
Python을 사용하여 호텔 데이터 스크랩
게시 됨: 2018-08-212000년에 설립된 보스턴에 기반을 둔 여행 웹사이트는 전 세계에서 가장 많이 사용되는 여행 포털 중 하나입니다. 그러나 수많은 사용자와 호텔, 예약, 리뷰를 통해 생성된 여행 데이터의 규모를 이해할 수 있습니다. 그럼 그 데이터로 무엇을 하고 파이썬을 사용하여 호텔 데이터 를 긁어 내는지 봅시다 .
호텔 데이터를 스크랩 하여 어떤 이점을 얻을 수 있습니까?
우리는 거대 세계 관광 예약 산업과 관련된 몇 가지 중요한 사실을 배웠습니다. 이제 중요한 것은 크롤링 및 스크래핑을 통해 이점을 얻을 수 있는 방법입니다. 글쎄요, 웹사이트와 달리 특정 국가 또는 도시나 지역의 사람들에게만 음식을 제공할 수도 있습니다. 특히 막 사업을 시작하는 경우 모든 롯지와 호텔을 매핑하는 것이 어려울 수 있습니다. 이 사이트에서 데이터를 크롤링하면 다음과 같은 각 호텔의 다양한 세부 정보를 얻을 수 있습니다.
- 성명
- 대표이미지
- 완전한 주소
- 객실 가격대
- 등급
- 리뷰
데이터가 많기 때문에 경쟁업체의 가격을 쉽게 모니터링하고 리뷰를 통해 다양한 속성에 대해 사용자가 말하는 내용을 이해할 수 있습니다. 가격 데이터 및 고객 리뷰의 중요한 응용 프로그램은 다음과 같습니다.
- 가격 데이터를 통한 경쟁력 있는 가격 및 가격 인텔리전스
- OTA가 브랜드 가격 및 일관성을 준수하는지 확인
- 계절과 위치에 따른 재고 이동 이해
- 온라인 평판 관리를 위한 브랜드 모니터링
- 소비자 선호도 이해
오늘은 URL이 있는 경우 특정 호텔에 대해 위에서 언급한 모든 데이터를 JSON 형식으로 크롤링하는 방법을 보여 드리겠습니다.
JSON 형식의 데이터가 있으면 자체 NoSQL 데이터베이스에 저장하고 필요할 때 사용할 수 있습니다. 가격이 필요하면 가격만 접근할 수 있고, 누군가에게 대표 이미지를 보여줘야 할 때는 그렇게 하는 식이다. 이전에 스크랩한 호텔 URL 목록을 유지하여 과거 데이터를 업데이트하는 시스템을 구축하는 동안 계속 스크랩하고 데이터베이스에 추가할 수 있습니다. 이러한 대규모 시스템은 PromptCloud와 같은 숙련된 웹 스크래핑 솔루션 제공업체의 도움을 받아 구축할 수 있습니다.
그럼 기본부터 시작하겠습니다.
1. 소스 코드 편집기 설정
나중에 제공되는 코드 조각을 복사하고 편집하려면 코드 편집기 또는 IDE가 필요합니다. 둘의 기본적인 차이점은 코드 편집기를 사용하면 모든 프로그래밍 언어의 코드를 편집할 수 있으며 코드를 편집하고 저장한 후 명령 프롬프트에서 코드를 실행할 수 있다는 것입니다. 그러나 PyCharm과 같은 IDE(통합 개발 환경)에는 소스 코드 편집기, 빌드용 자동화 도구 및 디버거와 같은 옵션이 있습니다. Pycharm, Sublime 및 Atom과 같은 IDE 및 코드 편집기를 위한 여러 가지 무료 옵션이 있습니다. Atom은 다양한 프로그래밍 언어에 대한 추가 패키지 설치를 통해 IDE에서 찾을 수 있는 추가 기능을 허용하기 때문에 Atom을 시작하는 것이 더 쉽습니다. 이것은 atom- https://atom.io/에 대한 링크입니다.
그들의 웹사이트를 방문하면 그들이 이미 귀하의 운영 체제와 호환성(32비트 또는 64비트)을 감지했음을 알 수 있습니다. 그에 따라 최신 버전의 편집기를 제공합니다. 다운로드 버튼을 클릭하면 됩니다.
많은 사람들이 인기 있는 버전 관리 소프트웨어인 Git을 사용하여 코드를 추적합니다. 당신도 그것을 사용하는 경우, atom은 GitHub와 놀라운 통합을 제공합니다.
아톰 설치 파일의 용량은 약 150MB이며 다운로드 후 클릭하시면 아래와 같은 팝업창이 나옵니다. 설치가 진행되는 동안 그대로 유지되므로 1~2분 정도 기다려야 할 수 있습니다.

2. 아톰 인스톨러
Atom이 설치되면 이전에 논의한 것처럼 IDE의 일부 기능을 제공하는 일부 패키지를 설치할 수도 있습니다. 이렇게 하면 자동 완성 및 쉬운 디버그와 같은 기능을 사용하여 코딩이 더 쉬워집니다. CTRL+ 쉼표 버튼을 누릅니다(제어 버튼과 쉼표 버튼을 동시에 누르기). 또는 먼 길을 가서 File >> Settings >> Install 을 선택할 수 있습니다. 여기에서 검색 창에 Python 을 입력하고 입력할 때 제안을 제공하여 코드를 자동 완성하는 데 도움이 되는 autocomplete-python 과 같은 다양한 패키지를 직접 얻을 수 있습니다.

컴퓨터에 기존 코드 파일(예: Java 파일 또는 루비 파일)이 있는 경우 이를 원자에 로드하고 모든 것이 어떻게 보이는지 확인할 수 있습니다. Atom 에는 테마 변경과 같은 더 많은 기능이 있지만 Google의 약간의 도움으로 수행할 수 있는 탐색 부분이 남아 있습니다.
3. 파이썬 설치하기
모든 종류의 객체 지향 프로그래밍 언어에 대한 몇 가지 기본 프로그래밍 경험이 권장됩니다. 그러나 이 DIY 튜토리얼은 스크레이퍼를 실행하고 데이터를 가져오는 데 도움이 되므로 데이터를 추출하여 기본적인 이해를 얻을 수 있습니다. 설치부터 JSON 보기까지 모든 것을 다룰 것입니다.
먼저 https://www.python.org/downloads 링크를 방문해야 합니다.
Download Python 3.7.0 버튼을 클릭합니다. 표시되는 버전은 지금부터 웹사이트를 확인하는 날짜에 따라 더 높을 수 있습니다. 또한 운영 체제, Linux, Mac 또는 Windows에 따라 Python 버전이 다를 수 있습니다.
설치 파일이 다운로드되면 클릭하고 설치를 선택할 수 있습니다. 지침에 따라 Python을 설치할 위치를 선택합니다. 다음은 Python 3.7.0 의 32비트 버전 설치 파일의 스크린샷입니다. Install Now 를 클릭하기 전에 두 상자를 모두 선택했는지 확인하십시오. Python을 설치할 디렉토리를 변경하는 등의 사용자 정의를 수행하려는 경우 Customize Installation 버튼을 클릭할 수도 있습니다.
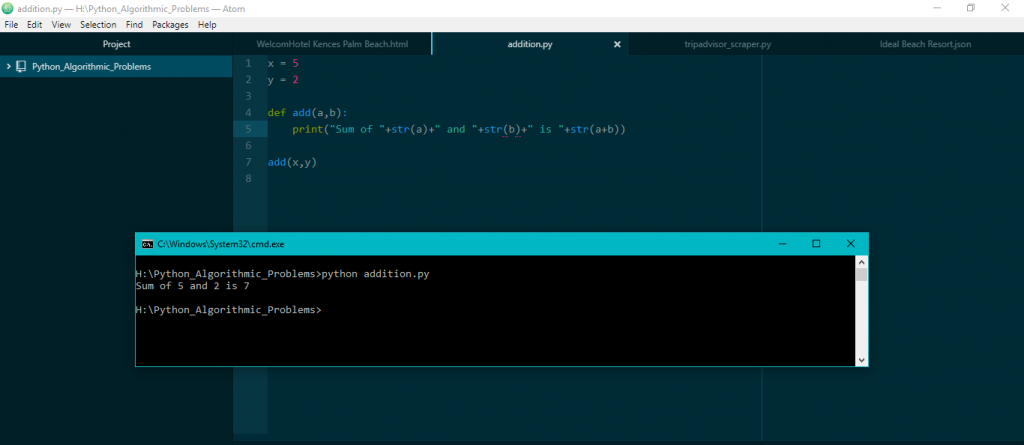
설치가 완료되면 파이썬 프로그램을 실행하여 모든 것이 잘 작동하는지 확인할 수 있습니다. 명령 프롬프트에서 파이썬 프로그램을 실행하는 데 유닉스 지식이 없어도 됩니다. python 다음에 실행하려는 파일 이름을 입력한 다음 Enter 키를 누르기만 하면 됩니다. .py 확장자는 파일이 Python 파일임을 지정하므로 모든 파일을 .py 확장자로 저장해야 합니다. 이제 두 숫자의 합을 제공하는 간단한 파이썬 프로그램을 사용해 보겠습니다. 현재 디렉토리에 addition.py .py라는 이름의 파일을 만들고 그 안에 다음 코드를 입력합니다.
[코드 언어 = "파이썬"]
x = 5
y = 2
def add(a,b):
print("+str(a)+"와 "+str(b)+"의 합은 "+str(a+b)"
더하기(x,y)
[/암호]
그런 다음 다음을 사용하여 명령 프롬프트에서 실행합니다.
[코드 언어=”python”]python 추가.py[/코드]
그러면 프로그램이 실행되고 두 숫자의 합이 표시됩니다. 빼기, 나누기 등에 대해 유사한 함수를 작성하고 파이썬의 느낌을 얻을 수 있습니다.
파이썬에서 여러 사람들이 재사용할 수 있는 기능을 만들었습니다. 이를 Python libraries 라고 합니다. 프로그램에서 가져와서 사용할 수 있지만 그렇게 하기 전에 pip 를 사용하여 해당 패키지를 설치했는지 확인해야 합니다. Pip 는 파이썬과 함께 번들로 제공되는 명령줄 패키지 관리자입니다.
이 튜토리얼에서는 Beautiful Soup 으로 더 잘 알려진 BS4 를 사용할 것입니다. HTML 및 XML 파일에서 데이터를 가져오기 위한 Python library 입니다. 모든 파서(또는 기본적으로 lxml 파서)와 함께 작동하여 구문 분석 트리를 탐색, 검색 및 수정하는 관용적 방법을 제공합니다. 이것은 한 줄의 코드를 사용하여 스크랩한 html에서 데이터를 청소하는 데 도움이 됩니다. 수동으로 이 작업을 수행하려면 며칠은 아니더라도 몇 시간이 걸렸을 것입니다.

아름다운 수프에 대한 더 많은 정보를 위한 문서 페이지는 여기 – Beautiful Soup(bs4)에서 볼 수 있습니다.
이미 시스템에 설치되어 있는 경우(이전에 누군가가 시스템에서 python을 사용한 경우) 명령줄에 다음 메시지가 표시됩니다.
"요구사항이 이미 충족됨 메시지" .
웹 크롤링 방법
이제 환경과 텍스트 편집기가 설정되었으므로 실제 업무에 착수할 수 있습니다. 특정 호텔의 웹 페이지에서 데이터를 추출하는 방법을 이해할 수 있습니다.
코드를 실행하면 URL을 입력하라는 메시지가 표시됩니다. 모든 호텔 페이지의 URL을 제공할 수 있습니다. 우리는 다음을 취할 것입니다 -
https://www..in/Hotel_Review-g1162480-d478012-Reviews-Radisson_BLU_Resort_Temple_Bay_Mamallapuram-Mahabalipuram_Kanchipuram_District_Tamil_N.html
웹 페이지를 크롤링하는 코드는 다음과 같습니다. 이 프로그램을 실행한 후 메시지가 표시되면 위에서 언급한 URL을 입력합니다. 문제 발생 시 코드 링크 –
(https://drive.google.com/open?id=19xBkg4rKTxk7Vk6-TfxnNLa9GTcVvq3a)
[코드 언어 = "파이썬"]
urllib.request, urllib.parse, urllib.error 가져오기
bs4 import BeautifulSoup에서
SSL 가져오기
json 가져오기
다시 수입
수입 시스템
sys.warnoptions가 아닌 경우 경고 가져오기:
warnings.simplefilter("ignore")#SSL 인증서 오류 무시
ctx = ssl.create_default_context()
ctx.check_hostname = 거짓
ctx.verify_mode = ssl.CERT_NONE# url = input('URL 입력 – ')
url=input("호텔 URL 입력 - ")
html = urllib.request.urlopen(url, 컨텍스트=ctx).read()
수프 = BeautifulSoup(html, 'html.parser')
html = 수프.prettify("utf-8")
호텔_json = {}
수프.find_all('script',attrs={“type” : “application/ld+json”})의 줄:
세부 정보 = line.text.strip()
세부사항 = json.loads(세부사항)
hotel_json[“이름”] = 세부정보[“이름”]
hotel_json[“url”] = “https://www.<domainname>.in”+details[“url”]
hotel_json[“이미지”] = 세부정보[“이미지”]
details["priceRange"] = details["priceRange"].replace("₩ ","Rs ")
details["priceRange"] = details["priceRange"].replace("₩","Rs ")
hotel_json[“priceRange”] = 세부사항[“priceRange”]
hotel_json["aggregateRating"]={}
호텔_json[“aggregateRating”][“ratingValue”]=details[“aggregateRating”][“ratingValue”]
hotel_json[“aggregateRating”][“reviewCount”]=details[“aggregateRating”][“reviewCount”]
호텔_json[“주소”]={}
hotel_json[“주소”][“거리”]=details[“주소”][“거리주소”]
hotel_json[“주소”][“지역”]=details[“주소”][“주소지역”]
hotel_json[“주소”][“지역”]=details[“주소”][“주소지역”]
hotel_json[“주소”][“우편번호”]=details[“주소”][“우편번호”]
hotel_json[“주소”][“국가”]=details[“주소”][“주소국가”][“이름”]
부서지다
hotel_json[“리뷰”]=[]
수프.find_all('p',attrs={"class" : "partial_entry"})의 줄:
리뷰 = line.text.strip()
검토하는 경우 != "":
리뷰 = line.text.strip()
만약 review.endswith( "More" ):
리뷰 = 리뷰[:-4]
만약 review.startswith("친애하는"):
계속하다
리뷰 = review.replace('r', ' ').replace('n', ' ')
리뷰 = ' '.join(리뷰.split())
hotel_json[“리뷰”].append(리뷰)
파일로 open(hotel_json[“name”] + “.html”, “wb”) 사용:
file.write(html)
open(hotel_json[“name”] + “.json”, 'w')을 outfile로 사용:
json.dump(hotel_json, outfile, 들여쓰기=4)
[/암호]
프로그램을 실행하고 제공된 html을 제공하면 호텔 이름과 동일한 이름의 json 파일(Radisson BLU Resort Temple Bay Mamallapuram.json)이 생성되며 다음과 같이 표시됩니다. 쉬운 사용을 위해 json에 링크 –
(https://drive.google.com/open?id=1DQxkTLVUm8UAu7ByKh7NrqK3iBjME6MQ)
[코드 언어 = "파이썬"]
{
"이름": "Radisson BLU Resort Temple Bay Mamallapuram",
"url": "https://www.<domainname>.in/Hotel_Review-g1162480-d478012-Reviews-Radisson_BLU_Resort_Temple_Bay_Mamallapuram-Mahabalipuram_Kanchipuram_District_Tamil_N.html",
"이미지": "https://media-cdn.<도메인 이름>.com/media/photo-s/03/e5/92/9b/radisson-blu-resort-temple.jpg",
"priceRange": "Rs 8,356 – Rs 36,027(표준 객실의 평균 요금 기준)",
"집계 평가": {
"등급값": "4.0",
"reviewCount": "2407"
},
"주소": {
"거리": "57 Covelong Road",
"지역": "Mahabalipuram",
"지역": "타밀 나두",
"Zip": "603104",
"국가": "인도"
},
"리뷰": [
“잘 관리된 해변의 거대한 리조트. 가장 큰 수영장 중 하나, 1에이커의 잔디, 어린이를 위한 다양한 활동, 잘 꾸며진 객실, 크리켓, 배구, 친절한 직원 및 해변의 해안 사원 전망이 있습니다. 음식은 보통입니다....”,
“이 장소는 굉장합니다. 우리는 수영장을 마주보고 있습니다. 버기는 무성한 녹색 잔디, 꽃 및 코코넛 나무 주변으로 우리를 데려갔습니다. 매우 잘 관리 된 장소. 수영장은 아마도 리조트의 가장 좋은 부분일 것입니다. 해변, 데크 공간이 아름답습니다. 서비스가 좋습니다. 우리는 리조트가…
“Radisson BLU Resort Temple Bay Mamallapuram에 대한 좋은 경험이 있습니다. 우리 팀과 함께 하루 종일 거기에있었습니다. 나는이 장소와 리조트와 연결된 해변을 좋아했습니다. 맛있는 음식 &amp; 웰컴 드링크.”,
“저는 온 가족이 함께 1일 동안 머물렀습니다. 우리는 6개의 방을 예약했고 방의 질이 너무 좋아서 가족 모두가 만족했습니다. 좋은 서비스 좋은 음식 좋은 수영장 좋은 직원. 전반적으로 매우 좋은 숙박”
]
}
[/암호]
추출된 데이터
JSON에서 여러 다른 필드를 볼 수 있습니다. 쉽게 드실 수 있도록 설명드리겠습니다. 이름 필드는 자체 설명이 가능하며 URL, 이미지 및 가격대가 뒤에 옵니다. URL은 실제로 프로그램이 요청할 때 제공한 URL과 동일합니다.

나중에 필요할 경우를 대비하여 JSON에 포함되어 있습니다. 이미지 URL은 호텔의 대표적인 이미지를 제공하고 가격대는 표준 객실을 얻을 수 있는 최소 요금과 최고의 스위트룸의 최대 비용에 대한 아이디어를 제공합니다. 주소 필드는 사용 사례에 따라 더 쉽게 필터링할 수 있도록 여러 하위 필드로 나뉩니다. 거리, 지역, 지역, 우편번호 및 국가가 모두 제공됩니다. 통합하여 하나로 사용하거나 우편번호, 국가, 지역 등으로 필터링하는 데 사용할 수 있습니다.
총 평점 필드에는 5점 만점의 평점과 호텔을 실제로 리뷰한 사람들의 수가 있습니다. 왜 둘 다 중요합니까? 호텔이 별점 4.9/5인데 10명만 리뷰한 반면 다른 호텔은 별점 4.5/5이지만 2,500명이 리뷰했다고 가정해 보겠습니다. 어떤 것을 고객이 예약할까요?
다음으로 호텔의 기본 페이지에서 최고의 리뷰로 구성된 리뷰 필드를 보게 될 것입니다. 일부 리뷰가 너무 길어 "..." 형식으로 잘린 것을 볼 수 있습니다. 프로그래밍 방식으로 이 항목을 확장하여 전체 리뷰도 표시할 수 있습니다. 이를 데이터에 사용하고 텍스트 마이닝 기술을 실행하여 호텔과 관련된 고객의 소리, 장단점을 이해할 수 있습니다.
JSON은 모든 프로그래밍 언어에서 읽을 수 있고 전 세계적으로 허용되는 표준 형식을 따르기 때문에 이 모든 데이터는 손상될 수 있고 형식이 변경될 수 있으며 원하는 대로 사용할 수 있습니다.
프로그램을 실행하면 호텔 이름의 html 파일도 생성된 것을 확인할 수 있습니다. 방금 스크랩한 html 페이지의 전체 복사본입니다. 추가 분석에 사용할 수 있으며 직접 데이터를 스크랩할 수 있습니다.
언제 웹 스크래핑 서비스 제공 업체와 함께 가야 합니까?
코딩 지식이 없는 대부분의 사람들은 전체 프로세스에 대해 여전히 확신할 수 없습니다. 이는 학습 프로세스로 사용될 수 있지만 정기적으로 대규모 데이터가 필요한 기업은 전문 크롤링 솔루션 제공업체를 선택해야 합니다. 다음은 완전 관리형 웹 스크래핑 서비스 제공업체인 PromptCloud와 같은 전문가와 협력할 때 얻을 수 있는 주요 이점입니다.
- 완전 관리형 서비스
- 완전히 사용자 정의 가능
- 강력한 SLA를 통한 전담 지원
- 짧은 대기 시간
- 높은 확장성
- 유리
면책 조항: 이 튜토리얼에서 제공하는 코드는 학습용입니다. 우리는 그것이 어떻게 사용되는지에 대해 책임을 지지 않으며 소스 코드의 해로운 사용에 대해 어떠한 책임도 지지 않습니다.