
Jarvis Rising – Google 如何“即時”生成機器學習模型來預測搜索無法預測的答案,以及如何索引這些模型以預測未來查詢的答案 [專利]
已發表: 2023-07-13
在分析了與 PAA 和 PASF 相關的 Google 專利後,我開始審查其他最近授予的專利。 不久之後,我又發現了另一個關於機器學習模型的使用的非常有趣的問題。 我剛剛分析的專利側重於使用和/或生成機器學習模型來響應查詢(當谷歌需要預測答案時,因為標準搜索結果無法提供足夠的答案)。 在多次閱讀該專利後,它強調了谷歌的系統在需要為用戶提供高質量答案(或預測)時的複雜程度。
與任何專利一樣,我們永遠不知道谷歌是否真正實現了該專利所涵蓋的內容,但這總是有可能的。 如果它得以實現,谷歌不僅可以利用訓練有素的機器學習模型來幫助預測查詢的答案,而且可以索引這些機器學習模型,將它們與各種實體、網頁等相關聯,然後檢索和檢索使用這些模型進行後續相關搜索。 想想這對谷歌來說有多麼強大和可擴展。
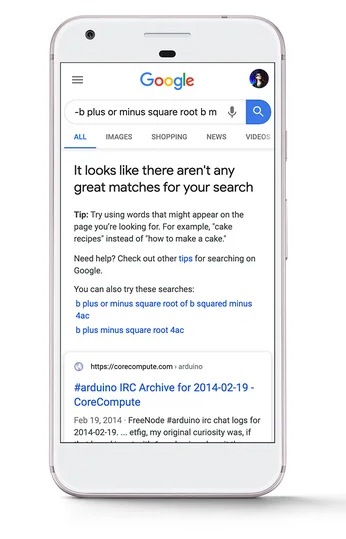
此外,該專利還解釋說,谷歌可以在搜索結果中向機器學習模型返回一個交互式界面,使用戶能夠添加參數,當搜索結果不充分時,這些參數可用於生成查詢預測。 專利的這一部分讓我想起了谷歌在 2020 年 4 月在 SERP 中推出的消息,當時沒有為查詢返回高質量的搜索結果。 當前的實現沒有提供供用戶交互的表單,但在某些時候肯定可以。 也許該界面將來可以用於更多查詢,而不僅僅是目前顯示的更模糊的查詢。 我將在下面的項目符號中詳細介紹這一點。
該專利的要點:
與我上一篇文章介紹最近的谷歌專利類似,我認為介紹細節的最佳方法是提供關鍵點的要點。
生成和/或利用機器學習模型來響應搜索請求
美國 11645277 B2
授予日期:2023 年 5 月 9 日
提交日期:2017 年 12 月 12 日
受讓人名稱:Google LLC
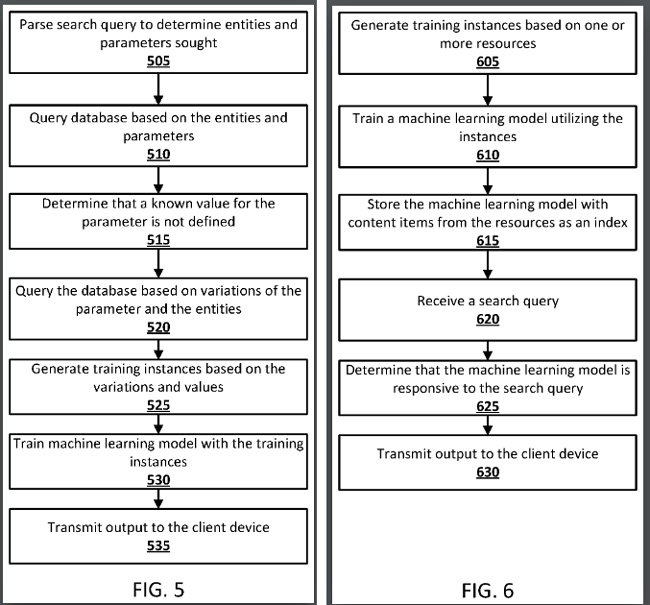
1. 谷歌的專利解釋說,如果無法確定地找到答案,並且用戶提交的請求本質上是預測性的,則可以使用經過訓練的機器學習模型來生成預測。
2. 例如,Google 可以首先根據查詢生成搜索結果,但如果結果質量不夠,則可以使用機器學習模型來提供更強的預測答案。 因此,當谷歌無法驗證答案時,系統可以根據機器學習模型提供預測答案。

3. 此外,機器學習模型可以“即時”生成,Google 可能會將經過訓練的機器學習模型存儲在搜索索引中。 是的,谷歌可以索引剛剛經過訓練以根據特定類型的查詢提供預測的機器學習模型。 我很快就會介紹更多相關內容。

4. 該專利提供了一個基於查詢“2050年中國將有多少醫生?”的示例。 如果無法通過標準搜索結果提供權威答案,則可以將查詢傳遞給經過訓練的機器學習模型以生成預測。


5. 該專利接著解釋說,該系統可能需要其他年份,如 2010 年、2015 年、2020 年等,並使用這些年份來生成預測(通過根據這些參數訓練的機器學習模型)。
6. 該專利解釋說,經過訓練的機器學習模型可以通過“用於訓練模型的資源”中的一個或多個內容項進行索引。 對於未來的查詢,當系統識別與機器學習模型相關的參數時(例如,如果後續用戶詢問類似“ 2040 年中國有多少醫生?”之類的相關問題),機器學習模型可以用於生成預測。

7. 該專利接著解釋說,機器學習模型可以與一個或多個內容項一起存儲,例如知識圖中的實體、表名稱、列名稱、網頁名稱等。 此外,機器學習模型可以使用與查詢相關的單詞(例如“中國”和“醫生”)來生成預測。
8. 該專利接著解釋說,該系統可能會提供一個交互式界面,供用戶選擇可傳遞給機器學習模型的參數。 這可以是文本字段、下拉菜單等。此外,響應可以包括向用戶呈現的消息,表明該響應是基於經過訓練的機器學習模型的預測。 因此,谷歌希望確保用戶理解這是基於機器學習模型的預測,而不是基於其索引的數據提供的答案。

9. 然後可以驗證經過訓練的模型,以確保預測至少達到“閾值質量”。 低於特定閾值的任何內容都可以被抑制並且不提供給用戶。 在這種情況下,可以改為顯示標準搜索結果。

10. 除了公共搜索結果之外,該專利還解釋說,該系統可以在私人數據庫上使用,以幫助公司預測某些結果。 該專利解釋說,“僅供一組用戶、一家公司和/或其他受限群體使用。” 例如,遊樂園的員工可能會問:“明天我們會賣多少個雪糕筒?” 然後,系統可以查詢私人數據庫以了解前幾天的銷售情況、天氣信息、出勤數據等,從而為員工預測答案。
11. 該專利解釋說,該系統可以在某個時候提供來自“自動助理”的推送通知。 只是大聲思考,我想知道這是否可能來自賈維斯式的助手,就像我在關於谷歌紅色代碼的文章中解釋的那樣,它觸發了出版商的數千個紅色代碼。

12. 從延遲的角度來看,該專利解釋說,用戶提交查詢後可能會出現延遲。 當發生這種情況時,標準搜索結果最初可能會與一條消息一起顯示,該消息表明“好的”結果不可用於查詢,並且正在使用機器學習模型來生成預測。 在這些情況下,系統可以稍後將該預測推送給用戶,或者提供超鏈接供用戶單擊以查看機器學習輸出。
13. 此外,該專利還指出,在某些情況下,用戶必須確認提示才能繼續該過程。 例如,系統可能會提供一條消息,指出“沒有好的答案。 要我給你預測一下答案嗎?” 然後,僅當響應提示而收到肯定的用戶輸入時,機器學習模型才會被訓練。 就像我之前解釋的那樣,我看到了與 2020 年 4 月推出的“沒有適合您的搜索的完美匹配”消息的聯繫。我想知道將來是否可以擴展以利用此模型......

摘要:谷歌可以通過(索引)機器學習模型以強大且超高效的方式預測高質量答案。
儘管我們不知道是否使用了任何特定專利,但這一過程的力量和效率對谷歌來說非常有意義。 從“即時”生成機器學習模型到為這些模型建立索引以供將來使用,再到利用帶有推送通知的交互式界面,谷歌似乎正在為像賈維斯這樣的助手奠定基礎。 因此,下次你要求谷歌預測答案時,請考慮一下這項專利。 並且可能會在某個時候提示您提供更多信息(直到賈維斯可以在一納秒內完成所有這些)。 :)
GG