
ETL vs. ELT: Welche Datenpipeline ist die richtige für Ihr Unternehmen?
Veröffentlicht: 2022-12-13ETL und ELT sind Methoden, um Daten von einem Ort zum anderen zu verschieben und sie dabei zu transformieren. Aber welches ist das Richtige für Ihr Unternehmen?
Dieser Beitrag vergleicht ETL und ELT in Bezug auf Geschwindigkeit, Datenaufbewahrung, Skalierbarkeit, Verwaltung unstrukturierter Daten, Einhaltung gesetzlicher Vorschriften, Wartung und Kosten. Am Ende sollten Sie wissen, wann Sie welche Methode in Ihrer Datenpipeline verwenden und warum.
Die zentralen Thesen:
- ETL ist aufgrund seiner Genauigkeit, Effizienz und Flexibilität seit Jahrzehnten die Standard-Datenpipeline.
- ELT ist eine Variante des ETL-Prozesses, der Daten zuerst in eine Zieldatenbank lädt und sie dann transformiert.
- ELT ist in vielen Fällen unkomplizierter und schneller als ETL, da keine Datentransformation auf einem eigenständigen Server erforderlich ist – die Daten werden stattdessen innerhalb des Ziels transformiert.
- Zu den wichtigsten Vorteilen einer ELT-Pipeline gehören Echtzeitanalysen, Wartungsfreundlichkeit, Skalierbarkeit, Unterstützung unstrukturierter Daten und insgesamt niedrigere Kosten.
Was ist Extrahieren, Transformieren, Laden (ETL)?
In der Geschäftswelt sind Daten wie Wasser. Es muss dort extrahiert werden, wo es gefunden wird, dorthin transportiert werden, wo es benötigt wird, und dann für die spätere Verwendung gelagert werden. Dieser Prozess wird als ETL bezeichnet: extrahieren, transformieren und laden .
Wie eine Rohrleitung verschiebt ETL Daten von einem Ort zum anderen, bereinigt sie unterwegs und speichert sie an einem zentralen Ort. Die Extraktionsphase entspricht dem Auffinden von Wasser in einem Fluss oder Brunnen. In der Transformationsphase wird das Wasser gereinigt und durch Rohre transportiert. Und die Ladephase ist, wenn das Wasser in einem Reservoir gespeichert wird.
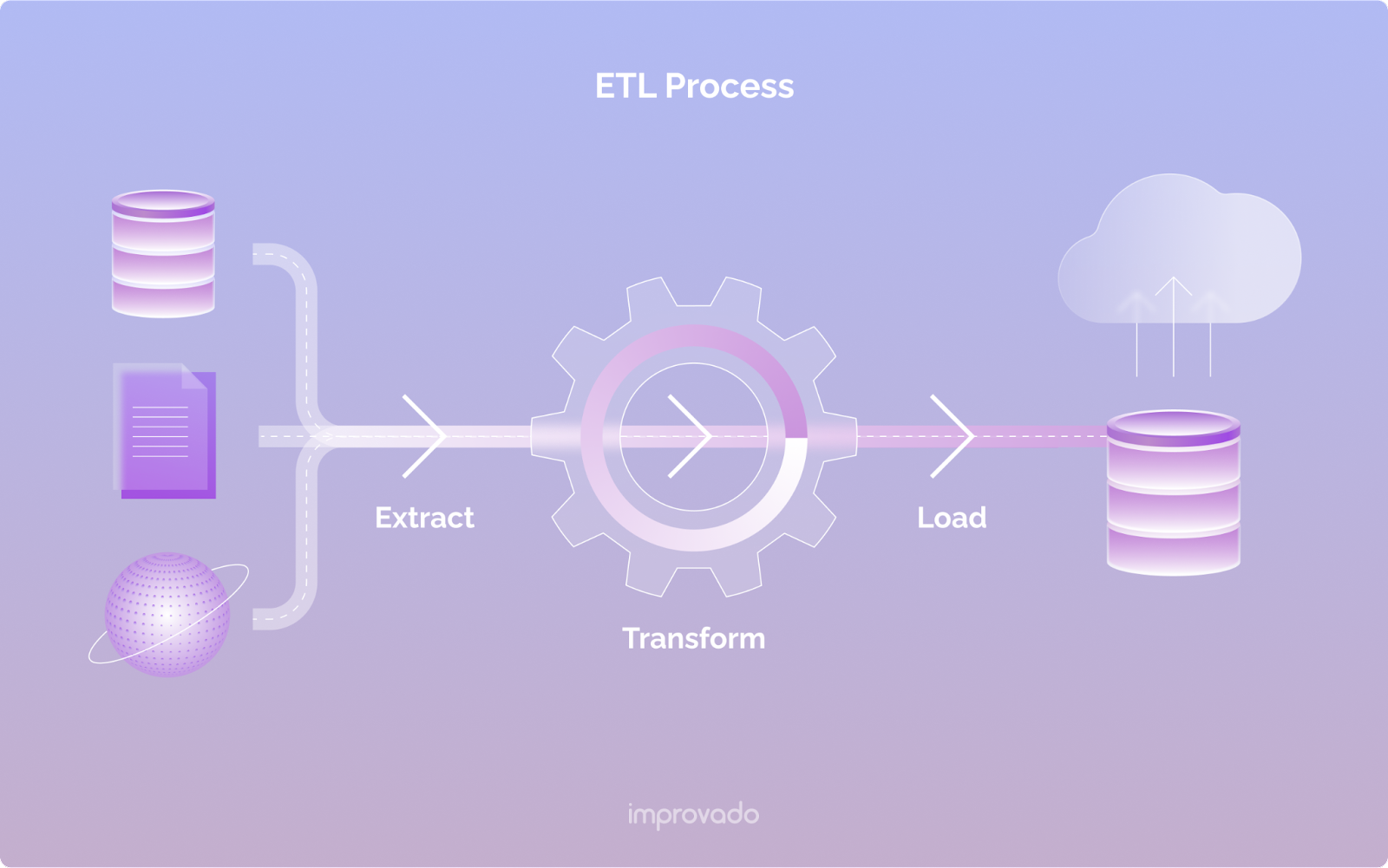
Hauptvorteile der ETL-Pipeline
Es gibt viele Gründe, warum ETL seit Jahrzehnten die Standard-Datenpipeline ist. Auf hoher Ebene stellt ETL sicher, dass ein Unternehmen einen einzigen Point of Truth für Daten hat, die aus unterschiedlichen Quellen abgerufen werden. Da Daten transformiert werden, bevor sie zur Analyse an den endgültigen Bestimmungsort geladen werden, stellt ETL sicher, dass die Daten von hoher Qualität und Genauigkeit sind.
Praktisch gesehen verbessert ETL die Datengenauigkeit, Effizienz und Flexibilität durch Automatisierung und Transformationen. ETL ist auch für die Data Governance von entscheidender Bedeutung. Eine gut konzipierte Pipeline führt einen aufgezeichneten Verlauf, der bei der Einhaltung interner Richtlinien und externer Vorschriften hilft. Beispielsweise ist das ETL-Tool von Improvado HIPAA- und SOC-2-konform, sodass es mit sensiblen Daten umgehen kann.
Somit öffnet eine ETL-Pipeline Türen zu Omnichannel-Kundenerlebnissen, Business Intelligence und datengesteuerter Entscheidungsfindung.
Was ist Extrahieren, Laden, Transformieren (ELT)?
Extract, Load, Transform (ELT) ist eine Variante des ETL-Prozesses, bei dem Daten zuerst in einen bestimmten Speicher geladen und dann transformiert werden.
Zurück zur Wassermetapher: ELT ist wie wenn Sie den Wasserhahn in Ihrem Haus aufdrehen, um Wasser zu bekommen. Das Wasser ist bereits im Haus, Sie müssen also nur den Wasserhahn aufdrehen, und es kommt heraus. ELT ist dasselbe für Daten. Die Daten sind bereits am Zielort, Sie müssen also nur den Wasserhahn aufdrehen, und schon kommen sie transformiert heraus.
ELT gewann mit der Einführung spaltenorientierter Datenbanken wie ClickHouse und jQuery an Dynamik. Früher mussten Unternehmen im Voraus Zeit und Ressourcen für die Erstellung der Extraktions-Transformations-Logik aufwenden, um Datenbankressourcen einzusparen. Die neue Generation von Datenbanken kann Daten viel schneller verarbeiten und Berechnungen durchführen, und sie kosten im Allgemeinen weniger. Somit entfällt die Notwendigkeit, Rohdaten beim Laden zu transformieren.
Diese Umkehrung des traditionellen ETL-Prozesses kann die Verwaltung der Datenpipeline vereinfachen und Zeit sparen, da Sie die Transformation parallel zum Laden durchführen können. Es bietet einen einfacheren und schnelleren Ansatz für die Datentransformation, da keine Datentransformation als separate Instanz erforderlich ist. Stattdessen werden die Daten innerhalb des Ziels transformiert, bei dem es sich in der Regel um ein Data Warehouse handelt.
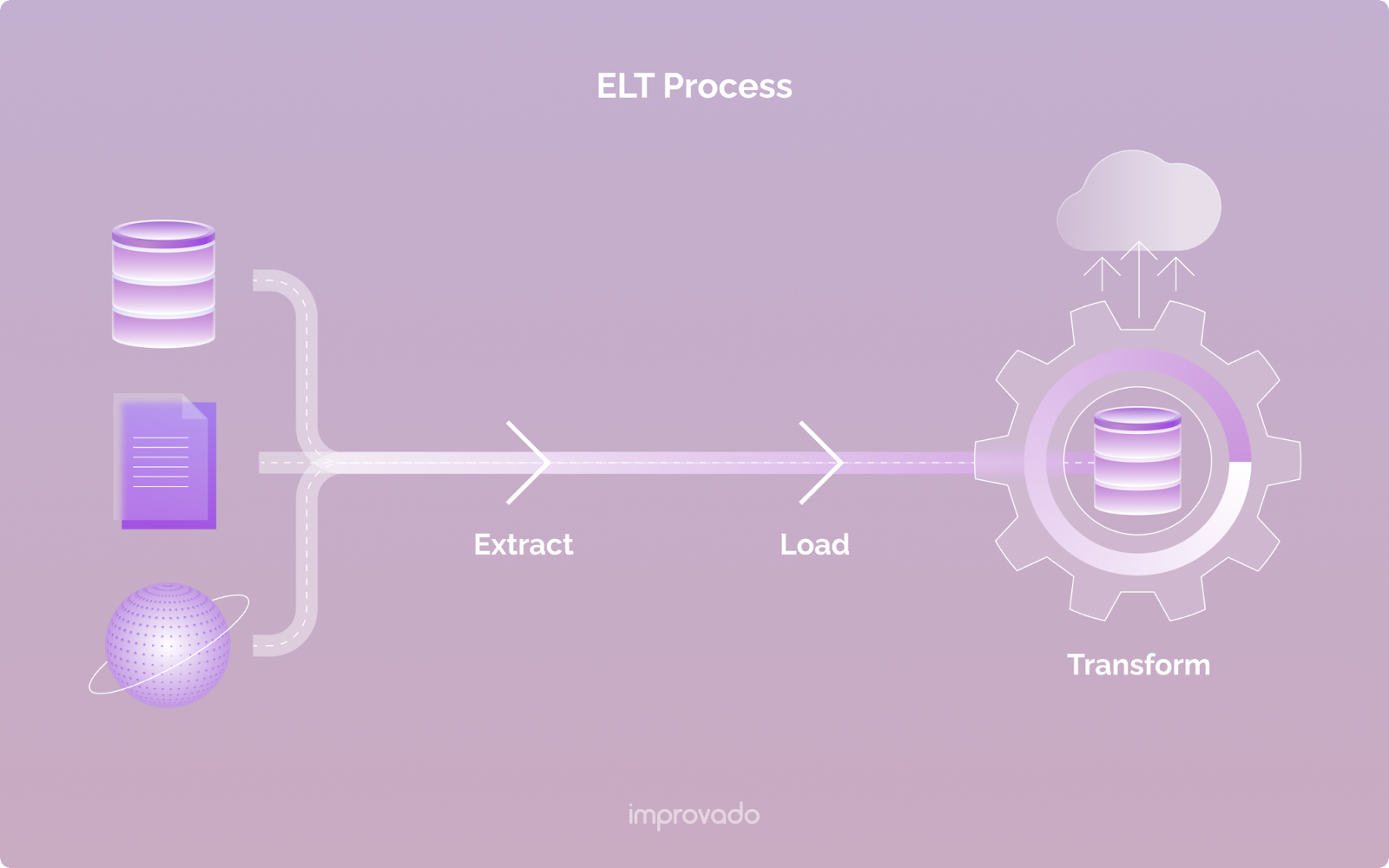
Hauptvorteile einer ELT-Pipeline
ELT hat aufgrund seiner Einfachheit und Flexibilität an Popularität gewonnen. Datenteams können Rohdaten aus einer Vielzahl von Quellen aggregieren, jederzeit für weitere Analysen darauf zugreifen und eine Transformationslogik entwickeln, wenn sie wirklich benötigt wird.
ELT ist eine fantastische Wahl für Echtzeit-Datenanalysen, da es Daten schneller als ETL laden und transformieren kann. ELT ist auch eine bessere Wahl, wenn Ihr Unternehmen komplexe oder sich ständig ändernde Transformationsprozesse betreibt.
Darüber hinaus ist ELT einfacher zu warten als ETL, da keine separate Transformationssoftware verwaltet werden muss. Und es bietet immer noch viele der gleichen Vorteile wie ETL, wie z. B. Datengenauigkeit und Effizienz.
ETL- und ELT-Prozesse im Vergleich
Nachdem wir uns die Vorteile von ETL und ELT angesehen haben, vergleichen wir die beiden Prozesse nebeneinander.

Geschwindigkeit
ELT ist aufgrund des Timings des Transformationsschritts schneller als ETL.
Angenommen, Sie laden einen Datensatz mit einer Größe von einem Terabyte. Bei ETL müsste der gesamte Datensatz auf den Transformationsserver geladen werden, bevor die Transformation beginnen könnte. Aber mit ELT können die Daten parallel geladen und transformiert werden, wodurch die Gesamtzeit, die zum Abschluss des Prozesses benötigt wird, erheblich reduziert wird.
Es gibt jedoch einige Fälle, in denen ETL schneller als ELT sein kann. Dies ist normalerweise der Fall, wenn der Datensatz klein ist und problemlos in eine eigenständige Instanz umgewandelt werden kann.
Aufbewahrung von Rohdaten
Der ELT-Prozess extrahiert alle Rohdaten und speichert sie unbegrenzt in Ihrem Data Warehouse. Transformationen werden später nur bei Bedarf angewendet – das heißt, Sie behalten immer den ursprünglichen Datensatz bei, was für historische Analysen und Debugging hilfreich ist.
Für ETL werden die Daten vor dem Laden von Daten in das Ziel-Data Warehouse oder die Datenbank Ihrer Wahl umfangreichen Transformationen unterzogen. Daher kann ETL Daten in eine aggregierte Form umwandeln, um Platz zu sparen, wodurch es schwierig wird, die ursprünglichen Werte zurückzuverfolgen, es sei denn, Sie laden sowohl ursprüngliche als auch transformierte Daten in ein Ziel. Wenn Sie die Ausgabedaten ändern möchten oder wenn sich die Rohdatenquelle ändert, müssen Sie die Extraktions-Transformations-Skripts neu schreiben (so wie sie als eins geliefert werden).
Skalierbarkeit
ELT ist flexibler, da alle drei Schritte (Extrahieren, Laden und Transformieren) separat ausgeführt werden. Das macht es einfacher, alles zu skalieren und zu ändern, was Sie im Prozess wollen.
Andererseits ist ETL starrer, da die Transformationsschicht eine inhärente Beschränkung hat. Es ist schwieriger, sich mit dem Wachstum Ihres Unternehmens weiterzuentwickeln – zum Beispiel, wenn Sie erweiterte Funktionen wie geplante Extraktionen, parallele Extraktionen, erweiterte Transformationslogik usw. hinzufügen möchten. Es erfordert auch mehr Ressourcen als das Optimieren von ELT, da Sie gleichzeitig beide Enden von ändern müssen der Prozess. Schließlich wirkt sich das, was der eine tut, auf den anderen aus.
Gleiches gilt für Qualitätssicherungsprozesse. Da bei ETL Extrahieren und Transformieren zusammenkommen, ist mehr Arbeit erforderlich, um QA-Prozesse einzurichten und das Produkt zu testen. Im Vergleich dazu ist die ELT-Logik, bei der Sie Ihre Daten zuerst extrahieren und laden und sie erst dann transformieren, viel einfacher zu testen.
Unstrukturierte Daten
ETL-Systeme sind nicht gut geeignet für den Umgang mit unstrukturierten Daten wie Protokolldateien, Social-Media-Daten und E-Mail-Nachrichten – sie sind darauf ausgelegt, mit strukturierten Daten zu arbeiten, die in Zeilen und Spalten organisiert sind. ETL kann an die Verarbeitung unstrukturierter Daten angepasst werden, jedoch nur mit einer fortschrittlichen Transformations-Engine.
Andererseits sind ELT-Systeme für den Umgang mit unstrukturierten Daten leicht verfügbar, da sie Daten effizienter laden und transformieren können.
Einhaltung gesetzlicher Vorschriften
Einige Branchen unterliegen Vorschriften, die eine bestimmte Datenverarbeitung erfordern. Beispielsweise ist die Gesundheitsbranche an HIPAA gebunden. Diese Compliance-Gesetzgebung legt fest, wie Unternehmen geschützte Gesundheitsinformationen (PHI) und elektronisch geschützte Gesundheitsinformationen (ePHI) sammeln, verwenden oder weitergeben können, um die Privatsphäre von Patienten zu schützen.
Ein Unternehmen kann ETL so konfigurieren, dass es diese regulatorischen Anforderungen erfüllt, da die Daten bereinigt und transformiert werden können, bevor sie in die Zieldatenbank geladen werden.
ELT wiederum ist anfälliger für Compliance-Verstöße. Das System lädt alle Daten, unabhängig von ihrer sensiblen Natur, und wird erst dann transformiert oder entfernt. Die Problemumgehung für diese Einschränkungen besteht darin, robuste Sicherheits- und Data-Governance-Maßnahmen zu gewährleisten.
Wartung
In ETL- und ELT-Systemen können die Wartungskosten hoch sein, treten jedoch in unterschiedlichen Phasen auf.
Mit ETL müssen Sie Skripte zum Extrahieren und Transformieren ständig aktualisieren, wenn sich die Rohdatenquellen im Laufe der Zeit ändern, was zu einem erhöhten Wartungsaufwand führen kann.
Bei ELT erfolgt der größte Teil der Wartung während des erstmaligen Ladens von Daten in den Speicher und beim Transformieren von Daten. Der First-Load-Datenspeicher kann schnell unüberschaubar werden, da er als Abladeplatz für eingehende Rohdaten fungiert. Regelmäßige Bereinigungen und Dokumentationsbemühungen werden eingerichtet, um die Last zu verwalten.
Darüber hinaus müssen Transformationspipelines jedes Mal neu entwickelt werden, wenn sich eine Rohdatenquelle ändert. Dies erfordert Wartungsarbeiten, gibt den Ingenieuren jedoch mehr Flexibilität, da keine Daten verloren gehen, wenn sich ein Transformationsskript nicht an die neue eingehende Datenstruktur anpasst.
Kosten
Wie jeder weiß, der an einem Softwareentwicklungsprojekt teilgenommen hat, können die Kosten schnell außer Kontrolle geraten. Und wenn es um Datenprojekte geht, können die Kosten für die Entwicklung einer robusten ETL-Lösung unerschwinglich sein, weshalb sich einige Unternehmen stattdessen für ELT entscheiden.
Mit ELT kann ein Großteil des Transformationsschritts von vorhandenen Tools wie dbt oder mit Hilfe von SQL durchgeführt werden, die beide tendenziell günstiger sind als herkömmliche ETL-Lösungen. Natürlich braucht es nach wie vor erfahrene Entwickler, die wissen, wie man diese Tools effektiv einsetzt. Aber insgesamt sind die Kosten für die Entwicklung einer ELT-Lösung wahrscheinlich deutlich niedriger als die Kosten für die Entwicklung einer ETL-Lösung von Grund auf neu.
Zum Vergleich: Das durchschnittliche Grundgehalt eines mittleren bis hochrangigen Backend-Ingenieurs in den USA beträgt 124.397 USD pro Jahr. Inzwischen liegt das durchschnittliche Gehalt eines SQL-Dateningenieurs oder BI-Entwicklers bei etwa 91.055 US-Dollar pro Jahr. Wenn Sie also mehrere Entwickler für die Arbeit an Ihrer Pipeline einstellen müssen, ist ELT kostengünstiger.
Es sollte anerkannt werden, dass die Speicherkosten in ETL niedriger sind, da es keine Rohdaten speichert, aber dieser Unterschied ist nicht signifikant, wenn Cloud-Speicher verwendet wird.
So entscheiden Sie sich zwischen ETL und ELT
Die Entscheidung zwischen ETL und ELT kann schwierig sein, da jeder Ansatz Vor- und Nachteile hat. Wir haben einige Fragen zusammengestellt, die Ihnen bei der Entscheidung helfen können.
Welche Art von Daten müssen Sie verarbeiten?
Sind Ihre Daten strukturiert oder unstrukturiert oder eine Mischung aus beidem? ETL eignet sich am besten für strukturierte Daten, während ELT sowohl strukturierte als auch unstrukturierte Daten verarbeiten kann.
Wie viel Wartung ist erforderlich?
Wiegen die Vorteile von ETL die Wartungskosten auf? Beispielsweise benötigen Sie möglicherweise Zugriff auf den Rohdatenverlauf, den ETL bereitstellt. In diesem Fall können die Vorteile von ETL die zusätzlichen Wartungskosten wert sein.
Wie komplex ist die Datenverarbeitungspipeline?
Die Ausgereiftheit Ihrer Datenverarbeitungspipeline bestimmt, ob ETL oder ELT die bessere Lösung ist. Beispielsweise kann ETL komplexe Transformationslogik ausführen, funktioniert aber am besten mit kleineren Datensätzen, während ELT ideal für große Datensätze ist, aber jede Datengröße verarbeiten kann.
Benötigen Sie Echtzeitdaten?
ETL verarbeitet Daten in Stapeln, was zu einer Verzögerung zwischen dem Sammeln der Daten und ihrer Verfügbarkeit in der Zieldatenbank führt. ELT kann Daten auch stapelweise verarbeiten, aber auch in Echtzeit, was hilfreich ist, wenn Sie aktuelle Daten benötigen.
Wie erfahren sind Ihre Entwickler?
Auf diese Frage gibt es keine allgemeingültige Antwort, da sie von den spezifischen Fähigkeiten und Erfahrungen Ihres Engineering-Teams abhängt. Im Allgemeinen sind mehr Ingenieure mit ETL-Ansätzen vertraut als mit ELT. Sobald Sie eine Datenpipeline eingerichtet haben, können BI/SQL-Ingenieure Änderungen im ELT-Prozess vornehmen, während ETL-Änderungen Mid-/Senior-Backend-Entwickler erfordern.
Ob ETL oder ELT, Improvado hat Sie abgedeckt
Unabhängig von Ihrem Ansatz kann Improvado Ihren Datenfluss mit seiner breiten Palette an Datenquellen-Konnektoren und -Zielen unterstützen. Das Team erfahrener Dateningenieure von Improvado kann Ihnen bei der Entwicklung und Implementierung einer Lösung behilflich sein, die speziell auf Ihre internen und externen Datenvorschriften und -anforderungen zugeschnitten ist.