
การเอาชนะความท้าทายทางเทคนิคในการขูดเว็บ: โซลูชันจากผู้เชี่ยวชาญ
เผยแพร่แล้ว: 2024-03-29การขูดเว็บเป็นแนวทางปฏิบัติที่มาพร้อมกับความท้าทายทางเทคนิคมากมาย แม้แต่กับนักขุดข้อมูลที่มีประสบการณ์ก็ตาม มันเกี่ยวข้องกับการใช้เทคนิคการเขียนโปรแกรมเพื่อรับและดึงข้อมูลจากเว็บไซต์ ซึ่งไม่ใช่เรื่องง่ายเสมอไปเนื่องจากธรรมชาติของเทคโนโลยีเว็บที่ซับซ้อนและหลากหลาย
นอกจากนี้ เว็บไซต์จำนวนมากยังมีมาตรการป้องกันเพื่อป้องกันการเก็บเกี่ยวข้อมูล ทำให้จำเป็นสำหรับโปรแกรมขูดในการเจรจากลไกป้องกันการคัดลอก เนื้อหาแบบไดนามิก และโครงสร้างเว็บไซต์ที่ซับซ้อน
แม้ว่าวัตถุประสงค์ของการได้มาซึ่งข้อมูลที่เป็นประโยชน์จะดูเป็นเรื่องง่ายอย่างรวดเร็ว แต่การจะไปถึงจุดนั้นจำเป็นต้องเอาชนะอุปสรรคที่น่ากลัวหลายประการ ซึ่งต้องใช้ความสามารถด้านการวิเคราะห์และทางเทคนิคที่แข็งแกร่ง
การจัดการเนื้อหาแบบไดนามิก
เนื้อหาแบบไดนามิกซึ่งหมายถึงข้อมูลหน้าเว็บที่อัปเดตตามการกระทำของผู้ใช้หรือการโหลดหลังจากการดูหน้าแรก มักก่อให้เกิดความท้าทายสำหรับเครื่องมือขูดเว็บ

แหล่งที่มาของรูปภาพ: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
เนื้อหาแบบไดนามิกดังกล่าวมักถูกใช้ในเว็บแอปพลิเคชันร่วมสมัยที่สร้างโดยใช้เฟรมเวิร์ก JavaScript หากต้องการจัดการและดึงข้อมูลจากเนื้อหาที่สร้างขึ้นแบบไดนามิกดังกล่าวได้สำเร็จ ให้พิจารณาแนวทางปฏิบัติที่ดีที่สุดเหล่านี้:
- พิจารณาใช้เครื่องมืออัตโนมัติของเว็บ เช่น Selenium, Puppeteer หรือ Playwright ซึ่งช่วยให้ Web Scraper ของคุณทำงานบนเว็บเพจได้เหมือนกับที่ผู้ใช้จริงทำ
- ใช้เทคนิคการจัดการ WebSockets หรือ AJAX หากเว็บไซต์ใช้เทคโนโลยีเหล่านี้เพื่อโหลดเนื้อหาแบบไดนามิก
- รอให้องค์ประกอบ โหลดโดยใช้การรอที่ชัดเจนในโค้ดที่คัดลอกเพื่อให้แน่ใจว่าเนื้อหาได้รับการโหลดอย่างสมบูรณ์ก่อนที่จะพยายามคัดลอก
- สำรวจการใช้ เบราว์เซอร์ที่ไม่มีส่วนหัว ซึ่งสามารถรัน JavaScript และเรนเดอร์ทั้งหน้ารวมถึงเนื้อหาที่โหลดแบบไดนามิก
ด้วยการใช้กลยุทธ์เหล่านี้อย่างเชี่ยวชาญ เครื่องขูดสามารถดึงข้อมูลจากเว็บไซต์ที่มีการโต้ตอบและเปลี่ยนแปลงแบบไดนามิกที่สุดได้อย่างมีประสิทธิภาพ
เทคโนโลยีต่อต้านการขูด
เป็นเรื่องปกติที่นักพัฒนาเว็บจะใช้มาตรการที่มุ่งป้องกันการคัดลอกข้อมูลที่ไม่ได้รับอนุญาตเพื่อปกป้องเว็บไซต์ของตน มาตรการเหล่านี้อาจทำให้เกิดความท้าทายที่สำคัญต่อเครื่องขูดเว็บ ต่อไปนี้เป็นวิธีการและกลยุทธ์หลายประการในการใช้เทคโนโลยีป้องกันการขูด:

ที่มาของภาพ: https://kinsta.com/knowledgebase/what-is-web-scraping/
- การแยกตัวประกอบแบบไดนามิก : เว็บไซต์อาจสร้างเนื้อหาแบบไดนามิก ทำให้ยากต่อการคาดเดา URL หรือโครงสร้าง HTML ใช้เครื่องมือที่สามารถรัน JavaScript และจัดการคำขอ AJAX
- การบล็อก IP : คำขอบ่อยครั้งจาก IP เดียวกันสามารถนำไปสู่การบล็อกได้ ใช้พร็อกซีเซิร์ฟเวอร์จำนวนมากเพื่อหมุนเวียน IP และเลียนแบบรูปแบบการรับส่งข้อมูลของมนุษย์
- CAPTCHA : สิ่งเหล่านี้ออกแบบมาเพื่อแยกความแตกต่างระหว่างมนุษย์และบอท ใช้บริการแก้ไข CAPTCHA หรือเลือกใช้การป้อนข้อมูลด้วยตนเองหากเป็นไปได้
- การจำกัดอัตรา : เพื่อหลีกเลี่ยงการจำกัดอัตราสะดุด ให้จำกัดอัตราคำขอของคุณ และใช้ความล่าช้าแบบสุ่มระหว่างคำขอ
- User-Agent : เว็บไซต์อาจบล็อก User-agent ของ Scraper ที่รู้จัก หมุนเวียนตัวแทนผู้ใช้เพื่อเลียนแบบเบราว์เซอร์หรืออุปกรณ์ต่างๆ
การเอาชนะความท้าทายเหล่านี้ต้องใช้แนวทางที่ซับซ้อนซึ่งเคารพข้อกำหนดในการให้บริการของเว็บไซต์ ในขณะเดียวกันก็เข้าถึงข้อมูลที่จำเป็นได้อย่างมีประสิทธิภาพ
การจัดการกับ CAPTCHA และกับดัก Honeypot
โปรแกรมขูดเว็บมักจะเผชิญกับความท้าทายของ CAPTCHA ที่ออกแบบมาเพื่อแยกแยะผู้ใช้ที่เป็นมนุษย์ออกจากบอท การเอาชนะสิ่งนี้ต้องการ:
- การใช้บริการแก้ไข CAPTCHA ที่ใช้ประโยชน์จากความสามารถของมนุษย์หรือ AI
- การดำเนินการล่าช้าและการสุ่มคำขอเพื่อเลียนแบบพฤติกรรมของมนุษย์
สำหรับกับดัก honeypot ซึ่งผู้ใช้จะมองไม่เห็น แต่จะดักจับสคริปต์อัตโนมัติ:
- ตรวจสอบโค้ดของเว็บไซต์อย่างระมัดระวังเพื่อหลีกเลี่ยงการโต้ตอบกับลิงก์ที่ซ่อนอยู่
- ใช้แนวทางปฏิบัติในการขูดแบบก้าวร้าวน้อยลงเพื่อให้อยู่ภายใต้เรดาร์
นักพัฒนาซอฟต์แวร์จะต้องสร้างสมดุลระหว่างประสิทธิภาพตามหลักจริยธรรมโดยคำนึงถึงข้อกำหนดของเว็บไซต์และประสบการณ์ผู้ใช้
ประสิทธิภาพการขูดและการเพิ่มประสิทธิภาพความเร็ว
กระบวนการขูดเว็บสามารถปรับปรุงได้โดยการเพิ่มประสิทธิภาพและความเร็ว เพื่อเอาชนะความท้าทายในโดเมนนี้:
- ใช้มัลติเธรดเพื่อให้สามารถดึงข้อมูลได้พร้อมกัน ช่วยเพิ่มปริมาณงาน
- ใช้ประโยชน์จากเบราว์เซอร์ที่ไม่มีส่วนหัวเพื่อการดำเนินการที่รวดเร็วยิ่งขึ้นโดยกำจัดการโหลดเนื้อหากราฟิกที่ไม่จำเป็น
- ปรับรหัสขูดให้เหมาะสมเพื่อดำเนินการโดยมีเวลาแฝงน้อยที่สุด
- ใช้การควบคุมปริมาณคำขอที่เหมาะสมเพื่อป้องกันการแบน IP ในขณะที่ยังคงรักษาความเร็วให้คงที่
- แคชเนื้อหาแบบคงที่เพื่อหลีกเลี่ยงการดาวน์โหลดซ้ำ ช่วยประหยัดแบนด์วิธและเวลา
- ใช้เทคนิคการเขียนโปรแกรมแบบอะซิงโครนัสเพื่อเพิ่มประสิทธิภาพการทำงานของ I/O เครือข่าย
- เลือกตัวเลือกที่มีประสิทธิภาพและไลบรารีการแยกวิเคราะห์เพื่อลดค่าใช้จ่ายในการจัดการ DOM
ด้วยการผสมผสานกลยุทธ์เหล่านี้ web scraper จึงสามารถบรรลุประสิทธิภาพที่แข็งแกร่งโดยลดการสะดุดในการปฏิบัติงานให้เหลือน้อยที่สุด

การสกัดและการแยกวิเคราะห์ข้อมูล
การขูดเว็บจำเป็นต้องมีการแยกและแยกวิเคราะห์ข้อมูลที่แม่นยำ ทำให้เกิดความท้าทายที่แตกต่างกัน ต่อไปนี้เป็นวิธีแก้ไขปัญหาเหล่านี้:
- ใช้ไลบรารีที่มีประสิทธิภาพ เช่น BeautifulSoup หรือ Scrapy ซึ่งสามารถจัดการโครงสร้าง HTML ต่างๆ ได้
- ใช้นิพจน์ทั่วไปอย่างระมัดระวังเพื่อกำหนดเป้าหมายรูปแบบเฉพาะอย่างแม่นยำ
- ใช้ประโยชน์จากเครื่องมืออัตโนมัติของเบราว์เซอร์ เช่น Selenium เพื่อโต้ตอบกับเว็บไซต์ที่ใช้ JavaScript จำนวนมาก เพื่อให้แน่ใจว่าข้อมูลจะถูกเรนเดอร์ก่อนที่จะแตกไฟล์
- ใช้ตัวเลือก XPath หรือ CSS เพื่อระบุองค์ประกอบข้อมูลภายใน DOM ได้อย่างแม่นยำ
- จัดการการแบ่งหน้าและการเลื่อนแบบไม่สิ้นสุดโดยการระบุและจัดการกลไกที่โหลดเนื้อหาใหม่ (เช่น การอัปเดตพารามิเตอร์ URL หรือการจัดการการเรียก AJAX)
การเรียนรู้ศิลปะแห่งการขูดเว็บ
การขูดเว็บเป็นทักษะอันล้ำค่าในโลกที่ขับเคลื่อนด้วยข้อมูล การเอาชนะความท้าทายด้านเทคนิค ตั้งแต่เนื้อหาแบบไดนามิกไปจนถึงการตรวจจับบอท ต้องใช้ความอุตสาหะและความสามารถในการปรับตัว การขูดเว็บที่ประสบความสำเร็จเกี่ยวข้องกับการผสมผสานวิธีการเหล่านี้:
- ใช้การรวบรวมข้อมูลอัจฉริยะเพื่อเคารพทรัพยากรของเว็บไซต์และนำทางโดยไม่ตรวจพบ
- ใช้การแยกวิเคราะห์ขั้นสูงเพื่อจัดการเนื้อหาแบบไดนามิก เพื่อให้มั่นใจว่าการแยกข้อมูลมีประสิทธิภาพต่อการเปลี่ยนแปลง
- ใช้บริการแก้ไข CAPTCHA อย่างมีกลยุทธ์เพื่อรักษาการเข้าถึงโดยไม่รบกวนการไหลของข้อมูล
- จัดการที่อยู่ IP อย่างรอบคอบและขอส่วนหัวเพื่อปิดบังกิจกรรมการคัดลอก
- จัดการการเปลี่ยนแปลงโครงสร้างเว็บไซต์โดยการอัปเดตสคริปต์พาร์เซอร์เป็นประจำ
การเรียนรู้เทคนิคเหล่านี้อย่างเชี่ยวชาญจะทำให้เราสามารถนำทางไปยังความซับซ้อนของการรวบรวมข้อมูลเว็บได้อย่างเชี่ยวชาญ และปลดล็อกการจัดเก็บข้อมูลอันมีค่าจำนวนมหาศาล
การจัดการโครงการขูดขนาดใหญ่
โครงการขูดเว็บขนาดใหญ่จำเป็นต้องมีการจัดการที่แข็งแกร่งเพื่อให้มั่นใจถึงประสิทธิภาพและการปฏิบัติตามข้อกำหนด การเป็นพันธมิตรกับผู้ให้บริการขูดเว็บมีข้อดีหลายประการ:
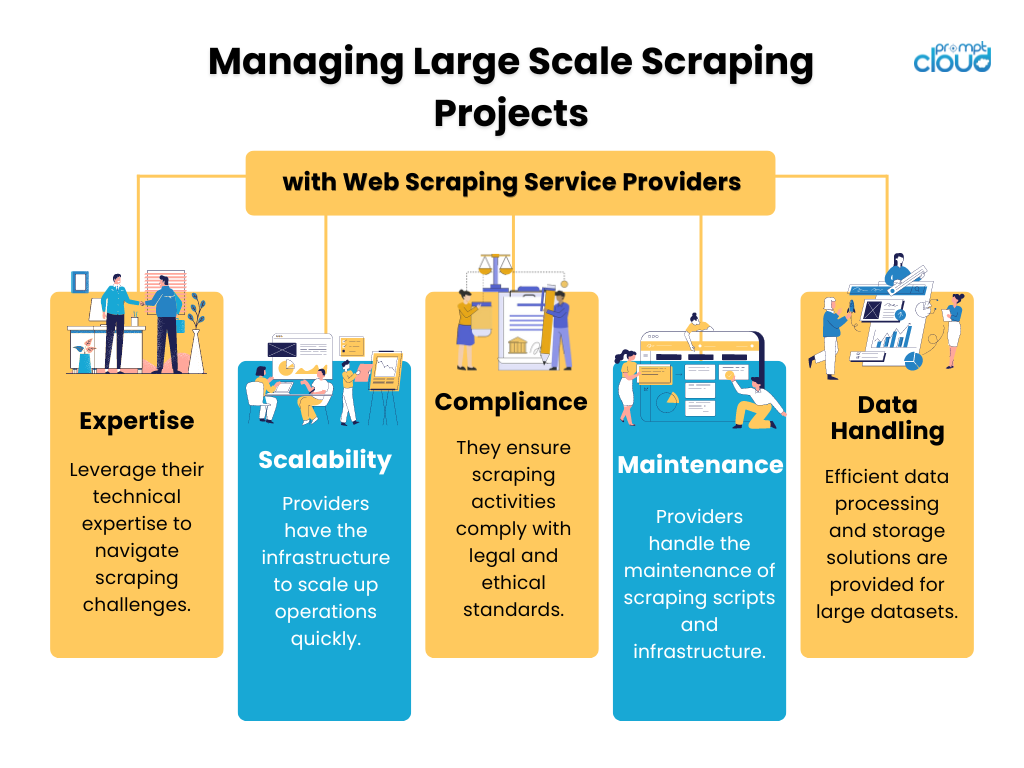
การมอบหมายโครงการขูดให้กับมืออาชีพสามารถเพิ่มประสิทธิภาพผลลัพธ์และลดความเครียดทางเทคนิคให้กับทีมงานในองค์กรของคุณ
คำถามที่พบบ่อย
การขูดเว็บมีข้อจำกัดอะไรบ้าง?
การขูดเว็บเผชิญกับข้อจำกัดบางประการที่ต้องพิจารณาก่อนที่จะรวมเข้ากับการดำเนินงาน ตามกฎหมายแล้ว บางเว็บไซต์ไม่อนุญาตให้คัดลอกผ่านข้อกำหนดและเงื่อนไขหรือไฟล์ robot.txt การเพิกเฉยต่อข้อจำกัดเหล่านี้อาจส่งผลให้เกิดผลกระทบร้ายแรง
ในทางเทคนิคแล้ว เว็บไซต์อาจใช้มาตรการตอบโต้ต่อการขูดข้อมูล เช่น CAPTCHA, บล็อก IP และ Honey Pots เพื่อป้องกันการเข้าถึงโดยไม่ได้รับอนุญาต ความแม่นยำของข้อมูลที่แยกออกมาอาจกลายเป็นปัญหาได้ เนื่องจากการแสดงผลแบบไดนามิกและแหล่งที่มาที่อัปเดตบ่อยครั้ง สุดท้ายนี้ การขูดเว็บจำเป็นต้องอาศัยความรู้ด้านเทคนิค การลงทุนในทรัพยากร และความพยายามอย่างต่อเนื่อง ซึ่งก่อให้เกิดความท้าทาย โดยเฉพาะอย่างยิ่งสำหรับผู้ที่ไม่มีความรู้ด้านเทคนิค
เหตุใดการขูดข้อมูลจึงเป็นปัญหา
ปัญหาส่วนใหญ่เกิดขึ้นเมื่อการขูดข้อมูลเกิดขึ้นโดยไม่ได้รับอนุญาตที่จำเป็นหรือประพฤติตามหลักจริยธรรม การแยกข้อมูลที่เป็นความลับถือเป็นการละเมิดบรรทัดฐานความเป็นส่วนตัวและการละเมิดกฎเกณฑ์ที่ออกแบบมาเพื่อปกป้องผลประโยชน์ส่วนบุคคล
การใช้เซิร์ฟเวอร์เป้าหมายแบบขูดมากเกินไป ส่งผลเสียต่อประสิทธิภาพและความพร้อมใช้งาน การโจรกรรมทรัพย์สินทางปัญญาถือเป็นข้อกังวลอีกประการหนึ่งที่เกิดจากการคัดลอกที่ผิดกฎหมายอันเนื่องมาจากคดีละเมิดลิขสิทธิ์ที่อาจเกิดขึ้นซึ่งริเริ่มโดยฝ่ายที่ได้รับความเดือดร้อน
ดังนั้น การปฏิบัติตามข้อกำหนดนโยบาย การรักษามาตรฐานทางจริยธรรม และการขอความยินยอมในทุกที่ที่จำเป็น ยังคงเป็นสิ่งสำคัญในขณะที่ดำเนินงานขูดข้อมูล
เหตุใดการขูดเว็บจึงอาจไม่ถูกต้อง?
การขูดเว็บซึ่งเกี่ยวข้องกับการดึงข้อมูลจากเว็บไซต์โดยอัตโนมัติผ่านซอฟต์แวร์พิเศษไม่รับประกันความถูกต้องสมบูรณ์เนื่องจากปัจจัยหลายประการ ตัวอย่างเช่น การปรับเปลี่ยนโครงสร้างเว็บไซต์อาจทำให้เครื่องมือขูดทำงานผิดปกติหรือรวบรวมข้อมูลที่ผิดพลาดได้
นอกจากนี้ เว็บไซต์บางแห่งยังใช้มาตรการป้องกันการขูด เช่น การทดสอบ CAPTCHA, การบล็อก IP หรือการแสดงผล JavaScript ส่งผลให้ข้อมูลที่พลาดหรือบิดเบี้ยว ในบางครั้ง การกำกับดูแลของนักพัฒนาในระหว่างการสร้างมีส่วนทำให้เกิดผลลัพธ์ที่ต่ำกว่ามาตรฐานเช่นกัน
อย่างไรก็ตาม การเป็นพันธมิตรกับผู้ให้บริการขูดเว็บที่เชี่ยวชาญสามารถเสริมความแม่นยำได้ เนื่องจากพวกเขานำความรู้และสินทรัพย์ที่จำเป็นมาเพื่อสร้างเครื่องขูดที่ยืดหยุ่นและว่องไวซึ่งสามารถรักษาระดับความแม่นยำสูงแม้จะมีการเปลี่ยนแปลงเค้าโครงเว็บไซต์ก็ตาม ผู้เชี่ยวชาญที่มีทักษะจะทดสอบและตรวจสอบความถูกต้องของแครปเปอร์เหล่านี้อย่างพิถีพิถันก่อนนำไปใช้งาน เพื่อให้มั่นใจว่าถูกต้องตลอดกระบวนการสกัด
การขูดเว็บน่าเบื่อไหม?
แท้จริงแล้ว การมีส่วนร่วมในกิจกรรมการขูดเว็บสามารถพิสูจน์ได้ว่าต้องใช้ความพยายามและลำบาก โดยเฉพาะสำหรับผู้ที่ขาดความเชี่ยวชาญด้านการเขียนโค้ดหรือความเข้าใจในแพลตฟอร์มดิจิทัล งานดังกล่าวจำเป็นต้องมีการประดิษฐ์โค้ดตามความต้องการ แก้ไขสเครปเปอร์ที่ผิดพลาด บริหารจัดการสถาปัตยกรรมเซิร์ฟเวอร์ และติดตามการเปลี่ยนแปลงที่เกิดขึ้นภายในเว็บไซต์เป้าหมาย ซึ่งทั้งหมดนี้จำเป็นต้องใช้ความสามารถทางเทคนิคอย่างมากควบคู่ไปกับการลงทุนจำนวนมากในแง่ของการเสียเวลา
การขยายการดำเนินการขูดเว็บขั้นพื้นฐานในอดีตนั้นมีความซับซ้อนมากขึ้นเรื่อยๆ เมื่อคำนึงถึงการปฏิบัติตามกฎระเบียบ การจัดการแบนด์วิธ และการนำระบบคอมพิวเตอร์แบบกระจายไปใช้
ในทางตรงกันข้าม การเลือกใช้บริการขูดเว็บแบบมืออาชีพจะช่วยลดภาระที่เกี่ยวข้องได้อย่างมากด้วยข้อเสนอสำเร็จรูปที่ออกแบบตามความต้องการเฉพาะของผู้ใช้ ด้วยเหตุนี้ ลูกค้าจึงมุ่งเน้นไปที่การควบคุมข้อมูลที่เก็บเกี่ยวมาเป็นหลัก ในขณะที่ปล่อยให้โลจิสติกส์การรวบรวมไปยังทีมงานเฉพาะซึ่งประกอบด้วยนักพัฒนาที่มีทักษะและผู้เชี่ยวชาญด้านไอทีที่รับผิดชอบในการเพิ่มประสิทธิภาพระบบ การจัดสรรทรัพยากร และตอบคำถามทางกฎหมาย ซึ่งช่วยลดความน่าเบื่อโดยรวมที่เกี่ยวข้องกับการริเริ่มการขูดเว็บอย่างเห็นได้ชัด