
Jarvis Rising – Cum ar putea Google să genereze un model de învățare automată „din mers” pentru a prezice răspunsuri atunci când Căutarea nu poate și cum ar putea indexa acele modele pentru a prezice răspunsuri pentru interogări viitoare [Patent]
Publicat: 2023-07-13
După ce am analizat un brevet Google legat de PAA și PASF, am început să examinez alte brevete recent acordate. Și nu a trecut mult până când am scos la suprafață un altul foarte interesant în ceea ce privește utilizarea modelelor de învățare automată. Brevetul pe care tocmai l-am analizat se concentrează pe utilizarea și/sau generarea unui model de învățare automată ca răspuns la o interogare (când Google trebuie să prezică un răspuns, deoarece rezultatele căutării standard nu au putut oferi un răspuns adecvat). După ce a citit brevetul de mai multe ori, a subliniat cât de sofisticate ar putea fi sistemele Google atunci când trebuie să ofere un răspuns (sau predicție) de calitate pentru utilizatori.
Ca în cazul oricărui brevet, nu știm niciodată dacă Google a implementat cu adevărat ceea ce acoperă brevetul, dar este întotdeauna posibil. Și dacă ar fi fost implementat, Google nu numai că ar putea folosi un model de învățare automată antrenat pentru a ajuta la prezicerea unui răspuns la o interogare, dar poate indexa acele modele de învățare automată, le poate asocia cu diverse entități, pagini web etc. și apoi poate prelua și utilizați acele modele pentru căutările ulterioare asociate. Gândiți-vă cât de puternic și scalabil poate fi pentru Google.
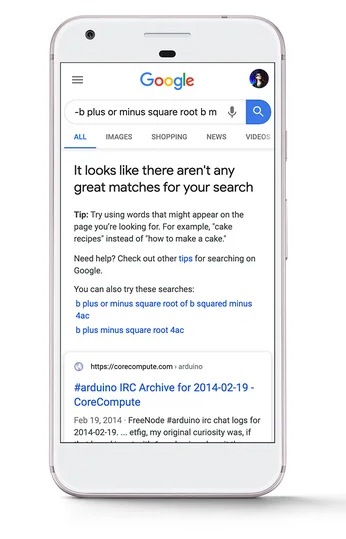
În plus, brevetul explică că Google poate returna o interfață interactivă modelului de învățare automată în rezultatele căutării, ceea ce le permite utilizatorilor să adauge parametri care pot fi utilizați pentru a genera o predicție pentru interogări atunci când rezultatele căutării nu sunt suficiente. Acea parte a brevetului m-a făcut să mă gândesc la mesajul lansat de Google în SERP-urile în aprilie 2020, când nu sunt returnate rezultate de căutare de calitate pentru o interogare. Implementarea actuală nu oferă un formular cu care să interacționeze utilizatorii, dar cu siguranță ar putea la un moment dat. Și poate că acea interfață ar putea fi folosită pentru mai multe interogări în viitor față de cele mai obscure pe care le apare pentru moment. Voi acoperi mai multe despre asta în marcatoarele de mai jos.
Puncte cheie ale brevetului:
Similar cu ultima mea postare care acoperă un brevet Google recent, cred că cea mai bună modalitate de a acoperi detaliile este să furnizez gloanțe cu punctele cheie.
Generarea și/sau Utilizarea unui model de învățare automată ca răspuns la o solicitare de căutare
US 11645277 B2
Data acordării: 9 mai 2023
Data depunerii: 12 decembrie 2017
Numele cesionarului: Google LLC
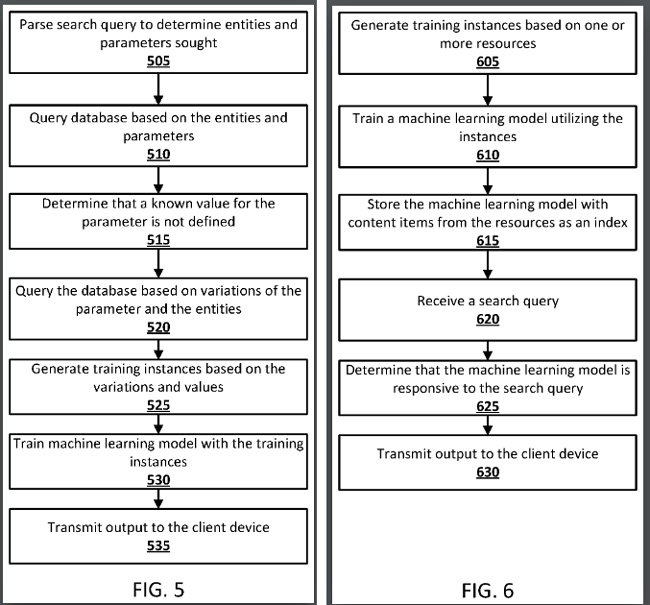
1. Brevetul Google explică că, dacă un răspuns nu poate fi localizat cu certitudine, iar utilizatorul trimite o solicitare care este de natură predictivă, un model de învățare automată antrenat poate fi utilizat pentru a genera o predicție.
2. De exemplu, Google ar putea genera mai întâi rezultate de căutare pe baza unei interogări, dar dacă rezultatele nu sunt de o calitate suficientă, atunci un model de învățare automată poate fi utilizat pentru a oferi un răspuns previzionat mai puternic. Deci, sistemul poate oferi răspunsuri prezise pe baza unui model de învățare automată atunci când un răspuns nu poate fi validat de Google.

3. De asemenea, modelul de învățare automată poate fi generat „din mers”, iar Google ar putea stoca modele de învățare automată instruite într-un index de căutare. Da, Google ar putea indexa modele de învățare automată care tocmai au fost instruite pentru a oferi predicții bazate pe anumite tipuri de interogări. Voi acoperi mai multe despre asta în curând.

4. Brevetul a oferit un exemplu bazat pe întrebarea „Câți medici vor fi în China în 2050?” Dacă un răspuns cu autoritate nu poate fi furnizat prin rezultatele căutării standard, atunci interogarea poate fi transmisă unui model de învățare automată antrenat pentru a genera o predicție.

5. Brevetul continuă să explice că sistemul ar putea dura alți ani, cum ar fi 2010, 2015, 2020 etc. și să îi folosească pentru a genera o predicție (prin intermediul unui model de învățare automată antrenat pe acești parametri).

6. Brevetul explică faptul că modelele de învățare automată instruite pot fi indexate după unul sau mai multe elemente de conținut din „resurse utilizate pentru a antrena modelul”. Și pentru interogări viitoare, atunci când sistemul identifică parametrii care sunt legați de un model de învățare automată (de exemplu, dacă un utilizator ulterior pune o întrebare similară, cum ar fi „Câți doctori sunt în China în 2040 ?”), modelul de învățare automată ar putea fi folosit pentru a genera o predicție.

7. Brevetul explică în continuare că modelele de învățare automată ar putea fi stocate cu unul sau mai multe elemente de conținut, cum ar fi entități dintr-un grafic de cunoștințe, nume de tabel, nume de coloane, nume de pagini web și multe altele. În plus, cuvintele asociate cu interogarea precum „China” și „medici” ar putea fi folosite de modelul de învățare automată pentru a genera o predicție.
8. Brevetul explică în continuare că sistemul ar putea oferi o interfață interactivă pentru ca utilizatorii să selecteze parametrii care pot fi transferați modelului de învățare automată. Acesta poate fi un câmp de text, un meniu derulant etc. De asemenea, răspunsul ar putea include un mesaj prezentat utilizatorului că răspunsul este o predicție bazată pe un model de învățare automată antrenat. Așadar, Google vrea să se asigure că utilizatorii înțeleg că este o predicție bazată pe un model de învățare automată versus răspunsurile furnizate pe baza datelor pe care le-a indexat.

9. Modelul antrenat poate fi apoi validat pentru a se asigura că predicțiile au cel puțin o „calitate de prag”. Orice lucru sub un anumit prag poate fi suprimat și nu furnizat utilizatorului. În acest caz, rezultatele căutării standard pot fi afișate în schimb.

10. Dincolo de rezultatele căutării publice, brevetul explică faptul că sistemul ar putea fi utilizat într-o bază de date privată pentru a ajuta companiile să prezică anumite rezultate. Brevetul explică: „privat pentru un grup de utilizatori, o corporație și/sau alte seturi restricționate”. De exemplu, un angajat al unui parc de distracții ar putea întreba „câte conuri de zăpadă vom vinde mâine?” Sistemul ar putea interoga apoi o bază de date privată pentru a înțelege vânzările din zilele anterioare, informații despre vreme, date despre prezență etc., pentru a prezice un răspuns pentru angajat.
11. Brevetul explică că sistemul ar putea furniza notificări push de la un „asistent automat” la un moment dat. Și doar gândindu-mă cu voce tare, mă întreb dacă ar putea fi de la un asistent asemănător Jarvis, așa cum am explicat în postarea mea despre Code Red de la Google, care a declanșat mii de Code Reds la editori.

12. Din punct de vedere al latenței, brevetul explică că ar putea exista o întârziere după ce un utilizator trimite o interogare. Când se întâmplă acest lucru, rezultatele căutării standard ar putea fi afișate inițial împreună cu un mesaj că rezultatele „bune” nu sunt disponibile pentru interogare și că este utilizat un model de învățare automată pentru a genera o predicție. În aceste situații, sistemul ar putea transmite acea predicție către utilizator mai târziu sau poate oferi un hyperlink pentru ca utilizatorii să facă clic pentru a vedea rezultatul învățării automate.
13. De asemenea, brevetul spune pentru unele situații că utilizatorul ar trebui să confirme promptul pentru ca procesul să continue. De exemplu, sistemul poate furniza un mesaj care să spună: „Nu este disponibil un răspuns bun. Vrei să-ți prezic un răspuns?” Apoi, modelul de învățare automată va fi antrenat numai dacă se primește o intrare afirmativă a utilizatorului ca răspuns la solicitare. După cum am explicat mai devreme, văd o legătură cu mesajul „Nu există potriviri grozave pentru căutarea ta” care a fost lansat în aprilie 2020. Mă întreb dacă s-ar putea extinde pentru a utiliza acest model în viitor...

Rezumat: Google ar putea prezice răspunsuri de calitate într-un mod puternic și super-eficient prin intermediul modelelor de învățare automată (indexate).
Deși nu știm dacă este folosit vreun brevet specific, puterea și eficiența acestui proces are foarte mult sens pentru Google. De la generarea de modele de învățare automată „din mers” la indexarea acelor modele pentru utilizare ulterioară până la utilizarea unei interfețe interactive cu notificări push, Google pare să pregătească scena pentru un asistent precum Jarvis. Deci, data viitoare când cereți Google să prezică un răspuns, gândiți-vă la acest brevet. Și s-ar putea să vi se solicite mai multe informații la un moment dat (până când Jarvis poate face toate acestea într-o nanosecundă). :)
GG