
Analiza danych z Twittera na finał Mistrzostw Świata FIFA — PromptCloud
Opublikowany: 2018-07-27Niedawno świat zaczął wracać do zdrowia po gorączce piłkarskiej Mistrzostw Świata FIFA, która zakończyła się zwycięstwem Francji. Zanim przejdziemy dalej, przyjrzyjmy się kontekstowi — mecz finałowy został zakwestionowany przez Francję i Chorwację i rozegrany na stadionie Łużniki w Moskwie w Rosji 15 lipca 2018 r. o godzinie 15:00 (strefa czasowa GMT). Francja wygrała mecz 4:2 z jednym rzutem karnym i golem samobójczym Chorwacji.
Podobnie jak w przypadku innych mediów społecznościowych, Twitter również był pełen fanów i widzów, którzy nieustannie tweetowali o meczu w miarę jego postępu. Popularny hashtag wydarzenia to #WordCupFinal . To badanie skoncentruje się na tweetach wyodrębnionych między 15:00 GMT a nieco powyżej 19:30 GMT dla wyżej wymienionego hashtagu. Ostateczny zestaw danych zawiera ponad 200 000 oryginalnych tweetów (nie obejmuje retweetów). Nasza analiza danych z Twittera odpowie na następujące pytania:
1. Jakie były najpopularniejsze hashtagi używane podczas meczu?
2. Które języki były najpopularniejsze pod względem liczby tweetów?
3. Które uchwyty na Twitterze były wymieniane najczęściej?
4. Jaka była długość znaków w większości tweetów?
5. Jakie były popularne tweety pod względem retweetów i polubień?
Zauważ, że to badanie nie obejmuje technik eksploracji tekstu; jednak można je zastosować przy użyciu metod opisanych już w poście dotyczącym wizualizacji danych tekstów piosenek Taylora Swifta.
[call_to_action title="Pobierz zestaw danych za darmo" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=fifa-tweets=&itm_content data-mining" button_title="" class="" target="_blank" animate=""]Zarejestruj się w DataStock przez CrawlBoard i kliknij kategorię „bezpłatne”, aby pobrać zestaw danych![/call_to_action]
Zachęcamy do pobrania zestawu danych Twittera, jeśli chcesz odtworzyć kod podany w tym poście lub poeksperymentować z danymi.
Najlepsze hashtagi
Najpierw załadujmy wymagane pakiety i przejdźmy do kolumny `hashtags` w celu analizy.
[język kodu=”r”]
# Częstotliwość hashtagów
biblioteka ("dplyr")
biblioteka ("ggplot2")
biblioteka("magrittr")
biblioteka("wagi")
biblioteka("ggrepel")
fifa_tweets <- read.csv(file.choose())
# Opcjonalna konfiguracja, aby pokazać większe liczby bez notacji naukowej
opcje(cyfry=22)
# Pobieranie hashtagów z formatu listy
fifa_hashtags <- unlist(strsplit(jako.znak .)
(unlist(fifa_tweets$hashtagi)),
'^c\(|,|"|\)'))
# Formatowanie poprzez usunięcie białych spacji
hashtagi <- sapply(fifa_hashtags, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# Konwersja do ramki danych
hashtag_df <- as_data_frame(table(tolower(fifa_hashtags[hashtags])))
hashtag_df <- hashtag_df[z(hashtag_df,zamówienie(-n)),]
hashtag_df <- hashtag_df[2:11,]
ggplot(hashtag_df, aes(x = reorder(Var1, n), y=n)) +
geom_bar(stat="tożsamość", fill="#00D4C9")+
coord_flip() +
theme_minimal() +
xlab("#Hashtagi") + ylab("Liczba") +
ggtitle("Najpopularniejsze hashtagi używane podczas finału Mistrzostw Świata FIFA z wyjątkiem #WorldCupFinal") +
theme_minimal()
[/kod]
Poniższy wykres pokazuje, że inne popularne hashtagi oprócz #WordCupFinal to #fracro, #fra, #worldcup i #cro. Pewne jest, że we Francji było więcej szumu niż w Chorwacji, zwłaszcza że wygrali mecz.
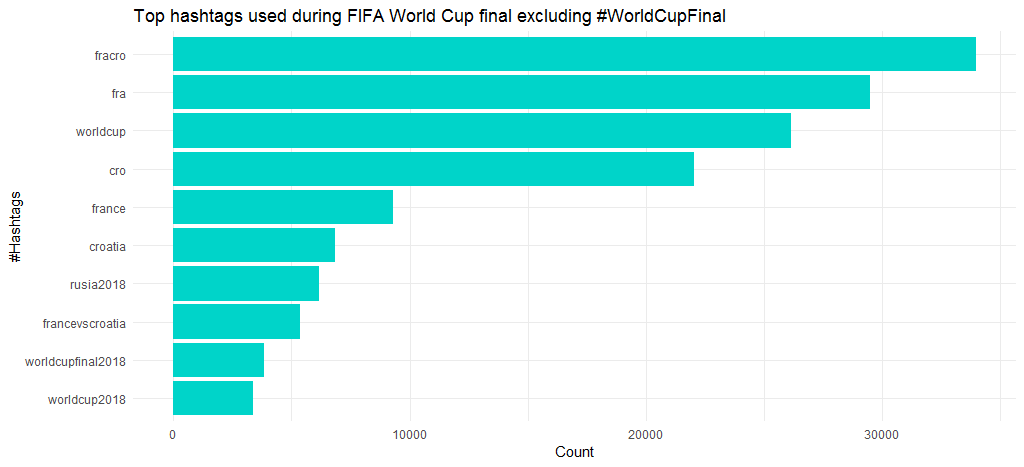
Najlepsze języki
Sprawdźmy teraz, w jakich językach zostały opublikowane tweety.
[język kodu=”r”]
lang_df <- count(fifa_tweety,język) %>%
rozmieszczenie(opis(n)) %>%
plasterek(1:15)
ggplot(data=lang_df, aes(x = reorder(lang, n), y=n)) +
geom_bar(stat = 'tożsamość', fill="#00D4C9") +
coord_flip() +
xlab("Języki") + ylab("Liczba") +
ggtitle("Najpopularniejsze języki używane w tweetach podczas finału Mistrzostw Świata FIFA") +
theme_minimal()

[/kod]
Oprócz angielskiego innymi popularnymi językami były portugalski, hiszpański, francuski i turecki. Zauważ, że `und` oznacza undefined.
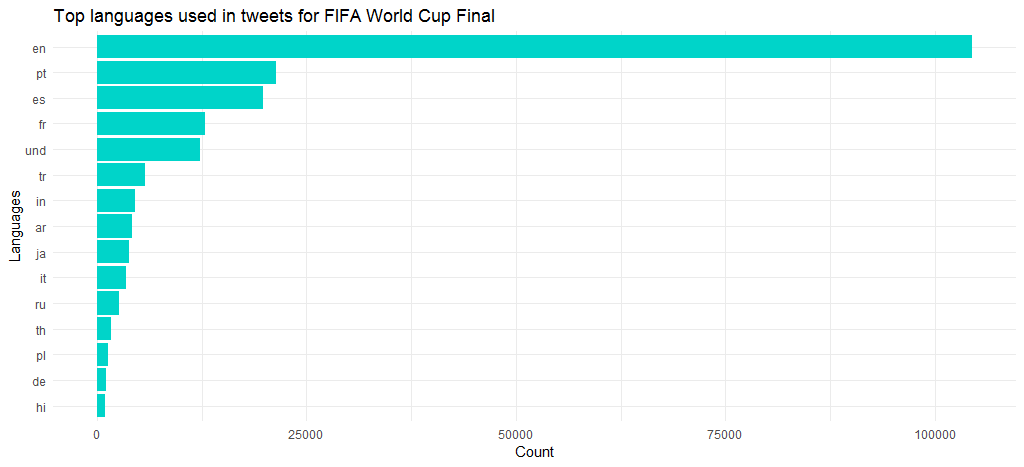
Najlepsze uchwyty na Twitterze
Teraz poznajmy popularnych użytkowników Twittera, o których wspominano w różnych tweetach.
[język kodu=”r”]
# Pobieranie wzmianek z formatu listy
wspomina_split <- unlist(strsplit(jako.znak .)
(unlist(fifa_tweets$mentions_screen_name))
'^c\(|,|"|\)'))
# Formatowanie poprzez usunięcie białych spacji
wspomina <- sapply(mentions_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# Konwersja do ramki danych
wspomina_df <- as_data_frame(table(tolower(mentions_split[wzmianki])))
wspomina_df <- wspomina_df[z(wzmiankami_df,zamówieniem(-n)),]
wspomina_df <- wspomina_df[1:10,]
ggplot(mentions_df, aes(x = reorder(Var1, n), y=n)) +
geom_bar(stat="tożsamość", fill="#00D4C9")+
theme_minimal() +
coord_flip() +
xlab("Uchwyty Twittera") + ylab("Liczba") +
ggtitle(„Najlepsze uchwyty Twittera wymienione podczas finału Mistrzostw Świata FIFA”) +
theme_minimal()
[/kod]
To pokazuje, że koreański zespół BTS zebrał ponad 2500 wzmianek dzięki piosence na finałowy mecz. A gracze tacy jak Paul Pogba (Francuz), Kylian Mbappe (Francuz), Luka Modric (Chorwacki), Antoine Griezmann (Antoine Griezmann) znaleźli się wśród 10 najlepszych użytkowników. Zauważ, że Kylian Mbappe stał się najmłodszym od czasu Pele, który zdobył bramkę w finale Pucharu Świata.

Rozkład długości znaków
Jaki był najczęstszy zakres długości znaków w tweetach? Dowiedzmy Się!
[język kodu=”r”]
ggplot(fifa_tweety) + aes(x=szerokość_tekstu_wyświetlanego,y = ..liczba../suma(..liczba..)) +
geom_density(stat='bin', binwidth=15, alfa = 0,4, fill = „#1ed7d1”) +
scale_y_continuous(etykiety = procent,nazwa = „Procent”) +
scale_x_continuous(breaks = scales::pretty_breaks(n = 20),name = „Długość znaku”) +
ggtitle(„Rozkład długości znaków w tweetach podczas finału Mistrzostw Świata FIFA”) +
theme_minimal()
[/kod]
Z wykresu wynika, że większość tweetów ma długość 45-60 znaków. Zauważ, że średnia długość wynosi 99.
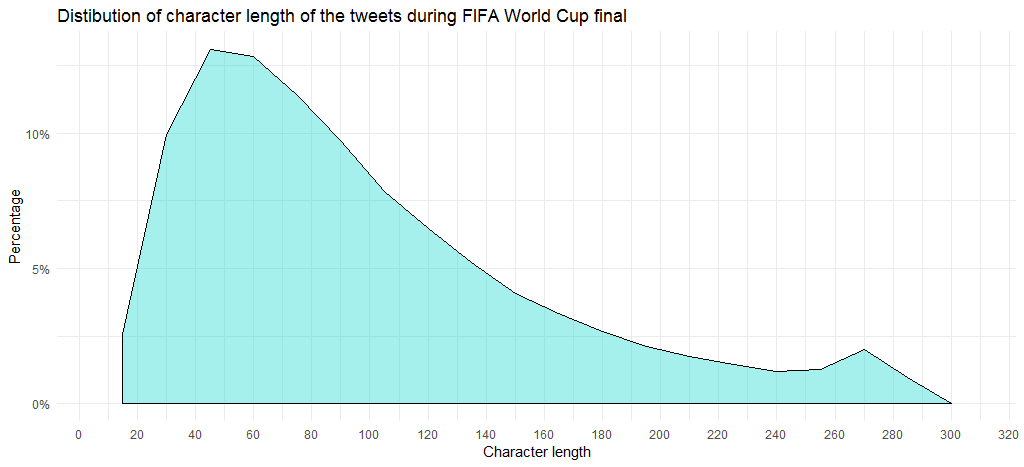
Popularne tweety
Teraz poznamy niektóre z najpopularniejszych tweetów publikowanych przez użytkowników.
[język kodu=”r”]
ggplot(fifa_tweety, aes(x=favorite_count, y=retweet_count)) +
geom_text_repel(data = fifa_tweets[fifa_tweets$favorite_count > 5000 | fifa_tweets$retweet_count > 2000,],
aes(etykieta = nazwa),
box.padding = jednostka(0.45, "linie")) +
geom_point(kolor = „#00D4C9”) +
xlab („Liczba ulubionych”) + ylab(„Liczba retweetów”) +
ggtitle(„Najpopularniejsze tweety publikowane podczas finału Mistrzostw Świata FIFA”) +
theme_minimal() +
theme(plot.margin=jednostka(c(.2,.5,.2,.2),"cm"))
[/kod]
To pokazuje, że najlepsze tweety pod względem faworytów i retweetów opublikowali Liga Mistrzów UEFA, Lay Zhang, Mistrzostwa Świata FIFA i Pele, który jest uważany za najlepszego piłkarza wszechczasów.

Sprawdźmy tweet opublikowany przez Pele:
Jeśli Kylian będzie nadal dorównywał moim rekordom, być może będę musiał ponownie odkurzyć moje buty… // Zobacz @KMbappe kontynuując igualar os meus records assim, eu vou ter que tirar a poeira das minhas chuteiras novamente…#WorldCupFinal https:// t.co/GYWfMxPn7p
— Pele (@Pele) 15 lipca 2018 r.
Do Ciebie
Przeprowadziliśmy eksploracyjną analizę danych na zestawie danych Twittera, aby znaleźć najczęściej używane hashtagi, popularne tweety, długość znaków w tweetach wraz z językiem i najczęściej wspominane konto na Twitterze. Teraz nadszedł czas, abyś pobrał zestaw danych i wykonał analiza — techniki eksploracji tekstu mogą być zastosowane w tekście tweeta dla n-gramów, chmury słów, analizy sentymentu i innych.
