
Cum să încărcați date în BigQuery cu R și Python
Publicat: 2023-06-06Lumea analizei web continuă să se precipite spre data fatidică de 1 iulie, când Universal Analytics oprește procesarea datelor și este înlocuită de Google Analytics 4 (GA4). Una dintre schimbările cheie este că, în GA4, puteți păstra datele în platformă doar pentru maximum 14 luni. Aceasta este o schimbare majoră față de UA, dar în schimbul acesteia, puteți introduce gratuit datele GA4 în BigQuery, până la o limită.
BigQuery este o resursă extrem de utilă pentru stocarea datelor dincolo de GA4. Deoarece acesta devine mai important ca niciodată în câteva luni, este un moment la fel de bun ca niciodată să începeți să îl utilizați pentru toate nevoile dvs. de stocare a datelor. Adesea, va fi de preferat să manipulați datele într-un fel înainte de încărcare. Pentru aceasta, vă recomandăm să utilizați un script scris fie în R sau Python, mai ales dacă acest tip de manipulare trebuie făcut în mod repetat. Puteți, de asemenea, să încărcați date în BigQuery direct din aceste scripturi și exact asta vă va ghida acest blog.
Se încarcă în BigQuery din R
R este un limbaj extrem de puternic pentru știința datelor și cel mai ușor de lucrat pentru a încărca date în BigQuery. Primul pas este să importați toate bibliotecile necesare. Pentru acest tutorial, vom avea nevoie de următoarele biblioteci:
library(googleAuthR)
library(bigQueryR)
Dacă nu ați folosit aceste biblioteci înainte, rulați install.packages(<PACKAGE NAME>) în consolă pentru a le instala.
În continuare, trebuie să abordăm ceea ce este adesea cea mai dificilă și în mod constant cea mai frustrantă parte a lucrului cu API-urile - autorizarea. Din fericire, cu R, acest lucru este relativ simplu. Veți avea nevoie de un fișier JSON care să conțină acreditările de autorizare. Acesta poate fi găsit în Google Cloud Console, același loc în care se află BigQuery. Mai întâi, navigați la Google Cloud Console și faceți clic pe „API-uri și servicii”.
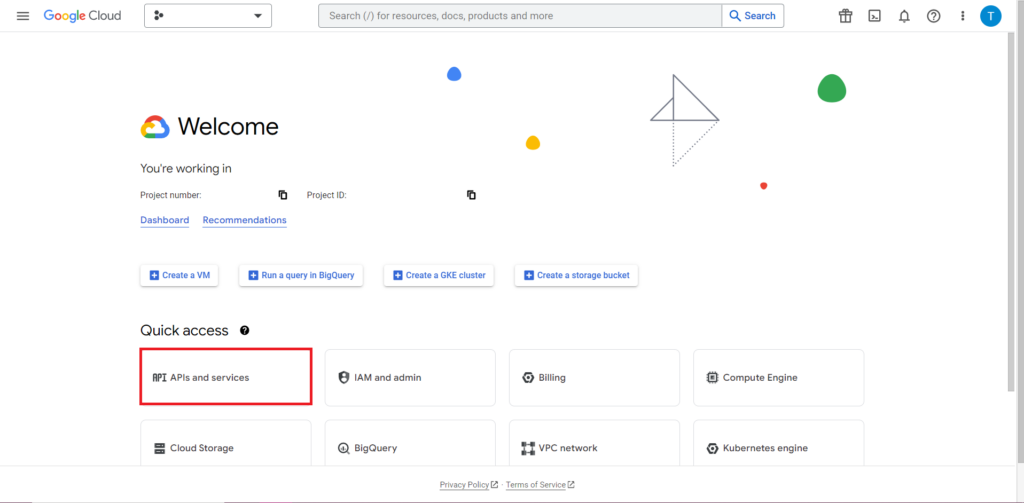
Apoi, faceți clic pe „Acreditări” în bara laterală.

Pe pagina Acreditări, puteți vedea cheile API existente, ID-urile de client OAuth 2.0 și Conturile de serviciu. Veți dori un ID de client OAuth 2.0 pentru aceasta, așa că fie apăsați butonul de descărcare de la sfârșitul rândului relevant pentru ID-ul dvs., fie creați un nou ID făcând clic pe „Creați acreditări” în partea de sus a paginii. Asigurați-vă că ID-ul dvs. are permisiunea de a vedea și edita proiectul BigQuery relevant – pentru a face acest lucru, deschideți bara laterală, plasați cursorul peste „IAM și administrator” și faceți clic pe „IAM”. Pe această pagină, puteți acorda acces contului dvs. de serviciu la proiectul relevant utilizând butonul „Acordați acces” din partea de sus a paginii.
Cu fișierul JSON obținut și salvat, puteți trece calea către acesta cu funcția gar_set_client() pentru a vă seta acreditările. Codul complet pentru autorizare este mai jos:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
Evident, veți dori să înlocuiți calea din funcția gar_set_client() cu calea către propriul fișier JSON și să introduceți adresa de e-mail pe care o utilizați pentru a accesa BigQuery în funcția bqr_auth().
Odată ce autorizarea este configurată, avem nevoie de câteva date pentru a le încărca în BigQuery. Va trebui să punem aceste date într-un cadru de date. În scopul acestui articol, voi crea câteva date fictive cu un număr de locații și număr de vânzări, dar cel mai probabil, veți citi date reale dintr-un fișier .csv sau dintr-o foaie de calcul. Pentru a citi date dintr-un fișier .csv, puteți utiliza pur și simplu funcția read.csv(), trecând ca argument calea către fișier:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
Alternativ, dacă aveți datele stocate într-o foaie de calcul, metoda dvs. va varia în funcție de locul în care se află această foaie de calcul. Dacă foaia de calcul este stocată în Foi de calcul Google, puteți citi datele acesteia în R folosind biblioteca googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
Ca și înainte, dacă nu ați folosit acest pachet înainte, va trebui să rulați install.packages(„googlesheets4”) în consolă înainte de a rula codul.
Dacă foaia de calcul este în Excel, va trebui să utilizați biblioteca readxl, care face parte din biblioteca tidyverse - ceva ce recomand să utilizați. Conține un număr mare de funcții care fac manipularea datelor în R atât de ușoară:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
Și încă o dată, asigurați-vă că rulați install.package(„tidyverse”) dacă nu ați făcut-o înainte!
Ultimul pas este să încărcați datele în BigQuery. Pentru aceasta, veți avea nevoie de un loc în BigQuery pentru a-l încărca. Tabelul dvs. va fi localizat într-un set de date, care va fi localizat într-un proiect și veți avea nevoie de numele tuturor celor trei în următorul format:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
În cazul meu, asta înseamnă că codul meu citește:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
Dacă tabelul tău nu există încă, nu-ți face griji, codul îl va crea pentru tine. Nu uitați să introduceți numele proiectului, setul de date și tabelul dvs. în codul de mai sus (între ghilimele) și asigurați-vă că încărcați cadrul de date corect! După ce ați făcut acest lucru, ar trebui să vedeți datele dvs. în BigQuery, după cum urmează:

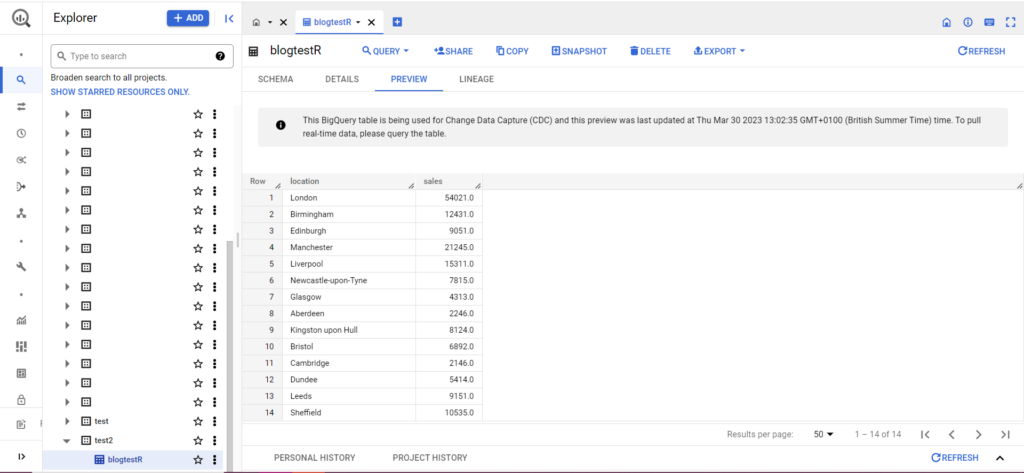
Ca pas final, să presupunem că aveți date suplimentare pe care doriți să le adăugați la BigQuery. De exemplu, în datele mele de mai sus, să spunem că am uitat să includ câteva locații de pe continent și vreau să încarc în BigQuery, dar nu vreau să suprascriu datele existente. Pentru aceasta, bqr_upload_data are un parametru numit writeDisposition. writeDisposition are două setări, „WRITE_TRUNCATE” și „WRITE_APPEND”. Primul îi spune bqr_upload_data() să suprascrie datele existente în tabel, în timp ce cel din urmă îi spune să adauge noile date. Astfel, pentru a încărca aceste date noi, voi scrie:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
Și, desigur, în BigQuery putem vedea că datele noastre au niște colegi de cameră noi:
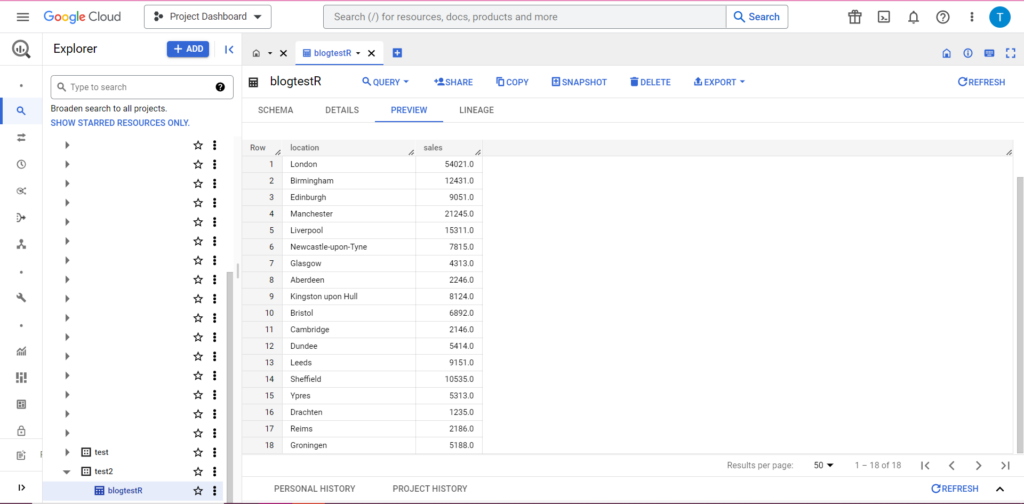
Se încarcă în BigQuery din Python
În Python, lucrurile stau puțin diferit. Încă o dată, va trebui să importăm câteva pachete, așa că să începem cu acestea:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
Autorizarea este complicată. Încă o dată vom avea nevoie de un fișier JSON care să conțină acreditări. Ca mai sus, vom naviga la Google Cloud Console și vom face clic pe „API-uri și servicii”, apoi pe „Acreditări” în bara laterală. De data aceasta, în partea de jos a paginii, va apărea o secțiune numită „Conturi de servicii”.
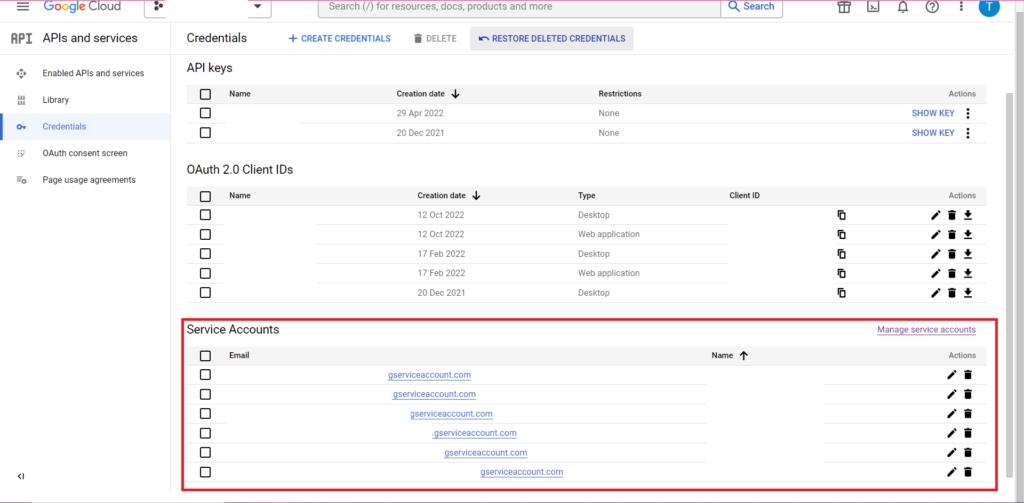
Acolo puteți fie descărca cheia în contul dvs. de serviciu, fie făcând clic pe „Gestionați contul de serviciu” puteți crea o cheie nouă sau un cont de serviciu nou pentru care puteți descărca acreditările.
Apoi, veți dori să vă asigurați că contul dvs. de serviciu are permisiunea de a accesa și edita proiectul dvs. BigQuery. Încă o dată, navigați la pagina IAM sub „IAM & Admin” din bara laterală și acolo puteți acorda acces la contul de serviciu la proiectul relevant utilizând butonul „Acordați acces” din partea de sus a paginii.
De îndată ce ați rezolvat, puteți scrie codul de autorizare:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
În continuare, va trebui să introduceți datele într-un cadru de date. Cadrele de date aparțin pachetului panda și sunt foarte ușor de creat. Pentru a citi dintr-un CSV, urmați acest exemplu:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
Evident, va trebui să înlocuiți calea de mai sus cu aceea către propriul fișier CSV. Pentru a citi dintr-un fișier Excel, urmați acest exemplu:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
Citirea din Foi de calcul Google este dificilă și necesită o altă rundă de autorizare. Va trebui să importăm câteva pachete noi și să folosim fișierul de acreditări JSON pe care l-am preluat în timpul tutorialului R de mai sus. Puteți urma acest cod pentru a vă autoriza și citi datele:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
După ce aveți datele în cadrul de date, este timpul să încărcați din nou în BigQuery! Puteți face acest lucru urmând acest șablon:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
De exemplu, iată codul pe care tocmai l-am scris pentru a încărca datele pe care le-am făcut mai devreme:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
După ce se face acest lucru, datele ar trebui să apară imediat în BigQuery!
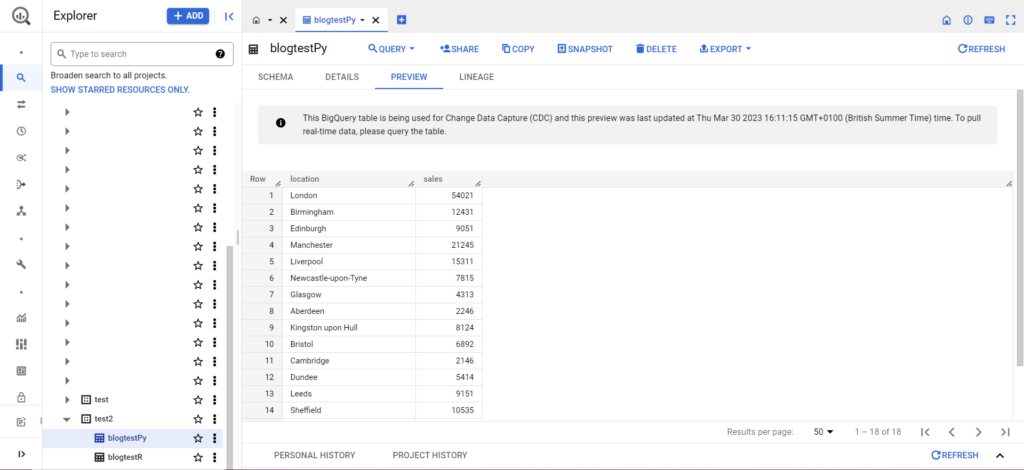
Există multe lucruri pe care le puteți face cu aceste funcții odată ce le-ați înțeles. Dacă doriți să preluați un control mai mare asupra configurației dvs. de analiză, Semetrical este aici pentru a vă ajuta! Consultați blogul nostru pentru mai multe informații despre cum să profitați la maximum de datele dvs. Sau, pentru mai multă asistență cu privire la toate lucrurile de analiză, accesați Web Analytics pentru a afla cum vă putem ajuta.