
网页抓取软件的演变:从简单的脚本到人工智能驱动的解决方案
已发表: 2024-03-13网络抓取已经从主要由技术爱好者使用的专业能力发展成为依赖数据的公司的重要资源。 过去,创建脚本只是为了从各个网站获取少量信息。 目前,网络抓取在创新方面处于领先地位,在市场分析、价格跟踪、潜在客户创建和网络抓取软件研究等领域发挥着重要作用。
什么是网页抓取软件?
网络抓取软件作为一种自动化工具,旨在从网站中提取数据。 它遍历网络,模拟用户操作,并从不同的网页收集指定信息。 这些软件程序旨在:
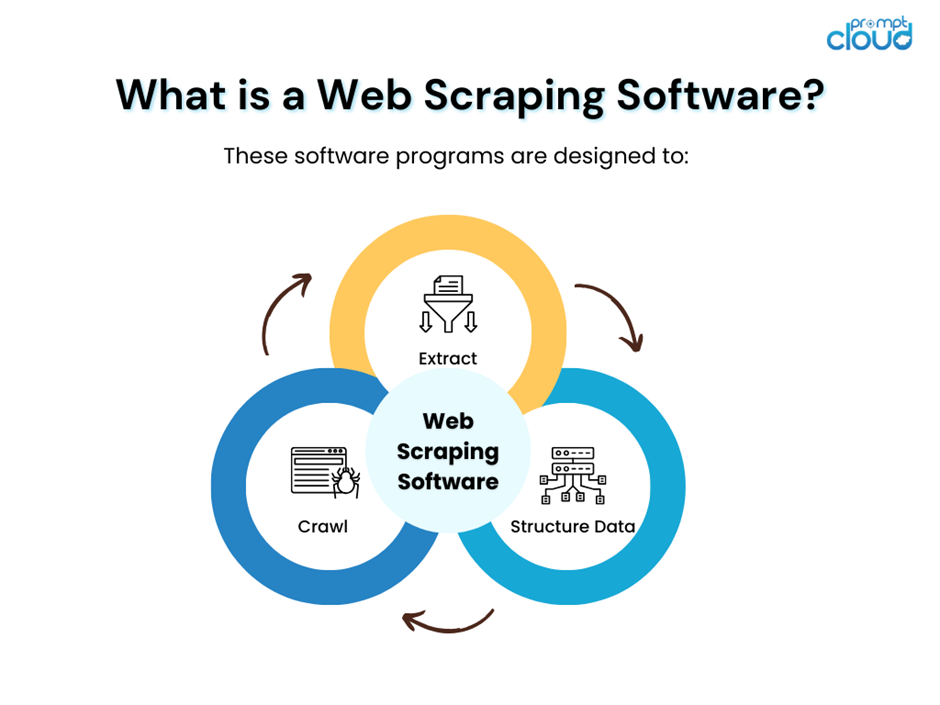
- 抓取网站结构以检测和检索内容。
- 提取数据点,例如价格、联系方式和文本内容。
- 将非结构化 Web 数据转换为结构化格式以进行分析。
网络抓取软件通常使用 Python 等编程语言或 Scrapy 等框架编写,可以处理简单到复杂的数据收集任务,支撑市场研究、SEO、数据驱动决策等领域的各种应用程序。
网页抓取软件的演变:从简单的脚本到复杂的机器人
图片来源:https://www.scrapingdog.com/
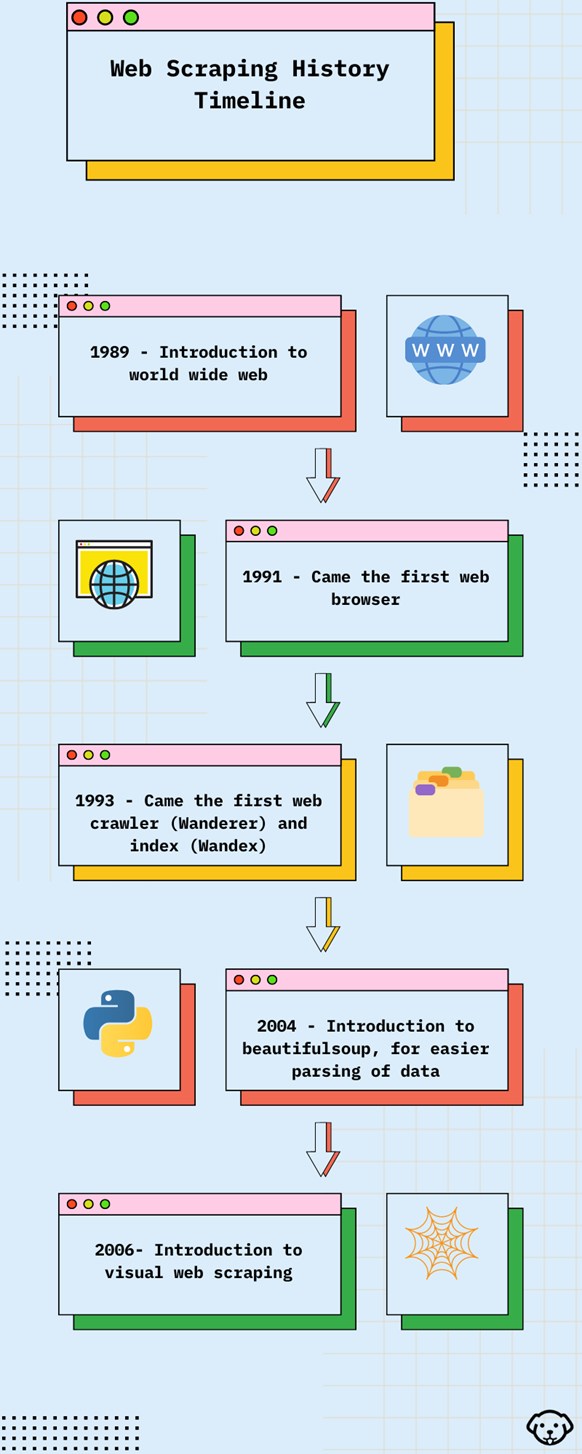
网络抓取经历了一场变革之旅。 最初,爱好者们使用了用 Perl 或 Python 等语言编写的基本脚本。 此类脚本遵循基本模式,获取网页,并通过正则表达式或简单的解析技术提取数据。 随着技术复杂性的增加,抓取工具也随之增加。
抓取工具演变成复杂的机器人,能够像人类用户一样浏览网站。 这些先进的系统包含以下功能:
- 无头浏览器,用于渲染 JavaScript 密集型网站
- 验证码解析技术,使机器人能够访问验证码保护区
- 代理轮换服务,避免IP封禁,模拟区域用户访问
- 用于自适应数据识别和提取的机器学习算法
正在进行的转变反映了网站管理员和网络抓取工具开发人员之间不断的竞争。 双方都坚持不懈地引入创新来保护或检索网络数据。
人工智能和机器学习在网页抓取软件中的集成
人工智能和机器学习的出现将网络抓取软件转变为高度智能的平台。 这些技术可以:

- 动态数据解释使软件能够理解并适应不同的网站布局和数据结构。
- 先进的模式识别,有助于有效地识别和提取相关信息。
- 增强的障碍导航,例如绕过验证码和处理复杂的 JavaScript。
- 预测分析允许企业根据抓取的数据预测趋势。
- 持续的学习能力,让软件每一次刮擦都变得更有效。
人工智能和机器学习的集成使抓取解决方案能够以更高的准确性和最少的人工干预来处理更复杂的任务。
网络抓取实践中的挑战和道德问题
网络抓取面临技术障碍,包括不断发展的网站结构和反机器人措施。 网络抓取中的道德问题也浮出水面,因为抓取者可能会侵犯版权、违反服务条款、影响网站性能并引起个人数据的隐私问题。
此外,人们对未经内容创作者同意而使用可公开访问的数据获取商业利益的公平性感到担忧。 律师、IT 专业人士和伦理学家就开放数据可用性和原创内容创作者权利保护之间的微妙平衡展开争论。
高级网页抓取对行业和市场研究的影响

图片来源:网页抓取 – 完整指南 | 提示云
在工业中,先进的网络抓取技术通过促进提取大量数据进行分析来提供显着的优势,从而带来巨大的效益。 市场研究人员利用这些工具来:
- 识别趋势:通过分析数据,他们可以发现市场动向和消费者行为模式。
- 竞争分析:企业跟踪竞争对手的价格、产品供应和市场策略。
- 客户情绪:抓取社交媒体和评论网站以评估公众意见。
- 供应链优化:监控供应商数据以改善物流。
- 有针对性的营销:更好地了解人口统计数据,开展更个性化的营销活动。
先进的网络抓取可以改进决策,促进采用战略和以数据为中心的业务方法。
网页抓取软件的未来
随着技术的进步,网络抓取软件有望实现变革性的进步。 专家预测:
- 人工智能和机器学习的集成将进一步完善数据提取,使软件更擅长解释和分析复杂的数据结构。
- 我们将开发增强型反机器人检测规避技术,以跟上更复杂的网站安全措施。
- 使用分布式网络的协作抓取将允许更有效的数据收集,减少单个服务器的负载并最大限度地降低检测风险。
- 法律和道德框架预计将不断发展,有可能在网络抓取领域产生更清晰的指导方针和标准。
- 爬虫软件可能会变得更加用户友好,迎合更广泛的受众,包括那些没有编程专业知识的人。
常见问题解答
哪种软件最适合网页抓取?
在选择网络抓取工具时,需要考虑多种因素,具体取决于目标网站的复杂程度、数据收集的规模以及个人的技术熟练程度。
大量的解决方案可以满足不同的需求,其中包括 BeautifulSoup、Scrapy 和 Selenium for Python; JavaScript 的 Puppeteer; 和 Octoparse 提供用户友好的界面,无需编码先决条件。
最终,确定最合适的选项取决于评估每个选项与您独特目标的契合程度。 尝试多种替代方案可能有助于确定理想的选择。
如何抓取整个网站?
开始抓取一个庞大网站的任务需要编写一个脚本,该脚本擅长遍历大量页面,同时准确捕获嵌入其中的相关细节。
通常,要实现这一目标,需要采用综合方法,其中包括破译 URL 参数、查找超链接、解决分页挑战以及在适用的情况下管理 cookie 管理等策略。
也就是说,在执行过程中保持谨慎仍然至关重要,因为通过积极的抓取活动或违反既定的服务条款而使服务器承受大量负载可能会导致不良后果,包括非法内容使用的过高费用和潜在的诉讼风险。
网页抓取是免费的吗?
尽管丰富的开源工具和教育材料促进了网络抓取工作,但成功实施此类项目通常需要与时间、计算能力、网络基础设施、专有软件采购或聘请精通网络抓取技术的熟练专业人员相关的支出。
此外,某些网站明确禁止抓取行为,对违规行为实施处罚,或在必要时诉诸司法措施。 因此,在开始网络抓取操作之前应始终获得事先同意,并在整个过程中保持警惕遵守道德规范。
ChatGPT 可以执行网页抓取吗?
ChatGPT 不独立执行网页抓取功能。 尽管 ChatGPT 能够理解自然语言查询并生成基于庞大学习数据库的定制回复,但它缺乏无需显式编程命令即可与外部平台交互的固有功能。
网络抓取计划的执行需要利用专门为此目的而设计的合适库或框架来编写编码脚本。 尽管如此,利用 ChatGPT 可以通过提供有关与网络抓取任务相关的基本概念的有价值的见解、建议或解释来简化开发流程的其他方面。