
Die Rolle von Web Scraping in der modernen Forschung – Ein praktischer Leitfaden für Forscher
Veröffentlicht: 2024-01-23Stellen Sie sich vor, Sie stecken mitten in der Recherche, als ein bahnbrechendes Tool auf den Markt kommt – Web Scraping. Es ist nicht nur ein normaler Datensammler; Betrachten Sie es als einen automatisierten Assistenten, der Forschern dabei hilft, Online-Informationen effizient zu sammeln. Stellen Sie sich Folgendes vor: Daten auf Websites, deren Herunterladen in strukturierten Formaten etwas schwierig ist – Web Scraping vereinfacht den Prozess.
Die Techniken reichen von einfachen Skripten in Sprachen wie Python bis hin zu fortgeschrittenen Vorgängen mit spezieller Web-Scraping-Software. Forscher müssen rechtliche und ethische Überlegungen berücksichtigen, das Urheberrecht einhalten und die Nutzungsbedingungen der Website respektieren. Es ist, als würde man sich auf eine digitale Reise begeben, nicht nur mit Programmierkenntnissen, sondern auch mit Verantwortungsbewusstsein im riesigen Online-Bereich.
Rechtliche und ethische Überlegungen verstehen
Wenn Sie zu Forschungszwecken Web-Scraping betreiben, ist es wichtig, bestimmte Gesetze zu kennen, etwa den Computer Fraud and Abuse Act (CFAA) in den Vereinigten Staaten und die Datenschutz-Grundverordnung (DSGVO) in der Europäischen Union. Diese Regeln befassen sich mit dem unbefugten Zugriff auf Daten und dem Schutz der Privatsphäre von Personen. Forscher müssen sicherstellen, dass sie:
- Beziehen Sie Daten von Websites mit öffentlichem Zugang oder mit ausdrücklicher Genehmigung.
- Beachten Sie die Nutzungsbedingungen der Website.
- Vermeiden Sie das Scrapen personenbezogener Daten ohne Zustimmung im Einklang mit internationalen Datenschutzgesetzen.
- Setzen Sie ethische Überlegungen um, z. B. darauf, die Funktionalität der Website nicht zu beeinträchtigen oder Server zu überlasten.
Die Vernachlässigung dieser Aspekte kann rechtliche Konsequenzen nach sich ziehen und den Ruf des Forschers schädigen.
Auswahl des richtigen Web-Scraping-Tools
Bei der Auswahl eines Web-Scraping-Tools sollten Forscher mehrere Schlüsselfaktoren berücksichtigen:
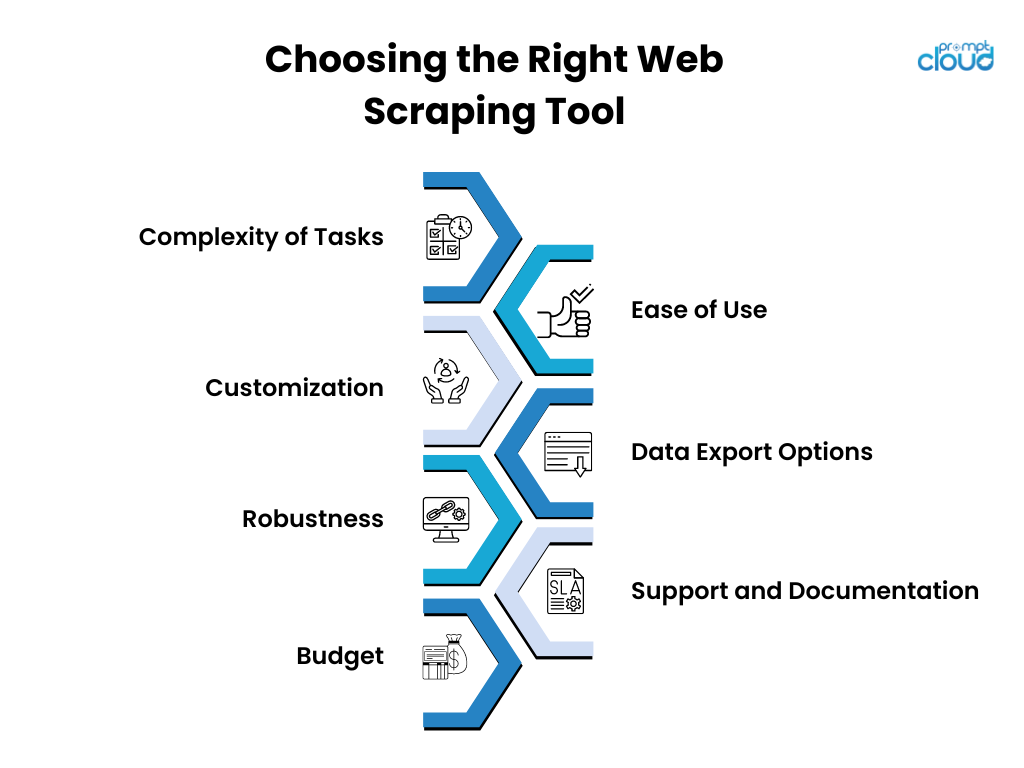
- Komplexität der Aufgaben
- Benutzerfreundlichkeit
- Anpassung
- Datenexportoptionen
- Robustheit
- Support und Dokumentation
- Budget
Durch sorgfältige Bewertung dieser Aspekte können Forscher das Web-Scraping-Tool identifizieren, das am besten zu ihren Projektanforderungen passt.
Datenerfassungsmethoden: API vs. HTML Scraping
Wenn Forscher Daten aus Webquellen sammeln, verwenden sie hauptsächlich zwei Methoden: API-Pulling (Application Programming Interface) und HTML-Scraping.
APIs dienen als von Websites angebotene Schnittstellen und ermöglichen den systematischen Abruf strukturierter Daten, die üblicherweise als JSON oder XML formatiert sind. Sie sind für den programmgesteuerten Zugriff konzipiert und können ein stabiles und effizientes Mittel zur Datenerfassung bieten, wobei in der Regel die Nutzungsbedingungen der Website eingehalten werden.
- Vorteile der API:
- Stellt oft strukturierte Daten bereit
- Entwickelt für den programmatischen Zugriff
- Im Allgemeinen stabiler und zuverlässiger
- Nachteile der API:
- Möglicherweise ist eine Authentifizierung erforderlich
- Manchmal durch Ratenbegrenzungen oder Datenobergrenzen begrenzt
- Möglicherweise eingeschränkter Zugriff auf bestimmte Daten
Beim HTML-Scraping hingegen werden Daten direkt aus dem HTML-Code einer Website extrahiert. Diese Methode kann verwendet werden, wenn keine API verfügbar ist oder die API nicht die erforderlichen Daten bereitstellt.
- Vorteile von HTML Scraping:
- Kann auf alle auf einer Webseite angezeigten Daten zugreifen
- Es sind weder API-Schlüssel noch eine Authentifizierung erforderlich
- Nachteile von HTML Scraping:
- Anfälliger für Brüche, wenn sich das Website-Layout ändert
- Die extrahierten Daten sind unstrukturiert
- Es müssen rechtliche und ethische Faktoren berücksichtigt werden
Forscher müssen die Methode wählen, die ihren Datenanforderungen, technischen Fähigkeiten und der Einhaltung gesetzlicher Rahmenbedingungen entspricht.
Best Practices beim Web Scraping für die Forschung
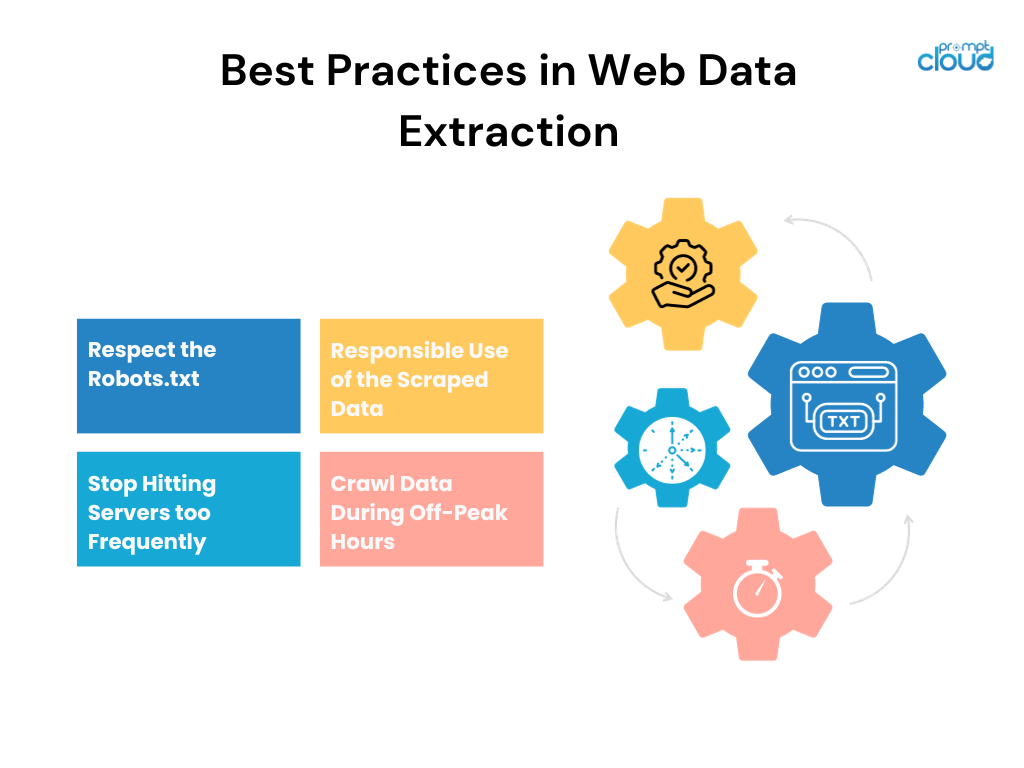
- Respektieren Sie rechtliche Grenzen : Bestätigen Sie die Rechtmäßigkeit des Scrapings einer Website und halten Sie sich an die Nutzungsbedingungen.
- APIs verwenden, wenn verfügbar : Bevorzugen Sie offiziell bereitgestellte APIs, da diese stabiler und legaler sind.
- Anfragerate begrenzen : Um eine Serverüberlastung zu vermeiden, drosseln Sie Ihre Scraping-Geschwindigkeit und automatisieren Sie höfliche Wartezeiten zwischen Anfragen.
- Identifizieren Sie sich : Machen Sie durch Ihren User-Agent-String transparent über den Zweck Ihres Scraping-Bots und Ihre Kontaktinformationen.
- Cache-Daten : Speichern Sie Daten lokal, um wiederholte Anfragen zu minimieren und so die Belastung des Zielservers zu reduzieren.
- Ethischer Umgang mit Daten : Schützen Sie private Informationen und stellen Sie sicher, dass die Datennutzung den Datenschutzbestimmungen und ethischen Richtlinien entspricht.
- Quellen zitieren : Benennen Sie die Quelle der gecrackten Daten in Ihrer wissenschaftlichen Arbeit korrekt und nennen Sie die ursprünglichen Dateneigentümer.
- Verwenden Sie robusten Code : Erwarten Sie potenzielle Fehler oder Änderungen in der Website-Struktur und gehen Sie elegant damit um, um die Forschungsintegrität aufrechtzuerhalten.
Anwendungsfälle: Wie Forscher Web Scraping nutzen
Forscher wenden Web Scraping in verschiedenen Bereichen an:

- Marktforschung : Extrahieren von Produktpreisen, Bewertungen und Beschreibungen zur Analyse von Markttrends und Verbraucherverhalten.
- Sozialwissenschaften : Durchsuchen von Social-Media-Plattformen zur Analyse der öffentlichen Stimmung und zur Untersuchung von Kommunikationsmustern.
- Akademische Forschung : Sammeln großer Datensätze aus wissenschaftlichen Zeitschriften für Metaanalysen und Literaturrecherchen.
- Analyse von Gesundheitsdaten : Aggregation von Patientendaten aus verschiedenen Gesundheitsforen und Websites zur Untersuchung von Krankheitsmustern.
- Wettbewerbsanalyse : Überwachung der Websites von Wettbewerbern auf Änderungen bei Preisen, Produkten oder Inhaltsstrategien.
Web Scraping in der modernen Forschung
Ein aktueller Artikel von Forbes untersucht die Auswirkungen von Web Scraping auf die moderne Forschung und betont die Transformation traditioneller Methoden durch die digitale Revolution. Die Integration von Tools wie Datenanalysesoftware und Web Scraping hat den Weg von der Neugier zur Entdeckung verkürzt und es Forschern ermöglicht, Hypothesen schnell zu testen und zu verfeinern. Web Scraping spielt eine entscheidende Rolle bei der Umwandlung des chaotischen Internets in einen strukturierten Informationsspeicher, der eine mehrdimensionale Sicht auf die Informationslandschaft bietet.
Das Potenzial des Web Scraping in der Forschung ist enorm, es katalysiert Innovationen und definiert Disziplinen neu, aber Forscher müssen Herausforderungen im Zusammenhang mit Datenschutz, ethischem Informationsaustausch und der Wahrung methodischer Integrität meistern, um in dieser neuen Ära der Forschung glaubwürdige Arbeit leisten zu können.
Häufige Herausforderungen beim Web Scraping meistern
Forscher stoßen beim Web Scraping oft auf mehrere Hürden. Um Website-Strukturen zu umgehen, die die Datenextraktion erschweren, sollten Sie den Einsatz erweiterter Parsing-Techniken in Betracht ziehen. Wenn Websites den Zugriff einschränken, können Proxyserver verschiedene Benutzerstandorte simulieren und so die Wahrscheinlichkeit einer Blockierung verringern.
Überwinden Sie Anti-Scraping-Technologien, indem Sie menschliches Verhalten nachahmen: Passen Sie Scraping-Geschwindigkeiten und -Muster an. Aktualisieren Sie außerdem regelmäßig Ihre Scraping-Tools, um sie an die rasante Entwicklung der Webtechnologien anzupassen. Stellen Sie schließlich das legale und ethische Scraping sicher, indem Sie die Nutzungsbedingungen der Website und die robots.txt-Protokolle einhalten.
Abschluss
Web Scraping kann bei ethischer Durchführung ein wirksames Werkzeug für Forscher sein. Um seine Kraft zu nutzen:
- Verstehen und befolgen Sie die rechtlichen Rahmenbedingungen und Nutzungsbedingungen der Website.
- Implementieren Sie robuste Datenverarbeitungsprotokolle, um Privatsphäre und Datenschutz zu respektieren.
- Setzen Sie Scraping mit Bedacht ein und vermeiden Sie eine Überlastung der Server.
Verantwortungsvolles Web-Scraping für die Forschung gleicht die Informationsbeschaffung für digitale Ökosysteme aus. Die Möglichkeiten des Web Scraping müssen mit Bedacht genutzt werden, um sicherzustellen, dass es weiterhin eine wertvolle Hilfe für die Forschung und keine störende Kraft bleibt.
FAQs:
Ist Web Scraping erkennbar?
Ja, Websites können Web Scraping mithilfe von Maßnahmen wie CAPTCHA oder IP-Blockierung erkennen, die darauf ausgelegt sind, automatisierte Scraping-Aktivitäten zu identifizieren. Die Kenntnis dieser Erkennungsmethoden und die Einhaltung der Website-Regeln ist für Personen, die Web Scraping betreiben, von entscheidender Bedeutung, um eine Entdeckung und mögliche rechtliche Konsequenzen zu vermeiden.
Was ist Web Scraping als Recherchemethode?
Web Scraping ist eine Technik, mit der Forscher automatisch Daten von Websites sammeln. Durch den Einsatz spezieller Tools können sie Informationen aus dem Internet effizient organisieren und so eine schnellere Analyse von Trends und Mustern ermöglichen. Dies rationalisiert nicht nur den Forschungsprozess, sondern liefert auch wertvolle Erkenntnisse und trägt zu einer schnelleren Entscheidungsfindung im Vergleich zu manuellen Methoden bei.
Ist es legal, Web-Scraping-Daten für Forschungszwecke zu verwenden?
Die Rechtmäßigkeit der Verwendung von durch Web Scraping gewonnenen Daten für Forschungszwecke hängt von den auf der Website festgelegten Regeln und den geltenden Datenschutzgesetzen ab. Forscher müssen Web Scraping in einer Weise durchführen, die den Richtlinien der Website entspricht und die Privatsphäre des Einzelnen respektiert. Dieser ethische Ansatz stellt sicher, dass die Forschung nicht nur legal ist, sondern auch ihre Glaubwürdigkeit und Zuverlässigkeit behält.
Nutzen Datenwissenschaftler Web Scraping?
Auf jeden Fall verlassen sich Datenwissenschaftler häufig auf Web Scraping als wertvolles Tool in ihrem Toolkit. Mit dieser Technik können sie umfangreiche Datenmengen aus verschiedenen Internetquellen sammeln und so Trends und Muster analysieren. Obwohl Web Scraping von Vorteil ist, müssen Datenwissenschaftler Vorsicht walten lassen und sicherstellen, dass ihre Praktiken mit ethischen Richtlinien und den Regeln für Web Scraping im Einklang stehen, um eine verantwortungsvolle und legale Nutzung sicherzustellen.