
Análise de dados do Twitter para a final da Copa do Mundo da FIFA – PromptCloud
Publicados: 2018-07-27Recentemente, o mundo começou a se recuperar da febre do futebol da Copa do Mundo da FIFA que terminou com a França emergindo como vencedora. Antes de prosseguir, vamos verificar o contexto – a partida final foi disputada pela França e pela Croácia e disputada no Estádio Luzhniki em Moscou, Rússia, em 15 de julho de 2018 às 15h (horário GMT). A França venceu a partida por 4 a 2, que incluiu um pênalti e um gol contra da Croácia.
Assim como qualquer outra mídia social, o Twitter também estava cheio de fãs e espectadores constantemente twittando sobre a partida à medida que avançava. A hashtag de tendência para o evento foi #WordCupFinal . Este estudo se concentrará nos tweets extraídos entre 15h GMT e pouco mais de 19h30 GMT para a hashtag acima mencionada. O conjunto de dados final é composto por mais de 200.000 tweets originais (não inclui retuítes). Nossa análise de dados do Twitter responderá às seguintes perguntas:
1. Quais foram as principais hashtags usadas durante a partida?
2. Quais foram os principais idiomas em termos de contagem de tweets?
3. Quais os identificadores do twitter foram mais mencionados?
4. Qual foi o comprimento de caracteres para a maioria dos tweets?
5. Quais foram alguns tweets populares em termos de retuítes e curtidas?
Observe que este estudo não abrange as técnicas de mineração de texto; no entanto, eles podem ser aplicados usando os métodos já descritos na postagem de visualização de dados de letras de músicas de Taylor Swift.
[call_to_action title="Baixe o conjunto de dados gratuitamente" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=fifa-tweets&itm_content= data-mining" button_title="" class="" target="_blank" animate=""]Inscreva-se no DataStock via CrawlBoard e clique na categoria 'grátis' para baixar o conjunto de dados![/call_to_action]
Sinta-se à vontade para baixar o conjunto de dados do Twitter, se quiser replicar o código fornecido neste post ou experimentar os dados.
Principais hashtags
Vamos primeiro carregar os pacotes necessários e passar para a coluna `hashtags` para análise.
[linguagem do código=”r”]
# Frequência das hashtags
library("dplyr")
biblioteca("ggplot2")
library("magrittr")
library("escalas")
biblioteca("grepel")
fifa_tweets <- read.csv(file.choose())
# Configuração opcional para mostrar números maiores sem notação científica
opções(dígitos=22)
# Obtendo as hashtags do formato de lista
fifa_hashtags <- unlist(strsplit(as.character
(unlist(fifa_tweets$hashtags)),
'^c\(|,|"|\)'))
# Formatação removendo os espaços em branco
hashtags <- sapply(fifa_hashtags, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# Convertendo para data frame
hashtag_df <- as_data_frame(table(tolower(fifa_hashtags[hashtags]))))
hashtag_df <- hashtag_df[com(hashtag_df,pedido(-n)),]
hashtag_df <- hashtag_df[2:11,]
ggplot(hashtag_df, aes(x = reordenar(Var1, n), y=n)) +
geom_bar(stat="identidade", preenchimento="#00D4C9")+
coord_flip() +
theme_minimal() +
xlab("#Hashtags") + ylab("Contagem") +
ggtitle("Principais hashtags usadas durante a final da Copa do Mundo da FIFA, excluindo #WorldCupFinal") +
theme_minimal()
[/código]
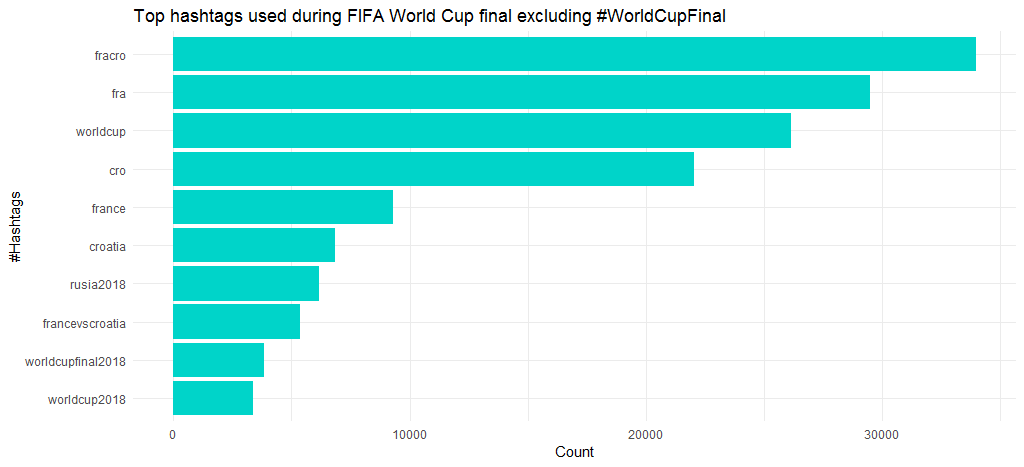
O gráfico a seguir mostra que outras hashtags populares além de #WordCupFinal são #fracro, #fra, #worldcup e #cro. É certo que o burburinho para a França foi maior do que para a Croácia, especialmente porque eles venceram a partida.
Principais idiomas
Vamos agora verificar os idiomas em que os tweets foram postados.
[linguagem do código=”r”]
lang_df <- count(fifa_tweets,lang) %>%
arranjar(desc(n)) %>%
fatia (1:15)
ggplot(data=lang_df, aes(x = reordenar(lang, n), y=n)) +
geom_bar(stat = 'identidade', preenchimento="#00D4C9") +
coord_flip() +
xlab("Idiomas") + ylab("Contagem") +
ggtitle("Principais idiomas usados nos tweets da final da Copa do Mundo da FIFA") +
theme_minimal()

[/código]
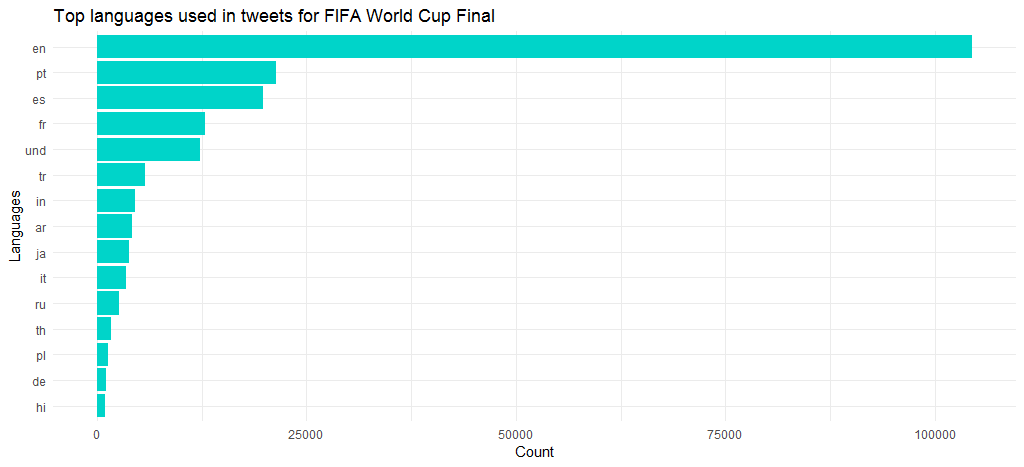
Além do inglês, outras línguas populares foram o português, o espanhol, o francês e o turco. Observe que `und` significa indefinido.
Principais alças do Twitter
Agora, vamos descobrir os usuários populares do Twitter que foram mencionados em vários tweets.
[linguagem do código=”r”]
# Obtendo as menções do formato de lista
menções_split <- unlist(strsplit(as.caractere
(unlist(fifa_tweets$mentions_screen_name)),
'^c\(|,|"|\)'))
# Formatação removendo os espaços em branco
menciona <- sapply(mentions_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# Convertendo para data frame
menções_df <- as_data_frame(table(tolower(mentions_split[menções]))))
menções_df <- menções_df[com(menções_df,pedido(-n)),]
menções_df <- menções_df[1:10,]
ggplot(menções_df, aes(x = reordenar(Var1, n), y=n)) +
geom_bar(stat="identidade", preenchimento="#00D4C9")+
theme_minimal() +
coord_flip() +
xlab("Twitter handles") + ylab("Count") +
ggtitle("Principais usuários do Twitter mencionados durante a final da Copa do Mundo da FIFA") +
theme_minimal()
[/código]
Isso mostra que a banda coreana BTS recebeu mais de 2500 menções devido à sua música para a partida final. E jogadores como Paul Pogba (francês), Kylian Mbappe (francês), Luka Modric (croata), Antoine Griezmann (Antoine Griezmann) estavam entre os 10 principais usuários mencionados. Observe que Kylian Mbappé se tornou o mais jovem desde Pelé a marcar na final da Copa do Mundo.

Distribuição de comprimento de caracteres
Qual foi o intervalo mais comum para comprimento de caracteres em tweets? Vamos descobrir!
[linguagem do código=”r”]
ggplot(fifa_tweets) + aes(x=display_text_width,y = ..count../sum(..count..)) +
geom_density(stat='bin', binwidth=15, alpha = .4, fill = "#1ed7d1") +
scale_y_continuous(rótulos = porcentagem, nome = "Porcentagem") +
scale_x_continuous(breaks = scales::pretty_breaks(n = 20),name = "Comprimento do caractere") +
ggtitle("Distribuição do tamanho dos caracteres dos tweets durante a final da Copa do Mundo da FIFA") +
theme_minimal()
[/código]
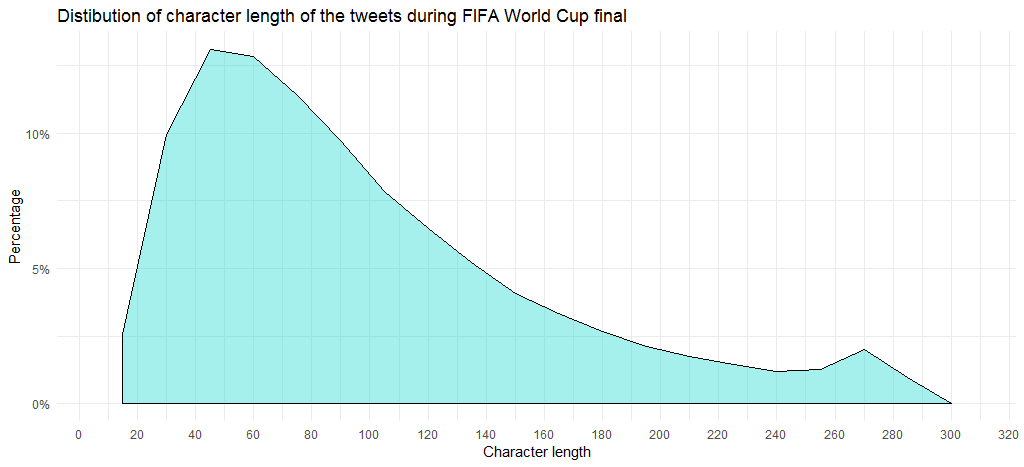
O gráfico mostra que a maioria dos tweets tem de 45 a 60 caracteres. Observe que o comprimento médio é de 99.
Tweets populares
Agora, descobriríamos alguns dos tweets mais populares postados pelos usuários.
[linguagem do código=”r”]
ggplot(fifa_tweets, aes(x=favorite_count, y=retweet_count)) +
geom_text_repel(dados = fifa_tweets[fifa_tweets$favorite_count > 5000 | fifa_tweets$retweet_count > 2000,],
aes(etiqueta = nome),
box.padding = unit(0,45, "linhas")) +
geom_point(color = "#00D4C9") +
xlab("Contagem de favoritos") + ylab("Contagem de retuítes") +
ggtitle("Principais tweets postados durante a final da Copa do Mundo da FIFA") +
theme_minimal() +
tema(plot.margin=unit(c(.2,.5,.2,.2),"cm"))
[/código]
Isso mostra que os principais tweets em termos de favoritos e retuítes foram postados por UEFA Champions League, Lay Zhang, Copa do Mundo da FIFA e Pelé, considerado o maior jogador de futebol de todos os tempos.

Vamos conferir o tweet postado por Pelé:
Se Kylian continuar igualando meus recordes assim, posso ter que tirar o pó das botas de novo… // Se o @KMbappe continuar a igualar os meus recordes assim, eu vou ter que tirar a poeira das minhas chuteiras novamente…#WorldCupFinal https:// t.co/GYWfMxPn7p
— Pelé (@Pele) 15 de julho de 2018
Para você
Realizamos uma análise exploratória de dados no conjunto de dados do Twitter para descobrir as hashtags mais usadas, tweets populares, comprimento de caracteres dos tweets junto com o idioma e a conta do twitter mais mencionada. análise — técnicas de mineração de texto podem ser aplicadas no texto do tweet para n-grams, nuvem de palavras, análise de sentimentos e muito mais.
