteúdo para públicos diferentes, implemente tags hreflang para indicar ao Google qual idioma e país você está tentando alcançar.
Às vezes, mesmo quando os atributos hreflang estão em vigor, o Google pode classificar o conteúdo como duplicado e simplesmente juntar duas ou mais versões. Pode não ser um problema grave em muitos casos, mas pode afetar negativamente a experiência do usuário.
É por isso que você deve simplesmente evitar mostrar o mesmo conteúdo em várias páginas.
Faça um esforço para localizar seu conteúdo , especialmente para mercados internacionais estratégicos . Localizar não é apenas traduzir – você precisa torná-lo adequado para o país específico que você está segmentando, levando em consideração o vocabulário local, costumes, moeda etc.
Gerenciar links internos
Depois de decidir sobre a versão preferida dos seus URLs, verifique os links internos do seu site e certifique-se de que cada um deles aponta para a versão correta do URL.
Distribua o conteúdo corretamente
Ao distribuir conteúdo, a fonte original deve ser escolhida como canônica.
Da mesma forma, quando outro site distribuir seu conteúdo, certifique-se de que ele inclua um link para seu conteúdo original e aponte para o URL correto.
Desabilitar o acesso a ambientes de teste
Os ambientes de preparação ou teste contêm uma cópia do site disponível em produção. Portanto, eles não devem ser rastreáveis ou indexáveis aos mecanismos de pesquisa. Para evitar que eles sejam acessados por bots e usuários, implemente a autenticação HTTP.
Tornar as páginas internas de resultados de pesquisa não indexáveis
Os visitantes que usam seus resultados de pesquisa internos visualizam diferentes variações de suas páginas, geralmente mostrando URLs idênticos ou semelhantes.
Certifique-se de não vincular a páginas de resultados de pesquisa internas para que os bots não possam seguir um caminho para encontrá-los e rastreá-los.
Você deve adicionar tags noindex a essas páginas, para que elas não sejam indexadas. No entanto, se você perceber que os bots rastreiam essas páginas excessivamente, você pode restringir o acesso deles no arquivo robots.txt.
Vale a pena notar que, em alguns casos, você pode realmente querer que algumas de suas páginas de pesquisa internas sejam indexadas – mas apenas algumas delas. Se você analisar como seus usuários estão procurando seu conteúdo no Google e perceber que uma página de pesquisa interna pode responder perfeitamente à intenção do usuário, sinta-se à vontade para tornar essa página indexável.
Evite problemas de conteúdo duplicado causados pelo CMS
As plataformas CMS causam sua parcela de problemas com conteúdo duplicado.
Por exemplo, o WordPress gera automaticamente páginas de tags e categorias . Essas páginas podem ser um grande desperdício de recursos dos rastreadores.
O WordPress também cria paginação de comentários , onde as páginas paginadas mostram o conteúdo original e exibem apenas comentários diferentes na parte inferior.
Você também pode descobrir que seu CMS cria páginas separadas para imagens que não contêm nenhum outro conteúdo.
Adicione tags noindex a páginas indesejadas ou desative esses recursos em seu CMS.
Como encontrar problemas de conteúdo duplicado em seu site
Existem alguns métodos rápidos para verificar se seu conteúdo pode ter sido duplicado.
Você pode usar uma ferramenta como Copyscape para ver qual conteúdo de suas páginas aparece na web.

Para saber mais sobre problemas de conteúdo duplicado em seu site, use o Siteliner , que descobre como as páginas do seu site correspondem ao conteúdo umas das outras.
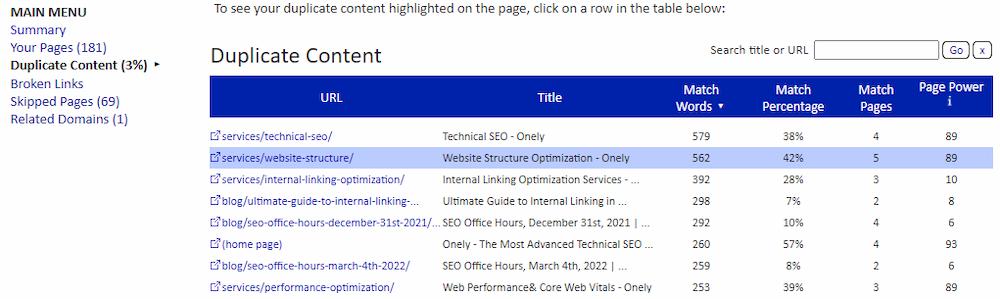
Relatório de cobertura de índice do Google
Para analisar os problemas de conteúdo duplicado com mais detalhes, visite o relatório Cobertura de índice do Google Search Console que mostrará os problemas específicos e como você pode resolvê-los.
Você pode encontrar os seguintes erros que indicam problemas de indexação relacionados a conteúdo duplicado:
Duplicar sem canônico selecionado pelo usuário
O Google encontrou URLs duplicados que não são canonizados para a versão preferida. Você pode verificar qual URL foi escolhido como canônico navegando até a ferramenta de inspeção de URL .
Para resolver esse problema, é recomendável que você mesmo selecione o URL canônico .
Duplicado, o Google escolheu um canônico diferente do usuário
O Google ignorou o URL canônico especificado e selecionou um diferente que achou mais adequado.
Esse problema indica que o Google não encontrou sinais suficientes apontando para o URL especificado que representa a versão principal do conteúdo fornecido - descubra como corrigir Duplicate, o Google escolheu canônico diferente de user .
URL enviado duplicado não selecionado como canônico
Esse status indica que você enviou URLs sem um URL canônico e que o Google considera os URLs enviados duplicados, por isso escolheu um canônico diferente.
Embora esse status seja semelhante a Duplicado, o Google escolheu um canônico diferente de usuário, a diferença é que você solicitou explicitamente que o Google indexasse esses URLs sem incluir um URL canônico .
Mais uma vez, você precisa adicionar tags canônicas ao URL preferido.
Resumo
Conteúdo duplicado não levará a penalidades do Google, mas ainda pode efetivamente retardar o crescimento do seu site na web.
É por isso que você deve estar ciente de quaisquer páginas duplicadas e monitorar suas implementações para garantir que não haja nenhum mecanismo que crie várias páginas sem sua supervisão.
Criar conteúdo exclusivo nas páginas, garantir a consistência do URL e implementar tags canônicas e redirecionamentos, quando apropriado, são ótimas maneiras de ajudar o Google a indexar e classificar suas páginas corretamente.