
Odkrywanie procesu eksploracyjnej analizy danych!
Opublikowany: 2022-06-03Zbiór danych można analizować na wiele sposobów. Proces eksploracyjnej analizy danych jest jedną z najczęściej stosowanych metod spośród dostępnych rozwiązań. Mówiąc prościej, proces obejmuje wyodrębnienie określonych punktów danych ze zbioru danych i generowanie wykresów. Wykresy te są następnie analizowane wizualnie w celu znalezienia trendów lub wzorców. Wizualizacje pomagają również w tworzeniu kopii zapasowych twierdzeń lub wniosków, aby umożliwić szybkie podejmowanie decyzji. Wyniki tych decyzji są następujące:
- Decyzje biznesowe oparte na danych
- Decyzje dotyczące przetwarzania i wykorzystywania danych.
Jaka jest rola grafów eksploracyjnych w analizie danych?
Wykresy eksploracyjne lub wizualizacje pomagają uzyskać wyraźny obraz danych. Osoby fizyczne są w stanie zrozumieć części danych za pomocą pojedynczej migawki bez konieczności ręcznego przeglądania danych – ćwiczenie, które w przeciwnym razie może zająć wiele godzin! Krok ten działa również jako prekursor decyzji typu – jakiego typu modele można zbudować lub jak można przetwarzać istniejące dane, a nawet na jakie pytania biznesowe można odpowiedzieć poprzez zrozumienie danych.
Wykonywanie eksploracyjnej analizy danych
Python i R to najpopularniejsze języki do analizy danych. Python jest najbardziej popularny wśród programistów, dzięki dostępności łatwych w użyciu bibliotek innych firm, takich jak pandas, seaborn i matplotlib.
Będziemy używać wspomnianych powyżej bibliotek do eksploracji danych dostarczonych w zestawie danych – Titanic – Machine Learning from Disaster autorstwa Kaggle. W pierwszym kroku drukujemy kilka pierwszych wierszy zestawu danych, aby zobaczyć, jak wyglądają dane.
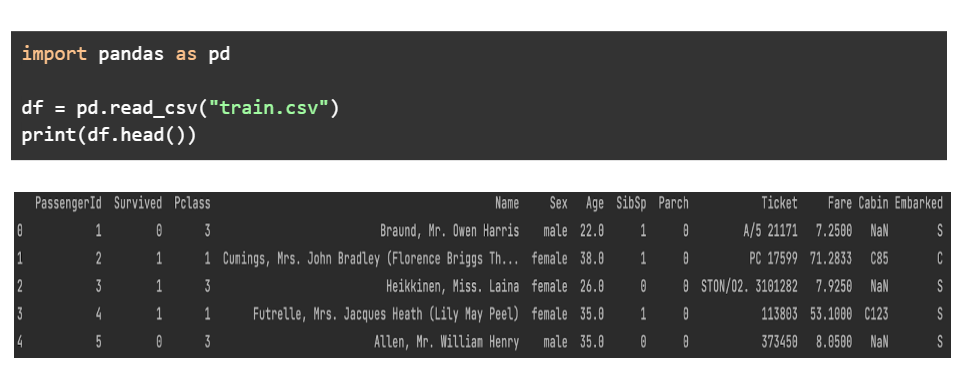
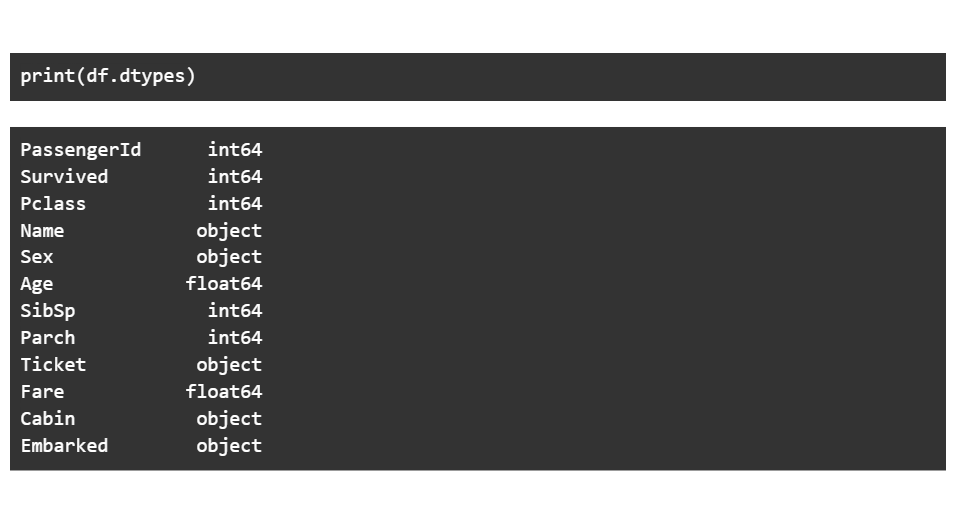
Następny krok polega na wydrukowaniu typów danych każdej kolumny. Kolumny obiektu są ciągami, kolumny zmiennoprzecinkowe zawierają wartości dziesiętne, podczas gdy kolumny int zawierają liczby.
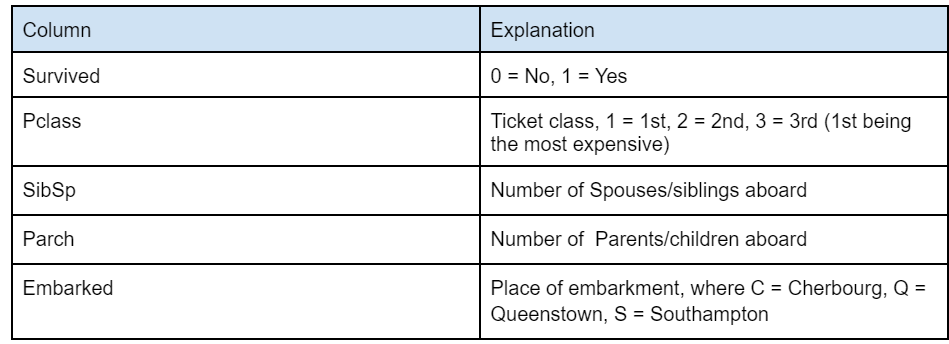
Jeśli jesteś zdezorientowany kilkoma kolumnami, które mogą nie być oczywiste, oto tabela, którą uzyskaliśmy ze strony internetowej Kaggle, która lepiej wyjaśnia te kolumny –
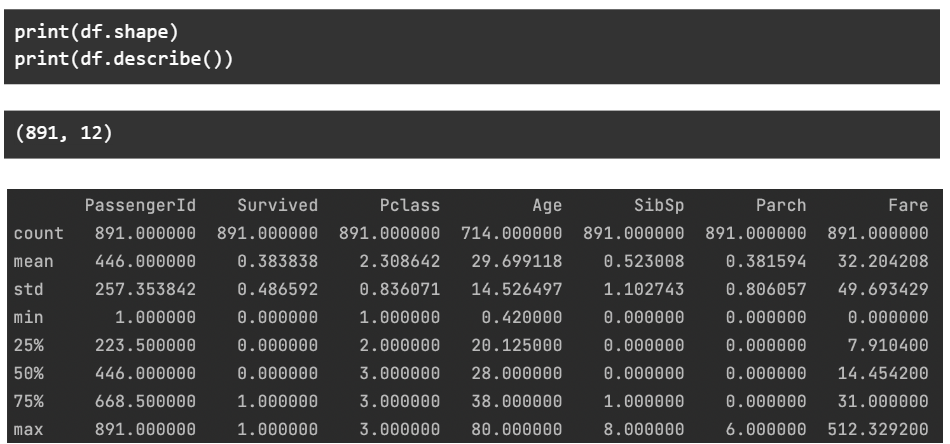
Aby dalej zagłębić się w dane, sprawdzamy kształt danych – liczbę wierszy i kolumn. Drukujemy również główne punkty danych statystycznych związane z każdą kolumną liczbową.
Ważnym aspektem tych zestawów danych jest to, jaki procent danych jest pusty. Tutaj wypisujemy liczbę pustych wpisów dla każdej kolumny –
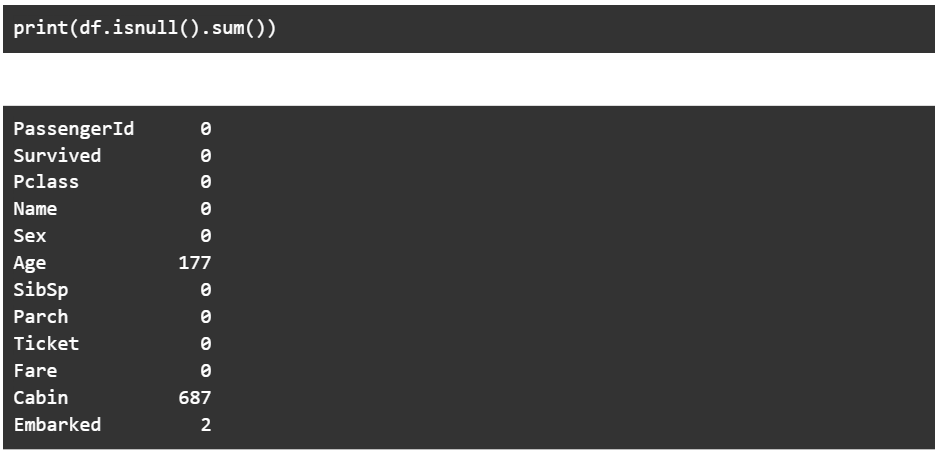
Jeśli chcesz usunąć wszystkie wiersze, w których dana kolumna ma pustą wartość, możesz użyć czegoś podobnego do poniższego kodu. Tutaj po prostu usuwamy wszystkie wiersze, w których „Wiek” jest pusty.

Następny krok obejmuje tworzenie wizualizacji z różnych kombinacji kolumn z dostępnego zestawu danych. Będziemy robić –
Analiza jednowymiarowa – Analiza pojedynczej kolumny.
Analiza dwuwymiarowa – Analiza dwóch kolumn (zwykle jedna kontra druga).
Analiza wielowymiarowa — analiza trzech lub więcej kolumn.
Jaka jest więc rola grafów eksploracyjnych w analizie danych ? W pierwszym przykładzie na podstawie naszego zbioru danych możemy zauważyć, ile osób z każdej grupy wiekowej wsiadło na pokład Titanica.

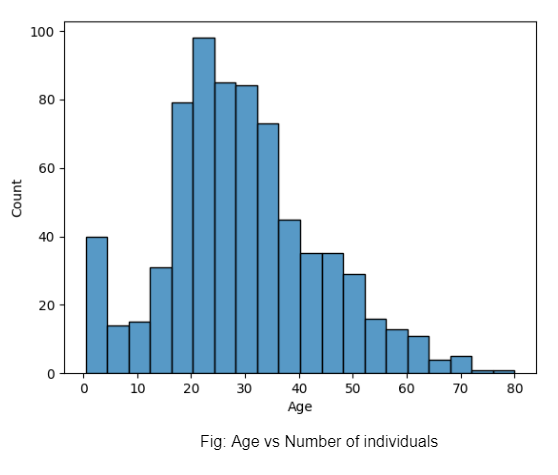
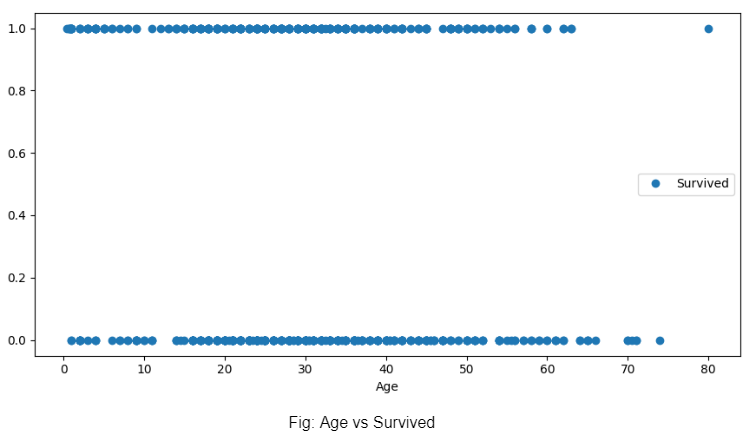
Następnie wykreślamy wykres wiek vs przeżycie i zdajemy sobie sprawę, że wiek osoby nie decydował o tym, czy przeżył wrak.


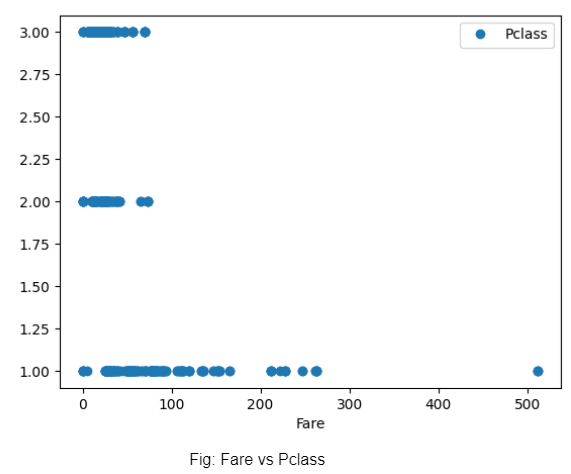
Planujemy taryfę w stosunku do klasy biletów i odkrywamy, że chociaż bilety pierwszej klasy były w niektórych przypadkach droższe, wszystkie bilety można było kupić tanio (prawdopodobnie w przypadku wcześniejszego zakupu). Natomiast ceny biletów na 3 i 2 klasę są prawie zbliżone.

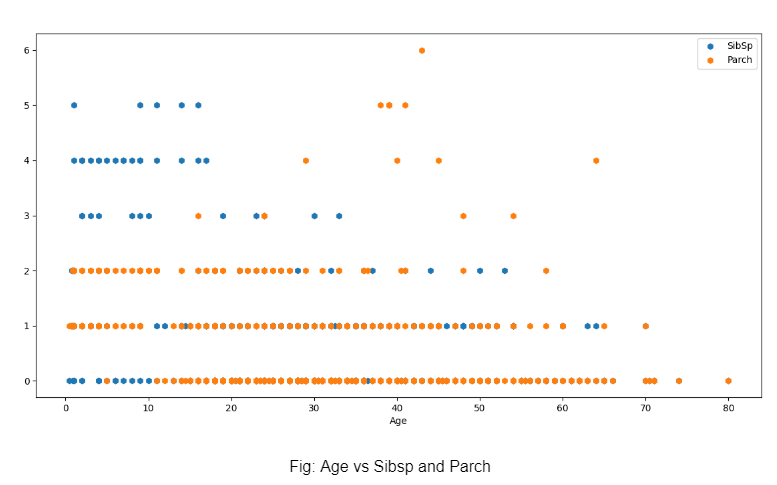
Jedyny wielowymiarowy wykres tej eksploracji przedstawia zależność Wiek vs SibSp i parch, aby dojść do wniosku, że młodsze osobniki miały większą szansę na posiadanie większej liczby rodzeństwa, co prawdopodobnie doprowadziło do wyższego SibSp. Parch był wyższy głównie w późniejszych wiekach, prawdopodobnie z powodu posiadania dzieci. Większość ma Parch tylko 1 lub 2, co wskazuje na obecność jednego z rodziców lub obu.

Wykreślając ocalałych w porównaniu z klasą, liczba tych, którzy przeżyli, jest prawie taka sama we wszystkich klasach, podczas gdy liczba zgonów jest najwyższa dla trzeciej klasy. Może to być spowodowane tym, że trzecia klasa ma największą liczbę.


Na ostatnim wykresie zestawiamy płeć względem ocalałych i zdajemy sobie sprawę, że w porównaniu z mężczyznami przeżył większy odsetek kobiet. Może to być spowodowane tym, że kobiety zostały najpierw poproszone o wejście na pokład łodzi ratunkowych.


Proces eksploracyjnej analizy danych może wyglądać jak wiele ciemnych znaków na stronie, ale wizualizacje pomagają wydobyć piękno i tajemnicę kryjącą się w danych. Właśnie dlatego analitycy danych i analitycy danych stosują analizę eksploracyjną jako podstawowy sposób oceny danych. Odbywa się to przed projektowaniem potoków danych lub systemów ETL. Wizualizacje ułatwiają korzystanie z danych, niezależnie od źródła i opisu problemu.