
A evolução do software de web scraping: de scripts simples a soluções baseadas em IA
Publicados: 2024-03-13Web scraping evoluiu de uma habilidade especializada usada principalmente por aficionados por tecnologia para se tornar um recurso crucial para empresas que dependem de dados. No passado, os scripts eram criados exclusivamente para obter pequenas quantidades de informações de websites individuais. Atualmente, o web scraping está liderando em termos de inovação, desempenhando um papel importante em áreas como análise de mercado, rastreamento de preços, criação de leads e pesquisa com software de web scraping.
O que é software de raspagem da Web?
O software de web scraping funciona como uma ferramenta automatizada projetada para extrair dados de sites. Ele percorre a web, simula ações do usuário e coleta informações específicas de diversas páginas da web. Esses programas de software são projetados para:
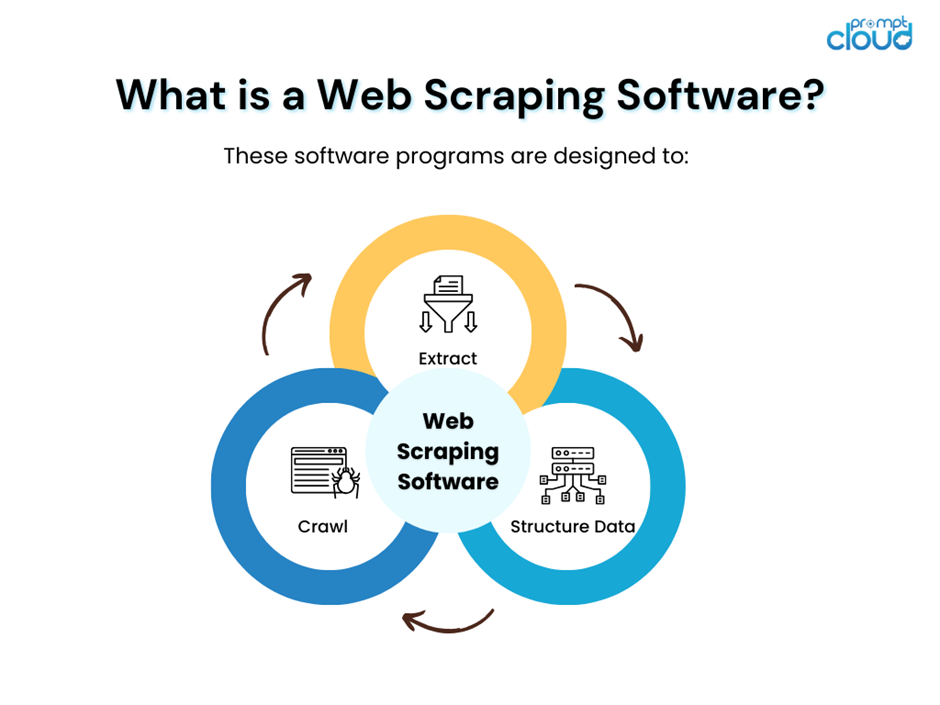
- Rastreie estruturas de sites para detectar e recuperar conteúdo.
- Extraia pontos de dados como preços, detalhes de contato e conteúdo textual.
- Converta dados não estruturados da web em um formato estruturado para análise.
Normalmente escrito em linguagens de programação como Python ou usando estruturas como Scrapy, o software de web scraping pode lidar com tarefas simples a complexas de coleta de dados, sustentando diversas aplicações em pesquisa de mercado, SEO, tomada de decisão baseada em dados e muito mais.
A evolução do software de web scraping: de scripts simples a bots complexos
Fonte da imagem: https://www.scrapingdog.com/
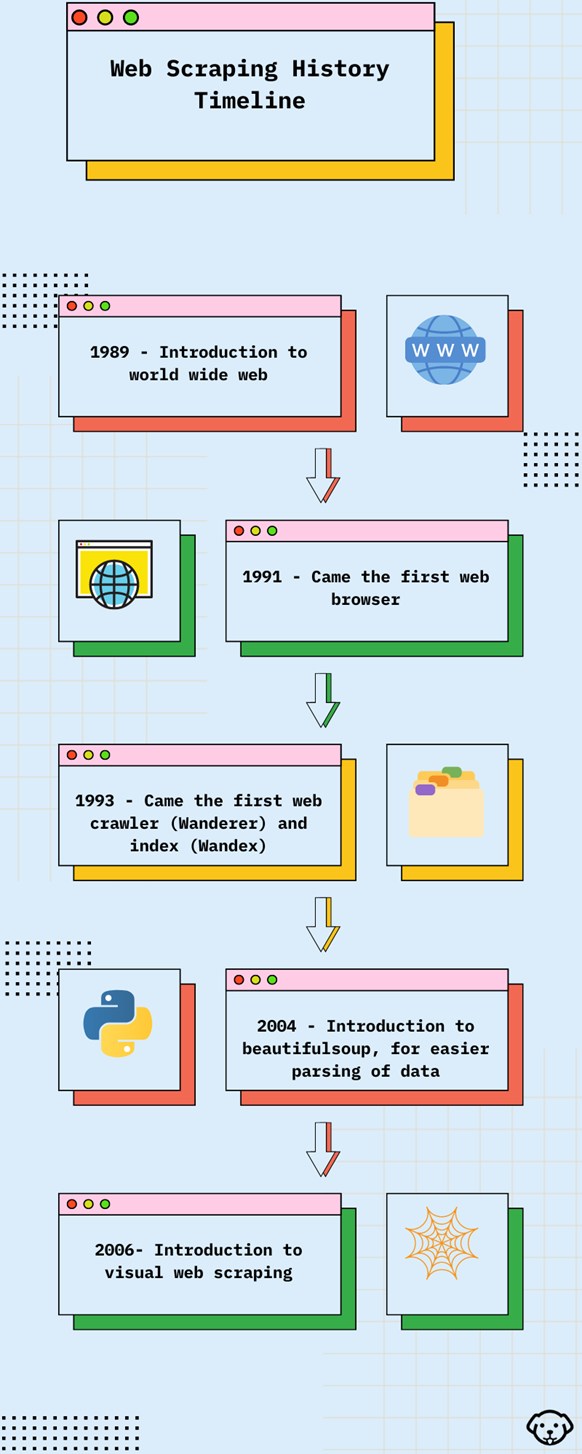
Web scraping teve uma jornada transformadora. Inicialmente, os entusiastas empregavam scripts rudimentares criados em linguagens como Perl ou Python. Esses scripts seguiam padrões básicos, buscando páginas da web e extraindo dados por meio de expressões regulares ou técnicas simples de análise. À medida que a complexidade tecnológica crescia, também cresciam as ferramentas de raspagem.
Os raspadores evoluíram para bots sofisticados, capazes de navegar em sites como um usuário humano. Esses sistemas avançados incorporaram recursos como:
- Navegadores headless , para renderizar sites com muito JavaScript
- Técnicas de resolução de CAPTCHA , permitindo acesso de bot a áreas protegidas por CAPTCHA
- Serviços de rotação de proxy , para evitar banimentos de IP e simular acesso de usuários regionais
- Algoritmos de aprendizado de máquina para reconhecimento e extração adaptativa de dados
A transformação contínua reflete uma competição incessante entre administradores de sites e desenvolvedores de ferramentas de web scraping. Ambas as partes introduzem inovações persistentemente para proteger ou recuperar dados da web.
A integração de IA e aprendizado de máquina em software de web scraping
O advento da IA e do aprendizado de máquina transformou o software de web scraping em plataformas altamente inteligentes. Essas tecnologias permitem:
- A interpretação dinâmica de dados permite que o software compreenda e se adapte a diferentes layouts de sites e estruturas de dados.
- O reconhecimento avançado de padrões ajuda a identificar e extrair informações relevantes de forma eficiente.
- Navegação de obstáculos aprimorada, como contornar CAPTCHAs e lidar com JavaScript complexo.
- A análise preditiva permite que as empresas prevejam tendências com base nos dados coletados.
- Capacidades de aprendizagem contínua, para que o software se torne mais eficaz a cada tentativa.
A integração de IA e aprendizado de máquina permite que soluções de scraping lidem com tarefas mais sofisticadas com maior precisão e mínima intervenção humana.
Desafios e preocupações éticas nas práticas de web scraping
A raspagem na Web enfrenta obstáculos técnicos, incluindo a evolução das estruturas dos sites e das medidas anti-bot. Questões éticas no web scraping também surgem, já que os scrapers podem infringir direitos autorais, violar os termos de serviço, impactar o desempenho do site e levantar questões de privacidade com dados pessoais.

Além disso, surgem preocupações sobre a justiça da utilização de dados acessíveis ao público para ganhos comerciais sem o consentimento dos criadores de conteúdos. Advogados, profissionais de TI e especialistas em ética debatem o delicado equilíbrio entre a disponibilidade de dados abertos e a proteção dos direitos dos criadores de conteúdo original.
O impacto do web scraping avançado nas indústrias e na pesquisa de mercado

Fonte da imagem: Web Scraping – Um guia completo | PromptCloud
Nas indústrias, as tecnologias avançadas de web scraping oferecem vantagens significativas, facilitando a extração de dados extensos para análise, levando a benefícios substanciais. Os pesquisadores de mercado utilizam essas ferramentas para:
- Identificar Tendências: Ao analisar dados, eles podem detectar movimentos de mercado e padrões de comportamento do consumidor.
- Análise Competitiva: As empresas rastreiam os preços, ofertas de produtos e estratégias de mercado dos concorrentes.
- Sentimentos do cliente: vasculhe as mídias sociais e avalie sites para avaliar a opinião pública.
- Otimização da cadeia de suprimentos: monitore os dados dos fornecedores para melhorar a logística.
- Marketing direcionado: entenda melhor os dados demográficos para campanhas mais personalizadas.
Web scraping avançado permite uma melhor tomada de decisões, promovendo a adoção de metodologias de negócios estratégicas e centradas em dados.
O futuro do software de raspagem da Web
À medida que a tecnologia avança, o software de web scraping está preparado para avanços transformadores. Os especialistas prevêem que:
- A integração da inteligência artificial e do aprendizado de máquina irá refinar ainda mais a extração de dados, tornando o software mais apto a interpretar e analisar estruturas de dados complexas.
- Técnicas aprimoradas para evitar a detecção de bots serão desenvolvidas para acompanhar medidas de segurança de sites mais sofisticadas.
- A raspagem colaborativa, utilizando redes distribuídas, permitirá uma coleta de dados mais eficiente, reduzindo a carga em servidores individuais e minimizando o risco de detecção.
- Espera-se que as estruturas legais e éticas evoluam, levando potencialmente a diretrizes e padrões mais claros no domínio do web scraping.
- O software Scraper provavelmente se tornará mais fácil de usar, atendendo a um público mais amplo, incluindo aqueles sem experiência em programação.
Perguntas frequentes
Qual software é melhor para web scraping?
Ao selecionar uma ferramenta para web scraping, vários fatores entram em jogo, dependendo da complexidade do site alvo, da magnitude da coleta de dados e da proficiência técnica do indivíduo.
Uma infinidade de soluções atendem a diversos requisitos – entre eles estão BeautifulSoup, Scrapy e Selenium para Python; Marionetista para JavaScript; e Octoparse oferecendo uma interface amigável sem pré-requisitos de codificação.
Em última análise, identificar a opção mais adequada depende de avaliar até que ponto cada uma se alinha com seus objetivos exclusivos. A experimentação com múltiplas alternativas pode ser benéfica para identificar o ajuste ideal.
Como faço para raspar um site inteiro?
Embarcar na missão de criar um site extenso exige a elaboração de um script capaz de percorrer inúmeras páginas e, ao mesmo tempo, capturar com precisão os detalhes pertinentes incorporados nelas.
Normalmente, conseguir isso envolve o emprego de uma abordagem combinada que envolve estratégias como decifrar parâmetros de URL, buscar hiperlinks, enfrentar desafios de paginação e administrar o gerenciamento de cookies, quando aplicável.
Dito isto, ter cautela continua sendo fundamental durante a execução, uma vez que sujeitar os servidores a cargas substanciais por meio de atividades agressivas de scraping ou infringir os termos de serviço estabelecidos pode resultar em repercussões indesejadas, desde cobranças exorbitantes pela utilização de conteúdo ilícito até riscos potenciais de litígio.
A raspagem na web é gratuita?
Embora abundantes ferramentas de código aberto e materiais educacionais facilitem os esforços de web scraping, a implementação bem-sucedida de tais projetos frequentemente exige gastos relacionados a tempo, poder computacional, infraestrutura de rede, aquisição de software proprietário ou envolvimento de profissionais qualificados fluentes em tecnologias de web scraping.
Além disso, determinados sites proíbem expressamente práticas de scraping, impondo penalidades pelo descumprimento ou recorrendo a medidas judiciais se necessário. Portanto, o consentimento prévio deve sempre ser obtido antes de iniciar as operações de web scraping, aliado à vigilância no sentido de aderir às normas éticas em todo o empreendimento.
O ChatGPT pode realizar web scraping?
ChatGPT não executa funções de web scraping de forma independente. Embora seja competente na compreensão de consultas em linguagem natural e na geração de respostas personalizadas baseadas em vastos bancos de dados de aprendizagem, o ChatGPT carece de recursos inerentes que permitam a interação com plataformas externas sem comandos de programação explícitos.
A execução de iniciativas de web scraping garante a composição de scripts codificados utilizando bibliotecas ou estruturas adequadas projetadas especificamente para esses fins. No entanto, aproveitar o ChatGPT poderia agilizar outros aspectos dos processos de desenvolvimento, fornecendo insights, sugestões ou explicações valiosas sobre conceitos subjacentes associados a tarefas de web scraping.