
Rôle du Web Scraping dans la recherche moderne – Un guide pratique pour les chercheurs
Publié: 2024-01-23Imaginez que vous êtes plongé dans la recherche lorsqu'un outil révolutionnaire arrive : le web scraping. Il ne s'agit pas simplement d'un simple collecteur de données ; considérez-le comme un assistant automatisé qui aide les chercheurs à collecter efficacement des informations en ligne. Imaginez ceci : des données sur des sites Web, qui sont un peu difficiles à télécharger dans des formats structurés – le web scraping intervient pour simplifier le processus.
Les techniques vont des scripts de base dans des langages comme Python aux opérations avancées avec un logiciel de scraping Web dédié. Les chercheurs doivent composer avec des considérations juridiques et éthiques, adhérer aux lois sur le droit d’auteur et respecter les conditions d’utilisation du site Web. C'est comme se lancer dans une quête numérique, armé non seulement de compétences en codage, mais aussi d'un sens des responsabilités dans le vaste domaine en ligne.
Comprendre les considérations juridiques et éthiques
Lorsque vous effectuez du web scraping à des fins de recherche, il est important de connaître certaines lois, comme la Computer Fraud and Abuse Act (CFAA) aux États-Unis et le Règlement général sur la protection des données (RGPD) dans l'Union européenne. Ces règles traitent de l'accès non autorisé aux données et de la protection de la vie privée des personnes. Les chercheurs doivent s’assurer :
- Obtenez des données à partir de sites Web accessibles au public ou avec une autorisation explicite.
- Respectez les conditions de service fournies par le site Web.
- Évitez de récupérer des données personnelles sans consentement, conformément aux lois internationales sur la confidentialité.
- Mettez en œuvre des considérations éthiques, telles que ne pas nuire aux fonctionnalités du site Web ou surcharger les serveurs.
Négliger ces aspects peut entraîner des conséquences juridiques et nuire à la réputation du chercheur.
Choisir le bon outil de scraping Web
Lors de la sélection d’un outil de web scraping, les chercheurs doivent prendre en compte plusieurs facteurs clés :
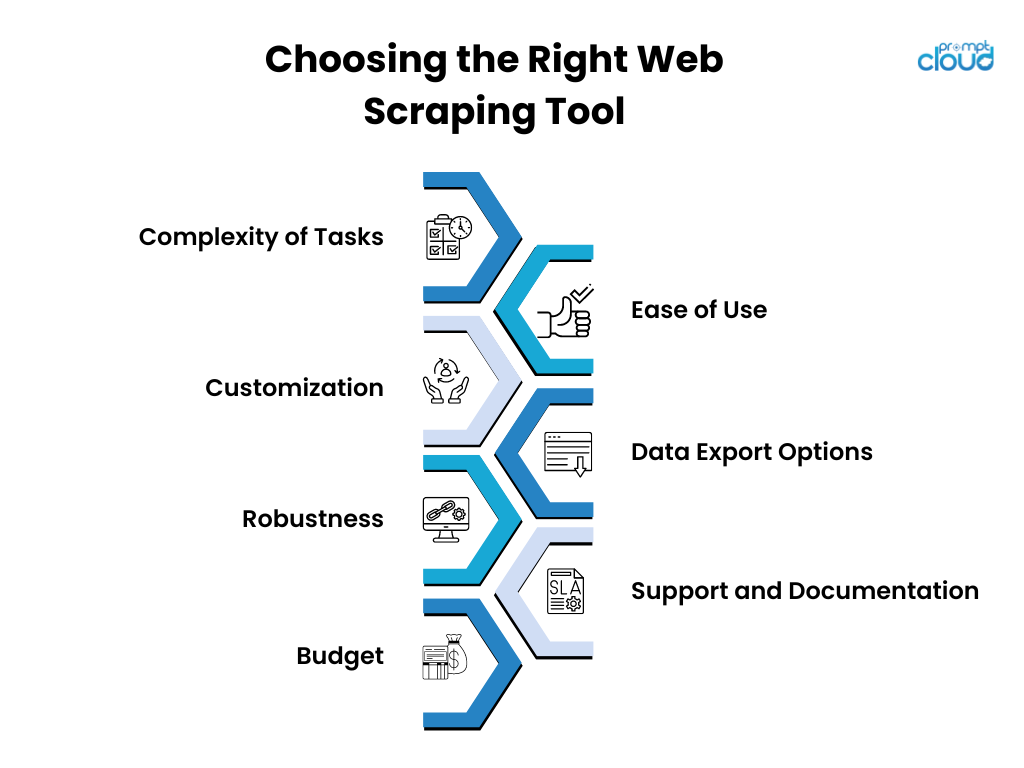
- Complexité des tâches
- Facilité d'utilisation
- Personnalisation
- Options d'exportation de données
- Robustesse
- Assistance et documentation
- Budget
En évaluant soigneusement ces aspects, les chercheurs peuvent identifier l'outil de web scraping qui correspond le mieux aux exigences de leur projet.
Méthodes de collecte de données : API vs HTML Scraping
Lorsque les chercheurs collectent des données à partir de sources Web, ils utilisent principalement deux méthodes : l’extraction API (Application Programming Interface) et le scraping HTML.
Les API servent d'interfaces proposées par les sites Web, permettant la récupération systématique de données structurées, généralement formatées en JSON ou XML. Ils sont conçus pour être accessibles par programme et peuvent fournir un moyen stable et efficace de collecte de données, tout en respectant généralement les conditions de service du site Web.
- Avantages de l'API :
- Fournit souvent des données structurées
- Conçu pour l'accès par programmation
- Généralement plus stable et fiable
- Inconvénients de l'API :
- Peut nécessiter une authentification
- Parfois limité par des limites de débit ou des plafonds de données
- Accès potentiellement restreint à certaines données
Le scraping HTML, en revanche, consiste à extraire des données directement du code HTML d'un site Web. Cette méthode peut être utilisée lorsqu'aucune API n'est disponible ou lorsque l'API ne fournit pas les données requises.
- Avantages du HTML Scraping :
- Peut accéder à toutes les données affichées sur une page Web
- Pas besoin de clés API ni d'authentification
- Inconvénients du HTML Scraping :
- Plus susceptible de se briser si la mise en page du site Web change
- Les données extraites ne sont pas structurées
- Les facteurs juridiques et éthiques doivent être pris en compte
Les chercheurs doivent choisir la méthode qui correspond à leurs besoins en données, à leurs capacités techniques et à leur conformité aux cadres juridiques.
Meilleures pratiques en matière de Web Scraping pour la recherche
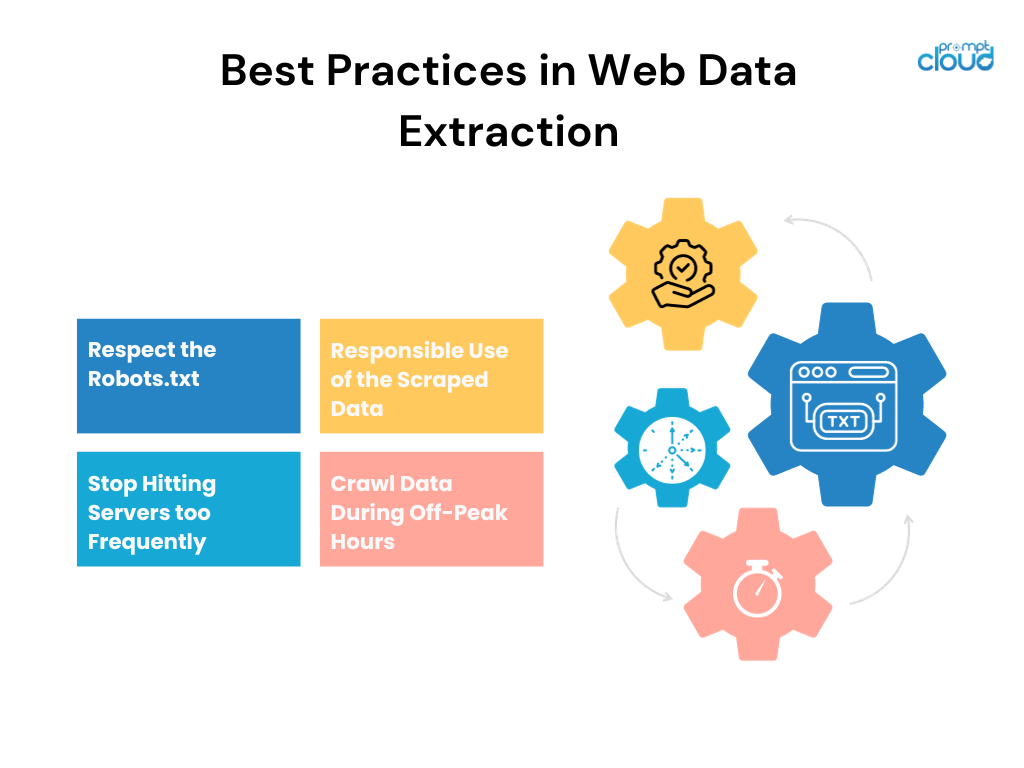
- Respectez les limites juridiques : confirmez la légalité du scraping d'un site Web et respectez les conditions d'utilisation.
- Utiliser les API lorsqu'elles sont disponibles : préférez les API fournies officiellement car elles sont plus stables et légales.
- Limiter le taux de requêtes : pour éviter la surcharge du serveur, limitez votre vitesse de scraping et automatisez les périodes d'attente polies entre les requêtes.
- Identifiez-vous : grâce à votre chaîne User-Agent, soyez transparent sur l'objectif de votre robot de scraping et vos informations de contact.
- Données en cache : enregistrez les données localement pour minimiser les demandes répétées, réduisant ainsi la charge sur le serveur cible.
- Gérer les données de manière éthique : protégez les informations privées et assurez-vous que l'utilisation des données est conforme aux réglementations en matière de confidentialité et aux directives éthiques.
- Citer les sources : attribuez correctement la source des données récupérées dans votre travail scientifique, en attribuant le crédit aux propriétaires originaux des données.
- Utilisez un code robuste : anticipez et gérez les erreurs potentielles ou les modifications dans la structure du site Web avec élégance pour maintenir l'intégrité de la recherche.
Cas d'utilisation : comment les chercheurs exploitent le Web Scraping
Les chercheurs appliquent le web scraping à divers domaines :

- Étude de marché : extraire les prix, les avis et les descriptions des produits pour analyser les tendances du marché et le comportement des consommateurs.
- Sciences sociales : grattage des plateformes de médias sociaux pour analyser l'opinion du public et étudier les modèles de communication.
- Recherche académique : Collecte de grands ensembles de données provenant de revues scientifiques à des fins de méta-analyse et de revue de la littérature.
- Analyse des données de santé : regroupement des données des patients provenant de divers forums et sites Web sur la santé pour étudier les modèles de maladie.
- Analyse concurrentielle : surveillance des sites Web concurrents pour détecter les changements de prix, de produits ou de stratégie de contenu.
Web Scraping dans la recherche moderne
Un article récent de Forbes explore l'impact du web scraping sur la recherche moderne, en mettant l'accent sur la transformation des méthodologies traditionnelles par la révolution numérique. L'intégration d'outils tels que les logiciels d'analyse de données et le web scraping ont raccourci le parcours de la curiosité à la découverte, permettant aux chercheurs de tester et d'affiner rapidement leurs hypothèses. Le web scraping joue un rôle central dans la transformation d’un Internet chaotique en un référentiel d’informations structuré, offrant une vue multidimensionnelle du paysage de l’information.
Le potentiel du web scraping dans la recherche est vaste, catalysant l’innovation et redéfinissant les disciplines, mais les chercheurs doivent relever les défis liés à la confidentialité des données, au partage éthique d’informations et au maintien de l’intégrité méthodologique pour un travail crédible dans cette nouvelle ère d’exploration.
Surmonter les défis courants du Web Scraping
Les chercheurs rencontrent souvent de nombreux obstacles lors du scraping Web. Pour contourner les structures de sites Web qui compliquent l’extraction de données, envisagez d’utiliser des techniques d’analyse avancées. Lorsque les sites Web limitent l'accès, les serveurs proxy peuvent simuler différents emplacements d'utilisateurs, réduisant ainsi le risque de blocage.
Surmontez les technologies anti-grattage en imitant le comportement humain : ajustez les vitesses et les modèles de grattage. De plus, mettez régulièrement à jour vos outils de scraping pour vous adapter à l’évolution rapide des technologies web. Enfin, assurez-vous d'un scraping légal et éthique en adhérant aux conditions d'utilisation du site Web et aux protocoles robots.txt.
Conclusion
Le web scraping, lorsqu’il est effectué de manière éthique, peut être un outil puissant pour les chercheurs. Pour exploiter sa puissance :
- Comprendre et respecter les cadres juridiques et les conditions d'utilisation du site Web.
- Mettre en œuvre des protocoles de traitement des données robustes pour respecter la confidentialité et la protection des données.
- Utilisez le scraping judicieusement, en évitant de surcharger les serveurs.
Le web scraping responsable pour la recherche équilibre la collecte d’informations pour les écosystèmes numériques. Le pouvoir du web scraping doit être utilisé de manière réfléchie, en veillant à ce qu’il reste une aide précieuse à la recherche et non une force perturbatrice.
FAQ :
Le web scraping est-il détectable ?
Oui, les sites Web peuvent détecter le web scraping à l’aide de mesures telles que le CAPTCHA ou le blocage IP, conçues pour identifier les activités de scraping automatisées. Être conscient de ces méthodes de détection et adhérer aux règles d'un site Web est crucial pour les personnes engagées dans le web scraping afin d'éviter d'être détectées et d'éventuelles conséquences juridiques.
Qu’est-ce que le web scraping comme méthode de recherche ?
Le Web scraping est une technique utilisée par les chercheurs pour collecter automatiquement des données sur des sites Web. En employant des outils spécialisés, ils peuvent organiser efficacement les informations provenant d'Internet, permettant une analyse plus rapide des tendances et des modèles. Cela rationalise non seulement le processus de recherche, mais fournit également des informations précieuses, contribuant ainsi à une prise de décision plus rapide par rapport aux méthodes manuelles.
Est-il légal d’utiliser des données récupérées sur le Web à des fins de recherche ?
La légalité de l'utilisation des données obtenues grâce au web scraping à des fins de recherche dépend des règles fixées par le site Web et des lois en vigueur sur la confidentialité. Les chercheurs doivent effectuer du web scraping d'une manière qui s'aligne sur les directives du site Web et respecte la vie privée des individus. Cette approche éthique garantit que la recherche est non seulement légale, mais maintient également sa crédibilité et sa fiabilité.
Les data scientists utilisent-ils le web scraping ?
Absolument, les data scientists s'appuient souvent sur le web scraping comme un outil précieux dans leur boîte à outils. Cette technique leur permet de rassembler un volume substantiel de données provenant de diverses sources Internet, facilitant ainsi l’analyse des tendances et des modèles. Bien que le web scraping soit avantageux, les data scientists doivent faire preuve de prudence, en s'assurant que leurs pratiques sont conformes aux directives éthiques et aux règles régissant le web scraping afin de maintenir une utilisation responsable et légale.