
Изучение процесса исследовательского анализа данных!
Опубликовано: 2022-06-03Набор данных можно анализировать несколькими способами. Процесс исследовательского анализа данных является одним из наиболее широко используемых методов среди доступных решений. Проще говоря, процесс включает в себя извлечение определенных точек данных из набора данных и создание графиков. Эти графики затем анализируются визуально, чтобы найти тенденции или закономерности. Визуализации также помогают подтверждать утверждения или выводы, чтобы обеспечить быстрое принятие решений. Результаты этих решений следующие:
- Бизнес-решения, основанные на данных
- Решения по обработке и использованию данных.
Какова роль исследовательских графиков в анализе данных?
Исследовательские графики или визуализации помогают получить четкое представление о данных. Люди могут понимать части данных с помощью одного снимка без необходимости просматривать данные вручную — в противном случае это упражнение может занять несколько часов! Этот шаг также предшествует таким решениям, как модели какого типа можно построить или как можно обрабатывать существующие данные, или даже на какие бизнес-вопросы можно ответить посредством понимания данных.
Выполнение исследовательского анализа данных
Python и R — наиболее распространенные языки для анализа данных. Python является наиболее популярным среди разработчиков благодаря наличию простых в использовании сторонних библиотек, таких как pandas, seaborn и matplotlib.
Мы будем использовать библиотеки, упомянутые выше, для изучения данных, предоставленных в наборе данных Titanic — Machine Learning from Disaster от Kaggle. На самом первом этапе мы печатаем первые несколько строк набора данных, чтобы понять, как выглядят данные.
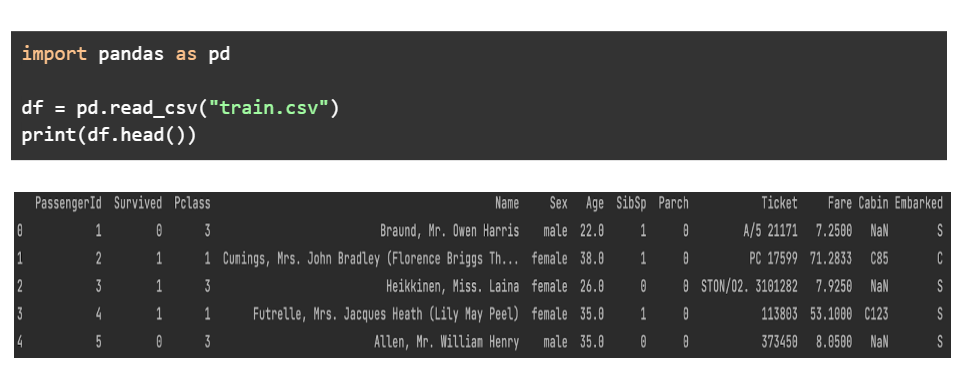
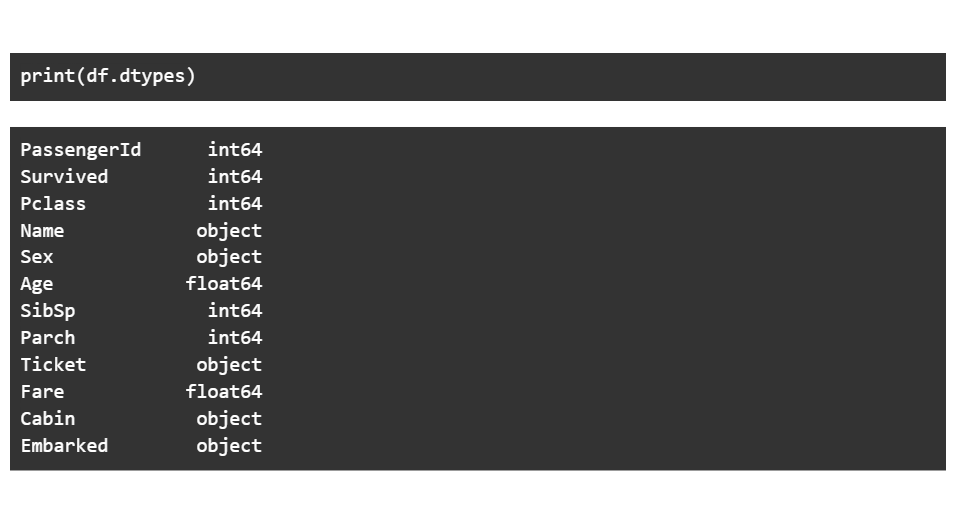
Следующий шаг включает печать типов данных каждого столбца. Столбцы объектов являются строками, столбцы с плавающей запятой содержат десятичные значения, а столбцы с целыми числами содержат числа.
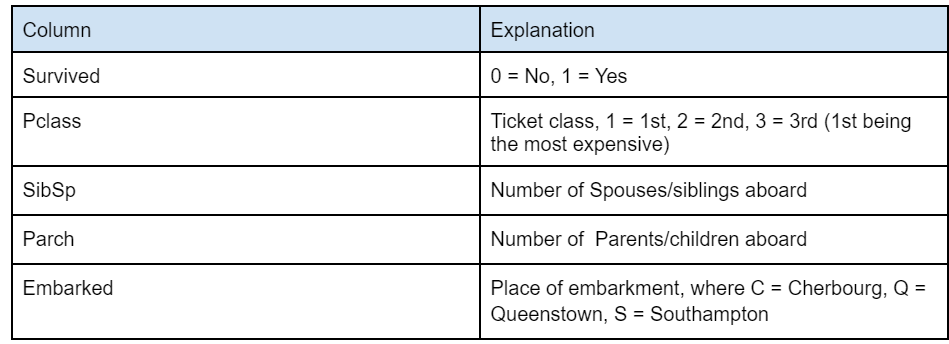
Если вы не уверены в нескольких столбцах, которые могут быть неясными, вот таблица, которую мы получили с веб-сайта Kaggle, которая лучше объясняет эти столбцы:
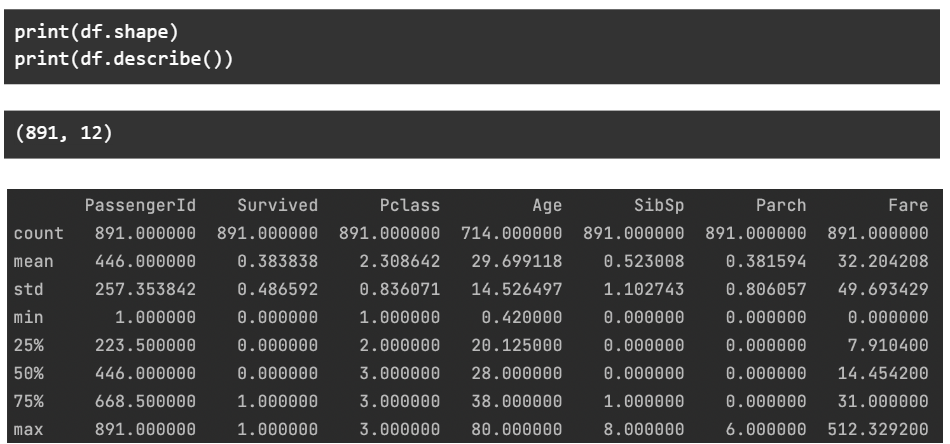
Чтобы глубже погрузиться в данные, мы проверяем форму данных — количество строк и столбцов. Мы также печатаем основные статистические данные, относящиеся к каждому числовому столбцу.
Важным аспектом этих наборов данных является то, какой процент данных пуст. Здесь мы печатаем количество нулевых записей для каждого столбца –
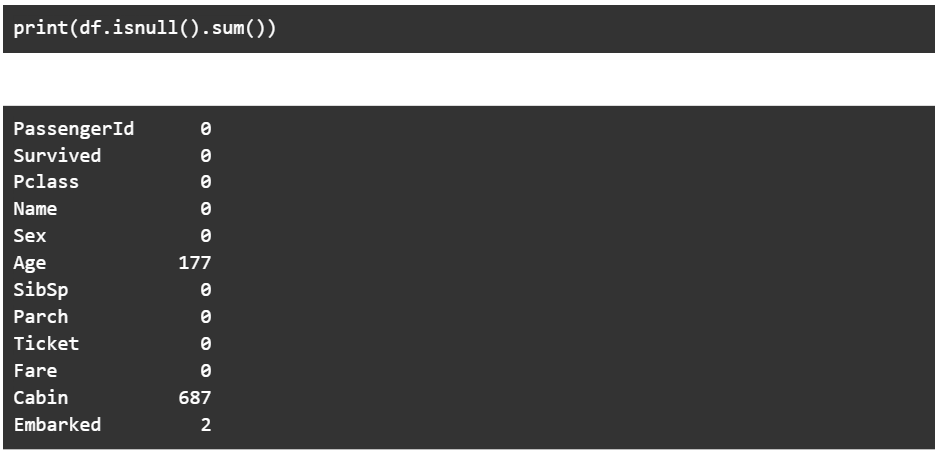
Если вы хотите удалить все строки, в которых конкретный столбец имеет пустое значение, вы можете использовать что-то вроде кода ниже. Здесь мы просто удаляем все строки, где «Возраст» пуст.

Следующий шаг включает в себя создание визуализаций из различных комбинаций столбцов из имеющегося набора данных. Мы будем делать -
Одномерный анализ — анализ одного столбца.
Двумерный анализ — анализ двух столбцов (обычно один против другого).
Многофакторный анализ — анализ трех или более столбцов.
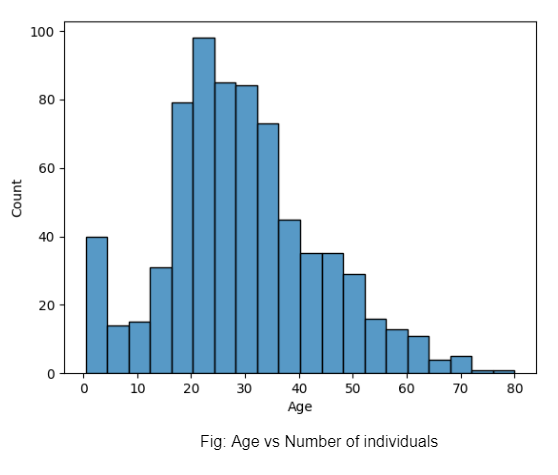
Итак , какова роль исследовательских графиков в анализе данных ? В первом примере мы можем заметить, сколько людей каждой возрастной группы сели на Титаник на основе нашего набора данных.

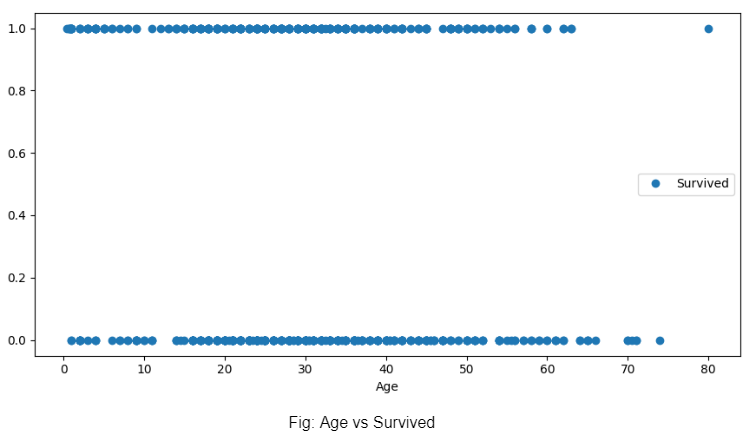
Затем мы строим график зависимости возраста от выживших и понимаем, что возраст человека не определял, выжил ли он или она в результате крушения.


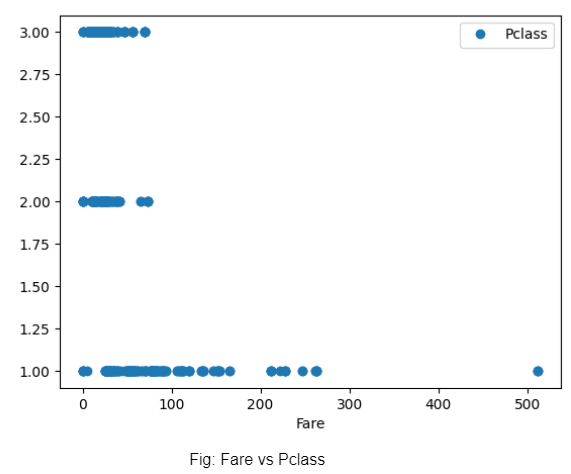
Мы сопоставляем стоимость проезда с классом билетов и обнаруживаем, что, хотя билеты 1-го класса в некоторых случаях стоили дороже, все билеты можно было купить дешево (вероятно, если бы они были куплены заранее). Однако цены на билеты 3-го и 2-го класса практически одинаковы.

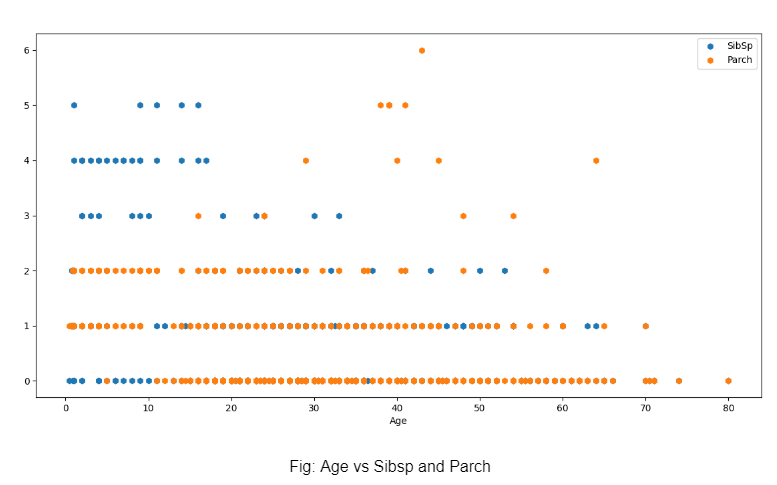
Единственным многомерным графиком этого исследования является построение зависимости возраста от SibSp и парча, чтобы прийти к выводу, что более молодые люди имеют более высокие шансы иметь больше братьев и сестер, что, вероятно, привело к более высокому SibSp. Содержание парача было выше в основном в более позднем возрасте, вероятно, из-за того, что у людей были дети. Большинство из них имеют Parch всего 1 или 2, что указывает на присутствие либо одного родителя, либо обоих.

При построении графика выживших по сравнению с классом количество выживших почти одинаково для всех классов, тогда как количество смертей является самым высоким для 3-го класса. Это может быть связано с тем, что 3-й класс имеет наибольшее количество.


На последнем графике мы сопоставляем пол с выжившими и понимаем, что по сравнению с мужчинами выжил больший процент женщин. Это могло быть связано с тем, что женщин попросили первыми сесть в спасательные шлюпки.


Процесс исследовательского анализа данных может выглядеть как множество темных пятен на странице, но визуализация помогает выявить красоту и тайну, скрытые в данных. Вот почему ученые и аналитики данных используют исследовательский анализ в качестве основного средства для оценки данных. Это делается перед проектированием конвейеров данных или систем ETL. Визуализации помогают легче использовать данные, независимо от источника и постановки задачи.