
ETL vs. ELT: ビジネスに適したデータ パイプラインはどれですか?
公開: 2022-12-13ETL と ELT は、データをある場所から別の場所に移動し、途中で変換する方法です。 しかし、どちらがあなたのビジネスに適していますか?
この投稿では、ETL と ELT を速度、データ保持、スケーラビリティ、非構造化データ管理、規制順守、メンテナンス、およびコストで比較します。 最後に、データ パイプラインで各メソッドを使用するタイミングとその理由を理解する必要があります。
重要ポイント:
- ETL は、その正確性、効率性、および柔軟性により、何十年にもわたって標準的なデータ パイプラインとなっています。
- ELT は、最初にターゲット データベースにデータをロードしてから変換する ETL プロセスの一種です。
- ELT はスタンドアロン サーバーでのデータ変換を必要としないため、多くの場合 ETL よりも簡単で高速です。データは変換先内で変換されます。
- ELT パイプラインの主な利点には、リアルタイム分析、メンテナンスの容易さ、スケーラビリティ、非構造化データのサポート、全体的なコストの削減などがあります。
抽出、変換、読み込み (ETL) とは何ですか?
ビジネスの世界では、データは水のようなものです。 見つかった場所から抽出し、必要な場所に移送してから、後で使用できるように保管する必要があります。 このプロセスはETL (抽出、変換、およびロード)として知られています。
配管パイプラインのように、ETL はデータをある場所から別の場所に移動し、途中でクリーンアップして、中央の場所に保存します。 抽出段階は、川や井戸で水を見つけることに相当します。 変換段階は、水が浄化され、パイプを通って運ばれるときです。 そして、負荷段階は、水が貯水池に貯蔵されているときです。
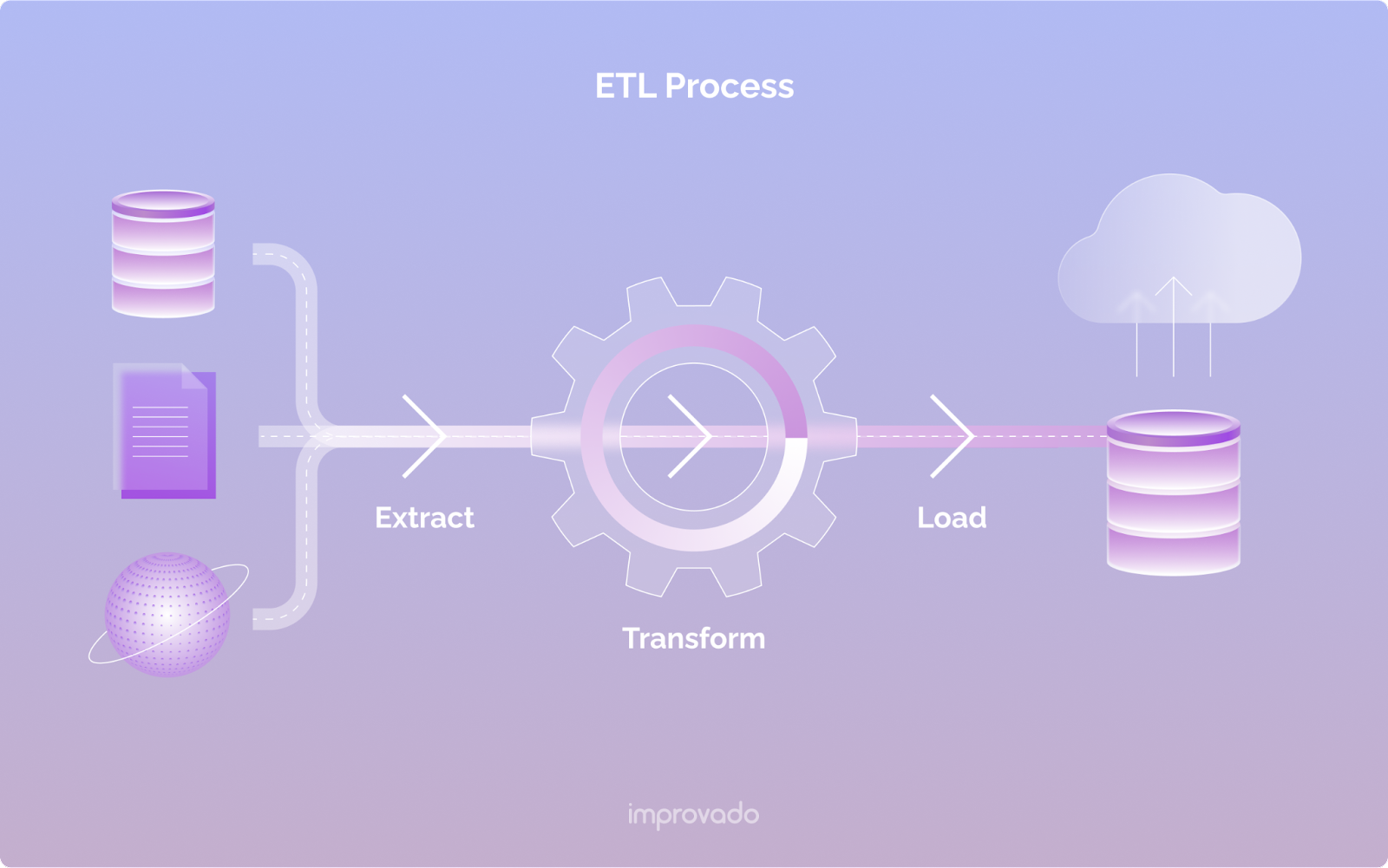
ETL パイプラインの主な利点
ETL が何十年にもわたって標準的なデータ パイプラインであった理由は多数あります。 大まかに言えば、ETL は、企業がさまざまなソースから取得したデータに対して単一の信頼できるポイントを持つことを保証します。 データは分析のために最終的な宛先にロードされる前に変換されるため、ETL はデータが高品質で正確であることを保証します。
実際には、ETL は自動化と変換によってデータの正確性、効率性、柔軟性を向上させます。 ETL は、データ ガバナンスにも不可欠です。 適切に設計されたパイプラインは記録された履歴を保持し、内部ポリシーおよび外部規制への準拠に役立ちます。 たとえば、Improvado の ETL ツールは HIPAA および SOC-2 に準拠しているため、機密データを処理できます。
したがって、ETL パイプラインは、オムニチャネルのカスタマー エクスペリエンス、ビジネス インテリジェンス、およびデータ駆動型の意思決定への扉を開きます。
抽出、読み込み、変換 (ELT) とは?
抽出、読み込み、変換 (ELT)は、指定されたストレージにデータをロードしてから変換する ETL プロセスの一種です。
水の比喩に戻ります。ELT は、家の蛇口をひねって水を汲むときのようなものです。 水はすでに家の中にあるので、蛇口をひねるだけで出てきます。 ELT はデータでも同じです。 データはすでに宛先にあるので、蛇口をオンにするだけで、変換されて出力されます。
ELT は、ClickHouse や jQuery などの列指向データベースの導入により勢いを増しました。 以前は、企業は抽出と変換のロジックを構築してデータベース リソースを節約するために、時間とリソースを事前に費やさなければなりませんでした。 新世代のデータベースは、データの処理と計算の完了を大幅に高速化でき、一般にコストが低くなります。 したがって、ロード時に生データを変換する必要がなくなりました。
この従来の ETL プロセスの逆転により、ロードと並行して変換を実行できるため、データ パイプラインの管理が簡素化され、時間を節約できます。 別のインスタンスとしてデータ変換を行う必要がないため、データ変換へのよりシンプルで高速なアプローチを提供します。 代わりに、データは、通常はデータ ウェアハウスである宛先内で変換されます。
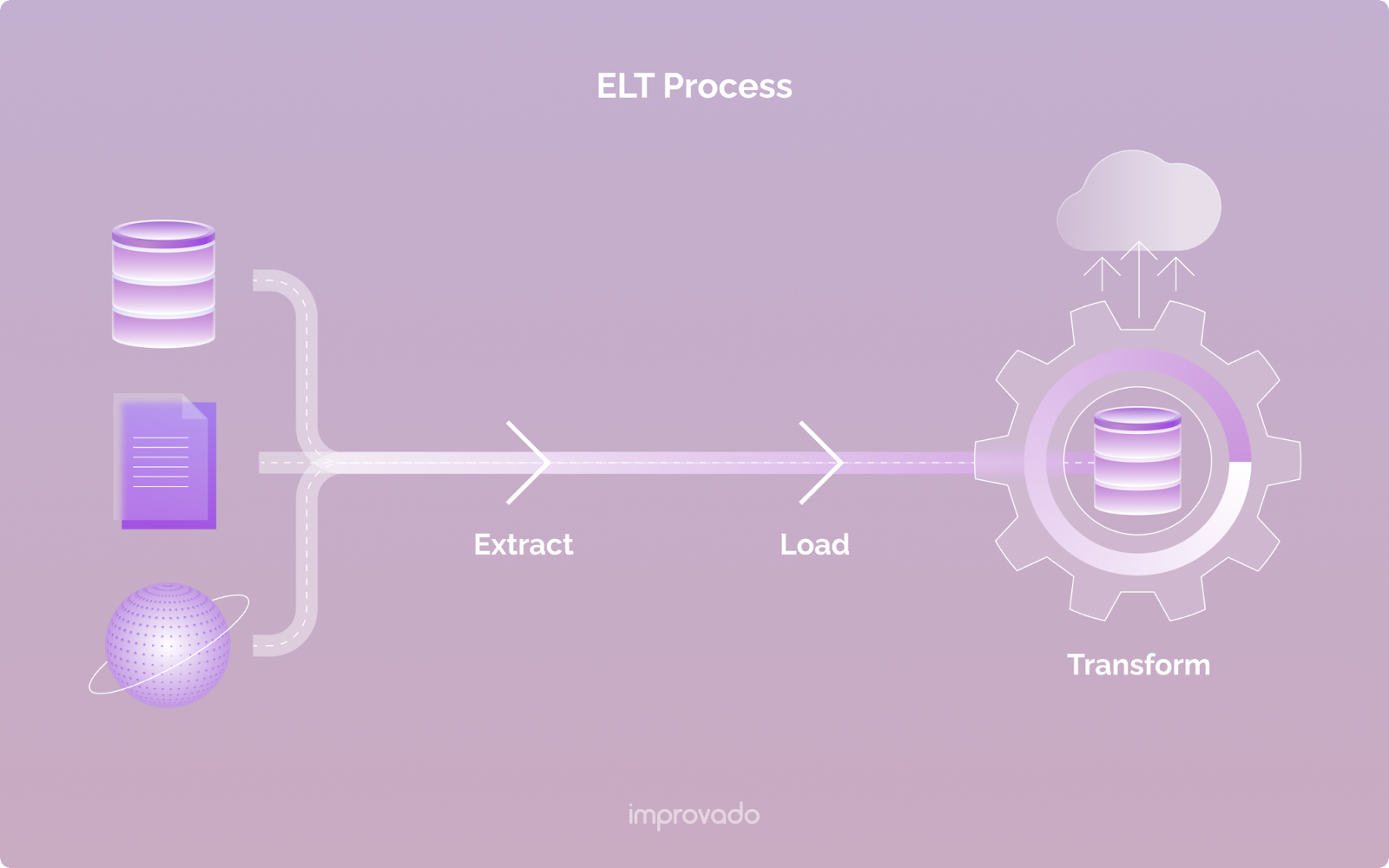
ELT パイプラインの主な利点
ELT は、そのシンプルさと柔軟性により人気を博しています。 データ チームは、さまざまなソースから生データを集約し、いつでもアクセスして詳細な分析を行い、本当に必要なときに変換ロジックを考え出すことができます。

ELT は、ETL よりも高速にデータを読み込んで変換できるため、リアルタイムのデータ分析に最適です。 ELT は、企業が複雑な、または絶え間なく変化する変革プロセスを運用している場合にも適しています。
さらに、ELT は別の変換ソフトウェアを管理する必要がないため、ETL よりも保守が容易です。 また、データの正確性や効率性など、ETL と同じ利点の多くを引き続き提供します。
ETL と ELT プロセスの比較
ETL と ELT の利点を確認した後、2 つのプロセスを並べて比較してみましょう。
スピード
変換ステップのタイミングにより、ELT は ETL よりも高速です。
サイズが 1 テラバイトのデータ セットを読み込んでいるとします。 ETL では、変換を開始する前に、データ セット全体を変換サーバーにロードする必要があります。 しかし、ELT を使用すると、データの読み込みと変換を並行して行うことができるため、プロセスの完了に必要な全体の時間を大幅に短縮できます。
ただし、ETL が ELT よりも高速な場合もあります。 これは通常、データ セットが小さく、スタンドアロン インスタンスで簡単に変換できる場合です。
生データの保持
ELT プロセスはすべての生データを抽出し、データ ウェアハウスに無期限に保存します。 変換は必要に応じて後で適用されます。つまり、常に元のデータ セットを保持できるため、履歴分析やデバッグに役立ちます。
ETL の場合、選択したターゲット データ ウェアハウスまたはデータベースにデータをロードする前に、データに広範な変換が行われます。 そのため、ETL はデータを集約形式に変換してスペースを節約する可能性があり、元のデータと変換されたデータの両方を宛先にロードしない限り、元の値を追跡することが困難になります。 出力データを変更したい場合、または生データ ソースが変更された場合は、抽出変換スクリプトを (1 つとして) 書き直す必要があります。
スケーラビリティ
ELT は、3 つのステップ (抽出、読み込み、変換) がすべて個別に実行されるため、より柔軟です。 これにより、プロセスで必要なものを簡単にスケーリングおよび変更できます。
一方、変換レイヤーには固有の制限があるため、ETL はより厳格です。 たとえば、スケジュールされた抽出、並列抽出、高度な変換ロジックなどの高度な機能を追加する場合など、ビジネスが成長するにつれて進化するのは難しくなります。また、ELT の調整よりも多くのリソースが必要です。プロセス。 結局のところ、一方が行うことは他方に影響を与えます。
同じことが品質保証プロセスにも当てはまります。 ETL では、抽出と変換が一緒に行われるため、QA プロセスの設定と製品のテストにより多くの作業が必要になります。 それに比べて、最初にデータを抽出してロードし、それを変換するだけの ELT ロジックは、テストがはるかに簡単です。
非構造化データ
ETL システムは、ログ ファイル、ソーシャル メディア データ、電子メール メッセージなどの非構造化データの処理には適していません。行と列に編成された構造化データを処理するように設計されています。 ETL は非構造化データの処理に適応できますが、高度な変換エンジンを使用する必要があります。
一方、ELT システムは、データをより効率的に読み込んで変換できるため、非構造化データの処理にすぐに利用できます。
企業コンプライアンス
一部の業界では、特定の方法でのデータ処理を必要とする規制の対象となっています。 たとえば、ヘルスケア業界は HIPAA に縛られています。 このコンプライアンス法は、患者のプライバシーを保護するために、企業が保護医療情報 (PHI) および電子保護医療情報 (ePHI) を収集、利用、または共有する方法を規定しています。
企業は、これらの規制要件を満たすように ETL を構成できます。これは、データを宛先データベースにロードする前にクレンジングおよび変換できるためです。
一方、ELT はコンプライアンス違反を起こしやすい傾向があります。 システムは、その機密性に関係なく、すべてのデータをロードし、変換または削除されます。 これらの制限の回避策は、堅牢なセキュリティとデータ ガバナンスの手段を確保することです。
メンテナンス
ETL および ELT システムでは、メンテナンス コストが高くなる可能性がありますが、発生する段階は異なります。
ETL では、未加工のデータ ソースが時間の経過とともに変化するにつれて、抽出と変換のスクリプトを常に更新する必要があり、メンテナンスのオーバーヘッドが増加する可能性があります。
ELT では、ほとんどのメンテナンスは、データをストレージに最初にロードするときと、データを変換するときに発生します。 最初の読み込みデータ ストレージは、受信する生データのダンプ グラウンドとして機能するため、すぐに管理不能になる可能性があります。 負荷を管理するために、定期的なクリーンアップと文書化の取り組みが実施されています。
さらに、生データ ソースが変更されるたびに、変換パイプラインを再設計する必要があります。 これには保守作業が必要ですが、変換スクリプトが新しい受信データ構造に適応できなくてもデータが失われないため、エンジニアはより柔軟に対応できます。
費用
ソフトウェア開発プロジェクトを経験したことがある人なら誰でも知っているように、コストはすぐに手に負えなくなります。 また、データ プロジェクトに関しては、堅牢な ETL ソリューションを開発するコストが法外に高くなる可能性があります。そのため、一部の企業は代わりに ELT を使用することを選択しています。
ELT を使用すると、変換ステップの多くを dbt などの既存のツールまたは SQL の助けを借りて処理できます。どちらも従来の ETL ソリューションよりも安価になる傾向があります。 もちろん、これらのツールを効果的に使用する方法を知っている経験豊富な開発者の必要性は依然としてあります。 しかし、全体として、ELT ソリューションを開発するコストは、ETL ソリューションをゼロから開発するコストよりも大幅に低くなる可能性があります。
概観すると、米国の中級から上級のバックエンド エンジニアの平均基本給は、年間 124,397 ドルです。 一方、SQL データ エンジニアまたは BI 開発者の平均年収は約 91,055 ドルです。 したがって、パイプラインに取り組むために複数の開発者を雇う必要がある場合は、ELT の方が費用対効果が高くなります。
生データを保存しないため、ETL の方がストレージのコストが低いことは認識しておく価値がありますが、クラウド ストレージを使用する場合、この違いは重要ではありません。
ETL と ELT のどちらを選択するかを決定する方法
ETL と ELT のどちらを選択するかは、それぞれのアプローチに長所と短所があるため、難しい場合があります。 決定を下すのに役立ついくつかの質問をまとめました。
どのような種類のデータを処理する必要がありますか?
データは構造化されているか、構造化されていないか、または両方が混在していますか? ETL は構造化データに最適ですが、ELT は構造化データと非構造化データの両方を処理できます。
メンテナンスはどのくらい必要ですか?
ETL の利点は、それを維持するためのコストを上回りますか? たとえば、ETL が提供する生データ履歴へのアクセスが必要になる場合があります。 この場合、ETL の利点は、追加のメンテナンス コストに見合う価値があるかもしれません。
データ処理パイプラインはどのくらい複雑ですか?
ETL と ELT のどちらが優れたソリューションであるかは、データ処理パイプラインの洗練度によって決まります。 たとえば、ETL は複雑な変換ロジックを実行できますが、小さいデータ セットで最適なパフォーマンスを発揮します。一方、ELT は大規模なデータセットに最適ですが、あらゆるデータ サイズを処理できます。
リアルタイムのデータが必要ですか?
ETL はデータをバッチで処理するため、データが収集されてから宛先データベースで使用可能になるまでに遅延が生じます。 ELT はデータをバッチで処理することもできますが、リアルタイムで処理することもできるため、最新のデータが必要な場合に役立ちます。
開発者はどのくらい経験がありますか?
エンジニアリング チームの特定のスキルと経験に依存するため、この質問に対する万能の答えはありません。 一般的に言えば、ELT よりも ETL アプローチに熟練しているエンジニアの方が多いです。 データ パイプラインが整ったら、BI/SQL エンジニアは ELT プロセスに変更を加えることができますが、ETL の変更には中/上級のバックエンド開発者が必要です。
ETL であろうと ELT であろうと、Improvado Has You Covered
アプローチに関係なく、Improvado は、幅広いデータ ソース コネクタと宛先を使用して、必要な場所でデータ フローを支援できます。 Impprovado の経験豊富なデータ エンジニア チームは、社内外のデータ規制とニーズに合わせて特別に調整されたソリューションの設計と実装を支援します。