
FIFA ワールド カップ決勝の Twitter データ分析 – PromptCloud
公開: 2018-07-27最近、世界は FIFA ワールド カップのサッカー熱から回復し始め、フランスが勝者として台頭して終わりました。 先に進む前に、状況を確認しておきましょう — 決勝戦はフランスとクロアチアによって争われ、2018 年 7 月 15 日午後 3 時 (GMT 時間帯) にロシアのモスクワにあるルジニキ スタジアムで行われました。 フランスは、クロアチアの 1 つのペナルティとオウンゴールを含む試合で 4-2 で勝利しました。
他のソーシャル メディアと同様に、Twitter もファンや視聴者が試合の進行に合わせて絶え間なくツイートすることで賑わっていました。 このイベントのトレンド ハッシュタグは#WordCupFinalた。 この調査では、上記のハッシュタグについて、GMT 午後 3 時から午後 7 時 30 分強の間に抽出されたツイートに焦点を当てます。 最終的なデータ セットは、200,000 を超える元のツイートで構成されます (リツイートは含まれません)。 私たちのツイッターデータ分析は、次の質問に答えます:
1. 試合中に使用された上位のハッシュタグは?
2. ツイート数でトップの言語は?
3. 最も多く言及された Twitter ハンドルは?
4. ほとんどのツイートの文字数は?
5. リツイートやいいねが多かったツイートは?
この調査では、テキスト マイニング技術については触れていないことに注意してください。 ただし、Taylor Swift の歌の歌詞データの視覚化に関する投稿で既に説明されている方法を使用して適用できます。
[call_to_action title="データ セットを無料でダウンロード" icon="icon-download" link="https://app.promptcloud.com/users/sign_up?target=data_stocks&itm_source=website&itm_medium=blog&itm_campaign=dataviz&itm_term=fifa-tweets&itm_content= data-mining" button_title="" class="" target="_blank" animate=""]CrawlBoard から DataStock にサインアップし、「無料」カテゴリをクリックしてデータセットをダウンロードしてください![/call_to_action]
この投稿で提供されているコードを複製したり、データを使って実験したりしたい場合は、Twitter データ セットを自由にダウンロードしてください。
上位のハッシュタグ
最初に必要なパッケージをロードし、分析のために「ハッシュタグ」列に移動しましょう。
[コード言語=”r”]
# ハッシュタグの頻度
ライブラリ(「dplyr」)
ライブラリ(「ggplot2」)
ライブラリ(「magrittr」)
library("スケール")
ライブラリ(「ggrepel」)
fifa_tweets <- read.csv(file.choose())
# 科学表記法なしでより大きな数を表示するためのオプションの構成
オプション(桁数=22)
# リスト形式からハッシュタグを取得
fifa_hashtags <- unlist(strsplit(as.character
(unlist(fifa_tweets$hashtags)),
'^c\(|,|"|\)'))
# 空白を削除してフォーマットする
ハッシュタグ <- sapply(fifa_hashtags, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# データフレームに変換
hashtag_df <- as_data_frame(table(tolower(fifa_hashtags[hashtags])))
ハッシュタグ df <- ハッシュタグ df[with(hashtag_df,order(-n)),]
ハッシュタグ df <- ハッシュタグ df[2:11,]
ggplot(hashtag_df, aes(x = reorder(Var1, n), y=n)) +
geom_bar(stat="ID", fill="#00D4C9")+
coord_flip() +
theme_minimal() +
xlab("#ハッシュタグ") + ylab("カウント") +
ggtitle("#WorldCupFinal を除く FIFA ワールドカップ決勝で使用された上位のハッシュタグ") +
theme_minimal()
[/コード]
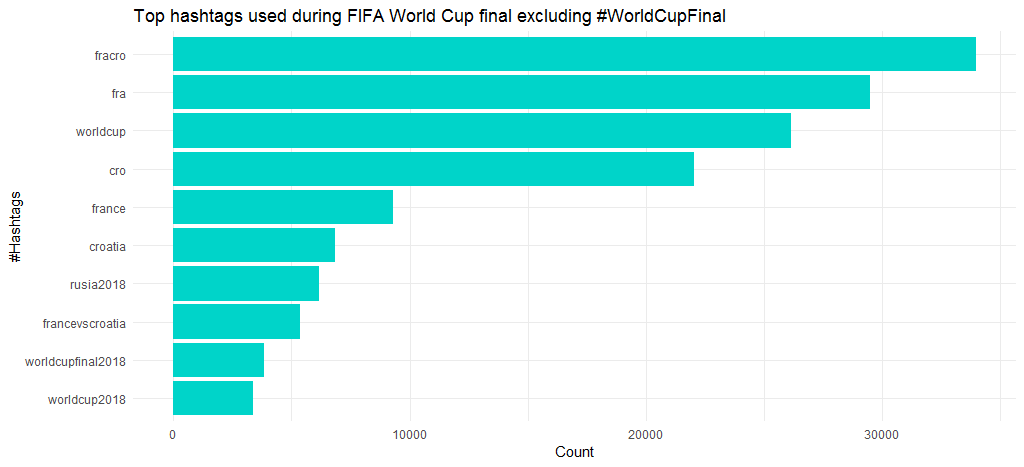
次のグラフは、#WordCupFinal 以外の人気のあるハッシュタグが #fracro、#fra、#worldcup、#cro であることを示しています。 特に試合に勝ったことから、フランスの話題がクロアチアよりも大きかったことは確かです。
トップ言語
ツイートが投稿された言語を確認してみましょう。
[コード言語=”r”]
lang_df <- count(fifa_tweets,lang) %>%
アレンジ(desc(n)) %>%
スライス(1:15)
ggplot(data=lang_df, aes(x = reorder(lang, n), y=n)) +
geom_bar(stat = 'ID', fill="#00D4C9") +
coord_flip() +
xlab("言語") + ylab("カウント") +
ggtitle("FIFA ワールド カップ決勝のツイートで使用された主な言語") +
theme_minimal()

[/コード]
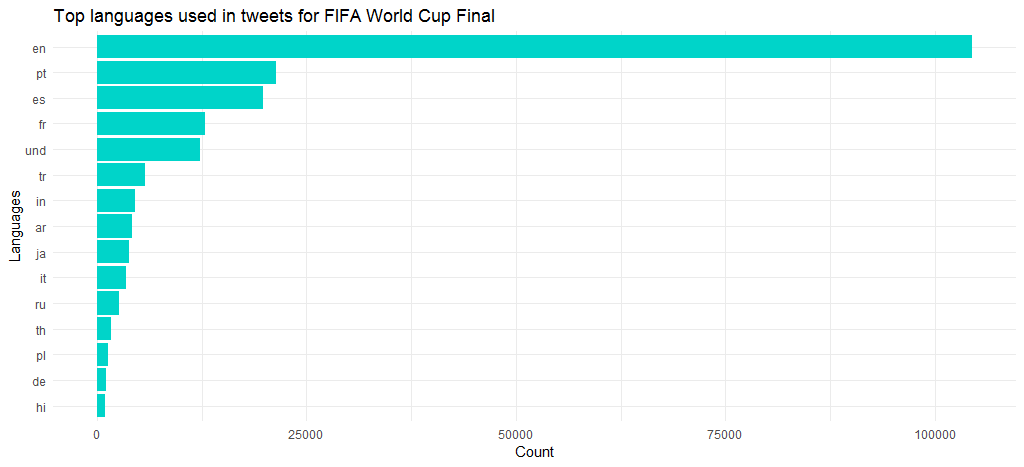
英語の他に、ポルトガル語、スペイン語、フランス語、トルコ語が人気の言語でした。 「und」は未定義を表すことに注意してください。
トップ Twitter ハンドル
それでは、さまざまなツイートで言及された人気の twitter ユーザーを見つけてみましょう。
[コード言語=”r”]
# リスト形式からメンションを取得する
Mentions_split <- unlist(strsplit(as.character)
(unlist(fifa_tweets$mentions_screen_name)),
'^c\(|,|"|\)'))
# 空白を削除してフォーマットする
言及 <- sapply(mentions_split, function(y) nchar(trimws(y)) > 0 & !is.na(y))
# データフレームに変換
ements_df <- as_data_frame(table(tolower(mentions_split[mentions])))
言及_df <- 言及_df[with(言及_df,順序(-n)),]
言及_df <- 言及_df[1:10,]
ggplot(mentions_df, aes(x = reorder(Var1, n), y=n)) +
geom_bar(stat="ID", fill="#00D4C9")+
theme_minimal() +
coord_flip() +
xlab("Twitter ハンドル") + ylab("Count") +
ggtitle("FIFA ワールド カップ決勝で言及された上位の Twitter ハンドル") +
theme_minimal()
[/コード]
これは、韓国のバンド BTS が決勝戦の曲で 2500 を超える言及を獲得したことを示しています。 そして、Paul Pogba (フランス)、Kylian Mbappe (フランス)、Luka Modric (クロアチア)、Antoine Griezmann (Antoine Griezmann) などの選手が、言及されたユーザーのトップ 10 に含まれていました。 キリアン・ムバッペはペレ以来最年少でワールドカップ決勝で得点したことに注意してください。

文字長分布
ツイートの文字の長さの最も一般的な範囲は? 確認してみましょう!
[コード言語=”r”]
ggplot(fifa_tweets) + aes(x=display_text_width,y = ..count../sum(..count..)) +
geom_density(stat='bin', binwidth=15, alpha = .4, fill = "#1ed7d1") +
scale_y_continuous(labels = percent,name = "パーセンテージ") +
scale_x_continuous(breaks = scales::pretty_breaks(n = 20),name = "文字長") +
ggtitle("FIFAワールドカップ決勝時のツイートの文字数分布") +
theme_minimal()
[/コード]
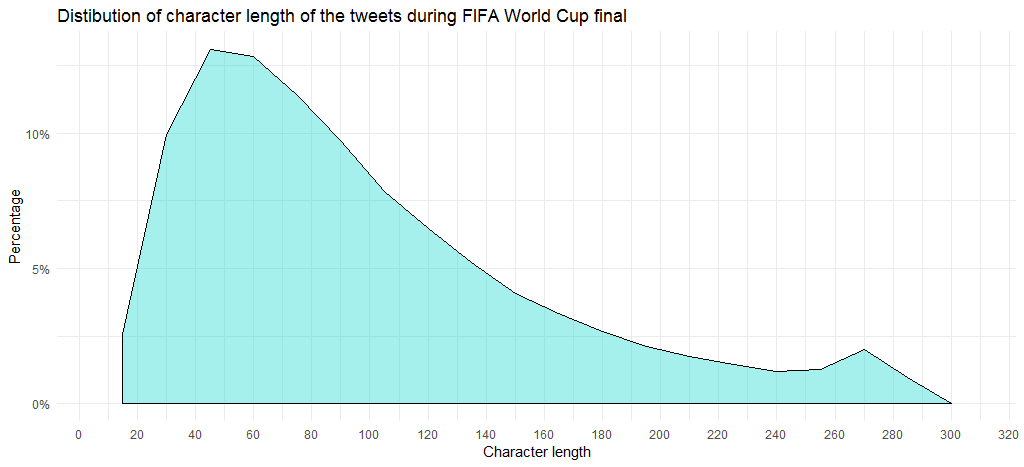
グラフは、ツイートの大半が 45 ~ 60 文字の長さであることを示しています。 平均長さは 99 であることに注意してください。
人気のツイート
これで、ユーザーが投稿した最も人気のあるツイートのいくつかを見つけることができます。
[コード言語=”r”]
ggplot(fifa_tweets, aes(x=favorite_count, y=retweet_count)) +
geom_text_repel(data = fifa_tweets[fifa_tweets$favorite_count > 5000 | fifa_tweets$retweet_count > 2000,],
aes(ラベル=名前)、
box.padding = unit(0.45, "lines")) +
geom_point(color = "#00D4C9") +
xlab(「お気に入り数」) + ylab(「リツイート数」) +
ggtitle("FIFA ワールドカップ決勝中に投稿された上位のツイート") +
theme_minimal() +
theme(plot.margin=unit(c(.2,.5,.2,.2),"cm"))
[/コード]
これは、お気に入り数とリツイート数で上位のツイートが、UEFA チャンピオンズ リーグ、レイ チャン、FIFA ワールド カップ、史上最高のサッカー選手と見なされているペレによって投稿されたことを示しています。

ペレが投稿したツイートを見てみましょう。
キリアンがこのように私の記録に匹敵し続けるなら、私は再び私のブーツをほこりを払わなければならないかもしれません. t.co/GYWfMxPn7p
— ペレ (@Pele) 2018 年 7 月 15 日
あなたに
Twitter のデータ セットに対して探索的データ分析を実行し、最も使用されているハッシュタグ、人気のあるツイート、ツイートの文字数、言語、最も言及されている Twitter アカウントを見つけました。分析 — n-gram、ワード クラウド、センチメント分析などのために、ツイート テキストにテキスト マイニング技術を適用できます。
