
Canonical标签:最佳実践、常见错误及び其の SEO 的影響响
公開: 2022-07-29どのウェブサイトでも、重複コンテンツの問題が発生する可能性があります。つまり、特定のコンテンツが重複コンテンツとして認識されていることに気付かない可能性があります。
カノニカル インデックスがない場合、インデックスは自分自身のバージョンを選択します。
この文章の中で、私は、Canonical の使用、Canonical の正しい使用方法、Canonical の使用を回避する必要があることを理解する必要があります。

クイック ナビゲーション
- 一、什么是カノニカル标签?
- 二、搜索引擎和重复内容
- 三、什么规范标签很重要?
- 四、いつ规范标签を使う
- 五、どのように页面を追加规范标签
- 1. rel=canonical <リンク> 标记
- 2. rel=canonical HTTP 标头
- 3. 点地図
- 4.CMSに规范标签を追加
- 六、Google どうやって择规范页面を選ぶ?
- 七、使用规范标签的最佳実践和常见错误
- 1) 不要直接删除非规范版本
- 2)URLの使用
- 3)向搜索引擎送信説明确的信号
- 4)表面创建链式または交叉式规范
- 5)内部で使用されていることを保証するURL
- 6) 正确的領域版本を選択
- 7)桌面版网址と移動版网址についての注意事項
- 8)规范标签&Hreflang
- 八、方法检查规范标签
- 1. 右键查看网页原始代码
- 2. Google Search Console を使用する检查
- 3.网络爬虫類工具の使用
- 总結
一、什么是カノニカル标签?
カノニカル ラベルは、そのページに複数のバージョンが存在する場合に、そのページの主要な(参照)バージョンであることを示します。
リンク ラベルを実装するための最も一般的な手法は、link rel="canonical" の文字列をページの HTML に追加することです。次に例を示します。
<link rel="canonical" href="https://example.com/sample-page/" />この番号は、ビュー ページが上記で指定された URL であることを示します。
规范标签は主に重いコンテンツを解決するために使用されます。
二、搜索引擎和重复内容
重複コンテンツの問題は、ユーザーとは異なる方法で閲覧されている爬虫類を参照するという、ある特定の出来事に起因します。
について 搜索引擎爬虫類,以下の URL は都道府県によって異なります:
- http://example.com
- https://example.com
- https://example.com/index.php
- http://example.com/index.php
- http://www.example.com
ユーザーが各ページで同じコンテンツを閲覧すると、爬虫類は、複数のページが同じコンテンツを持つように、各 URL を個別のエンティティとして認識します。
重複コンテンツの問題は、電子商取引のウェブサイトに限ったことではなく、多くのウェブサイトでは、URL に頻繁に追加され、重複コンテンツが発生する可能性があります。原因:
1. さまざまなデバイス タイプをサポートするため:
https://example.com/guide/google-seo https://m.example.com/guide/google-seo2. ユーザーがパラメーターや会議 ID などを取得するために必要なアクション テンプレート:
https://www.example.com/products?category=dresses&color=red https://www.example.com/dresses/red/reddress.html3.当您は同じ篇の博文を同時に複数のバージョンに放映し、博客系统会自动保存多彑址
https://blog.example.com/dresses/red-dresses-are-awesome/ https://blog.example.com/red-things/red-dresses-are-awesome/4. サーバー デバイスは、www/非 www http/https および仮想端末サーバーに対して同じコンテンツを提供するように構成されています。
http://example.com/red-dresses https://example.com/red-dresses http://www.example.com/red-dresses http://example.com:80/red-dresses https://example.com:443/red-dresses5.対応するブログ上で提供されたコンテンツが他のウェブサイトに転送されたコンテンツは、これらのドメイン内の元のコンテンツと完全にまたは部分的に重複しています:
https://news.example.com/red-dresses-for-every-day-155672.html(转载博文)
https://blog.example.com/dresses/red-dresses-are-awesome/3245/(原始博文)
无论に基づいて、当搜インデックス擎が重复的内容に達したとき、它们很难做出决定:
- この索引哪の页面、
- いくつかの面は、関連する键字名であり、
- 彼は、名前の信号を下の 1 つの URL に結合するか、複数のページに分割します。
この場合、Google が選択するのに役立つように、1 組の重複する面の中で最も代表的な 1 つの面を使用する必要があります。
三、什么规范标签很重要?
コンテンツの重複は 1 つの主な問題ですが、同じ (または非常に類似した) コンテンツを持つ複数の URL を取得する場合、多くの SEO 問題が発生する可能性があります。
1.検索結果中のページを指定
インデックスは、最適なユーザー エクスペリエンスを提供することを目的としています。これは、検索結果に複数のバージョンの同じ内容が表示されることがほとんどないためです。これは、この面の自然な流れを増加させ、商業利益に変換することができます。
2.增强规范页面的排名信号
他のネットワークは、ネットワーク プロトコルの異なる重複バージョンに接続する可能性があり、その結果、名前付け期間中の考慮事項のシグナルが希薄になります。
さらに、リンク インデックスは、他のネットワークからのリンクをすべてリンク インデックスに統合するため、リンク インデックスの競合は不要になります。排名または流量。
3.不鼓励抓取重复页面
インデックスを追加すると、そのページがサブページであることを認識して、これらの重複ページをより効率的に取得できる可能性が低くなります。の索引状態が影響を及ぼします。
四、いつ规范标签を使う
规范标签は SEO の重要性を認識しており、いつでも规范标签を使用していますか
1.修复网站常见的重复内容
以下のような問題がある場合は、ポリフェノールを添加する必要があります。
- さまざまな URL からアクセスできます(例: www.domain.com、domain.com、www.domain.com/index.html など)。
- 尾部斜杠 (“/”) を使用するか使用しないかを選択できます
- 大小写访问页面を区別できません
- 内容により異なる版本を提示(例:印刷版、PDFなど)
- この URL は、SSL で暗号化されていない HTTP バージョンで使用できます
2.製品の取捨選択
多くの場合、電子商取引ネットワークの典型的なフィルタリングおよび順序選択は、URL のフィルタリング文字列に追加されます。これにより、大量のコンテンツが生成されます。重複コンテンツを削除します。
3. URL中の残りのパラメータ
パラメーターが追跡に使用されず、コンテンツを変更できず、URL に重要な情報を追加しない場合、パラメーターが原因で Web サイトが完全に削除されない可能性があります。
4.追跡パラメータと会議ID
パラメータを追跡することで、アクティブまたはユーザーの移動を追跡できますが、それらはコンテンツの変更を行わないため、この変更も行われます。
5.转载内容
トランスポート コンテンツは、コンテンツのすべてのコンテンツが別のネットワークで再配信されることを意味します。
五、どのように页面を追加规范标签
多くの方法で標識を追加することができます。
1. rel=canonical <リンク> 标记
以下のコードをHTMLの繰り返しページの <head>部分に追加し、バージョンの URL を追加することができます。
<link rel="canonical" href="https://example.com" />
面 A、B、C の 3 つの重複する面があり、面 A を優先面として決定しました。
页面A:https://example.com/page-a
页面B:https://example.com/page-b
页面C:https://example.com/page-c
この場合、同じ <link rel="canonical" href="https://example.com/page-a" /> を面 A、面 B、面 C に追加します。
注意:このメソッドは HTML ページにのみ適しているため、他のタイプのドキュメントを想定している場合は、HTTP タグを使用してください。

2. rel=canonical HTTP 标头
画像 PDF のような文書には、ヘッダーの <head> 部分がないため、HTTP ヘッダーを使用してセキュリティ面を設定する必要はありません。
たとえば、複数のページを介して特定の PDF 文書が表示された場合、rel="canonical" HTTP コードを返すことができ、その PDF 文書の规范网址を Googlebot に通知します。
Link: <http://www.example.com/downloads/white-paper.pdf>; rel="canonical"注意:この解決策を使用するには、問題のあるネットワークのサーバーが必要です。
3. 点地図
Google は、すべてのサイトで 1 つのビューを選択し、それらのビューをポイントでマップすることができます。一部のネットワークは、(存在する場合) 重複ネットワークです。
4.CMSに规范标签を追加
1 )WordPressに权威の内容标签を配置する
Yoast SEO コンポーネントをインストールすることができます。これは、参照の影響を与えるコンテンツ ラベルから自動的に追加されます。
2 ) Shopifyで权威の内容标签を設定する
Shopify 自体は、製品とブログのゲストが参照の威信コンテンツ マークを追加していると考えられています。
3 )Squarespaceに权威の内容标签を配置する
Shopify の場合と同様に、Squarespace も参照ページから追加する可能性があります。
六、Google どうやって择规范页面を選ぶ?
注意してください、Googlebot は順守するのは循環の標識ではありません。
実際には、Google は現在バージョンを選択する際に、他の多くの要素を考慮します。
- 重定向
- 点地図
- URL 構造
- 内链和外链
- HTTPS プロトコルの使用
URL 検出ツールを使用して、Google が尊重されているかどうかを確認したり、さまざまなラベルを選択したりできます。
七、使用规范标签的最佳実践和常见错误
最適化された実装を循環させることは、インデックスを減らすのに役立ちます。
1) 不要直接删除非规范版本
私が重複コンテンツを発見したとき、何人かの人々は、直接重複したページまたはコンテンツを思い浮かべる可能性があります。内链または外链访问它们。
したがって、いくつかの重複ページを削除する必要がある場合は、最初に 301 をバージョンに再設定することをお勧めします。
2)URLの使用
当然のことながら、Google は対応する URL と Web サイトの URL を認識することができます。
话说,可能な限りサイト内で完全な URL を使用:
<link rel="canonical" href="https://example.com/sample-page/" />
しかたなく URL を含める
<link rel="canonical" href="/sample-page/" />
3)向搜索引擎送信説明确的信号
たとえば、特定の URL を別の URL に指定することを回避するために、説明を送信するためのシグナルを使用します。
4)表面创建链式または交叉式规范
たとえば、デバイス A、B、C、D が重複ページであり、A が優先ページであることを保証します。 C面でもB面を閲覧URLにする。
5)内部で使用されていることを保証するURL
前述のように、Google は、より強力なシグナルが別のウェブサイトを指している場合、設定された URL を選択しない可能性があります。 。
6) 正确的領域版本を選択
SSL に切り替わった後、HTTPS 以外の URL をリンクに含めないようにする必要があります。
7)桌面版网址と移動版网址についての注意事項
Google は、ウェブサイトのセットアップで個別のウェブサイトを使用することを推奨していません。 .
この場合、rel="canonical" および rel="alternate" 要素を含む <link> マークによって、2 つのネットワーク間の関係を示す必要があります。
- これは、Googlebot がモバイル バージョンの場所を検出するのに役立ちます。
- 移動バージョン上で、対応する面のバージョンへの rel="canonical" マークを追加。
たとえば、次の注記を追加:
<link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/page-1">移动版网页 (http://m.example.com/page-1) 上に、必要な注記:
<link rel="canonical" href="http://www.example.com/page-1">8)规范标签&Hreflang
Google が別のバージョンの同じコンテンツに翻訳することはありませんが、同じ複数のエリアの異なるウェブサイトで同じようなコンテンツまたは重複したコンテンツを提供する場合は、たとえば、example.fr/ と example.com/fr/ の両方が同様の法定コンテンツを表示する場合)、1 つの優先バージョンを設定し、次に rel="canonical" 要素と hreflang を使用して、検索ユーザーに正しい言語または地域を提供することを保証します网址。
八、方法检查规范标签
正規タグの追加が完了した後、追加が成功したかどうかの確認を忘れていました。
1. 右键查看网页原始代码
步段1 :在浏览器中您要检查的页面
ステップ 2 :ページ内の位置を右クリックし、[検査] または [ページ ソースの表示] を選択すると、ページのすべてのソース コードが表示されます。
ステップ 3 : Ctrl + F (Windows) または F + コマンド (Mac)。
ステップ4 : 「Canonical」の1つが表示され、黄色で表示される。何も結果が得られない場合、そのステップが設定されていないことを示す。
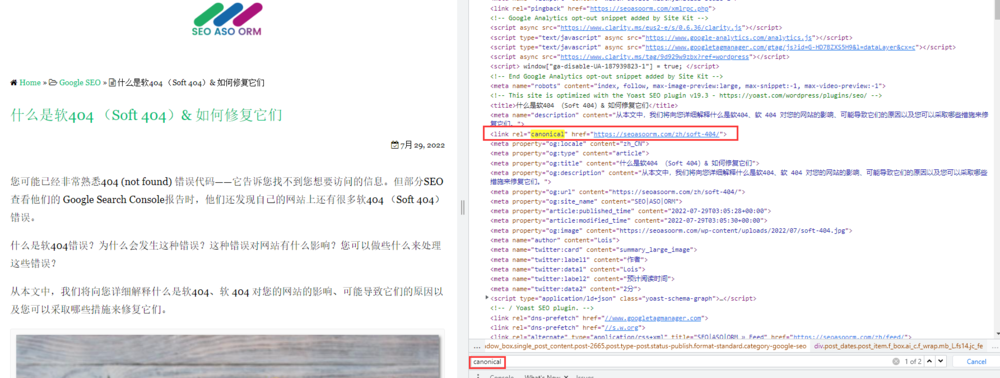
2. Google Search Console を使用する检查
Google Search Console には、インデックス インデックスと URL スキャン ツールが含まれています。
2.1.過払い率の報告
Google Search Console のオーバーレイ率レポートは、特定の URL がインデックスに登録されているかどうかに関する重要な情報源です。一部の URL はインデックスに登録されています。
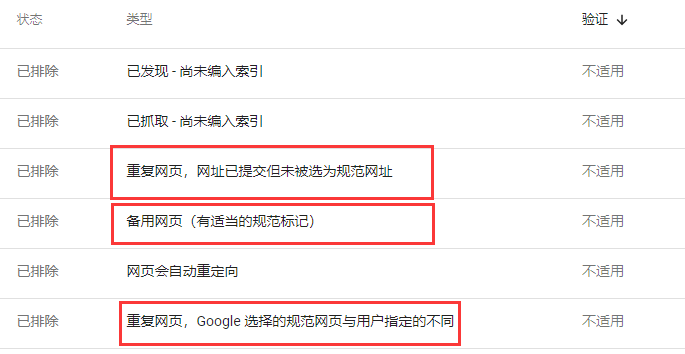
科学者の調査を分析し、科学者を拒否するために、次のいくつかと科学化に関連する状態を観察する必要があります。
1 )重复网页,网址已提交しかし规范网址に選ばれず
これは、Google が XML のポイントマップでそれを発見し、それが重複ページであると判断したことを意味します。
2 )备用网页(有适当规范标记)
このステータスの付いた URL は、Google に敬意を表して URL が変更されたことを示しています。
3 )重复网页,Googleが選択した规范网页とユーザー指定の異なる
このステータスは、Google が選択されたカスタマイズされたネットワークを無視したことを示しています。
2.2.网址检查工具
您は、ウェブ調査ツールを使用して、Googlebot がインデックスで拒否されたウェブサイトをどのように閲覧するかをさらに調べることができます。
- 上の次の取得日 – Googlebotが次のページを取得するまでの時間。
- ユーザーが宣言した詳細 – これは、選択された URL を示しています – 正しいURLかどうかを確認します。
- Googleが選択したページ– Google が別のビュー ページを選択した場合、選択された URL が表示される場合があります。
3.网络爬虫類工具の使用
スクリーミングフロッグに似たツールを使用して、非表示面と非表示面の比率に関する詳細情報を提供することができます。
总結
リンクを追加すると、レポート インデックスに含まれる URL が重複コンテンツの最適なバージョンであることがわかります。結果中。
ただし、Google は、Canonical ラベルを追加する過程で、追加されたラベルを無効にするさまざまなラベルを簡単に表示します。したがって、本書の最適な実践が行われます。