
Как загрузить данные в BigQuery с помощью R и Python
Опубликовано: 2023-06-06Мир веб-аналитики продолжает стремительно приближаться к судьбоносной дате 1 июля, когда Universal Analytics прекращает обработку данных и заменяется Google Analytics 4 (GA4). Одно из ключевых изменений заключается в том, что в GA4 вы можете хранить данные на платформе не более 14 месяцев. Это серьезное отличие от UA, но в обмен на это вы можете бесплатно передавать данные GA4 в BigQuery до определенного предела.
BigQuery — чрезвычайно полезный ресурс для хранения данных за пределами GA4. Поскольку через несколько месяцев он станет более важным, чем когда-либо, сейчас самое подходящее время, чтобы начать использовать его для всех ваших потребностей в хранении данных. Часто бывает предпочтительнее каким-либо образом манипулировать данными перед загрузкой. Для этого мы рекомендуем использовать скрипт, написанный либо на R, либо на Python, особенно если такого рода манипуляции необходимо выполнять неоднократно. Вы также можете загружать данные в BigQuery прямо из этих скриптов, и этот блог поможет вам в этом.
Загрузка в BigQuery из R
R — чрезвычайно мощный язык для обработки данных, и с ним проще всего работать для загрузки данных в BigQuery. Первый шаг — импорт всех необходимых библиотек. Для этого урока нам понадобятся следующие библиотеки:
library(googleAuthR)
library(bigQueryR)
Если вы еще не использовали эти библиотеки, запустите install.packages(<PACKAGE NAME>) в консоли, чтобы установить их.
Затем мы должны заняться тем, что часто является самой сложной и неизменно самой разочаровывающей частью работы с API — авторизацией. К счастью, с R это относительно просто. Вам понадобится файл JSON, содержащий учетные данные для авторизации. Это можно найти в Google Cloud Console, там же, где находится BigQuery. Сначала перейдите в Google Cloud Console и нажмите «API и службы».
Затем нажмите «Учетные данные» на боковой панели.

На странице учетных данных вы можете просмотреть существующие ключи API, идентификаторы клиентов OAuth 2.0 и учетные записи служб. Для этого вам понадобится идентификатор клиента OAuth 2.0, поэтому либо нажмите кнопку загрузки в самом конце соответствующей строки для вашего идентификатора, либо создайте новый идентификатор, нажав «Создать учетные данные» в верхней части страницы. Убедитесь, что у вашего идентификатора есть разрешение на просмотр и редактирование соответствующего проекта BigQuery. Для этого откройте боковую панель, наведите указатель мыши на «IAM и администратор» и нажмите «IAM». На этой странице вы можете предоставить своему сервисному аккаунту доступ к соответствующему проекту, нажав кнопку «Предоставить доступ» в верхней части страницы.
Получив и сохранив файл JSON, вы можете передать путь к нему с помощью функции gar_set_client(), чтобы установить свои учетные данные. Полный код для авторизации ниже:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Очевидно, вы захотите заменить путь в функции gar_set_client() на путь к вашему собственному JSON-файлу и вставить адрес электронной почты, который вы используете для доступа к BigQuery, в функцию bqr_auth().
После того, как авторизация настроена, нам нужны некоторые данные для загрузки в BigQuery. Нам нужно будет поместить эти данные в фрейм данных. Для целей этой статьи я собираюсь создать некоторые вымышленные данные с количеством местоположений и количеством продаж, но, скорее всего, вы будете считывать реальные данные из файла .csv или электронной таблицы. Чтобы прочитать данные из файла .csv, вы можете просто использовать функцию read.csv(), передав в качестве аргумента путь к файлу:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
В качестве альтернативы, если ваши данные хранятся в электронной таблице, ваш метод будет зависеть от того, где находится эта таблица. Если ваша электронная таблица хранится в Google Sheets, вы можете прочитать ее данные в R с помощью библиотеки googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Как и прежде, если вы раньше не использовали этот пакет, вам нужно будет запустить install.packages("googlesheets4") в консоли перед запуском кода.
Если ваша электронная таблица находится в Excel, вам нужно будет использовать библиотеку readxl, которая является частью библиотеки tidyverse, которую я рекомендую использовать. Он содержит огромное количество функций, которые значительно упрощают работу с данными в R:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
И еще раз, обязательно запустите install.package("tidyverse"), если вы еще этого не сделали!
Последний шаг — загрузить данные в BigQuery. Для этого вам понадобится место в BigQuery для его загрузки. Ваша таблица будет находиться в наборе данных, который будет расположен в проекте, и вам понадобятся имена всех трех из них в следующем формате:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
В моем случае это означает, что мой код гласит:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
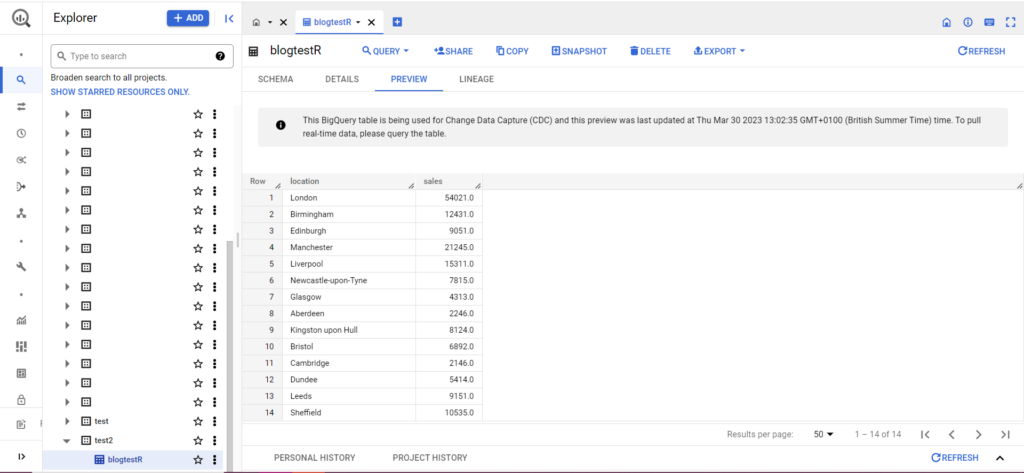
Если вашей таблицы еще нет, не волнуйтесь, код создаст ее за вас. Не забудьте вставить названия вашего проекта, набора данных и таблицы в приведенный выше код (в кавычках) и убедитесь, что вы загружаете правильный фрейм данных! Как только это будет сделано, вы должны увидеть свои данные в BigQuery, как показано ниже:

В качестве последнего шага предположим, что у вас есть дополнительные данные, которые вы хотели бы добавить в BigQuery. Например, в моих данных выше, скажем, я забыл включить пару местоположений с континента, и я хочу загрузить их в BigQuery, но я не хочу перезаписывать существующие данные. Для этого в bqr_upload_data есть параметр writeDisposition. writeDisposition имеет две настройки: «WRITE_TRUNCATE» и «WRITE_APPEND». Первый приказывает bqr_upload_data() перезаписать существующие данные в таблице, а второй — добавлять новые данные. Таким образом, чтобы загрузить эти новые данные, я напишу:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
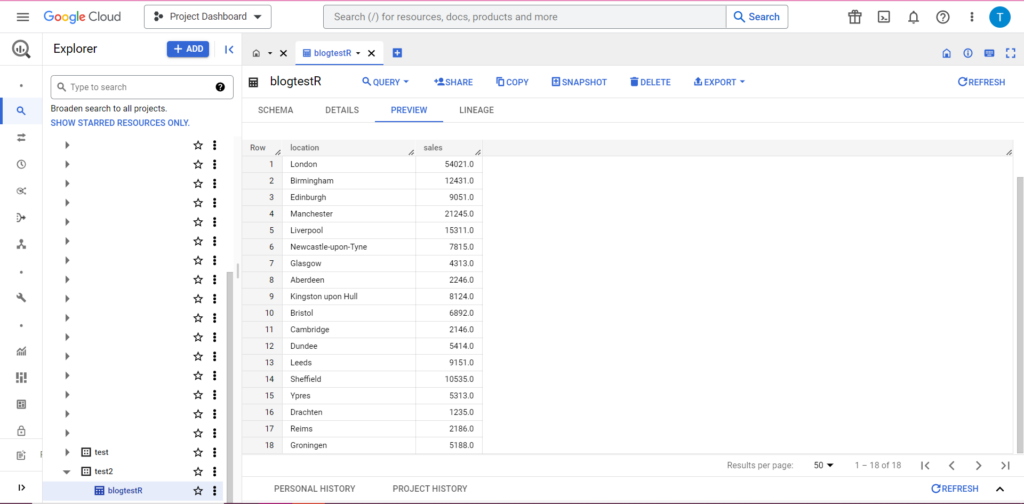
И, конечно же, в BigQuery мы видим, что у наших данных есть несколько новых соседей по комнате:
Загрузка в BigQuery из Python
В Python все немного иначе. Еще раз, нам нужно будет импортировать некоторые пакеты, так что давайте начнем с них:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
Авторизация сложная. Еще раз нам понадобится файл JSON, содержащий учетные данные. Как и выше, мы перейдем к Google Cloud Console и нажмем «API и службы», затем нажмите «Учетные данные» на боковой панели. На этот раз внизу страницы будет раздел «Сервисные аккаунты».
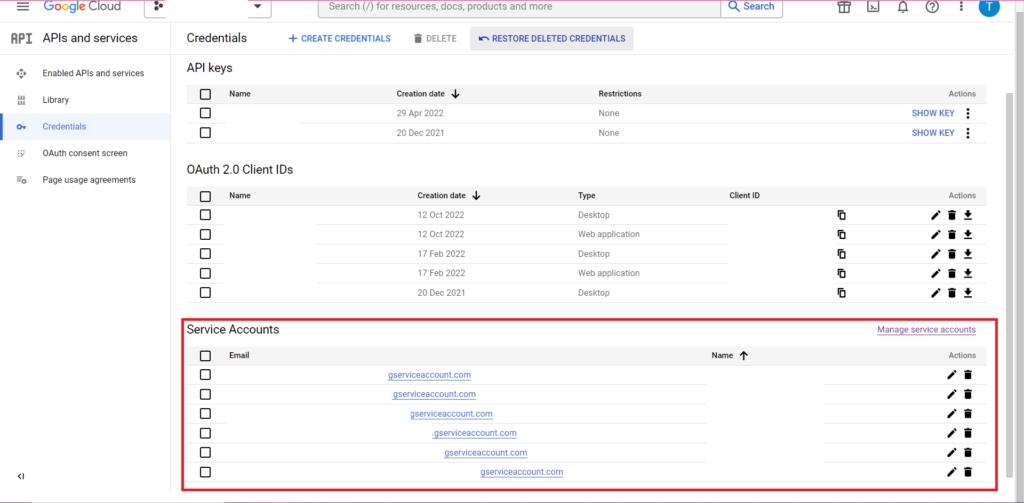
Там вы можете либо загрузить ключ в свою учетную запись службы, либо, нажав «Управление учетной записью службы», вы можете создать новый ключ или новую учетную запись службы, для которой вы можете загрузить учетные данные.
Затем вам нужно будет убедиться, что у вашего сервисного аккаунта есть разрешение на доступ и редактирование вашего проекта BigQuery. Еще раз перейдите на страницу IAM в разделе «IAM и администратор» на боковой панели, и там вы можете предоставить доступ своей учетной записи службы к соответствующему проекту, используя кнопку «Предоставить доступ» в верхней части страницы.
Как только вы разберетесь с этим, вы можете написать код авторизации:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
Затем вам нужно будет поместить свои данные в фреймворк данных. Фреймы данных принадлежат пакету pandas, и их очень просто создать. Чтобы прочитать из CSV, следуйте этому примеру:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Очевидно, вам нужно будет заменить указанный выше путь на путь к вашему собственному CSV-файлу. Чтобы прочитать из файла Excel, следуйте этому примеру:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Чтение из Google Sheets сложно и требует еще одного раунда авторизации. Нам нужно будет импортировать несколько новых пакетов и использовать файл учетных данных JSON, который мы получили во время обучения R выше. Вы можете использовать этот код для авторизации и чтения ваших данных:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
Когда у вас есть данные в фрейме данных, пришло время снова загрузить их в BigQuery! Вы можете сделать это, следуя этому шаблону:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Например, вот код, который я только что написал для загрузки данных, которые я сделал ранее:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
Как только это будет сделано, данные должны сразу появиться в BigQuery!
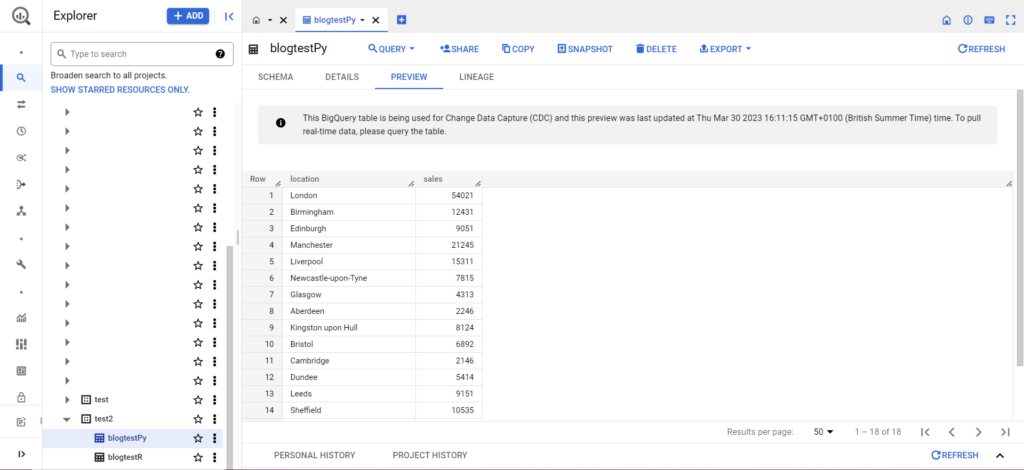
После того, как вы освоите их, вы сможете делать гораздо больше с помощью этих функций. Если вы хотите получить больший контроль над настройками аналитики, Semetrical здесь, чтобы помочь! Посетите наш блог для получения дополнительной информации о том, как получить максимальную отдачу от ваших данных. Или, чтобы получить дополнительную поддержку по всем аспектам аналитики, перейдите на веб-аналитику, чтобы узнать, как мы можем вам помочь.