
Superando desafios técnicos em web scraping: soluções especializadas
Publicados: 2024-03-29Web scraping é uma prática que apresenta vários desafios técnicos, mesmo para mineradores de dados experientes. Implica a utilização de técnicas de programação para obter e recuperar dados de sites, o que nem sempre é fácil devido à natureza complexa e variada das tecnologias web.
Além disso, muitos sites possuem medidas de proteção para evitar a coleta de dados, tornando essencial que os scrapers negociem mecanismos anti-raspagem, conteúdo dinâmico e estruturas de site complicadas.
Apesar do objetivo de adquirir rapidamente informação útil parecer simples, chegar lá requer a superação de diversas barreiras formidáveis, exigindo fortes capacidades analíticas e técnicas.
Lidando com conteúdo dinâmico
O conteúdo dinâmico, que se refere às informações da página da web que são atualizadas com base nas ações ou carregamentos do usuário após a visualização inicial da página, geralmente representa desafios para as ferramentas de web scraping.

Fonte da imagem: https://www.scaler.com/topics/php-tutorial/dynamic-website-in-php/
Esse conteúdo dinâmico é frequentemente utilizado em aplicações web contemporâneas construídas com estruturas JavaScript. Para gerenciar e extrair dados com êxito desse conteúdo gerado dinamicamente, considere estas práticas recomendadas:
- Considere o uso de ferramentas de automação da web, como Selenium, Puppeteer ou Playwright, que permitem que seu web scraper se comporte na página da mesma forma que um usuário genuíno faria.
- Implemente técnicas de manipulação de WebSockets ou AJAX se o site utilizar essas tecnologias para carregar conteúdo dinamicamente.
- Aguarde o carregamento dos elementos usando esperas explícitas em seu código de extração para garantir que o conteúdo esteja totalmente carregado antes de tentar extraí-lo.
- Explore o uso de navegadores headless que podem executar JavaScript e renderizar a página inteira, incluindo conteúdo carregado dinamicamente.
Ao dominar essas estratégias, os scrapers podem extrair dados com eficácia até mesmo dos sites mais interativos e que mudam dinamicamente.
Tecnologias anti-raspagem
É comum que os desenvolvedores web implementem medidas destinadas a impedir a coleta de dados não aprovada para proteger seus sites. Essas medidas podem representar desafios significativos para web scrapers. Aqui estão vários métodos e estratégias para navegar pelas tecnologias anti-raspagem:

Fonte da imagem: https://kinsta.com/knowledgebase/what-is-web-scraping/
- Factoring dinâmico : os sites podem gerar conteúdo dinamicamente, dificultando a previsão de URLs ou estruturas HTML. Utilize ferramentas que possam executar JavaScript e lidar com solicitações AJAX.
- Bloqueio de IP : Solicitações frequentes do mesmo IP podem levar a bloqueios. Use um pool de servidores proxy para alternar IPs e imitar padrões de tráfego humano.
- CAPTCHAs : são projetados para distinguir entre humanos e bots. Aplique serviços de resolução CAPTCHA ou opte pela entrada manual, se possível.
- Limitação de taxa : para evitar limites de taxa de disparo, limite suas taxas de solicitação e implemente atrasos aleatórios entre as solicitações.
- Agente de usuário : os sites podem bloquear agentes de usuário raspadores conhecidos. Alterne os agentes de usuário para imitar diferentes navegadores ou dispositivos.
Superar esses desafios requer uma abordagem sofisticada que respeite os termos de serviço do site e, ao mesmo tempo, acesse de forma eficiente os dados necessários.
Lidando com armadilhas CAPTCHA e Honeypot
Os web scrapers frequentemente encontram desafios CAPTCHA projetados para distinguir usuários humanos de bots. Superar isso requer:
- Utilizando serviços de resolução de CAPTCHA que aproveitam as capacidades humanas ou de IA.
- Implementar atrasos e randomizar solicitações para imitar o comportamento humano.
Para armadilhas honeypot, que são invisíveis para os usuários, mas interceptam scripts automatizados:
- Inspecione cuidadosamente o código do site para evitar interação com links ocultos.
- Empregar práticas de raspagem menos agressivas para permanecer fora do radar.
Os desenvolvedores devem equilibrar eticamente a eficácia com o respeito aos termos do site e à experiência do usuário.
Eficiência de raspagem e otimização de velocidade
Os processos de web scraping podem ser melhorados otimizando a eficiência e a velocidade. Para superar desafios neste domínio:
- Utilize multithreading para permitir a extração simultânea de dados, aumentando o rendimento.
- Aproveite navegadores headless para uma execução mais rápida, eliminando o carregamento desnecessário de conteúdo gráfico.
- Otimize o código de raspagem para ser executado com latência mínima.
- Implemente a limitação de solicitações apropriada para evitar banimentos de IP e, ao mesmo tempo, manter um ritmo estável.
- Armazene em cache o conteúdo estático para evitar downloads repetidos, economizando largura de banda e tempo.
- Empregue técnicas de programação assíncrona para otimizar as operações de E/S da rede.
- Escolha seletores e bibliotecas de análise eficientes para reduzir a sobrecarga da manipulação do DOM.
Ao incorporar essas estratégias, os web scrapers podem alcançar um desempenho robusto com problemas operacionais minimizados.

Extração e análise de dados
Web scraping requer extração e análise precisa de dados, apresentando desafios distintos. Aqui estão algumas maneiras de abordá-los:
- Use bibliotecas robustas como BeautifulSoup ou Scrapy, que podem lidar com várias estruturas HTML.
- Implemente expressões regulares com cautela para atingir padrões específicos com precisão.
- Aproveite ferramentas de automação de navegador como Selenium para interagir com sites com muito JavaScript, garantindo que os dados sejam renderizados antes da extração.
- Adote seletores XPath ou CSS para localização precisa de elementos de dados dentro do DOM.
- Lide com paginação e rolagem infinita identificando e manipulando o mecanismo que carrega novo conteúdo (por exemplo, atualizando parâmetros de URL ou manipulando chamadas AJAX).
Dominando a arte de web scraping
Web scraping é uma habilidade inestimável no mundo orientado a dados. Superar desafios técnicos – que vão desde conteúdo dinâmico até detecção de bots – requer perseverança e adaptabilidade. Web scraping bem-sucedido envolve uma combinação destas abordagens:
- Implemente rastreamento inteligente para respeitar os recursos do site e navegar sem detecção.
- Utilize análise avançada para lidar com conteúdo dinâmico, garantindo que a extração de dados seja robusta contra alterações.
- Empregue estrategicamente serviços de resolução de CAPTCHA para manter o acesso sem interromper o fluxo de dados.
- Gerencie cuidadosamente endereços IP e solicite cabeçalhos para disfarçar atividades de scraping.
- Lide com alterações na estrutura do site atualizando rotineiramente os scripts do analisador.
Ao dominar essas técnicas, é possível navegar habilmente pelas complexidades do rastreamento da web e desbloquear vastos estoques de dados valiosos.
Gerenciando projetos de raspagem em grande escala
Projetos de web scraping em grande escala exigem gerenciamento robusto para garantir eficiência e conformidade. A parceria com provedores de serviços de web scraping oferece várias vantagens:
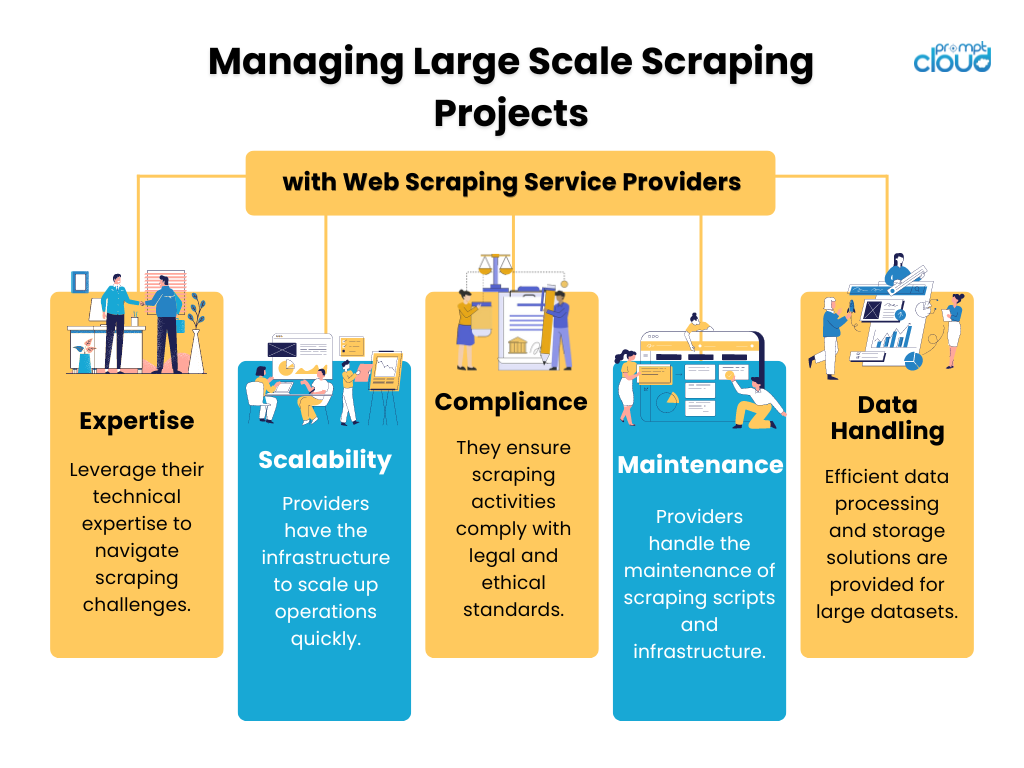
Confiar projetos de scraping a profissionais pode otimizar os resultados e minimizar o desgaste técnico de sua equipe interna.
Perguntas frequentes
Quais são as limitações do web scraping?
O web scraping enfrenta certas restrições que devem ser consideradas antes de incorporá-lo em suas operações. Legalmente, alguns sites não permitem a extração por meio de termos e condições ou arquivos robot.txt; ignorar essas restrições pode resultar em consequências graves.
Tecnicamente, os sites podem implementar contramedidas contra scraping, como CAPTCHAs, blocos de IP e honey pots, evitando assim o acesso não autorizado. A precisão dos dados extraídos também pode se tornar um problema devido à renderização dinâmica e às fontes atualizadas com frequência. Por último, o web scraping exige conhecimentos técnicos, investimento em recursos e esforço contínuo – apresentando desafios, especialmente para pessoas não técnicas.
Por que a coleta de dados é um problema?
Os problemas surgem principalmente quando a coleta de dados ocorre sem as permissões necessárias ou conduta ética. A extração de informações confidenciais viola normas de privacidade e transgride estatutos concebidos para proteger interesses individuais.
O uso excessivo de scraping sobrecarrega os servidores, impactando negativamente o desempenho e a disponibilidade. O roubo de propriedade intelectual constitui mais uma preocupação decorrente do roubo ilícito devido a possíveis ações judiciais de violação de direitos autorais iniciadas pelas partes lesadas.
Portanto, cumprir as estipulações políticas, defender os padrões éticos e buscar o consentimento sempre que necessário continua sendo crucial durante a realização de tarefas de coleta de dados.
Por que o web scraping pode ser impreciso?
Web scraping, que envolve a extração automática de dados de sites por meio de software especializado, não garante precisão total devido a diversos fatores. Por exemplo, modificações na estrutura do site podem causar mau funcionamento da ferramenta scraper ou capturar informações erradas.
Além disso, certos sites implementam medidas anti-raspagem, como testes CAPTCHA, bloqueios de IP ou renderização de JavaScript, levando a dados perdidos ou distorcidos. Ocasionalmente, os descuidos dos desenvolvedores durante a criação também contribuem para resultados abaixo do ideal.
No entanto, a parceria com provedores de serviços de web scraping proficientes pode aumentar a precisão, uma vez que eles trazem o conhecimento e os recursos necessários para construir scrapers resilientes e ágeis, capazes de manter altos níveis de precisão, apesar das mudanças nos layouts dos sites. Especialistas qualificados testam e validam esses raspadores meticulosamente antes da implementação, garantindo a correção durante todo o processo de extração.
A raspagem da web é tediosa?
Na verdade, o envolvimento em atividades de web scraping pode revelar-se trabalhoso e exigente, especialmente para aqueles que não têm conhecimentos de codificação ou compreensão de plataformas digitais. Essas tarefas exigem a elaboração de códigos personalizados, a retificação de scrapers defeituosos, a administração de arquiteturas de servidores e o acompanhamento das alterações que ocorrem nos sites direcionados – tudo isso exigindo habilidades técnicas consideráveis, juntamente com investimentos substanciais em termos de dispêndio de tempo.
A expansão dos empreendimentos básicos de web scraping torna-se cada vez mais complexa, dadas as considerações sobre conformidade regulatória, gerenciamento de largura de banda e implementação de sistemas de computação distribuídos.
Por outro lado, a opção por serviços profissionais de web scraping diminui substancialmente os encargos associados por meio de ofertas prontas projetadas de acordo com as demandas específicas do usuário. Consequentemente, os clientes concentram-se principalmente no aproveitamento dos dados recolhidos, deixando a logística de recolha para equipas dedicadas compostas por programadores qualificados e especialistas de TI responsáveis pela otimização do sistema, alocação de recursos e resolução de questões jurídicas, reduzindo assim significativamente o tédio geral relacionado com iniciativas de web scraping.