
كيفية تحميل البيانات إلى BigQuery باستخدام R و Python
نشرت: 2023-06-06يستمر عالم تحليلات الويب في الاندفاع نحو التاريخ المشؤوم الأول من يوليو عندما يتوقف Universal Analytics عن معالجة البيانات ويتم استبداله بـ Google Analytics 4 (GA4). أحد التغييرات الرئيسية هو أنه في GA4 ، يمكنك فقط الاحتفاظ بالبيانات في النظام الأساسي لمدة أقصاها 14 شهرًا. يعد هذا تغييرًا كبيرًا عن UA ، ولكن في مقابل ذلك ، يمكنك دفع بيانات GA4 إلى BigQuery مجانًا ، إلى حد أقصى.
BigQuery هو مورد مفيد للغاية لتخزين البيانات خارج GA4. نظرًا لأنه أصبح أكثر أهمية من أي وقت مضى في غضون بضعة أشهر ، فقد حان الوقت لبدء استخدامه لجميع احتياجات تخزين البيانات الخاصة بك. في كثير من الأحيان ، سيكون من الأفضل معالجة البيانات بطريقة ما قبل التحميل. لهذا ، نوصي باستخدام نص مكتوب إما بلغة R أو Python ، خاصةً إذا كان هذا النوع من التلاعب يحتاج إلى تكرار. يمكنك أيضًا تحميل البيانات إلى BigQuery مباشرةً من هذه النصوص البرمجية ، وهذا بالضبط ما ستوجهك هذه المدونة إليه.
تحميل إلى BigQuery من R.
تُعد R لغة قوية للغاية لعلوم البيانات وهي الأسهل في التعامل معها لتحميل البيانات إلى BigQuery. الخطوة الأولى هي استيراد جميع المكتبات الضرورية. في هذا البرنامج التعليمي ، سنحتاج إلى المكتبات التالية:
library(googleAuthR)
library(bigQueryR)
إذا لم تكن قد استخدمت هذه المكتبات من قبل ، فقم بتشغيل install.packages(<PACKAGE NAME>) في وحدة التحكم لتثبيتها.
بعد ذلك ، يجب أن نتعامل مع الجزء الأكثر تعقيدًا والأكثر إحباطًا في العمل مع واجهات برمجة التطبيقات - التفويض. لحسن الحظ ، مع R ، هذا بسيط نسبيًا. ستحتاج إلى ملف JSON يحتوي على بيانات اعتماد التفويض. يمكن العثور على هذا في Google Cloud Console ، وهو نفس المكان الذي يوجد فيه BigQuery. أولاً ، انتقل إلى Google Cloud Console ، وانقر فوق 'APIs and Services'.
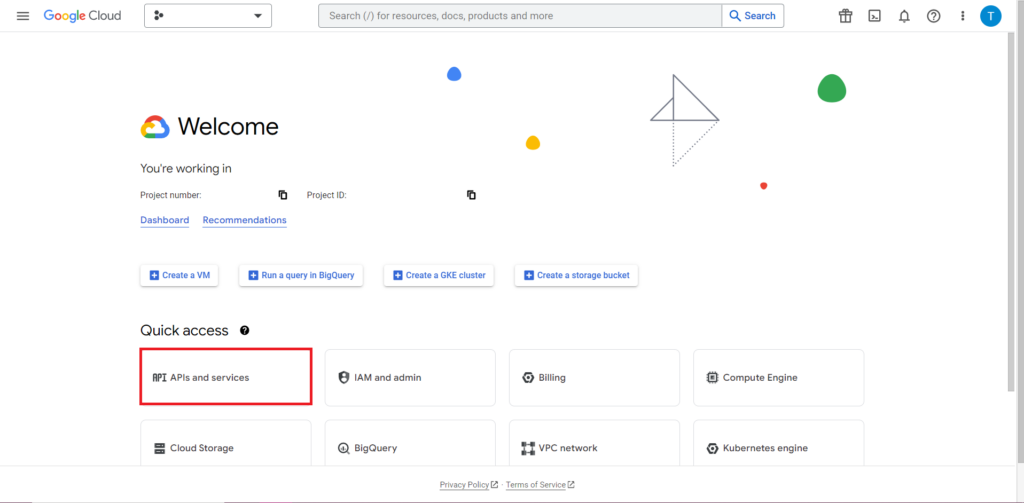
بعد ذلك ، انقر فوق "بيانات الاعتماد" في الشريط الجانبي.

في صفحة بيانات الاعتماد ، يمكنك عرض مفاتيح واجهة برمجة التطبيقات الحالية ومعرفات عميل OAuth 2.0 وحسابات الخدمة. ستحتاج إلى معرف عميل OAuth 2.0 لهذا ، لذلك إما أن تضغط على زر التنزيل في نهاية الصف ذي الصلة لمعرفك ، أو أنشئ معرفًا جديدًا بالنقر فوق "إنشاء بيانات اعتماد" في أعلى الصفحة. تأكد من أن المعرّف الخاص بك لديه الإذن لعرض وتعديل مشروع BigQuery ذي الصلة - للقيام بذلك ، افتح الشريط الجانبي ، وقم بالمرور فوق "IAM and Admin" وانقر على "IAM". في هذه الصفحة ، يمكنك منح حساب الخدمة الخاص بك حق الوصول إلى المشروع ذي الصلة باستخدام زر "منح الوصول" في أعلى الصفحة.
مع الحصول على ملف JSON وحفظه ، يمكنك تمرير المسار إليه باستخدام وظيفة gar_set_client () لتعيين بيانات الاعتماد الخاصة بك. الكود الكامل للتفويض أدناه:
googleAuthR::gar_cache_empty()
googleAuthR::gar_set_client("C:\\Users\\Tom Brown\\Documents\\R\\APIs\\credentials.json")
bqr_auth(email = "<your email here>")
من الواضح أنك سترغب في استبدال المسار في وظيفة gar_set_client () بالمسار إلى ملف JSON الخاص بك ، وإدخال عنوان البريد الإلكتروني الذي تستخدمه للوصول إلى BigQuery في دالة bqr_auth ().
بمجرد أن يتم إعداد التفويض بالكامل ، نحتاج إلى بعض البيانات لتحميلها على BigQuery. سنحتاج إلى وضع هذه البيانات في إطار بيانات. لأغراض هذه المقالة ، سأقوم بإنشاء بعض البيانات الخيالية مع عدد من المواقع وحسابات المبيعات ، ولكن على الأرجح ، ستقرأ بيانات حقيقية من ملف .csv أو جدول بيانات. لقراءة البيانات من ملف .csv ، يمكنك ببساطة استخدام الوظيفة read.csv () ، لتمرير المسار إلى الملف كوسيطة:
data <- read.csv("C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv")
بدلاً من ذلك ، إذا كانت بياناتك مخزنة في جدول بيانات ، فستختلف طريقتك بناءً على مكان وجود جدول البيانات هذا. إذا تم تخزين جدول البيانات في جداول بيانات Google ، فيمكنك قراءة بياناته إلى R باستخدام مكتبة googlesheets4:
library(googlesheets4)
data <- read_sheet(ss=”<spreadsheet URL>”, sheet=”<name of tab>”)
كما في السابق ، إذا لم تكن قد استخدمت هذه الحزمة من قبل ، فسيتعين عليك تشغيل install.packages ("googlesheets4") في وحدة التحكم قبل تشغيل التعليمات البرمجية الخاصة بك.
إذا كان جدول البيانات الخاص بك في Excel ، فستحتاج إلى استخدام مكتبة readxl ، وهي جزء من مكتبة المد والجزر - وهو أمر أوصي باستخدامه. يحتوي على عدد كبير من الوظائف التي تجعل معالجة البيانات في R أسهل بكثير:
library(tidyverse)
data <- read_excel(“C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx”)
ومرة أخرى ، تأكد من تشغيل install.package ("tidyverse") إذا لم تكن قد قمت بذلك من قبل!
الخطوة الأخيرة هي تحميل البيانات إلى BigQuery. لهذا ، ستحتاج إلى مكان في BigQuery لتحميله. سيكون جدولك موجودًا ضمن مجموعة بيانات ، والتي ستكون موجودة داخل مشروع ، وستحتاج إلى أسماء الثلاثة جميعها بالتنسيق التالي:
bqr_upload_data(“<your project>”, “<your dataset>”, “<your table>”, <your dataframe>)
في حالتي ، هذا يعني أن الكود الخاص بي يقرأ:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data)
إذا لم يكن جدولك موجودًا بعد ، فلا داعي للقلق ، فسيقوم الكود بإنشائه لك. لا تنسَ إدخال أسماء مشروعك ومجموعة البيانات والجدول في الكود أعلاه (ضمن علامات الاقتباس) وتأكد من تحميل إطار البيانات الصحيح! بمجرد الانتهاء من ذلك ، من المفترض أن ترى بياناتك في BigQuery ، على النحو التالي:
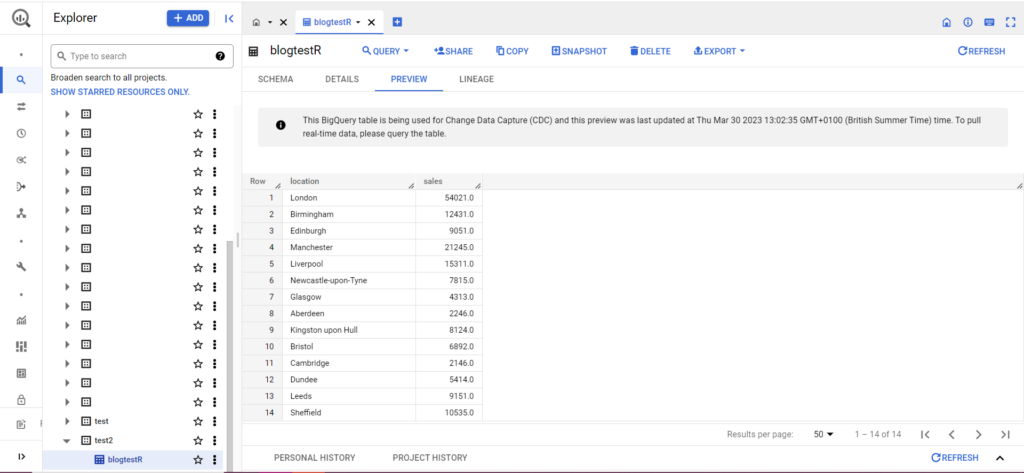

كخطوة أخيرة ، لنفترض أن لديك بيانات إضافية ترغب في إضافتها إلى BigQuery. على سبيل المثال ، في بياناتي أعلاه ، لنفترض أنني نسيت تضمين موقعين من القارة ، وأريد التحميل إلى BigQuery ، لكنني لا أريد استبدال البيانات الحالية. لهذا ، يحتوي bqr_upload_data على معلمة تسمى writeDisposition. يحتوي writeDisposition على إعدادين ، "WRITE_TRUNCATE" و "WRITE_APPEND". الأول يخبر bqr_upload_data () بالكتابة فوق البيانات الموجودة في الجدول ، بينما يخبرها الأخير بإلحاق البيانات الجديدة. وبالتالي ، لتحميل هذه البيانات الجديدة ، سأكتب:
bqr_upload_data(“my-project”, “test2”, “blogtestR”, data2, writeDisposition = “WRITE_APPEND”))
وبالتأكيد ، يمكننا أن نرى في BigQuery أن بياناتنا بها بعض رفقاء الغرفة الجدد:
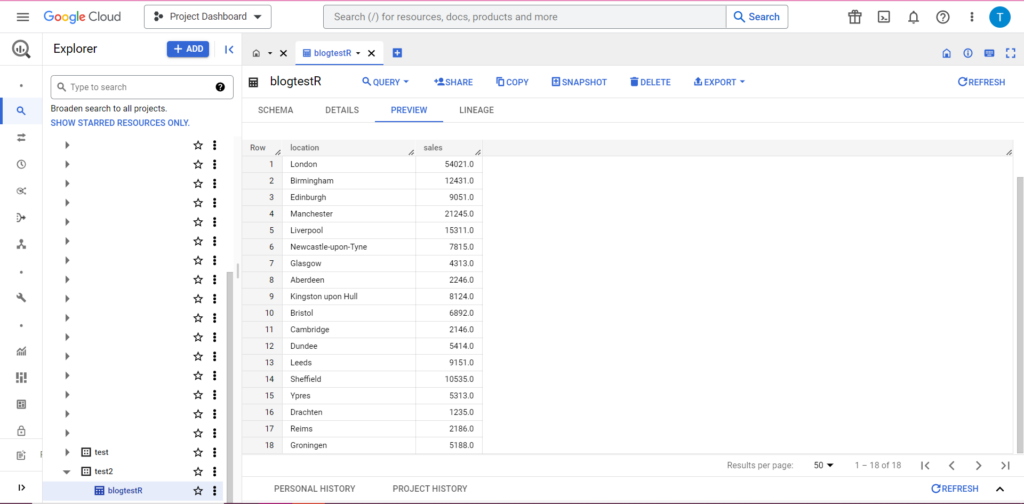
تحميل إلى BigQuery من Python
في بايثون ، تختلف الأمور قليلاً. مرة أخرى ، سنحتاج إلى استيراد بعض الحزم ، فلنبدأ بهذه:
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
التفويض معقد. مرة أخرى ، سنحتاج إلى ملف JSON يحتوي على بيانات الاعتماد. كما هو مذكور أعلاه ، سننتقل إلى Google Cloud Console وننقر على 'APIs and Services' ، ثم نضغط على 'Credentials' في الشريط الجانبي. هذه المرة ، في أسفل الصفحة ، سيكون هناك قسم يسمى "حسابات الخدمة".
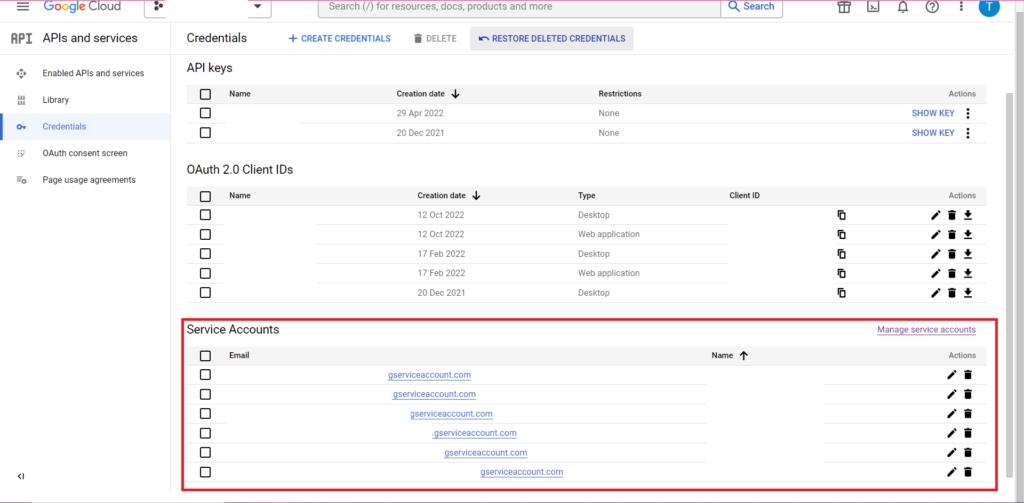
هناك يمكنك إما تنزيل المفتاح إلى حساب الخدمة الخاص بك ، أو بالنقر فوق "إدارة حساب الخدمة" يمكنك إنشاء مفتاح جديد أو حساب خدمة جديد يمكنك تنزيل بيانات الاعتماد من أجله.
ستحتاج بعد ذلك إلى التأكد من أن حساب الخدمة الخاص بك لديه الإذن للوصول إلى مشروع BigQuery وتعديله. مرة أخرى ، انتقل إلى صفحة IAM ضمن "IAM & Admin" في الشريط الجانبي ، وهناك يمكنك منح حساب الخدمة الخاص بك حق الوصول إلى المشروع ذي الصلة باستخدام زر "منح الوصول" في أعلى الصفحة.
بمجرد الانتهاء من ذلك ، يمكنك كتابة رمز التفويض:
bqcreds = service_account.Credentials.from_service_account_file('myjson.json', scopes = ['https://www.googleapis.com/auth/cloud-platform'])
client = bigquery.Client(credentials=bqcreds, project=bqcreds.project_id,)
بعد ذلك ، سيتعين عليك نقل بياناتك إلى إطار بيانات. تنتمي إطارات البيانات إلى حزمة الباندا ، وهي سهلة الإنشاء للغاية. للقراءة من ملف CSV ، اتبع هذا المثال:
data = pd.read_csv('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\mycsv.csv')
من الواضح أنك ستحتاج إلى استبدال المسار أعلاه بملف CSV الخاص بك. للقراءة من ملف Excel ، اتبع هذا المثال:
data = pd.read_excel('C:\\Users\\Tom Brown\\Documents\\Semetrical\\Blogs\\myxl.xlsx', sheet_name='mytab'>
القراءة من "جداول بيانات Google" صعبة وتتطلب جولة أخرى من التفويض. سنحتاج إلى استيراد بعض الحزم الجديدة ، واستخدام ملف بيانات اعتماد JSON الذي استردناه أثناء البرنامج التعليمي R أعلاه. يمكنك اتباع هذا الرمز لتفويض وقراءة بياناتك:
import gspread
from oauth2client.service_account import ServiceAccountCredentials
credentials = ServiceAccountCredentials.from_json_keyfile_name('myjson.json', scopes = ['https://spreadsheets.google.com/feeds'])
gc = gspead.authorize(credentials)
ss = gc.open_by_key('<spreadsheet key>')
sheet = ss.worksheet('<name of tab>')
data = pd.DataFrame(sheet.get_all_records())
بمجرد حصولك على بياناتك في dataframe ، حان الوقت للتحميل إلى BigQuery مرة أخرى! يمكنك القيام بذلك باتباع هذا النموذج:
table_id = “<your project>.<your dataset>.<your table>”
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
على سبيل المثال ، هذا هو الرمز الذي كتبته للتو لتحميل البيانات التي قدمتها سابقًا:
table_
job_config0 = bigquery.LoadJobConfig(write_disposition = 'WRITE_TRUNCATE')
job = client.load_table_from_dataframe(data, table_id, job_config=job_config0)
job.result()
بمجرد الانتهاء من ذلك ، من المفترض أن تظهر البيانات على الفور في BigQuery!
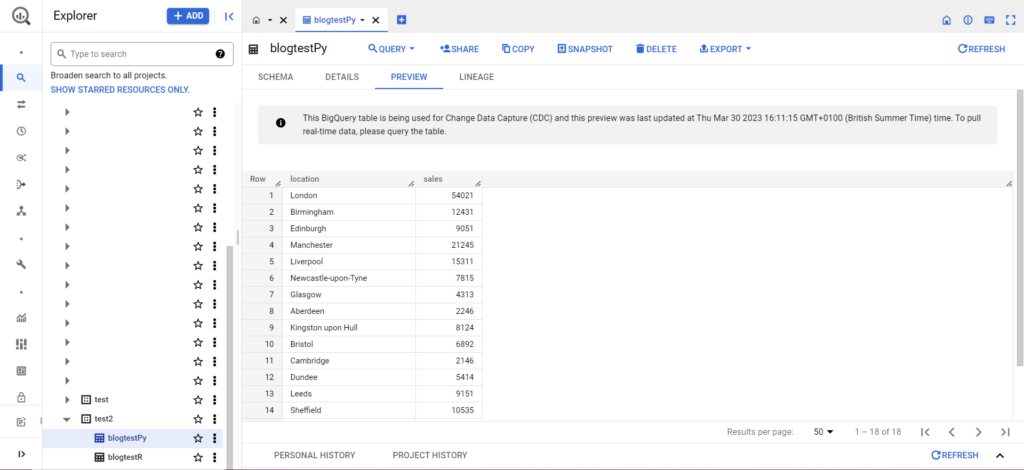
هناك الكثير مما يمكنك القيام به بهذه الوظائف بمجرد أن تتعود عليها. إذا كنت تريد التحكم بشكل أكبر في إعداد التحليلات الخاص بك ، فإن Semetrical هنا لمساعدتك! تحقق من مدونتنا للحصول على مزيد من المعلومات حول كيفية تحقيق أقصى استفادة من بياناتك. أو للحصول على مزيد من الدعم بشأن جميع التحليلات ، انتقل إلى تحليلات الويب لمعرفة كيف يمكننا مساعدتك.